



.webp)
July 3, 2026
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: May 21, 2026

Blazingly fast way to build, track and deploy your models!
Esses termos são usados de forma intercambiável até que algo dê errado. Eles descrevem arquiteturas distintas com garantias distintas, e o custo de confundi-los é pago em falhas de segurança, insucessos de auditoria e reconstruções que você não deveria ter tido que fazer.
À medida que o Protocolo de Contexto de Modelo se torna o meio padrão para conectar agentes de IA a fontes de dados e ferramentas, a terminologia da infraestrutura se emaranhou. Fornecedores, posts de blog e documentos de design internos usam "proxy", "roteador" e "gateway" de forma intercambiável. A distinção é vaga quando tudo está no laptop de um desenvolvedor e letal quando você começa a implantar agentes em produção — porque as três palavras nomeiam coisas estruturalmente diferentes, e a diferença só aparece quando um auditor faz uma pergunta que uma delas não consegue responder.
Pegando emprestado da rede, obtemos o modelo mental mais claro. Um proxy opera na Camada 4 (L4) — ele encaminha bytes e não os interpreta. Um roteador opera no despacho de capacidade da Camada 7 (L7) — ele conhece a ferramenta, mas não conhece o principal que a está chamando. Um gateway opera na política da Camada 7 (L7) — ele conhece a ferramenta, o principal, o orçamento e o rastro de auditoria. Cada camada é estritamente mais capaz, estritamente mais cara de operar e responde a estritamente mais perguntas sobre cada solicitação.
Um proxy é a peça mais simples no diagrama. Sua função é a mediação de protocolo. O MCP faz uso intenso de stdio para execução local; um proxy pode encapsular um servidor MCP baseado em stdio e expô-lo via HTTP/SSE ou WebSockets para que um cliente remoto possa alcançá-lo. Esse é todo o trabalho.
Um proxy não faz nenhuma interpretação da carga útil. Ele não analisa JSON-RPC, não entende chamadas de ferramentas, não sabe o que "ferramenta" significa. Ele encaminha bytes. Isso o torna rápido em sub-milissegundos e quase gratuito para operar. Um único desenvolvedor conectando o Claude Desktop a um servidor MCP dentro de um contêiner Docker na mesma máquina — esse é um caso de uso de proxy. Sem governança, sem estado, sem motivo para nenhum dos dois.
O erro é pensar que o proxy escalará. Não escalará. No momento em que você tem mais de um desenvolvedor ou mais de um servidor MCP downstream, o proxy deixa de ser um elemento de suporte de carga e o roteador assume. Um proxy não é um bloco de construção de uma pilha empresarial; é uma ferramenta de conveniência pessoal que um gateway pode encapsular internamente para adaptação de transporte. Tratá-lo como mais ou menos do que isso — superconstruí-lo, subestimá-lo — produz uma arquitetura que envelhece mal.

À medida que os ambientes crescem, codificar URLs de servidor diretamente nos clientes deixa de ser sustentável. Um roteador resolve a descoberta: em vez de o cliente saber onde o github-mcp-server reside, o cliente conecta-se ao roteador e pergunta quais ferramentas estão disponíveis. O roteador mantém um registro de servidores downstream e um mapa de capacidades.
Quando o LLM chama search_repositories, o roteador inspeciona a carga útil JSON-RPC, identifica a ferramenta de destino e despacha a chamada para o backend correto. É, mecanicamente, um agregador com uma tabela de roteamento — rápido, simples e uma abstração limpa. A maioria das equipes internas recorre a um assim que têm mais de dois servidores MCP, e não estão erradas em fazê-lo.
O que o roteador não faz é fazer a pergunta que mais importa em produção: a identidade que está fazendo esta chamada está realmente autorizada a invocar esta ferramenta? Ele roteia por capacidade. Ele não controla por política. O modelo pode chamar delete_branch em produção tão facilmente quanto pode chamar list_issues em um repositório público. O roteador despachará ambos obedientemente, e o log de auditoria que ele produz ou não é moldado apenas pelo fio — não por quem segurou o fio.
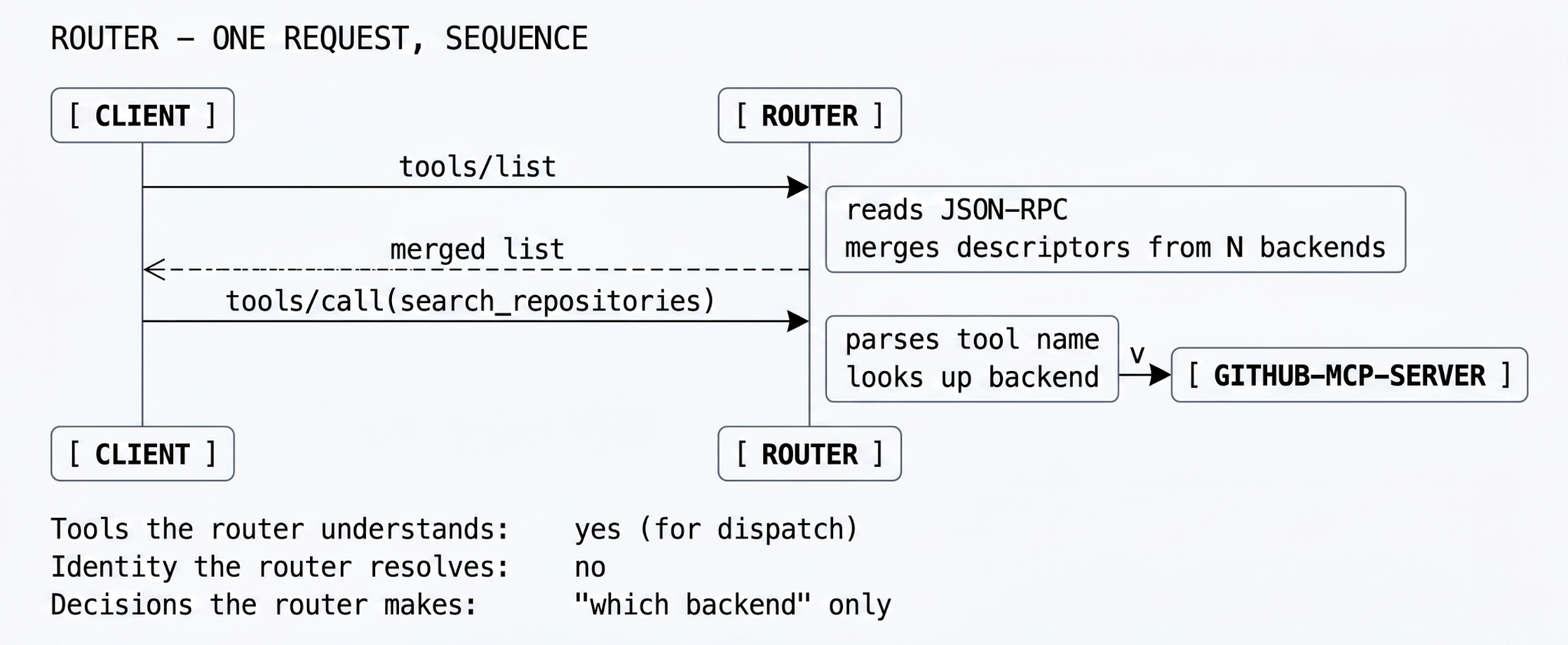
O roteador é a camada certa quando os agentes são internos, a rede é confiável e a ação no pior cenário é irreversível. A transição que prejudica as equipes é roteador → gateway, e geralmente acontece no dia em que alguém pergunta quem chamou delete_branch em produção na última terça-feira. O roteador não tem resposta a dar, porque nunca soube.
Um gateway engloba o proxy e o roteador e adiciona um plano de controle L7 por cima. Esta é a camada onde as operações de IA empresariais realmente acontecem — e a camada onde uma revisão de segurança começará, independentemente de alguém a ter chamado assim durante o design.
Um gateway inspeciona cada pacote. Ele se integra com a identidade corporativa (OAuth 2.0, SAML, OIDC) para estabelecer em nome de quem o agente está agindo. Ele impõe RBAC em nível de ferramenta. Ele executa a sanitização de esquema que detecta envenenamento de MCP. Ele rastreia o uso de tokens para atribuição de orçamento. Ele escreve logs à prova de adulteração para SIEMs externos. É, estruturalmente, o local onde a política de IA da organização é codificada — e o único lugar onde o agente de um contratado desligado para de funcionar no momento certo.
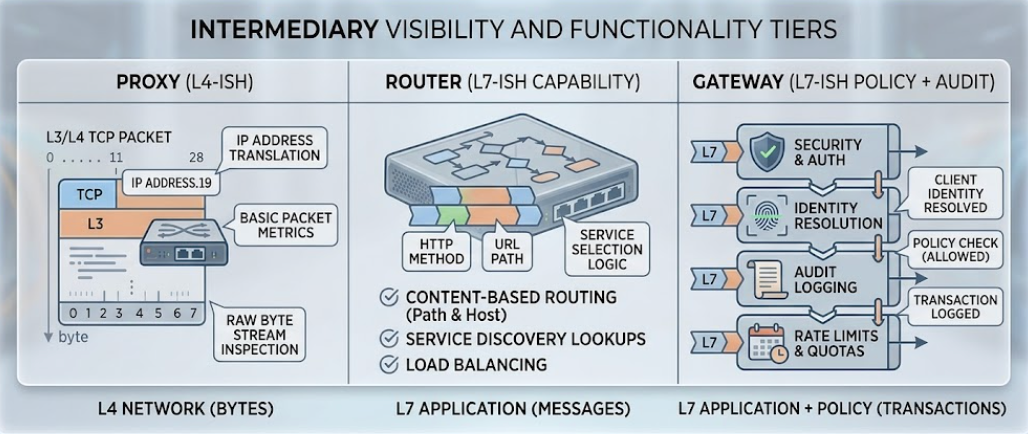
A mesma comparação em formato tabular, para os revisores de documentos de design que farão uma leitura rápida. Leia as colunas; cada uma responde a uma pergunta sobre uma requisição.
Tabela 1 — Matriz de capacidades. A coluna da direita é o que seu auditor perguntará; a coluna do meio é o que sua equipe buscará primeiro; a coluna da esquerda é o que roda no seu laptop.
Uma breve árvore de decisão, escrita na ordem em que as equipes de produção realmente respondem às perguntas:
A transição que mais afeta as equipes é roteador → gateway, e sempre acontece no mesmo momento: alguém faz uma pergunta de auditoria que exige logs correlacionados à identidade, e o roteador não tem resposta porque nunca soube quem estava chamando. A solução barata nesse ponto é adicionar um gateway. A solução cara é reconstruir a plataforma do agente após um incidente de segurança — que é o que uma parte das equipes acabará fazendo, porque a solução barata é invisível até o incidente.
A TrueFoundry é construída como um gateway federado. O plano de controle (onde as políticas são criadas, os modelos são registrados e a observabilidade reside) é separado do plano de gateway (onde o tráfego flui). O plano de gateway é completamente sem estado — cada pod de gateway se inscreve no plano de controle via NATS para atualizações de configuração, e cada verificação que ele realiza é em memória contra esse estado sincronizado. Não há um único ponto de falha entre o agente e o backend. Se o plano de controle cair, os gateways continuam a servir com sua última configuração conhecida; quando o plano de controle retorna, o NATS reconcilia. Como uma salvaguarda final, o plano de controle republica toda a configuração a cada 10 minutos — a consistência eventual é garantida mesmo que uma atualização intermediária tenha sido perdida.
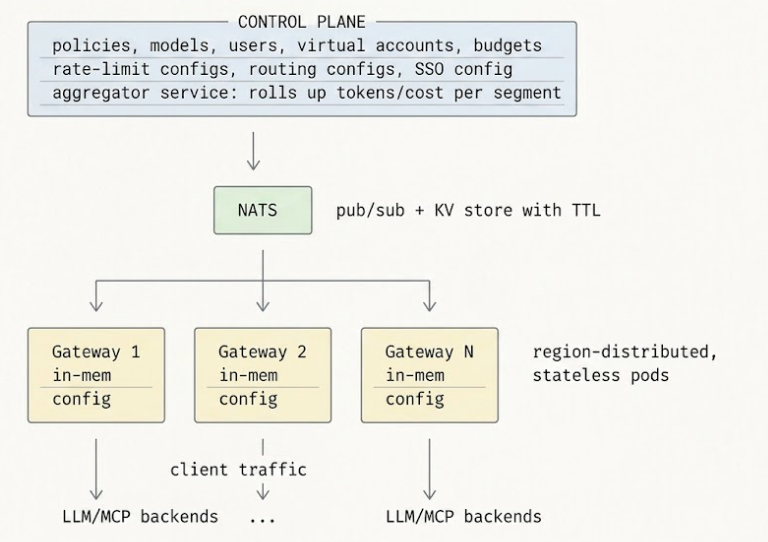
O plano de dados é construído sobre Hono — um framework alinhado com a Web Fetch API otimizado para a borda — e realiza todas as verificações de limite de taxa, autenticação e roteamento na memória do processo. O plano de controle sincroniza a configuração via NATS com cadência de sub-segundos; o próprio caminho da requisição nunca faz uma chamada externa, a menos que o cache ou uma barreira de proteção baseada em rede seja invocada. A propriedade estrutural que importa é a ausência de estado: um pod de gateway pode ser encerrado a qualquer momento sem perder decisões de política em andamento, porque não há decisões de política em andamento — cada decisão é tomada a partir da memória local contra uma configuração que chegou assincronamente.
A funcionalidade que une a arquitetura é a composição virtual de servidores MCP. O gateway mescla esquemas de dezenas de servidores MCP de backend em uma única superfície de API, com escopo dinâmico por chamador. O token IAM de um desenvolvedor frontend produz uma lista unificada de ferramentas diferente da de um engenheiro de plataforma, e nenhum deles vê ferramentas que o outro não tem permissão para usar. Da perspectiva do modelo, há um servidor MCP. Da perspectiva da equipe de plataforma, há um único lugar para definir a política. Da perspectiva do auditor, cada chamada de ferramenta tem um ID de rastreamento que vincula a decisão do modelo à identidade do desenvolvedor que a autorizou.
Mesmo cliente, mesmos backends, meio vastamente diferente. O meio é a parte que envelhece bem.
A arquitetura é principalmente a prática de escolher onde as fronteiras se estabelecem, e o custo de errar essa escolha é pago não no momento do design, mas no próximo incidente, na próxima auditoria, na próxima migração. A distinção proxy/roteador/gateway não é um problema de vocabulário. É uma questão de saber se sua plataforma tem um ponto de controle na junção onde a identidade corporativa encontra o loop do agente, ou se ela tem uma tabela de roteamento onde deveria haver um ponto de controle.
A maioria das equipes descobre essa distinção da maneira mais difícil. Algumas a descobrem durante uma análise post-mortem; outras durante uma revisão de conformidade; outras quando o agente de um contratado desligado continua funcionando por uma semana a mais do que deveria. O momento da descoberta é o mesmo nos três casos. O custo da descoberta é o que varia.
Sim, e a maioria das equipes faz isso. O caminho de migração é limpo: o gateway usa o mesmo protocolo de comunicação MCP, então os clientes existentes continuam funcionando. O que muda é o URL para o qual eles apontam e o cabeçalho de autenticação que eles incluem. Planeje a migração em duas fases — primeiro, configure o gateway em modo de auditoria (registro de logs, sem imposição) e valide se os logs correspondem às expectativas; depois, ative a imposição por servidor, começando pelos servidores MCP de menor risco e terminando com o banco de dados de produção.
Os gateways continuam a servir tráfego com a última configuração que buscaram, indefinidamente. Eles se inscrevem no NATS para atualizações em tempo real e, como backup, tentam buscar a configuração via HTTP do serviço de backend do plano de controle. Se tanto o NATS quanto o backend estiverem inativos, os pods de gateway existentes continuam a funcionar com a última configuração conhecida; novos pods que tentarem iniciar durante a interrupção falharão em sua verificação de prontidão e não receberão tráfego. A recomendação é executar múltiplas réplicas de gateway — a chance de todos eles reiniciarem durante uma interrupção do plano de controle é a probabilidade contra a qual você precisa se preparar, e ela é pequena.
O Hono é construído sobre a API Web Fetch e é projetado para ambientes de execução de borda (Cloudflare Workers, Deno, Bun, Node). É pequeno, rápido e funciona de forma idêntica em diferentes ambientes de execução — o que é importante porque o gateway precisa ser portátil entre SaaS, Kubernetes on-premise e ambientes isolados com proxy Squid. O Express tem uma área de superfície muito grande; o Fastify é bom, mas está vinculado a especificidades do Node. A propriedade relevante é a baixa sobrecarga consistente em alta concorrência, que o Hono entrega de forma confiável.
Ela define o escopo por chamador. O gateway avalia os atributos IAM e ABAC do principal em relação ao pacote de políticas toda vez que serve uma lista de ferramentas (tools/list), e emite uma união filtrada de descritores de ferramentas. Dois desenvolvedores que fazem login com segundos de diferença podem receber listas de ferramentas diferentes do mesmo endpoint do gateway. O modelo nunca sabe que existem múltiplos backends, e nunca sabe que existem ferramentas que seu chamador atual não pode acessar. É assim também que se obtêm implantações multi-tenant limpas — o mesmo gateway serve mundos diferentes para diferentes tenants.
Três mecanismos. As cargas de configuração são idempotentes — o plano de controle publica todo o estado atual no NATS a cada alteração, então receber a mesma mensagem duas vezes não tem efeito. O NATS oferece entrega "pelo menos uma vez", então o gateway verá cada atualização pelo menos uma vez. E como uma medida de segurança adicional, o plano de controle republica a configuração completa a cada 10 minutos — mesmo que uma atualização intermediária tenha sido perdida, o gateway converge para o estado correto em no máximo 10 minutos. O desvio é limitado por design.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.






.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




