Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.
9,9
Como Pensar sobre a Arquitetura de Gateway de IA na Pilha de IA Generativa
Nos sistemas modernos de IA generativa, o Gateway de IA atua como a camada de proxy crítica entre aplicações e provedores de modelos de linguagem (LLM). Ele desempenha um papel central na gestão da confiabilidade, observabilidade, controle de acesso e eficiência de custos para cada solicitação que entra em produção.
Como o gateway se encontra no caminho crítico do tráfego de produção, ele deve ser projetado com os seguintes princípios fundamentais em mente:
Principais Prioridades Arquitetônicas:
Alta Disponibilidade: O gateway não deve se tornar um ponto único de falha. Mesmo diante de problemas de dependência (como interrupções de banco de dados ou filas), ele deve continuar a atender o tráfego de forma elegante.
Baixa Latência: Como ele está em linha com cada solicitação de inferência, o gateway deve adicionar sobrecarga mínima para garantir uma experiência de usuário ágil.
Alto Rendimento e Escalabilidade: O sistema deve escalar linearmente com a carga e ser capaz de lidar com milhares de solicitações simultâneas com uso eficiente de recursos.
Sem Dependências Externas no Caminho Crítico: Quaisquer operações vinculadas à rede ou ao disco devem ser descarregadas para sistemas assíncronos para evitar gargalos de desempenho.
Tomada de Decisão em Memória: Verificações críticas como limitação de taxa, balanceamento de carga, autenticação e autorização devem ser todas realizadas em memória para máxima velocidade e confiabilidade.
Separação do Plano de Controle e do Plano de Proxy: As alterações de configuração e o gerenciamento do sistema devem ser desacoplados do roteamento de tráfego em tempo real, permitindo implantações globais com isolamento de falhas regional.
Arquitetura de Gateway de IA da TrueFoundry
Da TrueFoundry Gateway de IA incorpora todos os princípios de design acima, construído especificamente para baixa latência, alta confiabilidade e escalabilidade contínua
Arquitetura de Gateway da TrueFoundry
Principais Características da Arquitetura de Gateway de IA
Construído sobre o Framework Hono: O gateway aproveita Hono, um framework minimalista e ultrarrápido otimizado para ambientes de borda. Isso garante uma sobrecarga mínima em tempo de execução e um tratamento de requisições extremamente rápido.
Zero Chamadas Externas no Caminho da Requisição: Uma vez que uma requisição atinge o gateway, ela não aciona nenhuma chamada externa (a menos que o cache semântico esteja ativado). Toda a lógica operacional é tratada internamente, reduzindo riscos e aumentando a confiabilidade.
Aplicação em Memória: Todas as decisões de autenticação, autorização, limitação de taxa e balanceamento de carga são tomadas usando configurações em memória, garantindo tempos de resposta de sub-milissegundos.
Registro Assíncrono: Logs e métricas de requisição são enviados para uma fila de mensagens de forma assíncrona, garantindo que a observabilidade dos dados não bloqueie ou atrase o caminho da requisição.
Comportamento Tolerante a Falhas: Mesmo que a fila de log externa esteja inoperante, o gateway não falhará nenhuma requisição. Isso garante tempo de atividade e resiliência em caso de falhas parciais do sistema.
Escalável Horizontalmente: O gateway é limitado pela CPU e sem estado (stateless), o que facilita a sua expansão horizontal. Ele tem um desempenho eficiente sob alta concorrência e baixo uso de memória.
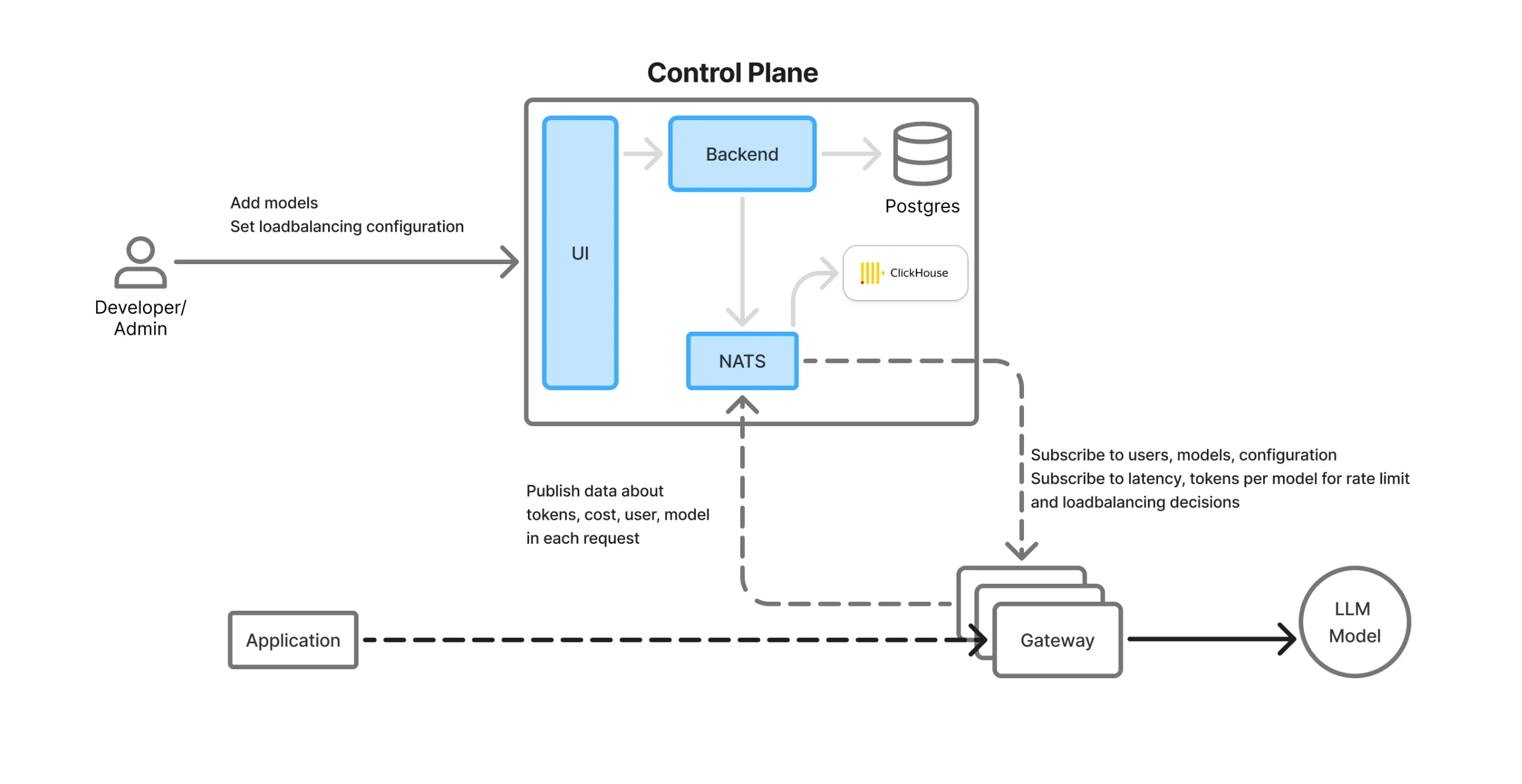
Plano de Controle e Fluxo de Dados
A TrueFoundry separa o plano de controle (gerenciamento) do plano de dados (roteamento de tráfego em tempo real) para escalabilidade e flexibilidade.
Visão Geral dos Componentes do Gateway de IA:
UI: Interface web com um playground de LLM, painéis de monitoramento e painéis de configuração para modelos, equipes, limites de taxa, etc.
Postgres DB: Armazena dados de configuração persistentes (usuários, equipes, chaves, modelos, contas virtuais, etc.)
ClickHouse: Banco de dados colunar de alto desempenho usado para armazenar logs, métricas e análises de uso.
Fila NATS: Atua como um barramento de sincronização em tempo real entre o plano de controle e os pods de gateway distribuídos. Todas as atualizações de configuração/estado são enviadas via NATS e ficam instantaneamente disponíveis em todas as regiões.
Serviço de Backend: Orquestra a sincronização de configurações, atualizações de banco de dados e ingestão de análises.
Pods de Gateway: Proxies leves, sem estado e na região, que lidam com o tráfego real de LLM. Eles consomem mensagens NATS e executam toda a lógica em memória, sem dependências externas.
Key Metrics for Evaluating Gateway
Criteria
What should you evaluate ?
Priority
TrueFoundry
Latency
Adds <10ms p95 overhead for time-to-first-token?
Must Have
✅ Supported
Data Residency
Keeps logs within your region (EU/US)?
Depends on use case
✅ Supported
Latency-Based Routing
Automatically reroutes based on real-time latency/failures?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Evaluating an AI Gateway?
A practical guide used by platform & infra teams
Benchmarks de Desempenho para o AI Gateway da TrueFoundry
O Gateway da TrueFoundry foi exaustivamente testado quanto ao desempenho sob cargas semelhantes às de produção:
250 RPS em 1 CPU/1GB de RAM com apenas 3 ms de latência adicionada.
Escala eficientemente até 350 RPS por pod antes de atingir a saturação da CPU, a partir da qual você pode adicionar réplicas.
Suporta dezenas de milhares de RPS com escalabilidade horizontal entre regiões.
Sem latência adicional mesmo com múltiplas regras de limite de taxa, autenticação e balanceamento de carga em vigor.
Por que isso é importante
Se você está executando cargas de trabalho de IA generativa em escala, ou planejando integrar múltiplos LLMs (OpenAI, Claude, código aberto, etc.), o gateway se torna a base da sua pilha.
O design da TrueFoundry garante:
Você pode rotear e escalar com segurança entre provedores.
Aplicar controles granulares no nível de usuário/equipe.
Manter a observabilidade e a governança em todo o sistema enquanto controla o custo da IA generativa.
Faça tudo isso sem impactar a latência ou a confiabilidade.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.































.webp)



.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




