



.webp)
July 3, 2026
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: May 21, 2026

Blazingly fast way to build, track and deploy your models!
É o hackathon de IA interno da sua empresa, e o agente de codificação de um participante fica preso em um loop de repetição não intencional. Ele continua enviando requisições de contexto longo para um modelo de alto custo por horas.
Como os organizadores distribuíram chaves de provedor brutas para cada participante, não há controles em nível de equipe sobre gastos ou velocidade de requisições. Na manhã de segunda-feira, um fluxo de trabalho descontrolado havia consumido uma grande parte do orçamento compartilhado de LLM e levou a organização a problemas de limite de taxa.
Essa história ressoa porque é plausível. Mas a verdadeira lição é mais ampla: o padrão empresarial correto para um hackathon não é distribuir credenciais de provedor brutas e esperar que as equipes se comportem. É rotear cada requisição através de um gateway governado que pode separar equipes, anexar políticas a metadados e manter a experimentação dentro de um modelo operacional controlado.
TrueFoundry se encaixa perfeitamente nesse padrão porque combina limites de workspace nativos do Kubernetes, indireção de segredos, controles de política cientes de metadados, guardrails de agentes e um ambiente de testes nativo de gateway. A afirmação mais precisa não é que ele garante 'zero vazamentos' ou controle de gastos rígido perfeito sob cada padrão de pico. A afirmação mais forte e defensável é que ele oferece às equipes de plataforma um plano de controle crível para executar hackathons sem transformá-los em eventos de custo e segurança não gerenciados.

A primeira regra de um hackathon seguro é simples: os participantes nunca devem precisar ver as chaves de API brutas do provedor. Uma vez que uma chave é copiada para notebooks, ambientes locais ou arquivos de configuração de agentes, ela se torna um problema de segurança e um problema de faturamento.
O modelo de workspace da TrueFoundry ajuda aqui porque o isolamento de workspace se alinha aos limites de namespace do Kubernetes. Na prática, isso significa que as cargas de trabalho de um workspace são executadas em um namespace diferente das cargas de trabalho de outro workspace, e as credenciais do provedor podem ser expostas através de grupos de segredos e FQNs de segredos, em vez de serem coladas diretamente em manifestos de aplicativos ou arquivos-fonte.
Essa é a arquitetura correta para equipes de hackathon. Dê a cada equipe um workspace, dê às cargas de trabalho acesso apenas aos grupos de segredos de que precisam e mantenha a credencial real do provedor sob controle da plataforma o tempo todo. A experiência do usuário ainda é simples, mas o raio de impacto é menor e auditável.
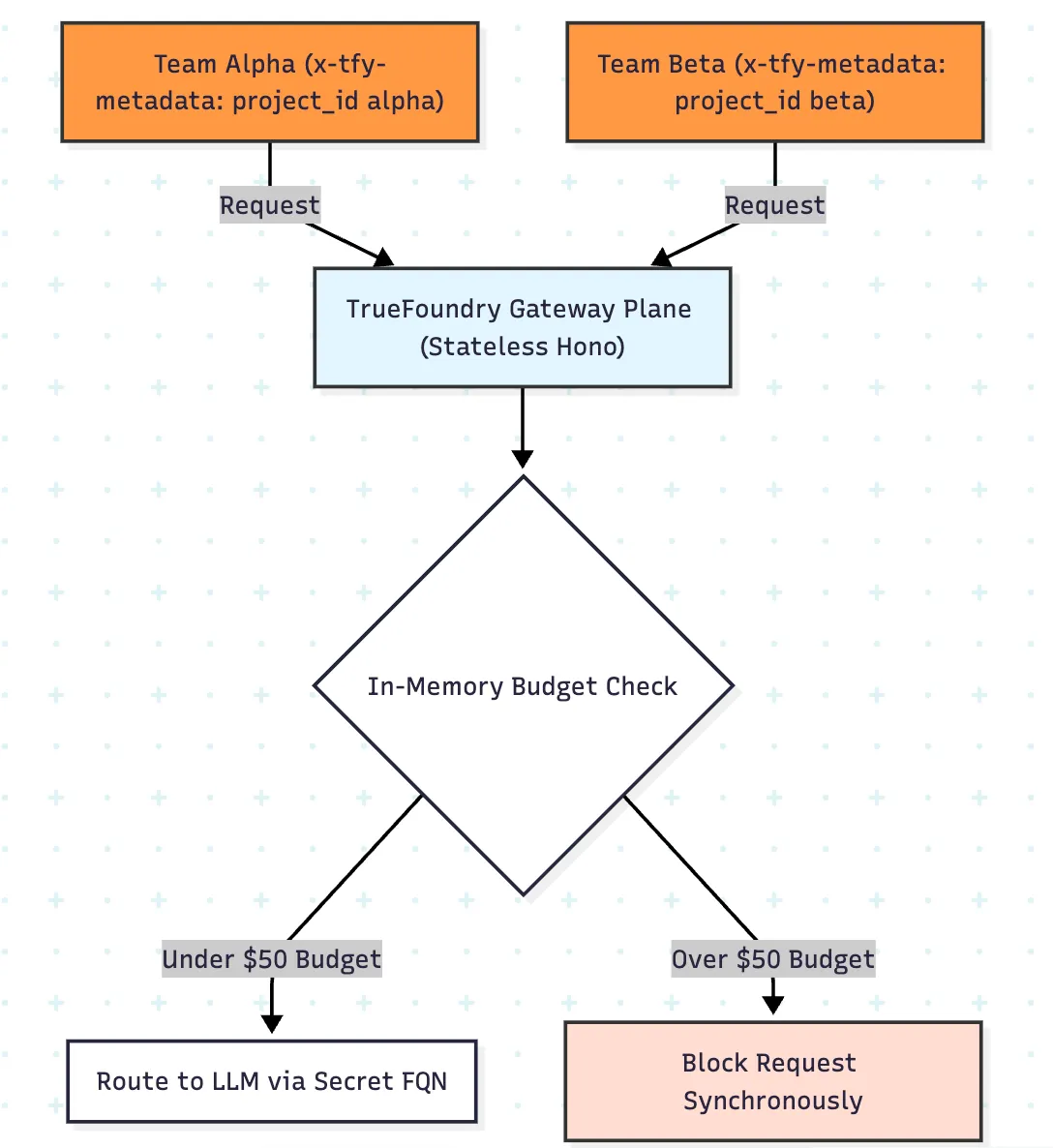
A questão operacional mais importante em um hackathon de IA não é se você pode ver os gastos depois que eles ocorrem. É se a plataforma pode avaliar a política no caminho da requisição antes que uma carga de trabalho descontrolada se torne cara.
O plano de gateway da TrueFoundry avalia autenticação, roteamento, guardrails, limites de taxa e política de orçamento no caminho crítico usando estado em memória, o que permite a aplicação de baixa latência antes da invocação do modelo. Isso é materialmente melhor do que um design onde a única visão de custo confiável chega depois que os logs são processados a jusante.
A parte especialmente útil para hackathons é o escopo de metadados. Em vez de criar manualmente uma regra por equipe, você pode anexar a identidade da equipe em x-tfy-metadata e aplicar políticas dinamicamente com campos como metadata.project_id. Isso significa que uma regra de orçamento e uma regra de limite de taxa podem se desdobrar em contadores isolados e envelopes de gastos por equipe.
Hackathons são onde as equipes experimentam servidores MCP, agentes de chamada de ferramentas, conectores de banco de dados e APIs internas. É exatamente aí que um modelo de segurança tradicional, apenas com LLM, começa a falhar.
O modelo de guardrail da TrueFoundry é especialmente relevante aqui porque expõe quatro pontos de execução: entrada LLM, saída LLM, pré-ferramenta MCP e pós-ferramenta MCP. Isso oferece às equipes de plataforma uma forma mais operacional de governar agentes do que depender de um único filtro genérico na frente do modelo.
A distinção útil é que diferentes riscos surgem em diferentes estágios. A injeção de prompt pode aparecer na entrada. Argumentos de ferramenta inseguros aparecem antes da execução. Registros sensíveis podem aparecer apenas depois que a ferramenta retorna. Um modelo de quatro ganchos permite que você coloque o controle certo no ponto certo do fluxo.
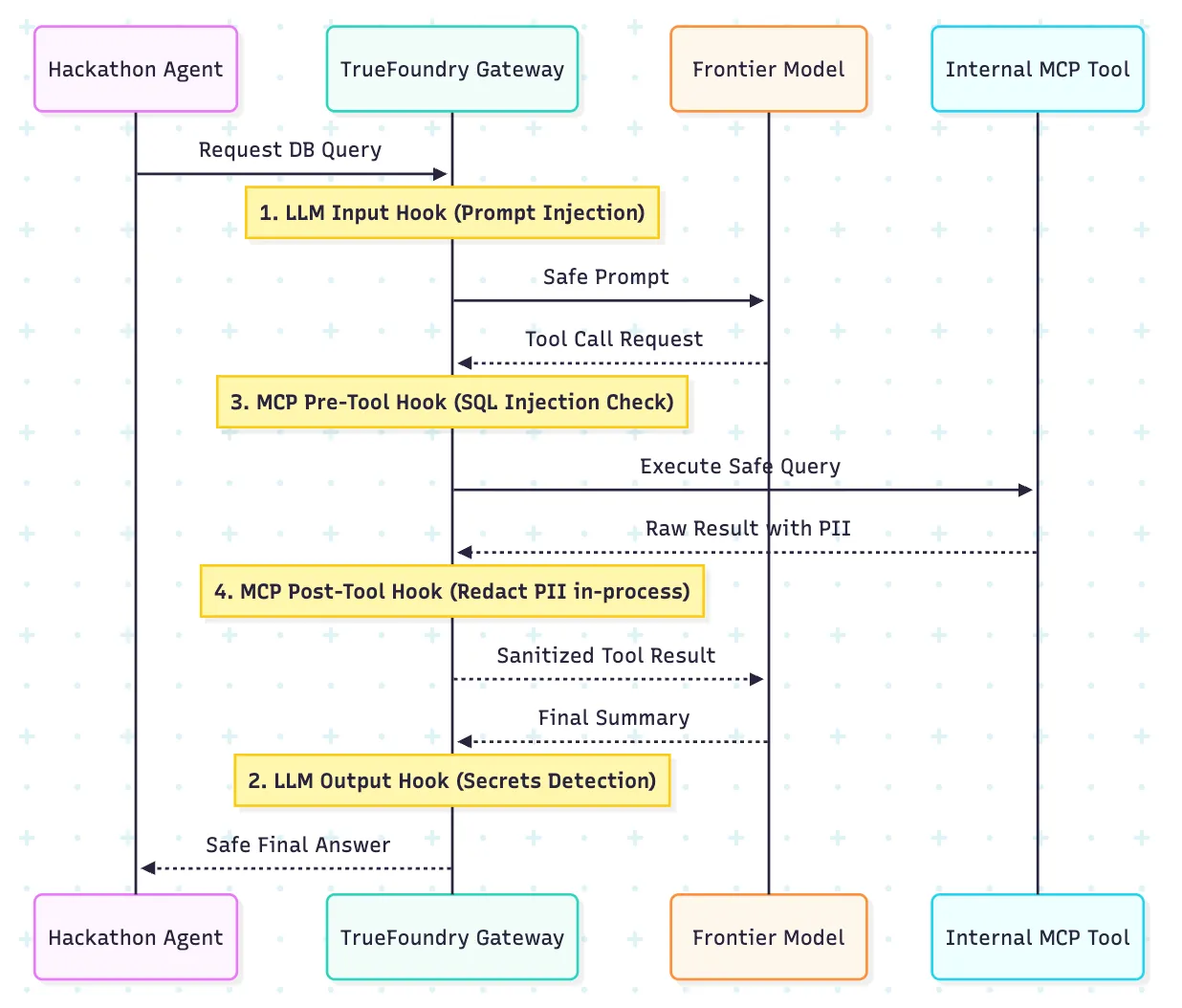
É também aqui que a detecção em processo faz a diferença. Se a varredura de segredos e verificações relacionadas puderem ser executadas dentro do caminho do gateway sem uma dependência externa adicional, o modelo de controle é mais fácil de entender durante um evento ao vivo. Mantenha os guardrails de base comuns a todas as equipes e, em seguida, adicione políticas mais rigorosas para equipes que usam ferramentas ou conjuntos de dados sensíveis.
Um hackathon seguro ainda precisa parecer rápido. Se as equipes precisarem de um tíquete toda vez que quiserem experimentar um prompt, elas contornarão a plataforma. A resposta não é menos controle. A resposta é tornar o caminho controlado o caminho mais fácil.
É aqui que o playground nativo do gateway faz a diferença. O ponto arquitetônico útil é que o tráfego de teste pode fluir através do mesmo plano de gateway usado para políticas de produção, para que as equipes possam validar prompts, roteamento e guardrails em loop, em vez de descobrir o comportamento da política apenas após a implantação.
A experiência do desenvolvedor também melhora quando a plataforma expõe sinais de depuração em nível de resposta. Cabeçalhos como x-tfy-resolved-model e x-tfy-applied-configurations, além de detalhamentos de tempo do servidor, ajudam as equipes a entender o que realmente aconteceu em uma solicitação de teste, em vez de adivinhar se um fallback, guardrail ou regra de roteamento foi acionado.
Leitores corporativos irão contestar imediatamente se uma publicação prometer demais sobre residência de dados. E devem. A afirmação útil não é que cada implantação é magicamente 'isolada'. É que o design de plano dividido permite que as equipes executem o plano de gateway em sua própria infraestrutura, mantendo o caminho crítico para inferência, verificações de política e acesso ao modelo sob um controle operacional mais rigoroso.
A outra metade da história é a observabilidade. Um hackathon é mais fácil de gerenciar quando a equipe da plataforma pode ver rastreamentos, latência e comportamento da política rapidamente. Mas a observabilidade também é uma superfície de governança de dados. Se os dados de prompt ou resposta forem exportados para análise, isso precisa ser uma escolha intencional com os controles de retenção e destino corretos.
A história da residência se fortalece quando você descreve explicitamente o modo de implantação, o comportamento de registro e os caminhos de exportação. Isso gera mais confiança do que dizer 'vazamento zero' e esperar que o leitor não faça perguntas de acompanhamento.
Sim - adicionar um fluxo de trabalho de proprietário explícito é uma boa ideia. Transforma a publicação de um comentário de arquitetura em um guia de execução.
1. Uma semana antes do evento: defina o modelo de controle
Crie um espaço de trabalho por equipe ou por categoria de competição. Decida os modelos permitidos, o caminho do provedor padrão, o orçamento por equipe, o limite de taxa por equipe e quais equipes podem usar ferramentas MCP ou dados internos sensíveis.
2. Antes do início: pré-carregue o caminho seguro
Publique um pequeno kit inicial para os participantes: o endpoint do gateway, o formato de metadados necessário, exemplos de trechos de SDK e um breve guia para o playground. As equipes devem começar pelo caminho governado, não pelos painéis brutos do provedor.
3. No registro: atribua um project_id a cada equipe
Torne o project_id o campo de metadados obrigatório desde o primeiro dia. Isso proporciona uma segmentação de gastos limpa, rastreamento mais claro, revisão de incidentes mais organizada e menos mapeamento manual posteriormente.
4. Durante as horas de desenvolvimento: monitore o evento como um sistema em tempo real
Monitore os gastos por equipe, a pressão do limite de taxa e padrões de rastreamento incomuns. O objetivo é resgatar as equipes cedo, não apenas analisar falhas mais tarde.
5. Para equipes de agentes: exija revisão de ferramentas antes de acesso amplo
Se uma equipe precisar de acesso ao banco de dados, servidores MCP ou APIs internas, mova-a para um perfil de proteção mais rigoroso antes de habilitar essas ferramentas. Experimentos de agentes devem conquistar mais confiança, não começar com ela.
6. Antes das demonstrações: exigir uma verificação final no playground
Cada equipe deve validar seu fluxo final através do playground ou da superfície de teste oficial. Isso detecta metadados ausentes, roteamento inesperado e surpresas de proteção antes da demonstração.
7. Após o evento: transformar observações em padrões da plataforma
Revise os rastreamentos, incidentes de orçamento, chamadas bloqueadas e perguntas de suporte. Em seguida, converta as melhores práticas em modelos de espaço de trabalho padrão, trechos de código e linhas de base de políticas para o próximo hackathon.
A tese central da publicação original ainda é válida: se você está organizando um hackathon de IA empresarial, o padrão mais seguro não é distribuir chaves de provedor brutas. É rotear as solicitações através de um gateway que pode separar equipes, medir gastos, controlar o throughput e governar os fluxos de trabalho dos agentes.
O que torna a versão revisada melhor é que ela diz isso de uma forma que um comprador cético pode acreditar. A história de hackathon mais forte da TrueFoundry não é uma promessa vaga de segurança total. É uma combinação prática de isolamento de espaço de trabalho, indireção de segredos, política com escopo de metadados, hooks de agente governados, controles de caminho de solicitação e um playground que ajuda as equipes a testar através da mesma superfície de política pela qual elas farão o deploy.
Isso é o suficiente. Seus hackers ainda podem construir o futuro. Suas equipes de plataforma, segurança e finanças simplesmente não precisam perder um fim de semana no processo.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.






.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




