



.webp)
July 3, 2026
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: June 26, 2026
Blazingly fast way to build, track and deploy your models!
As ferramentas de codificação com IA fazem agora parte do desenvolvimento diário. Desenvolvedores usam produtos como Claude Code, Cline, Cursor, Gemini CLI, OpenAI Codex CLI, Qwen Code CLI, Roo Code e Goose para gerar código, refatorar, depurar e explicar grandes bases de código diretamente do editor ou terminal. O problema na maioria das empresas não é a adoção. O problema é a governança. Cada ferramenta pode se comunicar com um ou mais fornecedores de modelos. Cada ferramenta frequentemente armazena chaves localmente. As equipes rapidamente acabam com dezenas de pontos de entrada não gerenciados para modelos externos. Isso cria um risco real em relação a quais modelos são aprovados, para onde o código e o contexto são enviados, como os gastos são atribuídos e como os incidentes são investigados. Também dificulta a confiabilidade, pois o roteamento e os mecanismos de fallback são inconsistentes entre as ferramentas.
Se você tentar resolver isso manualmente, geralmente acabará construindo um proxy interno para o qual cada IDE e CLI aponta. Esse proxy precisa de autenticação, autorização, listas de permissão de modelos aprovados, roteamento de provedores, logs de auditoria, limitação de taxa, controles de orçamento e observabilidade. Ele também precisa ser compatível com as APIs que essas ferramentas esperam. Muitas ferramentas usam uma API compatível com OpenAI, mas também têm peculiaridades em relação à nomenclatura de modelos e comportamentos especiais que você precisa gerenciar.
Aqui está um pequeno exemplo fictício que mostra por que isso se torna um trabalho de engenharia real. Não está pronto para produção. Destina-se apenas a mostrar a dimensão do problema.
from fastapi import FastAPI, Request, HTTPException
import time
import httpx
app = FastAPI()
APPROVED_MODELS = {
"gpt-4o": {"provider": "openai", "target": "gpt-4o"},
"claude-3-5-sonnet": {"provider": "anthropic", "target": "claude-3-5-sonnet"},
}
OPENAI_URL = "https://api.openai.com/v1/chat/completions"
ANTHROPIC_URL = "https://api.anthropic.com/v1/messages"
def verify_token(auth_header: str) -> dict:
# Na realidade, esta é uma validação JWT contra Okta ou seu IdP.
if not auth_header or not auth_header.startswith("Bearer "):
raise HTTPException(status_code=401, detail="missing token")
return {"user": "alice", "team": "platform"}
@app.post("/v1/chat/completions")
async def chat_completions(req: Request):
user_ctx = verify_token(req.headers.get("authorization"))
body = await req.json()
model = body.get("model")
if model not in APPROVED_MODELS:
raise HTTPException(status_code=403, detail="modelo não aprovado")
route = APPROVED_MODELS[model]
started = time.time()
async with httpx.AsyncClient(timeout=60) as client:
if route["provider"] == "openai":
upstream = await client.post(
OPENAI_URL,
headers={"Authorization": "Bearer " + "UPSTREAM_OPENAI_KEY"},
json={**body, "model": route["target"]},
)
else:
# Você também precisaria de transformações de requisição e resposta aqui.
upstream = await client.post(
ANTHROPIC_URL,
headers={"x-api-key": "UPSTREAM_ANTHROPIC_KEY"},
json={"model": route["target"], "messages": body.get("messages", [])},
)
latency_ms = int((time.time() - started) * 1000)
# Na realidade, você emitiria rastreamentos OpenTelemetry e logs estruturados aqui.
print("llm_request", {"user": user_ctx["user"], "model": model, "latency_ms": latency_ms})
return upstream.json()
Mesmo nesta versão simplificada, você pode ver peças ausentes. Você ainda precisa de transformações robustas entre fornecedores, suporte a streaming, retentativas, fallbacks, cabeçalhos de passagem seguros, escopo de locatário e equipe, e logs de auditoria duráveis. Você também precisa de um sistema de configuração que se adapte a diferentes equipes.
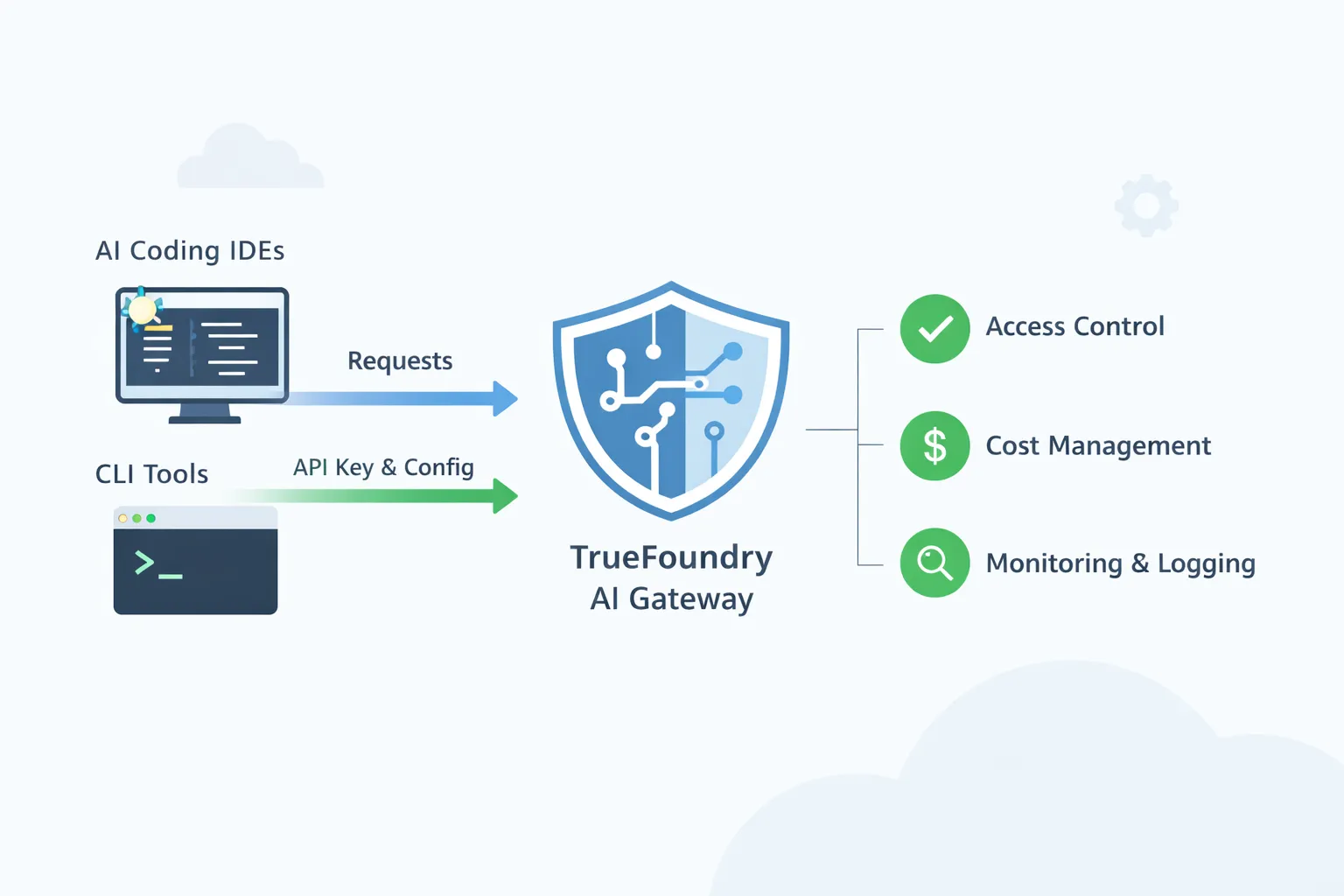
O TrueFoundry AI Gateway foi projetado para ser esse ponto de controle compartilhado. IDEs e CLIs continuam usando os fluxos de trabalho que os desenvolvedores já gostam, mas o tráfego é roteado através de um único gateway governado. O gateway se torna o local onde as equipes de plataforma impõem o acesso aprovado ao modelo, aplicam políticas e obtêm visibilidade completa do uso.
Um tema central nos guias de IDE é simples. Você obtém a URL base e o nome do modelo no playground do TrueFoundry AI Gateway. Em seguida, você configura a IDE ou CLI para usar essa URL base e um token TrueFoundry.
A maioria das IDEs e ferramentas de desktop de codificação de IA pode ser apontada para um único endpoint compatível com OpenAI. O TrueFoundry AI Gateway fornece esse endpoint. Você começa no playground do Gateway e copia o snippet unificado. Este snippet fornece a URL base e o nome do modelo que você deve usar. Em seguida, você abre as configurações da IDE e seleciona uma opção de provedor que suporte uma URL base personalizada. Muitas ferramentas chamam isso de compatível com OpenAI. Você cola a URL base do Gateway. Você cola um token TrueFoundry como chave de API. O token pode ser um token pessoal para um desenvolvedor ou um token de conta virtual para uso compartilhado ou automatizado. A TrueFoundry documenta ambas as opções e recomenda o token de conta virtual para uso em estilo de produção. Leia mais aqui
Algumas IDEs funcionam melhor quando veem nomes de modelos padrão curtos, como gpt 4o. Os nomes de modelos TrueFoundry são frequentemente totalmente qualificados. A correção recomendada é definir uma regra de roteamento ou balanceamento de carga no Gateway para que a IDE continue usando o nome curto enquanto o Gateway o mapeia para o modelo de destino totalmente qualificado. Cursor e Codex documentam esse padrão porque possuem lógica interna vinculada a nomes de modelos padrão. Documentação do Cursor
Também pode haver restrições de rede. O Cursor documenta que seu fluxo de solicitação pode envolver servidores Cursor. Isso significa que a URL do Gateway deve ser acessível a partir da infraestrutura do Cursor. Na prática, o endpoint do Gateway precisa de acessibilidade pública para que o Cursor funcione conforme descrito no guia.
As ferramentas CLI geralmente se integram através de variáveis de ambiente ou de um arquivo de configuração local. Para CLIs compatíveis com OpenAI, o padrão comum é definir OPENAI_BASE_URL para o endpoint do TrueFoundry Gateway e definir OPENAI_API_KEY para um token TrueFoundry. A TrueFoundry documenta isso como uma abordagem de autenticação suportada para o Gateway. Leia mais: Autenticação
Algumas CLIs usam variáveis específicas do provedor. A CLI do Gemini usa uma URL base do Gemini e uma chave de API do Gemini. O guia TrueFoundry mostra como definir GOOGLE_GEMINI_BASE_URL para uma URL de proxy Gemini da TrueFoundry e GEMINI_API_KEY para um token TrueFoundry, para que cada solicitação flua através do Gateway. Leia mais: Gemini-cli
Outras CLIs dependem de um arquivo JSON de configurações. O Claude Code é configurado através de um arquivo settings.json que define valores de ambiente para a URL base e cabeçalhos de autenticação. O guia TrueFoundry mostra ANTHROPIC_BASE_URL apontando para o Gateway e usa um token Bearer em cabeçalhos personalizados para que o tráfego do Claude Code seja governado através do Gateway. Leia mais: Claude code
Algumas ferramentas também precisam do mapeamento de nomes padrão mencionado anteriormente. O guia da CLI do Codex explica que o Codex espera nomes de modelo padrão e pode apresentar mau funcionamento com nomes totalmente qualificados. Ele recomenda usar o roteamento do Gateway para que você chame gpt 5 na CLI enquanto o Gateway roteia para o modelo totalmente qualificado correto nos bastidores. Leia mais: Codex
A aprovação de modelos e o controle de acesso são as necessidades de governança mais básicas quando as ferramentas de codificação de IA se espalham por uma empresa. Um desenvolvedor pode instalar o Cursor ou o Cline em minutos e apontá-lo para qualquer provedor de modelo. Sem um gateway, a empresa acaba com muitos caminhos não gerenciados onde o contexto do código e os prompts podem sair da rede usando chaves pessoais. Com o TrueFoundry AI Gateway, você cria um pequeno catálogo aprovado de modelos permitidos para uso em codificação e mapeia esses modelos para equipes ou grupos de usuários. Os desenvolvedores continuam usando o mesmo IDE que preferem, mas cada solicitação passa pelo gateway, de modo que uma solicitação para um modelo não aprovado é bloqueada. Isso também possibilita separar o acesso por nível de risco. Um engenheiro júnior pode ter acesso a um modelo mais barato para edições rápidas, enquanto um engenheiro sênior ou uma equipe de incidentes de produção pode acessar um modelo mais robusto para depuração difícil. O importante é que a aprovação seja imposta centralmente, em vez de depender de cada desenvolvedor seguir um documento de política.
A responsabilidade pelos custos torna-se importante porque as ferramentas de codificação de IA podem gerar grandes volumes de tokens sem que ninguém perceba. Um único desenvolvedor usando um agente que itera sobre uma base de código pode criar centenas ou milhares de chamadas em um curto período. Sem um gateway, os gastos são distribuídos entre chaves pessoais e contas de fornecedores, de modo que o setor financeiro vê uma fatura, mas não consegue identificar qual equipe ou aplicativo a gerou. Com um gateway, você pode emitir tokens baseados em identidade e exigir que cada sessão de IDE ou CLI se autentique usando uma identidade de usuário ou de serviço. Isso permite atribuir o uso a uma pessoa, a uma equipe ou a uma ferramenta interna. Uma vez que a atribuição existe, os controles se tornam práticos. Você pode definir orçamentos para uma equipe por mês e pode definir limites de taxa que evitam loops acidentais e descontrolados. Se uma ferramenta começar a enviar solicitações em massa, o gateway pode limitá-la em vez de deixá-la consumir o orçamento silenciosamente.
A resposta a incidentes e a auditoria são onde as equipes de plataforma sentem a diferença no dia a dia. Quando um desenvolvedor diz que o assistente está lento ou falhando, é difícil depurar se o tráfego está indo diretamente de um laptop para um fornecedor. Você pode não saber se o problema é o fornecedor, a rede, um nome de modelo mal configurado ou uma configuração específica da ferramenta. Quando as solicitações passam pelo gateway, a equipe de plataforma pode consultar as métricas e logs do gateway para ver qual modelo foi chamado, como estava a latência, quais erros ocorreram e se as falhas estão isoladas em um provedor ou uma região. Esta é também a base para os requisitos de auditoria. As equipes de segurança e conformidade frequentemente perguntam para onde o contexto do código foi enviado e quem teve acesso. Um gateway pode manter um registro de quais destinos foram usados e quem os invocou. Ele também pode suportar políticas que reduzem o risco, como mascarar strings sensíveis antes que as solicitações cheguem a provedores externos ou restringir certas equipes de enviar prompts para endpoints externos.
A confiabilidade durante problemas com provedores é importante porque os provedores de modelos têm lentidões e timeouts periódicos. As ferramentas de codificação de IA são particularmente sensíveis porque são interativas. Alguns timeouts podem fazer a ferramenta parecer quebrada e os desenvolvedores mudarão para o que funcionar. Muitos IDEs também assumem certos nomes de modelo. O Cursor e ferramentas semelhantes geralmente funcionam melhor quando o nome do modelo se parece com um nome padrão no estilo OpenAI. Se você mudar de provedor, normalmente precisaria alterar a configuração de cada desenvolvedor. Com o roteamento do gateway, você pode manter o mesmo nome de modelo nas configurações do IDE e alterar para o que ele mapeia nos bastidores. Se um provedor estiver com timeout, você pode rotear para outro provedor ou para outra conta ou região. O desenvolvedor continua usando a mesma configuração do IDE e simplesmente vê a ferramenta continuar funcionando. Isso também é útil quando você deseja lançar um novo modelo. Você pode gradualmente desviar o tráfego para o novo modelo, mantendo a experiência do usuário estável, e pode reverter rapidamente se a qualidade ou a latência não forem aceitáveis.
IDEs de codificação de IA tornam os desenvolvedores mais rápidos. As empresas precisam do mesmo nível de governança que já aplicam a sistemas de controle de versão e CI. O caminho prático é centralizar o controle sem forçar os desenvolvedores a mudar de ferramentas. O TrueFoundry AI Gateway foi construído para atuar nesse ponto de controle. Os guias de integração para Claude Code, Cline, Cursor, Gemini CLI, OpenAI Codex CLI, Qwen Code CLI, Roo Code e Goose seguem todos o mesmo princípio. Mantenha o fluxo de trabalho do desenvolvedor. Centralize a política, a visibilidade e o controle no gateway.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.






.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




