



.webp)
July 3, 2026
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: May 21, 2026

Blazingly fast way to build, track and deploy your models!
50 Perguntas para Fazer a Cada Fornecedor em 2026
As avaliações de plataformas de IA empresarial falham de maneiras previsíveis. A demonstração do fornecedor é executada com base em um prompt de teste selecionado. O slide de preços deles usa suposições de 5.000 tokens por chamada que não correspondem à sua carga de trabalho real. O diagrama de arquitetura de segurança que eles mostram é para um modo de implantação sobre o qual você não perguntou. A capacidade de MCP que eles afirmam está disponível “em nossa próxima versão”. Seis semanas depois, você está assinando um contrato para um produto que se encaixa em 70%, e sua equipe de plataforma passa o período do contrato preenchendo os outros 30% com trabalho personalizado.
Uma RFP pontuada muda a dinâmica. Cada fornecedor responde às mesmas perguntas, por escrito, antes de qualquer demonstração. Suas não-respostas (uma pergunta evitada, uma capacidade que “requer nosso parceiro de integração”, uma alegação de conformidade que não resiste a uma pergunta de escopo) vêm à tona no registro escrito, onde não podem ser reformuladas em uma chamada de acompanhamento. O mesmo registro responsabiliza o fornecedor quando a realidade pós-assinatura começa a divergir do discurso pré-assinatura, que é a queixa de aquisição mais comum na renovação do primeiro ano.
Três coisas levam este modelo além do que as estruturas genéricas de aquisição empresarial já cobrem. Governança de MCP, a pilha de protocolos que seus agentes de IA usarão para se comunicar com ferramentas, onde a maioria dos produtos de gateway de IA ainda está adicionando controle de acesso para o qual não foram projetados. Controles de IA Agêntica, a correlação de rastreamento, atribuição de custos e limites de isolamento que transformam uma tarefa de agente de várias etapas em uma unidade depurável, faturável e governável, em vez de uma névoa de chamadas de LLM desconectadas. Conformidade específica de IA, incluindo paridade de campos de log de auditoria entre invocações de LLM e ferramentas, respostas estruturadas de residência de dados que consideram o roteamento do provedor de modelo entre regiões, e os controles arquitetônicos BAA que tornam a aplicação do HIPAA real em vez de burocracia.
Use isto como ponto de partida. Ajuste os pesos ao seu ambiente. Envie o mesmo documento para cada fornecedor em sua lista restrita. A equipe de soluções da TrueFoundry está preparada para responder a todas as 50 perguntas por escrito, com evidências, como parte da avaliação empresarial formal.
Agora, às perguntas em si.

Figura 1. Arquitetura de referência de plano dividido: plano de controle e plano de computação separados por um limite apenas de metadados, com um IdP alimentando a identidade em ambos.
A ordem das operações importa mais do que as próprias perguntas. A maioria das avaliações falhas pula a primeira etapa: obter respostas escritas para o modelo completo antes que qualquer fornecedor possa fazer uma demonstração. As demonstrações são para verificação de alegações escritas, não para descoberta. Se a primeira comunicação de um recurso por parte de um fornecedor vier de um slide, você entregou a ele o controle da narrativa da avaliação.
Envie o modelo a todos os fornecedores da sua lista restrita simultaneamente, com um prazo de duas semanas para a resposta escrita. Use as respostas para pontuar com base em uma rubrica ponderada. Somente após a pontuação você agenda as demonstrações, e nessas demonstrações o trabalho da sua equipe de plataforma é verificar se o que está por escrito corresponde ao que está em execução. Trate qualquer alegação que surgir na demonstração, mas que não estava na resposta escrita, como uma descoberta a ser investigada, e não como um recurso a ser pontuado positivamente.
Algumas especificidades para executar isso bem:
Se você já participou de uma revisão de segurança onde o escopo de conformidade do fornecedor cobria apenas a opção SaaS que você não planejava usar, você sabe o custo de pular a etapa da rubrica. Uma RFP pontuada força a revelação desse detalhe antes do contrato.
Segurança e conformidade é onde a maioria das avaliações de plataformas de IA desmorona na segunda reunião. Não porque os fornecedores não tenham certificações. A maioria tem SOC 2 Tipo II em algum lugar. O modo de falha é o alinhamento: o escopo da certificação, os controles arquitetônicos que a implementam e o modo de implantação que você realmente está comprando não correspondem. Um SOC 2 cobrindo o portal de marketing do fornecedor não serve para um gateway de IA que processa PHI on-prem. Um BAA que existe em formato de modelo, mas não descreve como o PHI é isolado no plano de dados, é burocracia, não um controle. As perguntas abaixo forçam o alinhamento entre o escopo da certificação e a realidade arquitetônica que impede que as respostas “somos certificados” tenham um peso que não deveriam.
O outro modo de falha que vale a pena mencionar cedo: fornecedores que respondem a perguntas de segurança de forma abstrata porque sua arquitetura concreta é dividida entre dois produtos com diferentes posturas de controle. Sua versão on-premise é limitada em recursos e não é certificada separadamente. Sua versão SaaS possui as certificações, mas não se encaixa no seu ambiente. Identifique isso fazendo a mesma pergunta duas vezes, especificando o modo de implantação em cada vez. Se as respostas forem diferentes, você está diante de dois produtos comercializados como um só.
Pontue esta seção sem piedade.
Uma implantação de plano dividido onde o plano de dados (o proxy que lida com prompts, respostas de modelos, embeddings, invocações de ferramentas MCP) é executado inteiramente na VPC do cliente e nunca abre uma conexão de saída para a infraestrutura do fornecedor para cargas úteis de solicitação. O plano de controle (configuração, configurações de RBAC, painéis) pode ser executado na infraestrutura do fornecedor ou na infraestrutura do cliente, dependendo do modo de implantação, mas troca apenas metadados. Logs de auditoria, dados de prompt-resposta e embeddings são armazenados em armazenamento de blob controlado pelo cliente (S3, GCS, Azure Blob), não em bancos de dados gerenciados pelo fornecedor. Se a “implantação VPC” do fornecedor ainda envia prompts para um agregador de logs gerenciado pelo fornecedor, isso é uma implantação SaaS com uma embalagem diferente.
Verifique a seção Descrição do Sistema para a nomeação explícita dos modos de implantação cobertos. Procure por linguagem como “o ambiente SaaS multi-tenant hospedado em [nuvem]” versus “os componentes de gateway e plano de controle implantados pelo cliente”. Se a descrição nomear apenas um, a certificação cobre apenas um. Verifique os Critérios de Serviços de Confiança cobertos. A Segurança é a base, mas Disponibilidade, Confidencialidade e Integridade de Processamento são importantes para cargas de trabalho de IA que lidam com dados regulamentados. Um SOC 2 cobrindo apenas Segurança é apenas metade da história.
A plataforma obtém as chaves do provedor de modelo do Vault ou Secrets Manager do cliente na inicialização do gateway ou sob demanda, usando uma função IAM gerenciada pelo cliente, com referências de chave (não os valores das chaves) armazenadas na configuração da plataforma. A rotação é uma operação do Vault: reescreva a chave no Vault, o gateway obtém o novo valor na próxima leitura ou em um intervalo de atualização configurável. A plataforma nunca persiste chaves de provedor em repouso. Se a resposta do fornecedor for “você carrega as chaves em nossa interface de administração e nós as armazenamos criptografadas”, esse é um modelo de segurança diferente (e mais fraco). As chaves agora estão na infraestrutura do fornecedor, mesmo em uma implantação “VPC”.
{
"event_type": "llm_inference",
"timestamp": "2026-04-28T14:22:31.482Z",
"request_id": "req_01H8X2YZ...",
"trace_id": "4bf92f3577b34da6a3ce929d0e0e4736",
"user": {
"id": "u_4821",
"email": "ana@company.com",
"team": "applied-ml"
},
"application": {
"id": "app_chat_support",
"env": "prod"
},
"model": {
"provider": "anthropic",
"id": "claude-sonnet-4-6",
"version": "20260217"
},
"tokens": {
"input": 1842,
"output": 619,
"cached": 1200
},
"latency_ms": {
"ttft": 312,
"total": 2180
},
"cost_usd": 0.01443,
"policy": {
"guardrails_evaluated": [
"pii",
"content_filter"
],
"decision": "allow"
},
"status": "success"
}O log de invocação da ferramenta MCP deve ter paridade de campos para as dimensões compartilhadas (timestamp, request_id, trace_id, user, application, latency_ms, status, policy decision) além dos campos específicos da ferramenta:
{
"event_type": "mcp_tool_invocation",
"timestamp": "2026-04-28T14:22:32.014Z",
"request_id": "req_01H8X2YZ...",
"trace_id": "4bf92f3577b34da6a3ce929d0e0e4736",
"user": {
"id": "u_4821",
"email": "ana@company.com",
"team": "applied-ml"
},
"application": {
"id": "app_chat_support",
"env": "prod"
},
"mcp_server": {
"id": "github-prod",
"version": "1.4.2"
},
"tool": {
"name": "github.create_issue",
"schema_version": "v2"
},
"parameters_hash": "sha256:7c8b...a31e",
"response_size_bytes": 412,
"latency_ms": 528,
"policy": {
"rules_evaluated": [
"repo_allowlist",
"rate_limit"
],
"decision": "allow"
},
"status": "success"
}Observe o mesmo trace_id em ambos: a chamada LLM e a invocação MCP se correlacionam a uma única solicitação do usuário, o que é a resposta concretizada à pergunta 8 da Seção 4. Faça o hash dos parâmetros em vez de registrá-los em texto puro. O registro completo de parâmetros é um risco de vazamento de dados em ambientes regulamentados. Se o log MCP de exemplo do fornecedor estiver faltando policy.decision, trace_id ou atribuição de usuário, a governança MCP é um relatório post-hoc, não uma aplicação.

Figura 2. Fluxo de dados do log de auditoria: paridade de campos entre eventos de inferência LLM e eventos de invocação de ferramenta MCP, ambos correlacionados por um trace_id.
“Criptografado em repouso” é universal. De quem é a chave que está criptografando é o controle real. Em uma implantação auto-hospedada, chaves controladas pelo cliente são alcançáveis porque os armazenamentos de dados estão na conta do cliente; em uma implantação SaaS, chaves controladas pelo cliente são uma capacidade do lado do fornecedor que precisa ser projetada. Faça a pergunta com o modo de implantação especificado.
Para implantações auto-hospedadas, “disponibilidade de patch” significa uma versão marcada que a equipe de plataforma do cliente pode implantar. “Janela de aplicação pelo cliente” é o SLA que o cliente assume internamente. Se o fornecedor propõe uma janela de 30 dias para o cliente aplicar patches para CVEs críticos, é muito tempo para ficar exposto; recuse.
A maioria das aquisições empresariais falha na implantação. A plataforma parece ótima na demonstração SaaS, então a revisão de segurança revela três coisas que a bloqueiam: conectividade de saída para a infraestrutura do fornecedor para telemetria, um banco de dados de configuração hospedado na nuvem do fornecedor e um plano de controle que está fortemente acoplado a uma região de nuvem específica. Quando essas restrições se tornam visíveis, você já negociou o preço do produto errado, e o caminho a seguir é renegociar a partir de uma posição de custo irrecuperável ou aceitar uma implantação que cria dívida de conformidade.
Esta seção revela as restrições de implantação antecipadamente. Os fornecedores que podem responder a isso claramente são aqueles que já implantaram em ambientes como o seu. Os fornecedores que precisam de uma chamada de descoberta para responder à Seção 2 não o fizeram, e você estará fazendo a engenharia de integração na chamada de descoberta pela qual você está pagando a eles.
Observe as respostas com atenção.
┌──────────────────────────────────────────────────────┐
│ Customer VPC (one region, two AZs for HA) │
│ │
│ [ALB / NLB] │
│ │ │
│ ├──> Gateway pods (3+ replicas, HPA enabled) │
│ │ ↕ reads keys from │
│ │ [Secrets Manager / Vault] │
│ │ ↕ writes audit + metrics to │
│ │ [S3 / GCS / Azure Blob] │
│ │ ↕ reads config from │
│ │ [Postgres (HA, multi-AZ)] │
│ │ │
│ └──> egress to: model provider APIs, │
│ MCP servers (in-VPC or │
│ allowlisted external) │
│ │
│ [Control plane endpoint] ──> metadata only, │
│ (vendor or self-hosted) no payload data │
└──────────────────────────────────────────────────────────┘
Dimensionamento de ordem de magnitude para ~500 RPS sustentados: 3 a 4 réplicas de gateway com 2 vCPU / 4 GB de RAM cada, Postgres com 4 vCPU / 16 GB de RAM e 100 GB de SSD, armazenamento de blob escalado com retenção (uma retenção de 90 dias a 10 KB/entrada de log e 500 RPS é de aproximadamente 1,2 TB). O fornecedor deve apresentar números como estes por escrito antes da assinatura, e não "depende da carga de trabalho".

Figura 3. Um plano de controle gerenciando planos de computação em AWS, Azure, GCP e Kubernetes on-premise simultaneamente, cada um com seu próprio limite de residência de dados.
Qualquer coisa pior do que isso para uma configuração de produção multi-região deve vir com uma explicação por escrito. "Não suportamos multi-região" é aceitável de um pequeno fornecedor; "suportamos, mas não nos comprometemos com o RTO" não é.
Toda página de produto de gateway de IA é igual: API unificada, roteamento inteligente, controle de custos, observabilidade. Os detalhes por trás dessas palavras são o que separa um gateway que você pode executar em produção de um proxy simples com um site de marketing. "Roteamento inteligente" pode significar desde um round-robin estático entre dois modelos até uma política de cascata real com tetos de custo, correspondência de capacidade e cadeias de fallback. "Controle de custos" pode significar um painel que mostra a fatura de ontem, ou pode significar orçamentos de tokens rígidos que realmente retornam um 429 para a aplicação quando uma equipe atinge seu limite.
As perguntas nesta seção forçam a obtenção dos detalhes. Rejeite respostas que apenas repetem o material de marketing. O fornecedor que diz "suportamos roteamento inteligente" sem descrever a linguagem das regras, o comportamento em cascata, o tratamento de falhas e a integração orçamentária não tem roteamento. Eles têm um sinalizador de configuração.
Faça-os provar que a arquitetura existe.
route: chat-support
match:
application: app_chat_support
team: applied-ml
strategy: cascade
cascade:
- model: claude-sonnet-4-6
provider: anthropic
conditions: { max_input_tokens: 1000000 }
- model: gpt-5.5
provider: openai
conditions: { fallback_on: ["rate_limit", "5xx"] }
- model: claude-haiku-4-5
provider: anthropic
conditions: { fallback_on: ["all_above_failed"] }
guardrails: [pii, content_filter]
budget_ref: budget_applied_ml_q2
A aplicação envia uma requisição padrão compatível com OpenAI. O gateway seleciona o provedor com base na regra, segue a cascata em caso de falha, anexa a referência orçamentária para atribuição de custos e aplica guardrails diretamente. Nenhuma alteração no código da aplicação é necessária quando a rota é reconfigurada. Se o “roteamento inteligente” do fornecedor exige alterações no nível da aplicação para cada variante, isso não é roteamento no nível do gateway. É um wrapper.
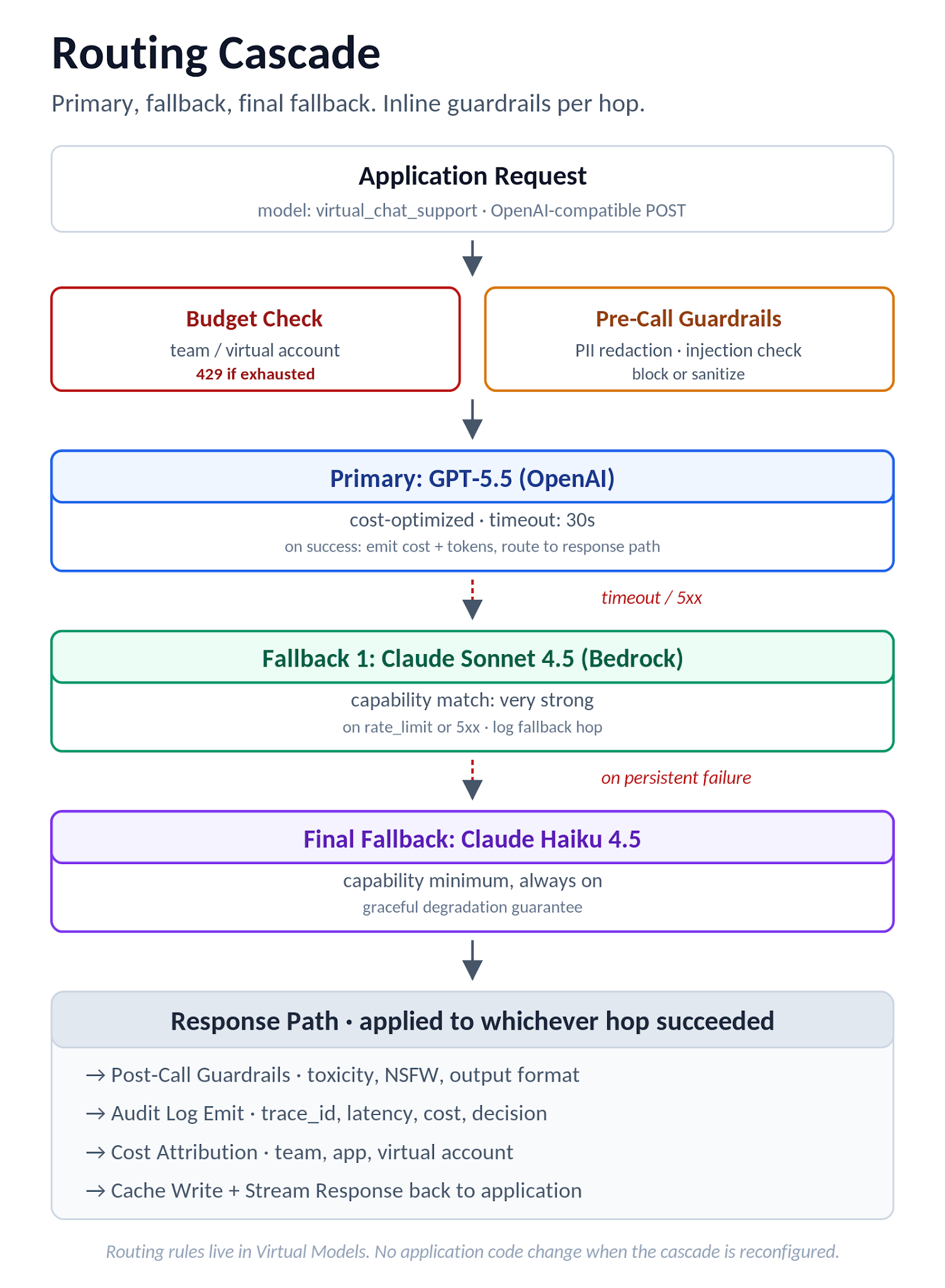
Figura 4. Fluxo da cascata de roteamento: verificação de orçamento, guardrails pré-chamada, tentativa de modelo primário, cadeia de fallback e um caminho de resposta unificado com auditoria, custo e cache.
Esta seção é onde a maioria dos produtos de gateway de IA terá dificuldades, porque a maioria deles foi projetada para a era das chamadas de LLM e antecede o momento em que o MCP começou a aparecer em ambientes empresariais reais. MCP não é “mais observabilidade para chamadas de ferramenta”. É um plano de governança separado: um registro de servidores aprovados, um ponto de aplicação para quais ferramentas cada função pode invocar, logs de auditoria que correspondem aos logs de chamadas de LLM em cobertura de campo, e um motor de políticas que é executado no momento da invocação, em vez de como um relatório post-hoc. Fornecedores que não possuem este plano tentarão responder às perguntas da Seção 4 com descrições de observabilidade de LLM. Fique atento à substituição. Quanto mais direta a resposta, mais real a capacidade.
O padrão a esperar: um fornecedor robusto de gateway de IA descreverá o gateway MCP como uma superfície de produto separada, com seu próprio registro, seu próprio mapeamento RBAC, seu próprio esquema de log de auditoria e sua própria linguagem de política. Um fornecedor mais fraco o descreverá como “observabilidade estendida” sobre sua pilha de observabilidade de LLM existente, o que é um indício de que a governança é escassa. Avalie a Seção 4 especificamente; não a inclua na Seção 3.
Leia cada resposta em busca de linguagem de aplicação direta.
policy: github-write-restriction
applies_to:
mcp_server: github-prod
tool_pattern: "github.*"
rules:
- match:
tool: github.delete_repo
action: deny
reason: "Destructive operations require change-management ticket"
- match:
tool: github.create_pr
user.team: ["junior-engineers"]
parameters.target_branch: "main"
action: deny
reason: "Direct-to-main PRs require senior-engineer approval"
- match: {tool: "github.*"}
action: allow
log_level: full
As atualizações para esta regra devem se propagar para o gateway em segundos (push de configuração, não redeploy). Se a resposta do fornecedor for "as políticas são avaliadas pelo próprio servidor MCP", isso não é uma política imposta pelo gateway. É uma política imposta pelo servidor, e você precisará manter a paridade de políticas em todos os servidores MCP no catálogo. Outro problema.
traceparent: 00-4bf92f3577b34da6a3ce929d0e0e4736-00f067aa0ba902b7-01
└─ trace-id (32 hex) └─ span-id (16 hex)
O gateway preserva o trace-id em cada chamada downstream (provedor LLM, servidor MCP, salto secundário do gateway) injetando-o nos cabeçalhos de saída e emite cada chamada como um span sob o mesmo trace-id. No Datadog, Grafana Tempo ou Jaeger, o resultado é uma cascata única mostrando: solicitação do usuário → chamada LLM (claude-sonnet-4-6, 2.1s) → chamada de ferramenta (github.create_issue, 528ms) → chamada LLM (formatador de saída, 380ms) → resposta. Sem isso, o mesmo fluxo aparece como quatro entradas não relacionadas e a análise da causa raiz se torna um palpite.

Figura 5. Arquitetura do Gateway MCP: um único endpoint para ferramentas e agentes de desenvolvedor, com camadas de autenticação, registro, política e log entre clientes e servidores MCP.
A diferença entre uma plataforma de IA que monitora bem e uma que observa bem se manifesta nas perguntas que sua equipe financeira faz no final do mês. O monitoramento informa que a fatura aumentou 40 por cento. A observabilidade informa que o chatbot da equipe de marketing começou a entrar em loop devido a um caso de borda na janela de contexto três semanas atrás, que 70 por cento do aumento é de uma única aplicação, e que as solicitações descontroladas têm uma assinatura específica que você pode direcionar para um modelo mais barato. A primeira resposta deixa o financeiro irritado. A segunda resposta torna o financeiro um aliado.
A mesma distinção aparece na depuração de agentes. O monitoramento informa que uma tarefa de agente falhou. A observabilidade informa qual chamada LLM retornou uma resposta malformada, qual invocação de ferramenta downstream expirou como resultado e a qual solicitação de usuário a falha estava associada. Sem rastreamento correlacionado entre os planos LLM e MCP (Seção 4, pergunta 8), cada falha de agente é um exercício forense. As perguntas abaixo forçam o fornecedor a descrever o que é realmente capturado por chamada, como pode ser consultado e como os dados saem da plataforma quando seu sistema financeiro precisa deles.
Os detalhes importam aqui.
agent_task: trace_id 4bf92f35...
user: ana@company.com (team: applied-ml)
initiating_request: app_chat_support, 2026-04-28 14:22:31
duration: 4.8s
components:
- llm: claude-sonnet-4-6 | tokens 1842 in / 619 out | $0.0144
- tool: github.create_issue | latency 528ms | n/a
- llm: claude-haiku-4-5 | tokens 412 in / 87 out | $0.0011
total_cost_usd: $0.0155
total_tokens: 2960
Isso é o que torna a "atribuição de custos do agente" um sinal de nível financeiro, em vez de uma curiosidade técnica.

Figura 6. Vista em cascata de rastreamento de uma única tarefa de agente: chamada LLM, chamada de ferramenta MCP e segunda chamada LLM, todas sob um único trace_id com o custo agregado em todos os spans.
O custo de uma lacuna de integração raramente é visível na aquisição. Ele se manifesta seis meses depois, quando o acesso de um funcionário desligado leva 48 horas para ser revogado porque o SCIM não é real, quando uma interrupção P1 às 2h da manhã recebe uma resposta automática “responderemos durante o horário comercial” porque o SLA é aspiracional, quando uma renomeação de grupo no Okta quebra as atribuições de função porque a integração SSO da plataforma nunca foi testada com eventos de ciclo de vida de grupo. Cada um desses é um custo de engenharia finito, mas eles se acumulam no imposto operacional que faz com que as equipes de plataforma migrem silenciosamente de produtos, de outra forma capazes, na renovação do terceiro ano.
A Seção 6 revela as realidades operacionais. Dois padrões de diagnóstico: qualquer resposta “sim” a uma pergunta de suporte a protocolo merece um acompanhamento sobre quais clientes utilizam esse protocolo em produção hoje versus quais clientes serão os primeiros a experimentá-lo. E qualquer compromisso de SLA sem créditos explícitos anexados deve ser tratado como uma meta de marketing. SLAs contratuais vêm com créditos porque os fornecedores precificam o risco de não cumpri-los; SLAs aspiracionais são escritos pelo marketing e não vêm.
Obtenha os créditos por escrito.
Se a plataforma só pode consumir um formato de claim fixo, a integração com qualquer coisa que não seja Okta/Azure AD torna-se dolorosa. A flexibilidade acima é um custo de configuração único; sem ela, cada integração de IdP torna-se um engajamento personalizado.
POST /scim/v2/Users
Authorization: Bearer <scim-token>
Content-Type: application/scim+json
{
"schemas": ["urn:ietf:params:scim:schemas:core:2.0:User"],
"userName": "ana@company.com",
"name": {"givenName": "Ana", "familyName": "Ruiz"},
"emails": [{"value": "ana@company.com", "primary": true}],
"groups": [{"value": "applied-ml"}, {"value": "ai-platform-developer"}],
"active": true
}Quando o usuário é desprovisionado no IdP, o mesmo endpoint recebe um PATCH que altera 'active' para 'false', e a plataforma deve revogar o acesso do usuário prontamente, em vez de apenas na próxima tentativa de login. Teste isso na prova de conceito: desprovisione um usuário de teste no IdP, então tente usar um token de plataforma ainda válido e confirme que o ciclo de vida de desprovisionamento funciona de ponta a ponta. Se a plataforma só honra o desprovisionamento no próximo login do usuário, isso é uma lacuna de conformidade que vale a pena registrar por escrito.
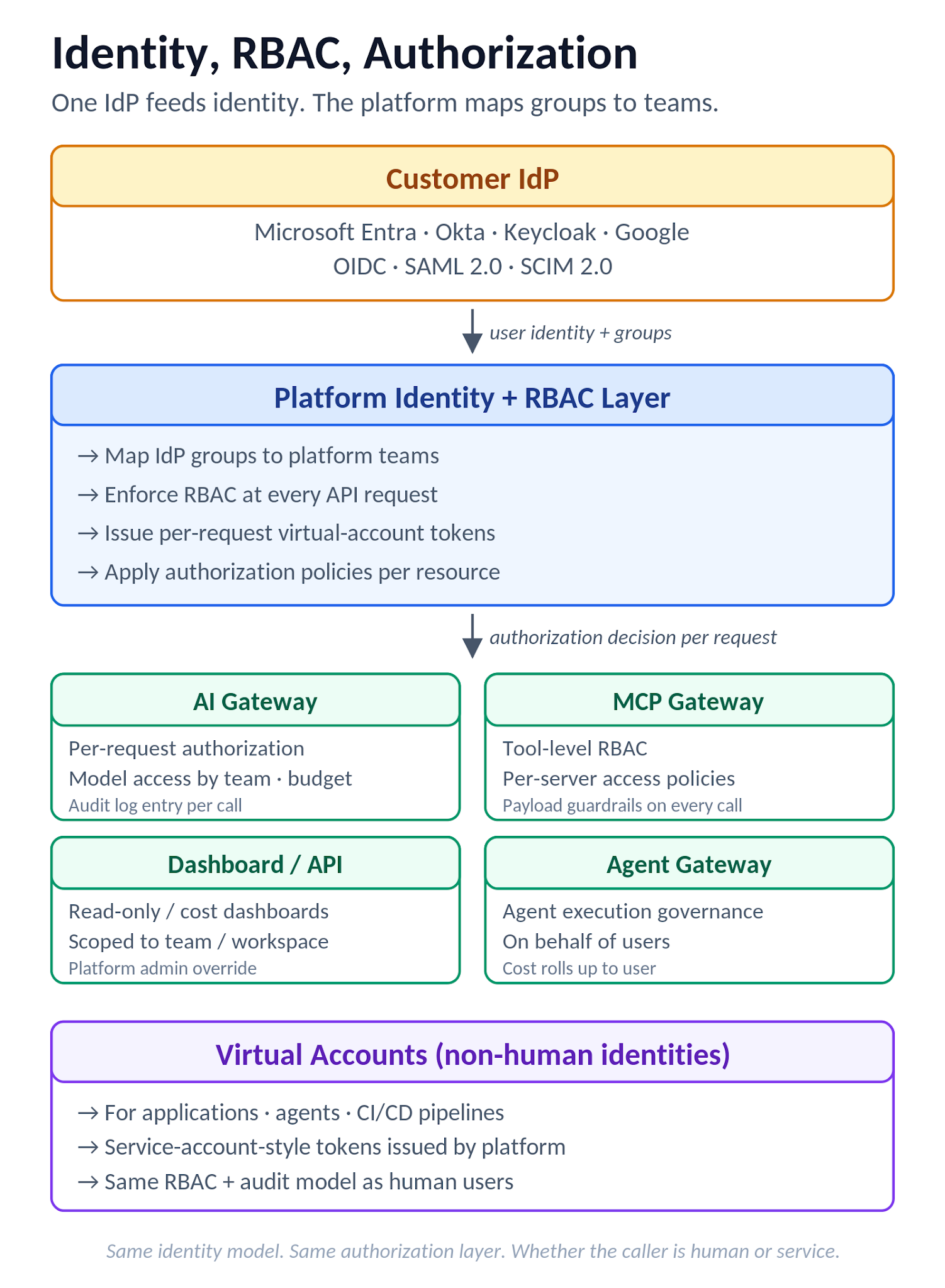
Figura 7. Fluxo de Identidade e RBAC: IdP alimenta a identidade, a plataforma mapeia grupos para equipes e Contas Virtuais, com aplicação no AI Gateway, MCP Gateway, painel e Agent Gateway.
Cuidado com “tempo de resposta” definido como “um e-mail automático dizendo que recebemos seu ticket.” Isso não é resposta. Resposta real é um engenheiro se envolvendo na questão. E a cláusula de crédito é o teste: SLAs contratuais vêm com créditos, SLAs de marketing não.
A equipe de soluções da TrueFoundry trata esta RFP como a avaliação formal, não como um artefato de vendas. Cada pergunta recebe uma resposta por escrito com evidências: relatórios SOC 2 Tipo II, documentação BAA para implantações na área da saúde, resumos de testes de penetração, arquiteturas de referência, logs de auditoria de exemplo, referências de clientes. O resultado é um documento que suas equipes de segurança, compras e plataforma usam para tomar uma decisão sem a necessidade de uma chamada de descoberta para preencher as lacunas.
A arquitetura subjacente às respostas mapeia diretamente para a estrutura de seções deste modelo, razão pela qual a maioria das perguntas é resolvida de forma clara. Analisando:
O modelo de implantação é de plano dividido. O plano de controle é o cérebro da orquestração, hospedando configuração, RBAC e painéis. Os planos de computação se conectam de volta através de um agente e hospedam as cargas de trabalho reais, incluindo o Gateway de IA, o Gateway MCP e quaisquer aplicações implantadas ou modelos auto-hospedados. Os planos de computação podem ser executados em contas de nuvem do cliente (AWS, GCP, Azure) ou em Kubernetes on-premise, e múltiplos planos de computação se conectam a um plano de controle para permitir operações multiambiente sob uma única superfície de controle. O Gateway de IA pode ser auto-hospedado dentro da infraestrutura do cliente (as opções de implantação são documentadas separadamente) para controles de residência e soberania de dados. Logs de auditoria e dados de rastreamento são armazenados usando projetos de log de requisições e rastreamento do Gateway, com RBAC governando o acesso a rastreamentos e logs. A arquitetura de plano dividido é o que torna a mesma postura de residência de dados disponível em implantações SaaS, single-cloud, multi-cloud e auto-hospedadas, em vez de tratar cada uma como um produto separado com posturas de controle separadas.
Soberania de dados é a arquitetura, não uma linha de marketing.
A autenticação usa SSO empresarial via OIDC ou SAML 2.0 com validação opcional de token IdP diretamente no Gateway de IA para controle de acesso à API. IdPs comuns (Microsoft Entra ID, Okta, Keycloak, Google) são suportados, com reivindicações de identidade e associações de grupo mapeadas do IdP para as equipes TrueFoundry para impulsionar o RBAC em escala. O provisionamento SCIM é suportado em todas as configurações de SSO — tanto OIDC quanto SAML — de modo que o desprovisionamento no IdP se propaga em vez de esperar pelo próximo login do usuário. O RBAC opera no nível do Tenant (funções de Admin/Membro) mais funções personalizadas com permissões delimitadas para usuários, equipes, clusters, workspaces, implantações, contas de provedor do Gateway de IA, servidores MCP e projetos de rastreamento. Identidades não-humanas (aplicações, agentes) recebem Contas Virtuais com tokens estilo conta de serviço, e a autorização por requisição nos limites do Gateway de IA (modelos, agentes, servidores e ferramentas MCP) suporta padrões de menor privilégio. Chaves de provedor se integram com armazenamentos de segredos gerenciados pelo cliente; a autenticação do gateway é sobreposta ao IdP em vez de substituí-lo, de modo que MFA e acesso condicional permanecem impostos pelo IdP do cliente.
O gateway de IA roteia mais de 1.000 LLMs através de um único endpoint compatível com OpenAI: OpenAI, Anthropic (direto e via AWS Bedrock), Azure OpenAI, GCP Vertex AI, Groq, Mistral e modelos auto-hospedados servidos via vLLM, TGI ou Triton. O roteamento é configurado através de Modelos Virtuais, que expõem uma interface de modelo e fazem balanceamento de carga ou failover entre múltiplos provedores e modelos subjacentes. O TrueFailover adiciona roteamento consciente de interrupções e degradações, com resiliência multi-região e multi-nuvem integrada. Limites rígidos de token e requisições por usuário, equipe ou Conta Virtual retornam uma rejeição estruturada quando uma equipe atinge seu orçamento, em vez de um alerta suave com a requisição ainda sendo processada. O fallback do provedor é automático e a penalidade de latência é capturada como uma métrica separada na chamada, em vez de estar oculta na latência total. O cache semântico usa embeddings e similaridade de cosseno com limite e TTL configuráveis; a documentação cita uma melhoria de latência de até ~20x para consultas repetidas ou semelhantes. Guardrails são baseados em regras (alvo por modelo, usuário ou metadados), cada um pode Validar (bloquear) ou Mutar (reescrever/redigir), e o Bring-Your-Own Guardrail é suportado através de um servidor de guardrail personalizado usando um modelo FastAPI.
O roteamento aqui é o produto, não uma flag de configuração.
A pilha MCP e de agentes é o diferencial. A TrueFoundry executa um Gateway MCP nativo e um Registro MCP que registram, descobrem e conectam com segurança servidores e ferramentas MCP centralmente através de controles de acesso governados e fluxos de autenticação empresariais. Transportes MCP modernos, incluindo HTTP streamable para conexões proxy, são suportados, e a camada de protocolo usa mensagens JSON-RPC padrão conforme a especificação MCP. A autenticação é em camadas: autenticação de gateway, controle de acesso a servidores MCP e autenticação por servidor ou por ferramenta (incluindo padrões baseados em OAuth documentados para servidores MCP empresariais). A configuração centralizada significa que as ferramentas de desenvolvedor se comunicam com um único endpoint de gateway, em vez de cada desenvolvedor configurar suas próprias conexões MCP, que é o padrão de "shadow-tooling" que o registro foi projetado para prevenir. O Agent Hub fornece catalogação organizacional e orquestração para agentes complexos e agentes pré-existentes, e o Agent Gateway fornece a camada de governança empresarial (acesso seguro a ferramentas, observabilidade, controles de custo) para executar esses agentes em produção. A mesma identidade que governa o acesso a LLMs governa o acesso a ferramentas, então a autorização para ambos reside em uma única configuração de IdP. E o mesmo contexto de rastreamento que une uma tarefa de agente LLM de várias etapas une as invocações MCP sob ela, o que torna a consolidação de custos por tarefa e a depuração de ponta a ponta tratáveis em vez de teóricas.
A observabilidade usa o registro de requisições do Gateway com rastreamentos. Contagens de tokens, custos, latência (TTFT e total), decisões de guardrail, decisões de política e atribuição de equipe e aplicação são capturados por chamada, armazenados como rastreamentos e acessíveis através de projetos de rastreamento com seu próprio RBAC. A exportação de telemetria é baseada em padrões: exportação de dados OpenTelemetry mais exportação de logs e rastreamentos para sistemas externos, incluindo Grafana, Datadog e Prometheus, para que os clientes se integrem com pilhas de observabilidade existentes em vez de aprender uma proprietária. Painéis de custo são em tempo real e compartilháveis com líderes de equipe através de RBAC somente leitura. O mesmo armazenamento de logs/rastreamentos é o que cria o conjunto de dados auditável de tentativas de injeção de prompt, acertos de política e padrões de abuso que os clientes podem explorar para ajustar os guardrails ao longo do tempo.
Sua pilha de observabilidade existente permanece sua pilha de observabilidade existente.
A evidência de throughput por trás de tudo isso: 10 bilhões de requisições por mês processadas em toda a base de clientes, mais de 1.000 clusters Kubernetes gerenciados pela plataforma, sobrecarga do lado do gateway abaixo de 10ms p95 (TTFT) e mais de 350 RPS sustentados em uma única vCPU. Clientes em produção incluem Resmed, Siemens Healthineers, Automation Anywhere, Zscaler e Nvidia. A Série A foi liderada pela Intel Capital em fevereiro de 2025, elevando o financiamento total para aproximadamente US$ 21 milhões com a participação de Peak XV Partners (Surge), Eniac Ventures e Jump Capital.
Escala de produção, não escala piloto.
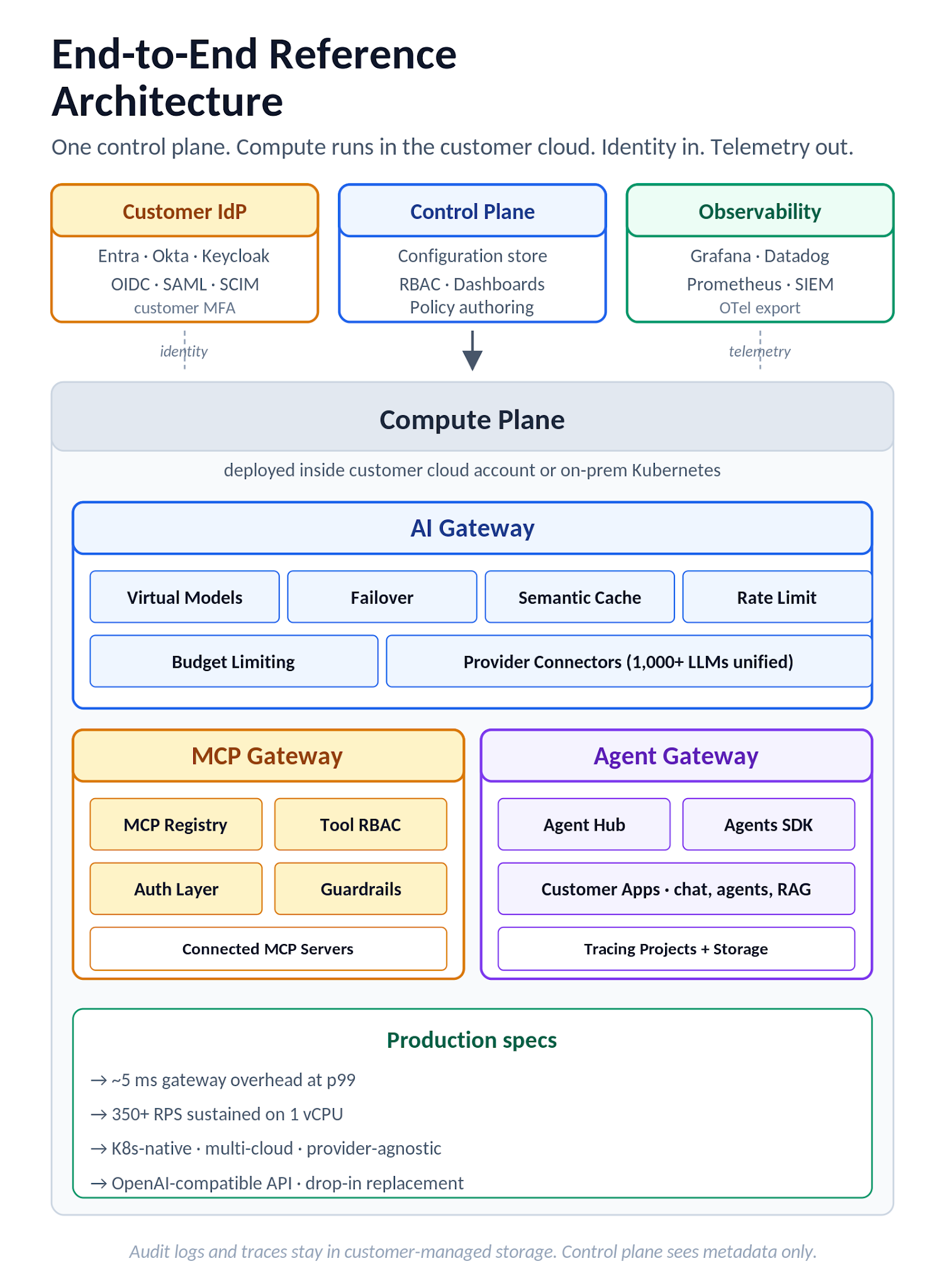
Figura 8. Arquitetura de referência ponta a ponta da TrueFoundry: plano de controle, plano de computação (com Gateway de IA, Gateway MCP, Gateway de Agente e Aplicativos do Cliente), IdP do cliente e alvos de observabilidade.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.






.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




