



.webp)
July 3, 2026
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: May 21, 2026
Blazingly fast way to build, track and deploy your models!
Se você já participou de uma reunião com sua equipe de Segurança da Informação ou Jurídica sobre uma implantação global de ML, você sabe o momento exato em que o clima muda. É quando alguém pergunta: "Espere, onde estão realmente os logs de inferência para os clientes alemães?"
A residência de dados costumava ser um problema de banco de dados. Agora, com pipelines de ML que abrangem treinamento, serviço, monitoramento e feature stores, é uma bagunça generalizada em toda a sua pilha de infraestrutura. GDPR, CCPA, leis de soberania de dados em toda a Ásia – não são sugestões. Errar significa multas massivas ou, pior, ter que desativar uma implantação ativa.
Temos usado a TrueFoundry para gerenciar nossa infraestrutura de ML e, francamente, a abordagem deles para a residência de dados é uma das principais razões pelas quais continuamos com eles. Isso muda fundamentalmente a forma como pensamos sobre onde os dados residem versus onde são gerenciados.
Aqui está uma visão de como funciona na prática e por que parece diferente das plataformas MLOps SaaS típicas.
O maior problema com muitas plataformas MLOps gerenciadas é que, para obter a conveniência de suas ferramentas, você frequentemente precisa enviar seus dados (artefatos de modelo, trechos de treinamento, logs) para a nuvem deles. Isso é inviável para indústrias altamente regulamentadas.
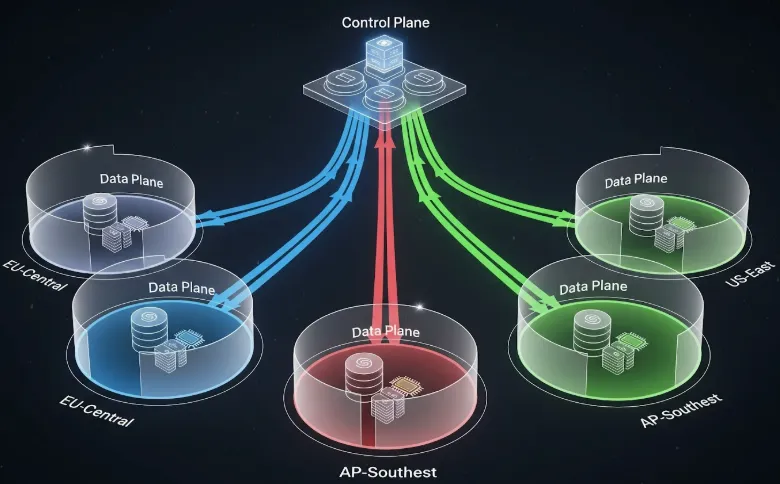
A TrueFoundry opera de forma diferente. Eles empregam uma separação rigorosa entre o Plano de Controle (sua interface de gerenciamento SaaS) e o Plano de Dados (suas contas de nuvem).
Pense da seguinte forma: a TrueFoundry é o controlador de tráfego aéreo. Eles dizem aos aviões para onde ir e quando pousar. Mas você é o proprietário do aeroporto, dos hangares e dos próprios aviões. A TrueFoundry nunca possui de fato a carga dentro do avião.
Quando você conecta um cluster Kubernetes (EKS, GKE, AKS) à TrueFoundry, você está essencialmente instalando um agente. Esse agente se conecta ao Plano de Controle da TrueFoundry para obter instruções, mas todo o processamento e armazenamento de dados real acontece dentro do seu perímetro de rede predefinido.
Aqui está uma visão de alto nível dessa relação.
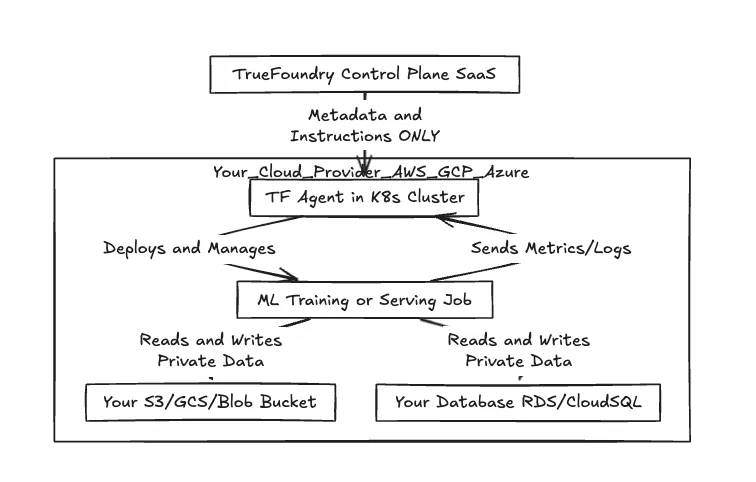
Fig. 1: Fluxo de trabalho da separação entre Plano de Controle e Plano de Dados
Conforme mostrado acima, o "trabalho pesado" e a E/S de dados real permanecem inteiramente dentro do limite do seu ambiente de nuvem. A única coisa que atravessa a rede de volta para a TrueFoundry são metadados – status do trabalho, métricas de utilização de recursos e especificações de configuração.
Como isso se traduz em uma configuração do mundo real onde você tem uma equipe na UE que legalmente não pode ter os dados de seus clientes tocando o solo dos EUA?
O TrueFoundry utiliza um conceito chamado "Workspaces". Um Workspace é um agrupamento lógico de recursos que está vinculado a um cluster de computação subjacente específico e a uma integração de armazenamento de artefatos.
Para garantir a residência de dados, configuramos clusters distintos nas nossas regiões geográficas exigidas.
Repetimos o processo para us-east-1 com um workspace "US-Prod".
Quando um cientista de dados da UE deseja implantar um modelo, ele recebe acesso apenas ao workspace "EU-Prod". Quando ele aciona um trabalho de treinamento ou implanta um serviço, o plano de controle do TrueFoundry garante que a computação ocorra no cluster de Frankfurt e os pesos do modelo resultantes sejam salvos no bucket S3 de Frankfurt. A plataforma fisicamente não pode colocar os dados em outro lugar, porque esse workspace não tem conhecimento de qualquer outra infraestrutura.
Abaixo está uma comparação de como os dados são tratados em um SaaS de ML gerenciado típico versus esta arquitetura.
Tabela 1: Comparação de Modelos de Tratamento de Dados
Em uma organização madura, você acaba com um modelo hub-and-spoke. Você tem um plano de controle TrueFoundry centralizado, oferecendo à sua equipe de engenharia de plataforma uma visão unificada para facilitar o gerenciamento, mas a execução real é fragmentada geograficamente.
Esse isolamento é crítico. Isso significa que, mesmo que um desenvolvedor tente acidentalmente configurar um trabalho incorretamente, as restrições da infraestrutura impedem o vazamento de dados entre regiões.
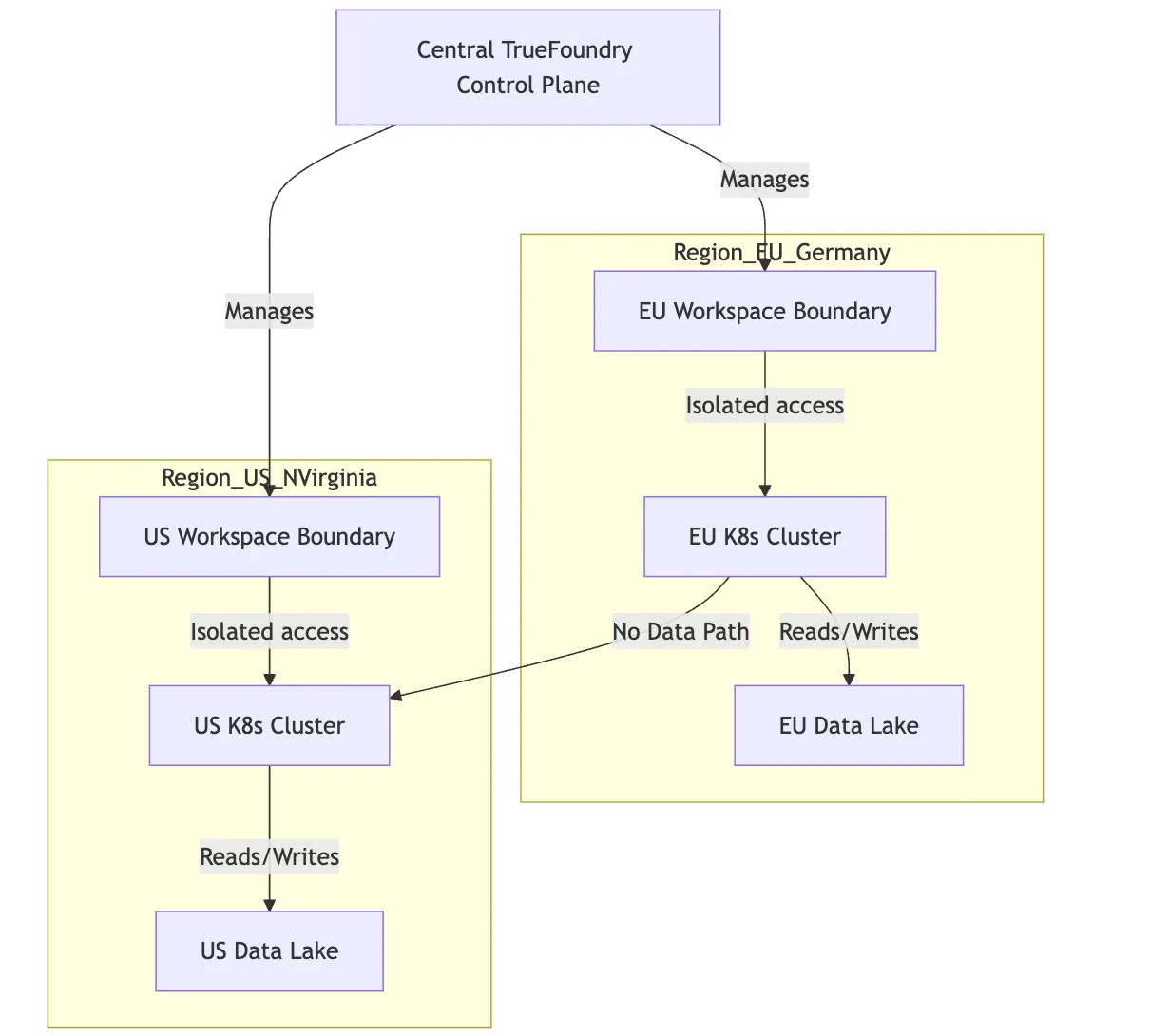
Fig. 2: Diagrama de Isolamento Multirregional usando Workspaces
A residência de dados raramente é um trabalho empolgante, mas é fundamental. Se você errar, nada mais importa.
A beleza da arquitetura do TrueFoundry é que ela não tenta ser um "bunker de dados seguro" por si só. Em vez disso, ela respeita os bunkers que você já construiu na AWS, Azure ou GCP. Ela nos permite oferecer aos nossos cientistas de dados uma experiência de implantação moderna, semelhante à Heroku, sem ter que lutar constantemente com nossa equipe de InfoSec por exceções. Definimos o perímetro uma vez, anexamos o TrueFoundry a ele e paramos de nos preocupar com a saída acidental de dados.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.






.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




