



.webp)
July 3, 2026
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: May 28, 2026

Blazingly fast way to build, track and deploy your models!
Os sistemas de IA já não são ferramentas passivas. Estão cada vez mais agênticos – operando autonomamente em fluxos de trabalho, APIs e dados empresariais sensíveis. Em sistemas tradicionais, a residência de dados era definida pelo local onde os dados eram armazenados. Uma vez que as bases de dados e o armazenamento residissem em regiões aprovadas, a conformidade era considerada resolvida.
A IA agêntica quebra esse modelo. Cada interação gera novas superfícies de dados – prompts, memória do agente, registos, rastreios e dados de inferência transitórios, que são processados e observados em tempo de execução, muitas vezes em várias regiões, mesmo quando nada é persistido.
Como resultado, a residência de dados já não é um mero item de conformidade. É uma questão fundamental de infraestrutura agora discutida ao nível da administração. A pergunta que as empresas devem responder é simples: Para onde se movem os dados gerados por IA em tempo de execução e quem controla esses caminhos?
Na TrueFoundry, a residência de dados é aplicada no Gateway de IA, onde a inferência, os agentes e as ferramentas convergem. A residência é tratada como uma propriedade do sistema, aplicada em condições de operação normal, falhas e escala. Este blogue explica como a residência de dados é definida, aplicada e verificada no Gateway de IA da TrueFoundry.
A residência de dados era mais simples quando as aplicações tinham caminhos de dados previsíveis. As requisições fluíam dos usuários para os serviços e para os bancos de dados, geralmente dentro de uma única região, e os controles de conformidade eram em grande parte estáticos.
Sistemas de IA quebram este modelo em tempo de execução.
Em arquiteturas de IA modernas, o movimento de dados é dinâmico e orientado por decisões, não fixo. Uma única requisição de usuário pode acionar múltiplos caminhos de execução, todos orquestrados pelo AI Gateway. É aqui que a residência de dados se torna frágil.
Em tempo de execução, um AI Gateway pode:
Cada uma dessas decisões pode introduzir movimento de dados implícito, muitas vezes sem que a aplicação tenha conhecimento disso.
As falhas mais comuns de residência de dados em sistemas de IA ocorrem:
Crucialmente, essas falhas ocorrem mesmo quando:
Todas essas falhas têm uma coisa em comum: elas ocorrem em tempo de execução, impulsionadas por roteamento, novas tentativas, execução de agente e comportamento de registro.
O Gateway de IA é a única camada que:
É por isso que a residência de dados em sistemas de IA não pode ser garantida apenas pela configuração de implantação. Ela deve ser imposta no Gateway de IA, onde os caminhos de execução são decididos em tempo real.
Em plataformas como TrueFoundry, a residência é tratada como um restrição rígida de tempo de execução, não uma preferência de melhor esforço, garantindo que nenhum caminho de execução, incluindo cenários de falha, possa violar os limites regionais.
Sistemas de IA Agentes não apenas usam dados, eles geram continuamente novas superfícies de dados em tempo de execução. Essas superfícies não existiam em aplicações tradicionais, e elas mudam fundamentalmente o que a residência de dados deve considerar.
Em sistemas de IA, a residência de dados não se limita mais a dados em repouso. Ela se estende a cada dado criado, processado ou observado durante a inferência e a execução do agente, mesmo que esses dados existam apenas brevemente.
Os mais importantes dessas novas responsabilidades de dados são frequentemente os menos visíveis.
Solicitações de inferência transportam prompts e respostas através do AI Gateway, frequentemente contendo lógica proprietária, dados de clientes ou contexto interno sensível. Ao contrário das APIs tradicionais, esses dados são de formato livre e não higienizados, tornando-os particularmente de alto risco.
Fluxos de trabalho agentivos introduzem contexto e memória persistentes entre interações. Se esse estado for processado ou reproduzido fora das regiões aprovadas, a residência é violada, mesmo quando as chamadas de inferência individuais parecem conformes.
Sistemas de IA também geram logs, rastreamentos, embeddings e metadados de execução que podem codificar informações sensíveis. Se os pipelines de observabilidade exportarem esses dados entre regiões, violações ocorrem silenciosamente.
Crucialmente, os dados não precisam ser armazenados para serem não conformes. Dados de inferência transitórios, processados apenas em memória por milissegundos, ainda se enquadram nos requisitos de residência se cruzarem um limite jurisdicional.
Os controles de residência tradicionais foram projetados para sistemas estáticos, não para roteamento dinâmico, novas tentativas, failover e execução orientada por agentes. Em sistemas de IA, a residência deve ser aplicada em tempo de execução, onde esses caminhos de dados são criados.
Em plataformas como TrueFoundry, essa aplicação acontece no Gateway de IA, onde prompts, contexto do agente, novas tentativas e telemetria convergem, tornando a residência uma propriedade do sistema em vez de uma suposição.
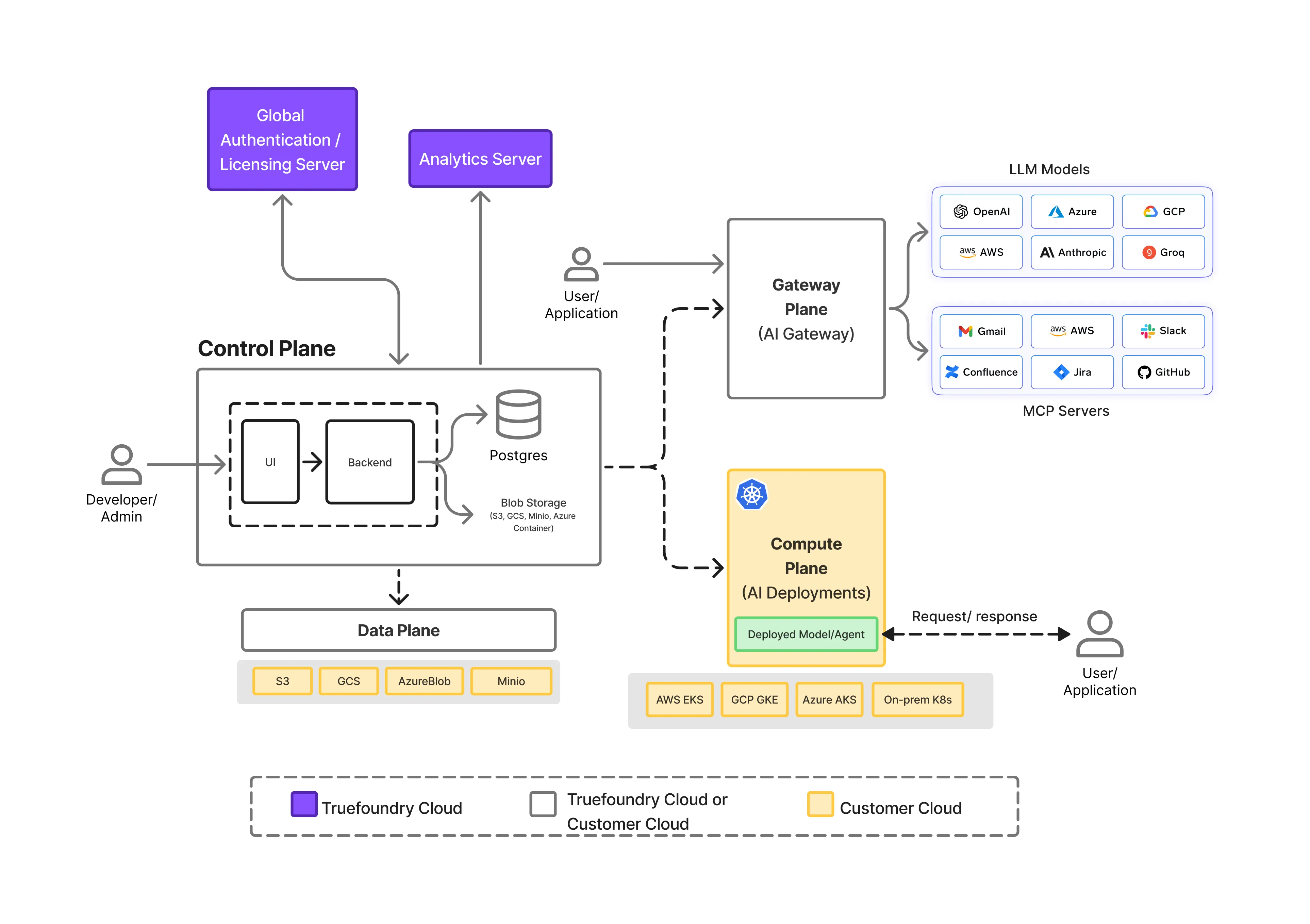
Garantir a residência de dados em sistemas de IA exige mais do que uma implantação regional. Exige clara separação de responsabilidades em toda a pilha de IA, para que os caminhos de execução, controle e dados possam ser governados independentemente.
TrueFoundry é projetado em torno de uma arquitetura de plano dividido que que torna isso possível.
Em um nível superior, a plataforma é composta por três planos distintos:
Essa separação é fundamental para como a residência de dados é aplicada de forma confiável em tempo de execução.
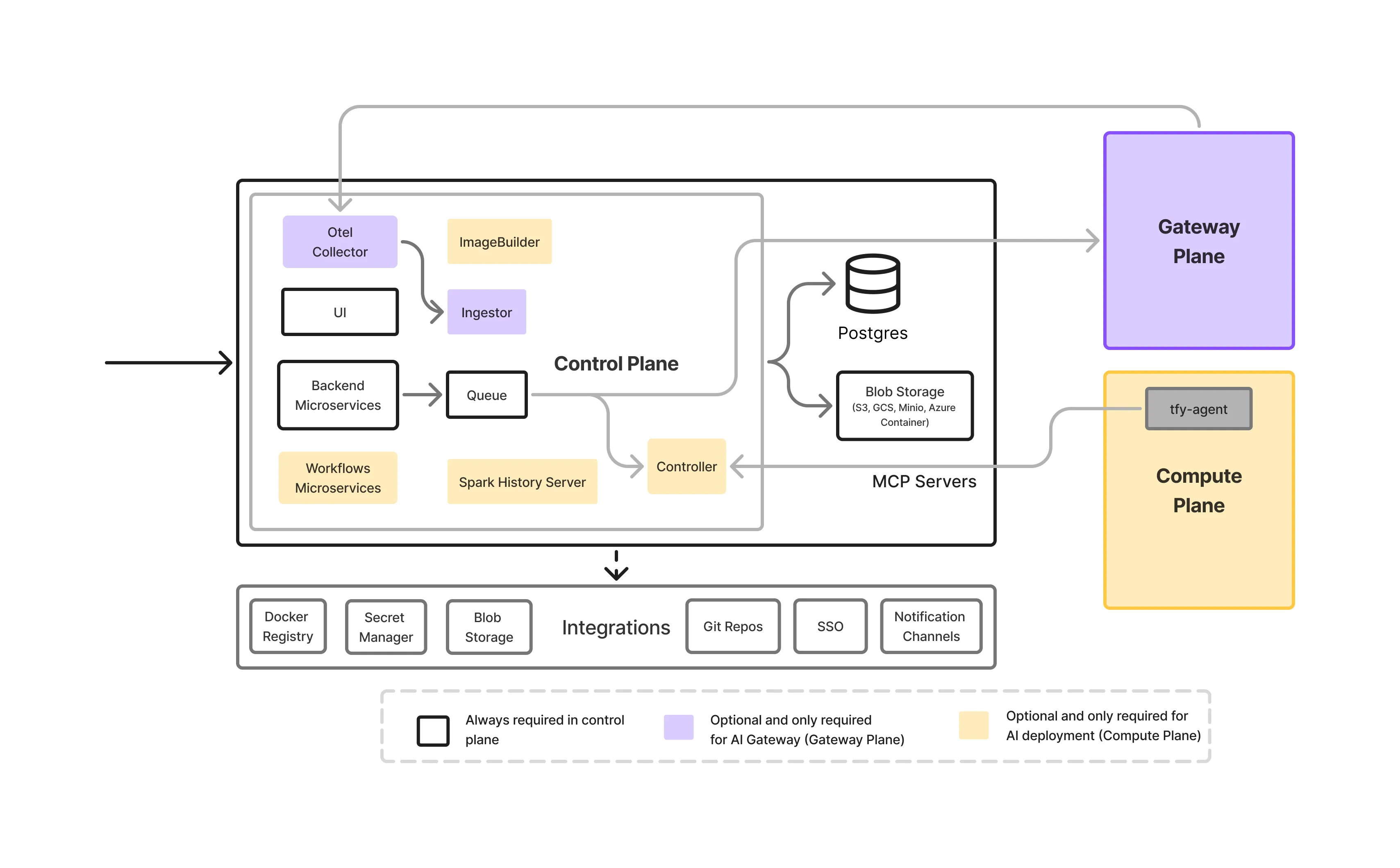
O plano de controle é a camada de orquestração da plataforma TrueFoundry. É responsável por:
Crucialmente, o plano de controle não processa tráfego de inferência e não executa cargas de trabalho. Ele define o que deve acontecer, não onde os dados fluem em tempo de execução.
Para empresas com requisitos rigorosos de conformidade, o TrueFoundry suporta ambos:
Isso permite que as organizações escolham o equilíbrio adequado entre simplicidade operacional e requisitos de soberania, sem alterar como a aplicação da residência funciona a jusante.
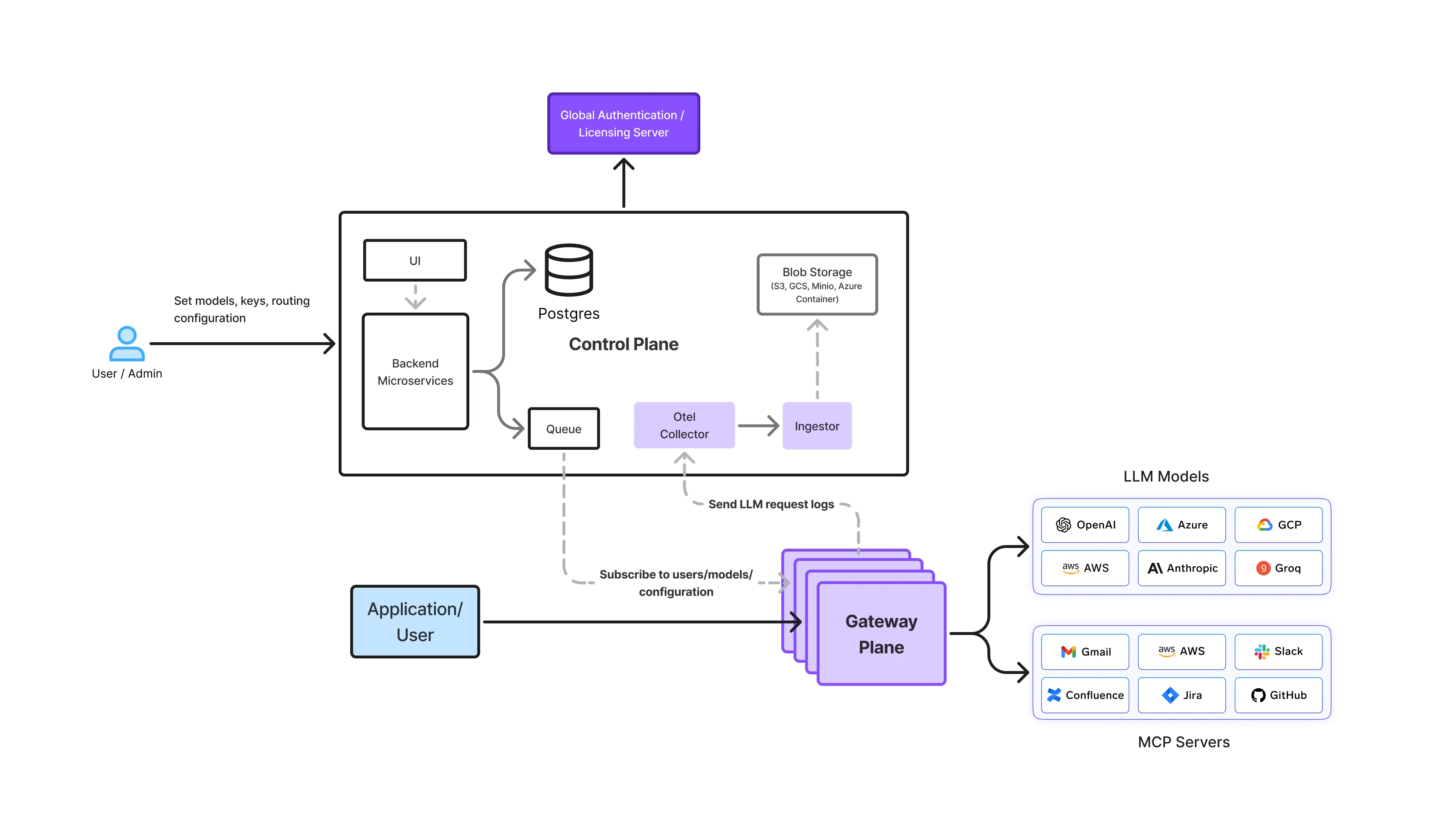
O plano de gateway é onde a residência de dados é ativamente aplicada.
Os Gateways de IA da TrueFoundry ficam entre as aplicações e todos os fornecedores de modelos, atuando como:
Cada requisição de inferência, nova tentativa, failover, invocação de agente e evento de observabilidade passa pelo gateway. Isso lhe confere visibilidade total sobre:
Devido a isso, o plano de gateway é o única camada capaz de impor a residência de dados como uma restrição rígida.
Se uma solicitação não puder ser atendida dentro dos limites de residência configurados, o gateway rejeita a solicitação, fechando o acesso em vez de roteá-la silenciosamente para uma região não-conforme.
Esta é a principal diferença entre imposição em tempo de execução e configuração de melhor esforço.
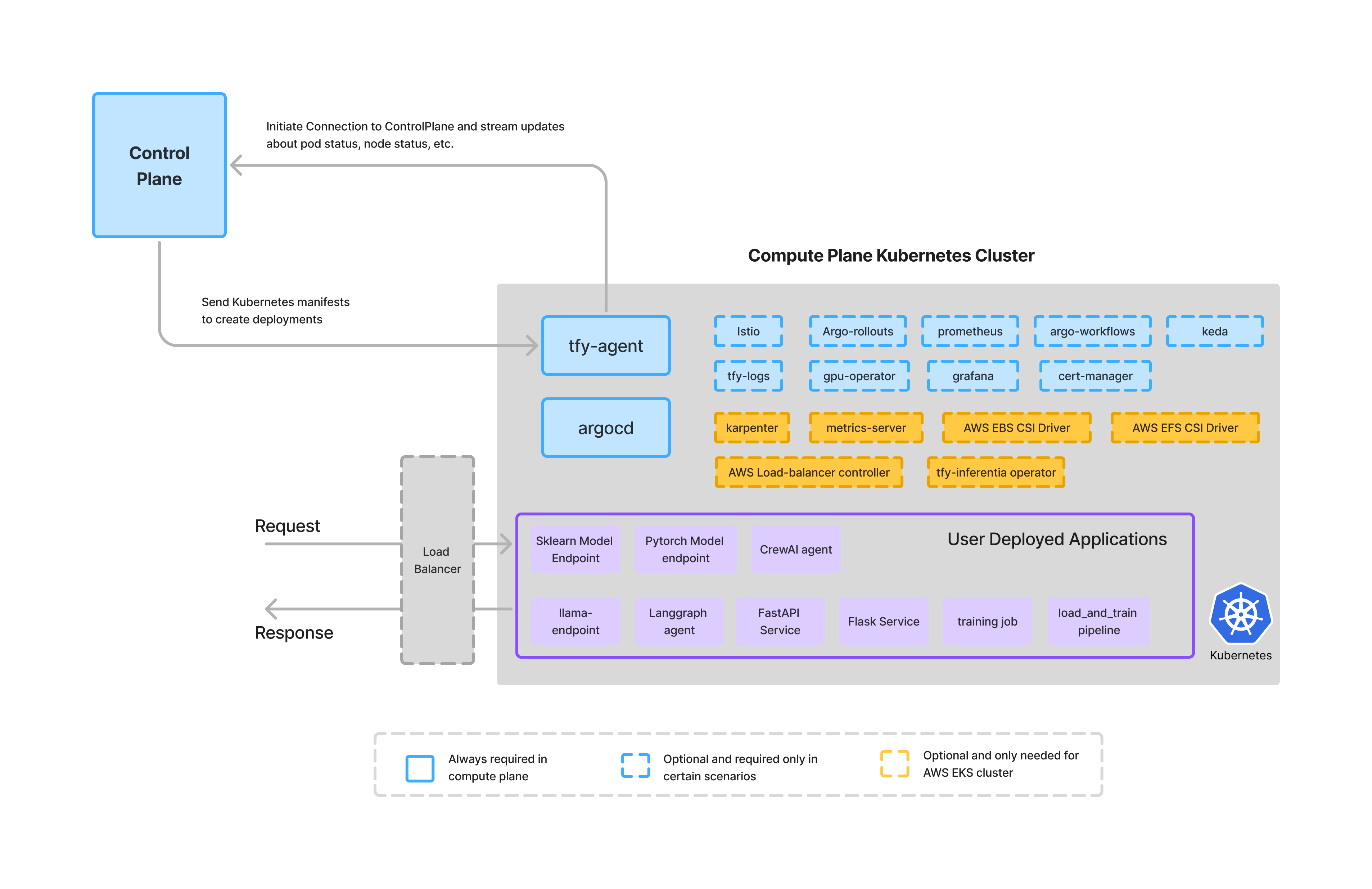
O plano de computação é onde aplicativos, agentes e cargas de trabalho realmente são executados.
Na TrueFoundry, o plano de computação:
Este design garante que:
A TrueFoundry não executa cargas de trabalho de clientes em computação compartilhada. Em vez disso, ela se integra aos clusters existentes do cliente ou ajuda a provisionar novos, mantendo a execução firmemente dentro do limite de confiança da organização.
Esta separação de planos permite à TrueFoundry impor a residência de dados sem comprometer:
Como a imposição ocorre no gateway — onde roteamento, novas tentativas, agentes e logs convergem —, a residência de dados se mantém mesmo sob:
É isso que permite que a residência de dados se torne uma propriedade do sistema, não uma suposição ligada a diagramas de implantação.
A residência de dados em sistemas de IA não é uma configuração simples — ela deve ser garantida em execução, roteamento e armazenamento. Na TrueFoundry, isso é alcançado através de três modos de aplicação complementares que, juntos, cobrem todo o ciclo de vida dos dados de IA.
Cada modo aborda uma classe diferente de risco de residência e pode ser usado de forma independente ou em combinação, dependendo dos requisitos da empresa.
Para organizações com as mais rigorosas necessidades de residência e conformidade, a TrueFoundry permite um modelo de implantação onde os dados nunca saem do ambiente do cliente.
Neste modo:
Isso se aplica a ambos:
Ao garantir que os caminhos de execução e de dados permaneçam inteiramente dentro da infraestrutura controlada pelo cliente, este modo oferece as mais fortes garantias de residência possíveis e simplifica as auditorias regulatórias.
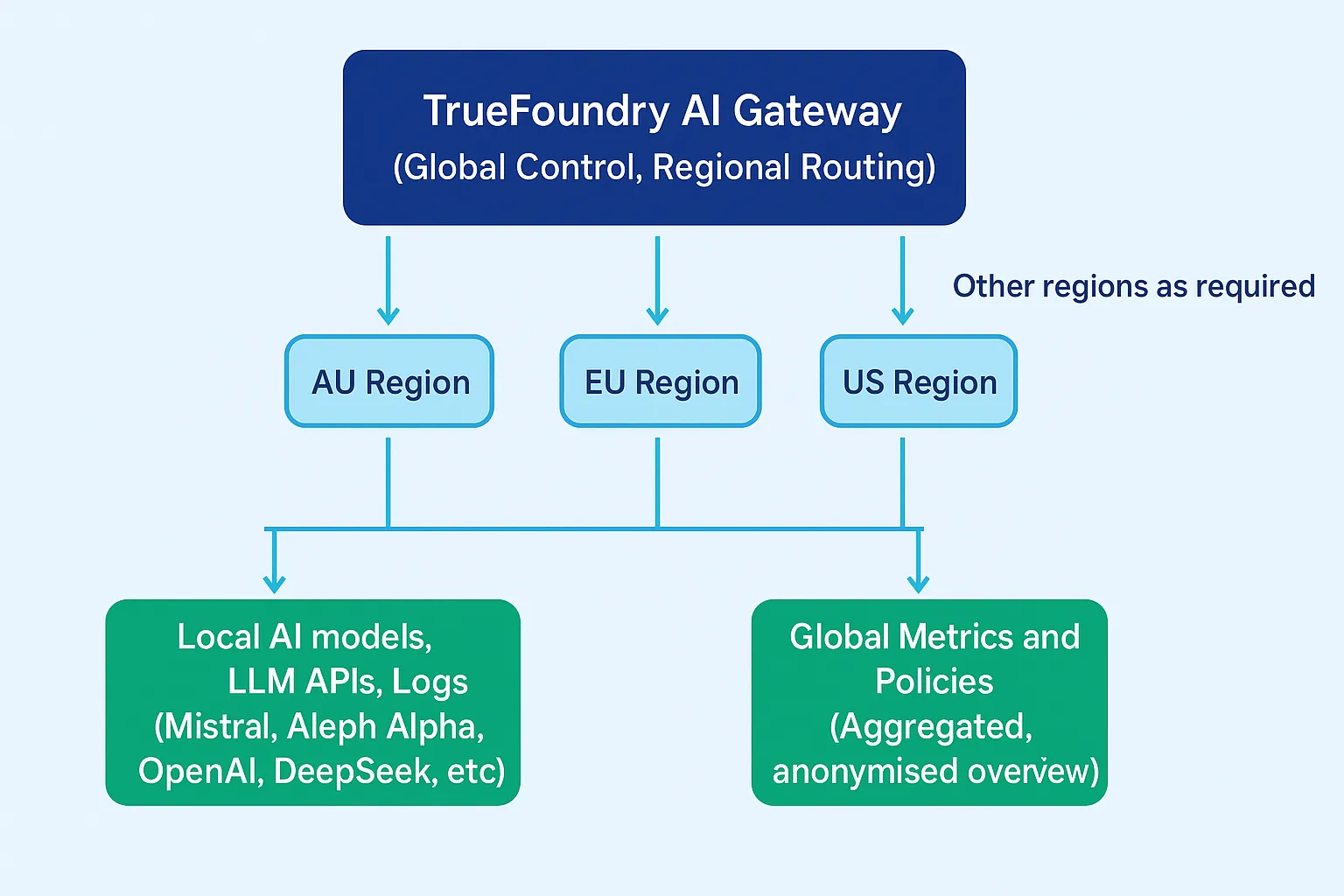
Muitas empresas precisam operar globalmente, garantindo que os dados de uma determinada geografia nunca ultrapassem as fronteiras jurisdicionais.
A TrueFoundry impõe isso através de implantações de AI Gateway específicas para cada região:
As aplicações escolhem explicitamente qual endpoint de gateway regional usar. Isso torna a residência de dados:
Se não existir um caminho de execução compatível com a residência para uma solicitação, o gateway fecha a solicitação com falha em vez de roteá-la para outra região. Isso garante que os mecanismos de disponibilidade nunca anulem a intenção de conformidade.
A inferência e a execução são apenas parte do panorama da residência de dados. Logs, rastreamentos, prompts e telemetria frequentemente contêm informações igualmente sensíveis e devem seguir as mesmas regras de residência.
O TrueFoundry permite que as empresas imponham a residência na camada de armazenamento ao:
Isso torna possível:
Como essas escolhas de armazenamento estão integradas diretamente na configuração do AI Gateway e do SDK, os dados de observabilidade seguem as mesmas garantias de residência que o tráfego de inferência.
Cada modo de imposição resolve um problema diferente:
Juntos, eles garantem que a residência de dados seja aplicada:
Essa abordagem em camadas é o que permite à TrueFoundry transformar a residência de dados de uma configuração de melhor esforço em uma propriedade de sistema verificável e imposta em tempo de execução.
Na TrueFoundry, a residência de dados é aplicada através de múltiplas camadas explícitas dentro do AI Gateway, cada um abordando uma classe diferente de risco em tempo de execução.
Essas camadas trabalham juntas para garantir que as garantias de residência sejam mantidas em condições do mundo real.
Em sistemas de IA, as garantias de residência de dados só são válidas se forem aplicadas em tempo de execução, em cada caminho de execução, não apenas durante a operação em estado estável. Na TrueFoundry, o Gateway de IA é o ponto de aplicação onde decisões de roteamento, novas tentativas, execução de agentes e observabilidade convergem.
Os seguintes mecanismos explicam como a residência de dados é aplicada de forma determinística dentro do Gateway de IA da TrueFoundry.
Os modelos na TrueFoundry são registrados com afinidade de região explícita. O Gateway de IA avalia as restrições de residência antes de rotear qualquer solicitação e seleciona apenas endpoints de modelo que são elegíveis para a região permitida da carga de trabalho.
Isso evita:
Como a residência é tratada como uma restrição de roteamento rígida, não uma preferência, modelos não conformes nunca são considerados — mesmo que estejam disponíveis ou sejam mais rápidos.
Retentativas e caminhos de failover são a fonte mais comum de violações silenciosas de residência de dados em sistemas de IA.
O AI Gateway da TrueFoundry impõe:
Isso garante que os mecanismos de disponibilidade nunca anulem a intenção de conformidade. Se um caminho em conformidade não estiver disponível, o sistema falha explicitamente em vez de rotear dados entre regiões.
Para cargas de trabalho agentivas, a residência de dados deve permanecer consistente em inferência de modelo e invocação de ferramentas a jusante.
A TrueFoundry garante:
Isso elimina um modo de falha comum onde a inferência permanece em conformidade, mas os agentes vazam dados indiretamente através de ferramentas ou servidores MCP implantados em outras regiões.
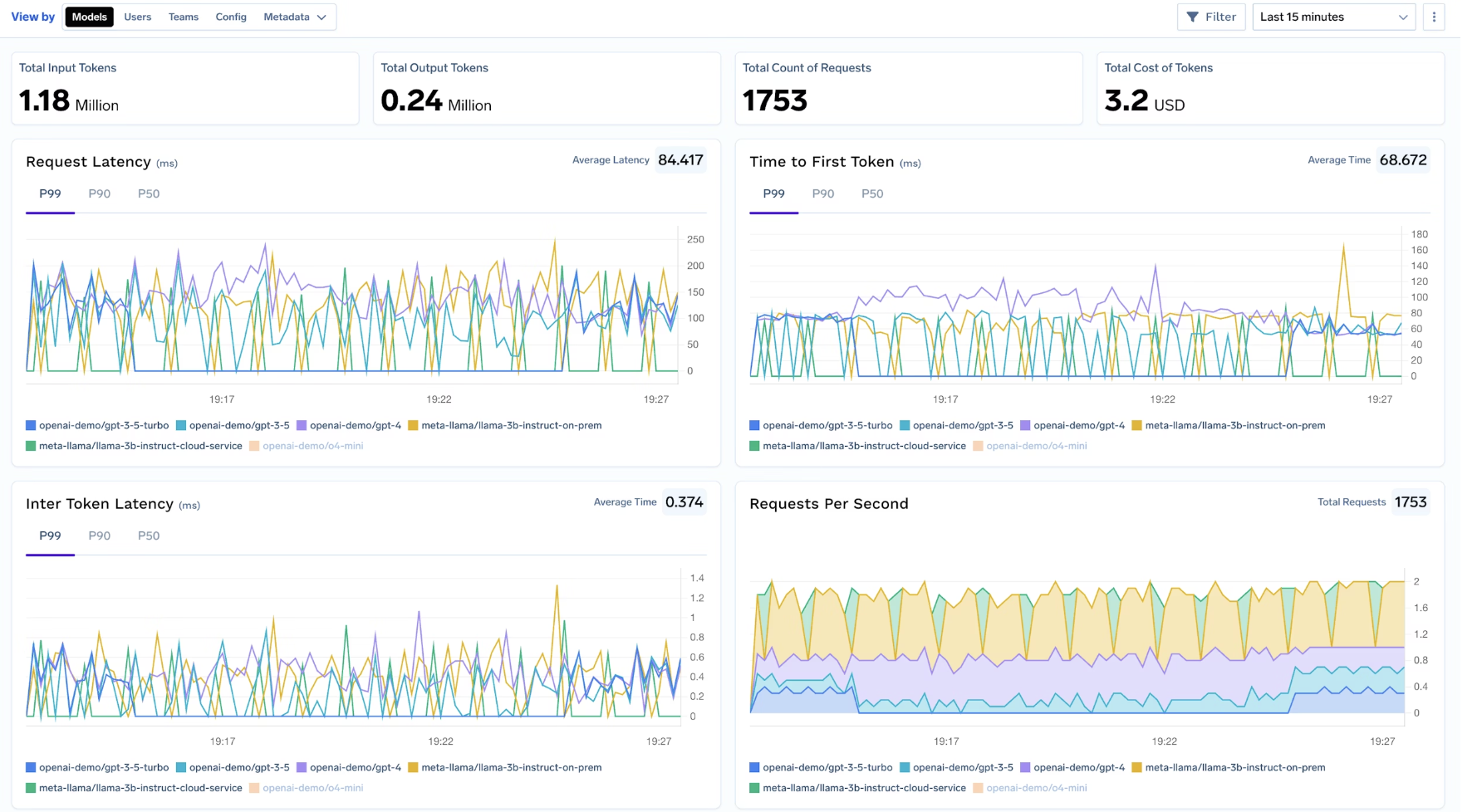
Os pipelines de observabilidade são frequentemente negligenciados em projetos de residência de dados, apesar de frequentemente conterem dados altamente sensíveis.
O AI Gateway da TrueFoundry garante que:
Isso fecha uma das lacunas de residência mais persistentes em sistemas de IA, onde a inferência está em conformidade, mas os logs e rastreamentos não estão.
Esses mecanismos de aplicação se aplicam uniformemente em:
Como a aplicação ocorre antes da execução, a residência de dados torna-se uma propriedade verificável do sistema, e não uma configuração de melhor esforço vinculada à alocação da infraestrutura.
A maioria das violações de residência de dados em sistemas de IA não são causadas por configurações incorretas óbvias. Elas surgem de casos de borda e caminhos de exceção que raramente são testados até que algo dê errado.
A seguir, estão os cenários de falha mais comuns que as empresas enfrentam e como o TrueFoundry AI Gateway foi projetado para evitá-los.
O que acontece em muitos sistemas
Um endpoint de modelo regional torna-se indisponível. O AI Gateway tenta novamente automaticamente ou faz failover para o próximo endpoint disponível, muitas vezes em outra região.
Do ponto de vista da disponibilidade, isso parece um sucesso.
Do ponto de vista da conformidade, é uma violação silenciosa.
Como a TrueFoundry evita isso
Isso garante que mecanismos de disponibilidade nunca substituam a política de residência.
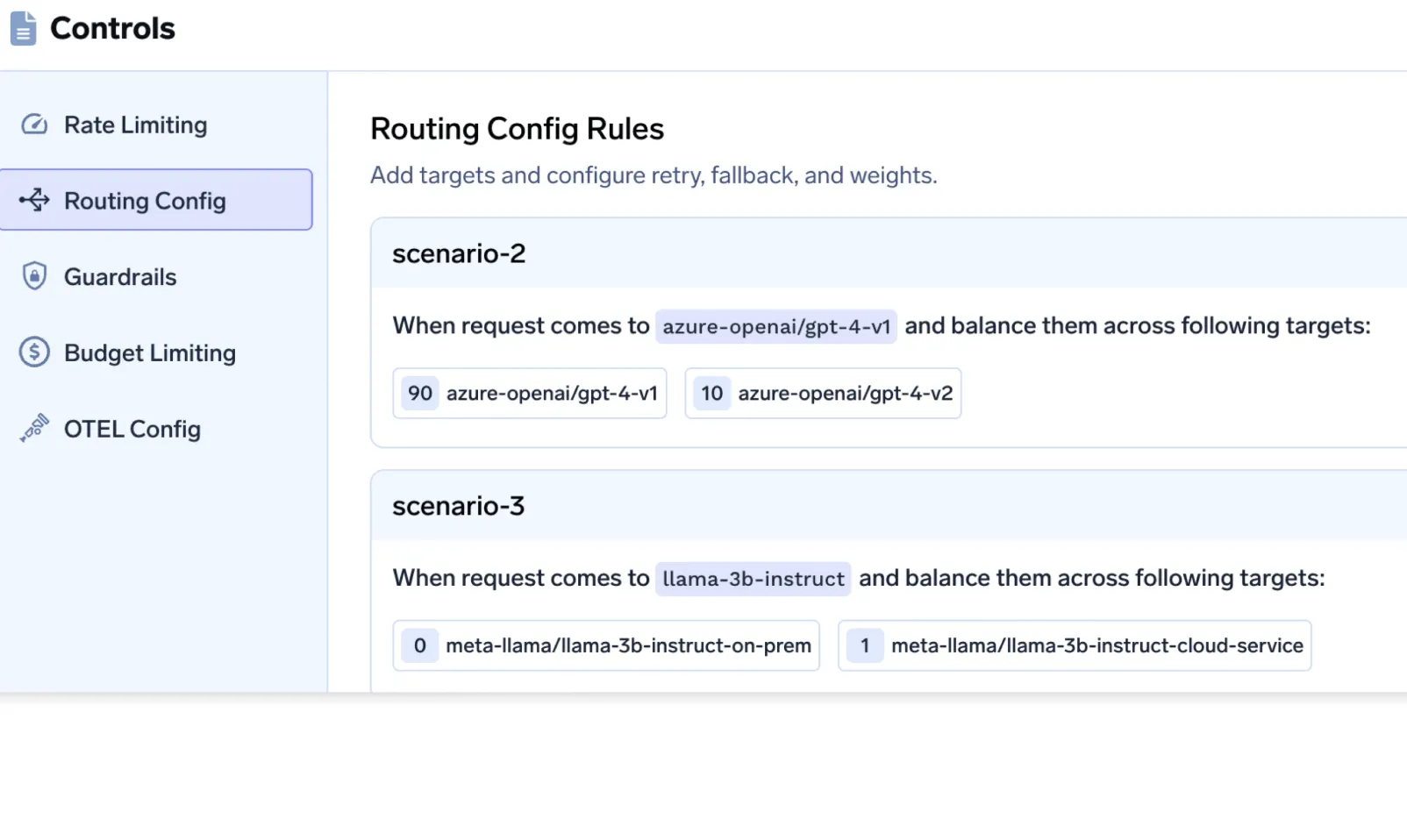
O que acontece em muitos sistemas
Alguns modelos são implantados na região, enquanto outros (muitas vezes backups ou modelos mais recentes) são hospedados globalmente. As políticas de roteamento selecionam, sem intenção, modelos não residentes.
Como a TrueFoundry evita isso
Isso torna as garantias de residência resilientes à rotatividade de modelos e à experimentação.
O que acontece em muitos sistemas
A inferência é executada localmente, mas os agentes invocam ferramentas ou servidores MCP implantados em outras regiões, criando movimentação indireta de dados.
Como a TrueFoundry evita isso
Isso mantém a residência consistente durante a inferência e execução a jusante.
O que acontece em muitos sistemas
Prompts, respostas e rastreamentos são exportados para serviços centralizados de registro ou monitoramento fora da região, muitas vezes por padrão.
Como a TrueFoundry evita isso
Isso fecha uma das lacunas de conformidade mais frequentemente negligenciadas em sistemas de IA.
As garantias de residência só são significativas se puderem ser verificadas e demonstradas. A TrueFoundry permite que as empresas validem a residência de dados através de visibilidade e auditabilidade em tempo de execução, e não por suposições a posteriori.
O Gateway de IA fornece visibilidade sobre:
Isso permite que as equipes confirmem que cada caminho de execução permaneceu em conformidade.
Para revisões de conformidade e segurança, a TrueFoundry apresenta:
Isso torna possível comprovar a residência durante auditorias, em vez de depender apenas de diagramas arquitetônicos.
Uma vantagem fundamental da aplicação ao nível do gateway é a testabilidade.
As empresas podem:
Isso transforma a residência de um requisito estático em uma propriedade de sistema continuamente verificável.
Em sistemas de IA modernos, a residência de dados não pode ser garantida apenas por escolhas de implantação. O roteamento dinâmico, as novas tentativas, os fluxos de trabalho de agentes e os pipelines de observabilidade introduzem caminhos de execução onde os dados podem cruzar silenciosamente as fronteiras regionais.
O AI Gateway é a única camada com contexto suficiente para evitar isso. Ele vê cada solicitação de inferência, cada nova tentativa, cada ação de agente e cada rastro emitido pelo sistema. Se a residência não for imposta aqui, ela não poderá ser imposta de forma consistente em nenhum outro lugar.
Na TrueFoundry, a residência de dados é tratada como uma propriedade de sistema em tempo de execução. Os caminhos de execução são restritos por design, os casos de exceção falham de forma segura e a aplicação é observável e auditável. Isso torna as garantias de residência resilientes não apenas em estado estável, mas também em caso de falha, escala e mudança.
Para empresas que implementam IA em ambientes regulamentados ou multirregionais, essa distinção importa. A residência de dados não é mais um item a ser marcado; é um compromisso arquitetônico. E o AI Gateway é onde esse compromisso se torna realidade.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.






.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




