



.webp)
July 3, 2026
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: May 21, 2026
Blazingly fast way to build, track and deploy your models!
A maioria dos engenheiros encontra o Claude Code pela primeira vez como um preenchimento automático mais inteligente. Peça para ele escrever uma função, e você receberá uma função de volta. Essa abordagem é aceitável até que você comece a usá-lo e perceba que algo diferente está acontecendo.
O Claude Code vai além do simples preenchimento automático. Ele lê arquivos, raciocina sobre bases de código, propõe edições, executa comandos de shell e se ajusta com base nos resultados. Isso é execução, não apenas previsão. Uma vez que um modelo pode executar, o prompt é apenas uma parte da história.
As equipes que percebem isso cedo param de perguntar "o que o Claude Code pode fazer?" e começam a fazer uma pergunta melhor: como o fluxo de trabalho realmente funciona? Que tipo de contexto ele está usando? Que ferramentas ele chama? O que acontece quando um teste falha no meio do caminho? Como ele decide tentar novamente?
O prompt não responde a essas perguntas. As respostas estão no fluxo de trabalho.
Este guia explica como os fluxos de trabalho do Claude Code são estruturados, onde eles falham, como escalá-los em uma equipe e como é o uso em produção depois que as demonstrações terminam. Para entender esses aspectos, primeiro precisamos esclarecer o que é realmente um fluxo de trabalho do Claude Code.
Um fluxo de trabalho do Claude Code não é um prompt. Um prompt é apenas o início do fluxo de trabalho.
O fluxo de trabalho é todo o processo: o modelo recebe uma instrução, extrai contexto da base de código, escolhe quais ferramentas usar, faz alterações, lê os resultados e então decide o que fazer em seguida. Esse ciclo, interpretar, agir, observar, ajustar, é o fluxo de trabalho.
Pense nele como cinco partes que estão todas conectadas:
Um exemplo concreto torna isso mais claro. Você diz ao Claude Code: "Adicione validação de entrada ao manipulador de login." O que realmente acontece:
Essa sequência é o fluxo de trabalho — o prompt é uma linha; a execução tem cinco etapas. Para ver como cada etapa se desenrola em detalhes, vamos percorrer o fluxo de trabalho passo a passo.
Um loop de execução estruturado é executado dentro de uma única instrução. Cada etapa tem sua própria lógica e seu próprio modo de falha.
Etapa 1: Ingestão de Contexto
O fluxo de trabalho começa puxando os arquivos relevantes. O Claude Code lê os arquivos-fonte, inspeciona a estrutura do módulo e constrói uma imagem funcional da base de código. Esta etapa é mais importante do que parece. Se você carregar os arquivos errados ou não o suficiente, o modelo começará com uma visão distorcida. Essa distorção é transmitida para tudo o que vem a seguir.
Os limites da janela de contexto significam que esta é sempre uma imagem parcial. A questão é se o recorte é o recorte certo.
Etapa 2: Interpretação do Prompt
A instrução é traduzida em um plano de ação. "Corrigir o teste intermitente" ainda não é acionável; o modelo precisa inferir o escopo, identificar quais arquivos são relevantes e se esta é uma tarefa de depuração, uma reescrita de teste ou um problema de fixture. A ambiguidade nesta etapa tende a aparecer como desvio mais tarde.
Etapa 3: Invocação de Ferramentas
Uma vez que a tarefa é enquadrada, ele começa a chamar as ferramentas. Leitura de arquivos. Busca de símbolos. Geração de patches. Comandos de shell. Neste ponto, o fluxo de trabalho deixa de ser passivo. O modelo está agindo no repositório, não apenas raciocinando sobre ele. É também aqui que os limites de permissão e as configurações das ferramentas começam a importar.
Etapa 4: Execução e Feedback
A alteração proposta foi aplicada. Então o fluxo de trabalho lê o que realmente está acontecendo: testes são executados, builds compilam ou falham, linters reclamam. A execução produz feedback. Esse feedback é o que transforma uma geração única em um loop agêntico. O modelo não termina quando produz um diff. Ele só é concluído quando o loop de feedback se fecha.
Etapa 5: Iteração
Com base no que retornou, o modelo se ajusta. Ele pode refinar o patch, abrir outro arquivo, mudar a abordagem ou determinar que a tarefa está completa. Este loop pode parar rapidamente em tarefas bem definidas. Pode sair do controle em tarefas mal definidas, especialmente quando o contexto piora durante a execução.
O caminho de execução aproximado é o seguinte:
ler arquivos → interpretar tarefa → invocar ferramentas → aplicar patch → executar testes → observar saída → iterar ou parar.
Compreender este caminho ajuda a clarificar a arquitetura subjacente aos fluxos de trabalho do Claude Code.
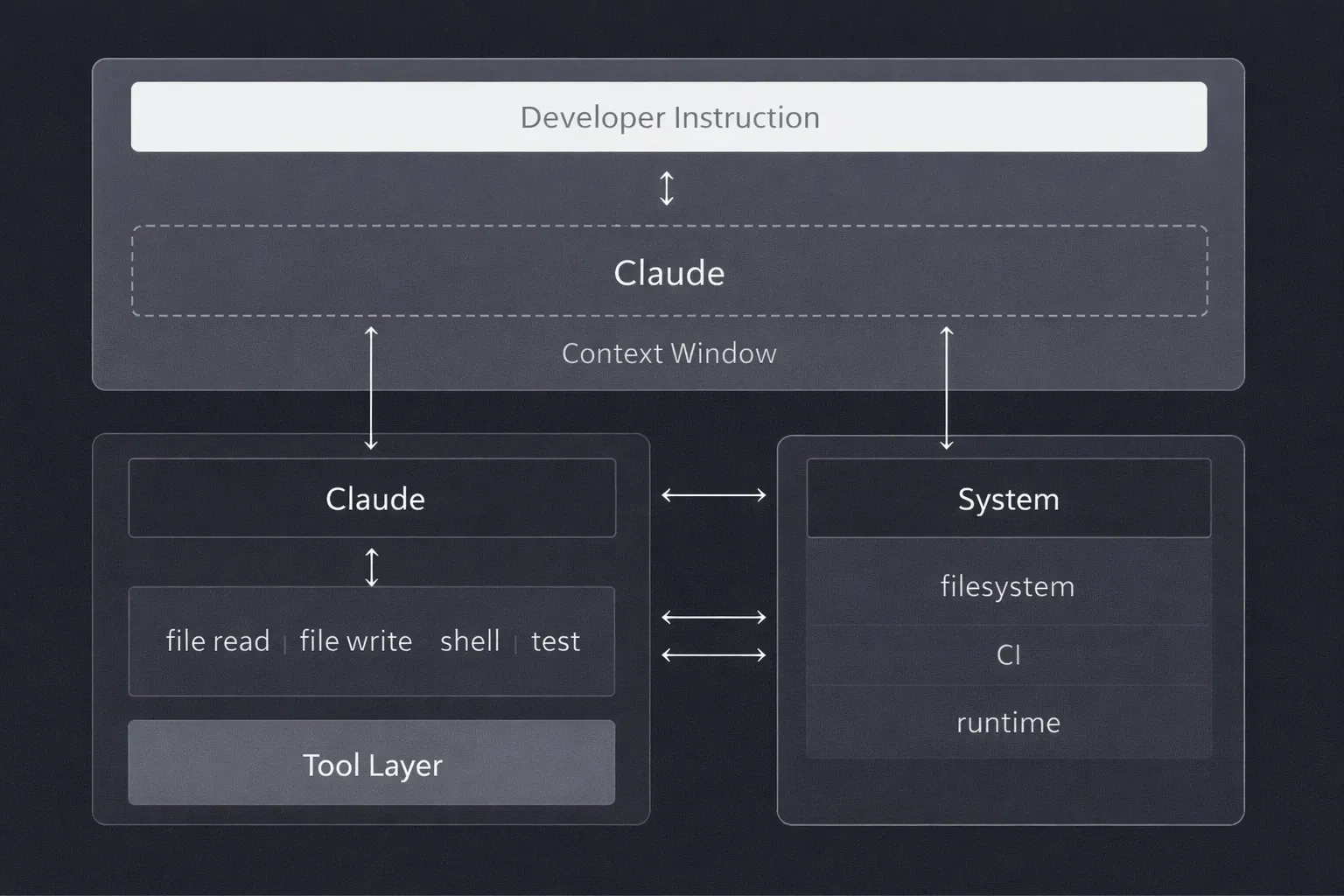
No nível mais alto, a arquitetura segue um caminho simples:
instrução do desenvolvedor → Claude → camada de ferramentas → sistema de arquivos e tempo de execução.
Mas cada limite introduz restrições que moldam como o fluxo de trabalho realmente se comporta.
A Janela de Contexto
Claude opera dentro de uma janela de contexto limitada. Ele não consegue ler todo o código-base de uma vez. Ele vê uma fatia que foi escolhida pelo que foi carregado no início da execução e pelo que se acumulou durante a execução. Isso não é um erro; é uma propriedade fundamental. Mas significa que cada decisão que o modelo toma é baseada em informações incompletas, mesmo quando não parece assim do lado de fora.
A Camada de Ferramentas
Claude não modifica arquivos ou executa comandos diretamente. Ele chama ferramentas que o fazem. Leituras de arquivos, edições e execuções de shell são expostas como interfaces estruturadas. Em princípio, essa abstração mantém o fluxo de trabalho composível e auditável. Você pode inspecionar o que o modelo solicitou. Mas também significa que falhas na camada de ferramentas (timeouts, gravações parciais, formatos de saída inesperados) aparecem como problemas de comportamento do modelo quando, na verdade, são problemas de infraestrutura.
Gerenciamento de Estado
O estado reside em dois lugares. O estado implícito se acumula dentro da janela de contexto à medida que o raciocínio avança. Durante a execução, o estado explícito é gravado em arquivos, logs e saídas de comando. Quando a janela de contexto se enche ou é cortada, o estado implícito se degrada. O modelo continua executando, mas usa uma imagem interna diferente daquela com a qual começou.
5. Onde os Fluxos de Trabalho do Claude Code Falham
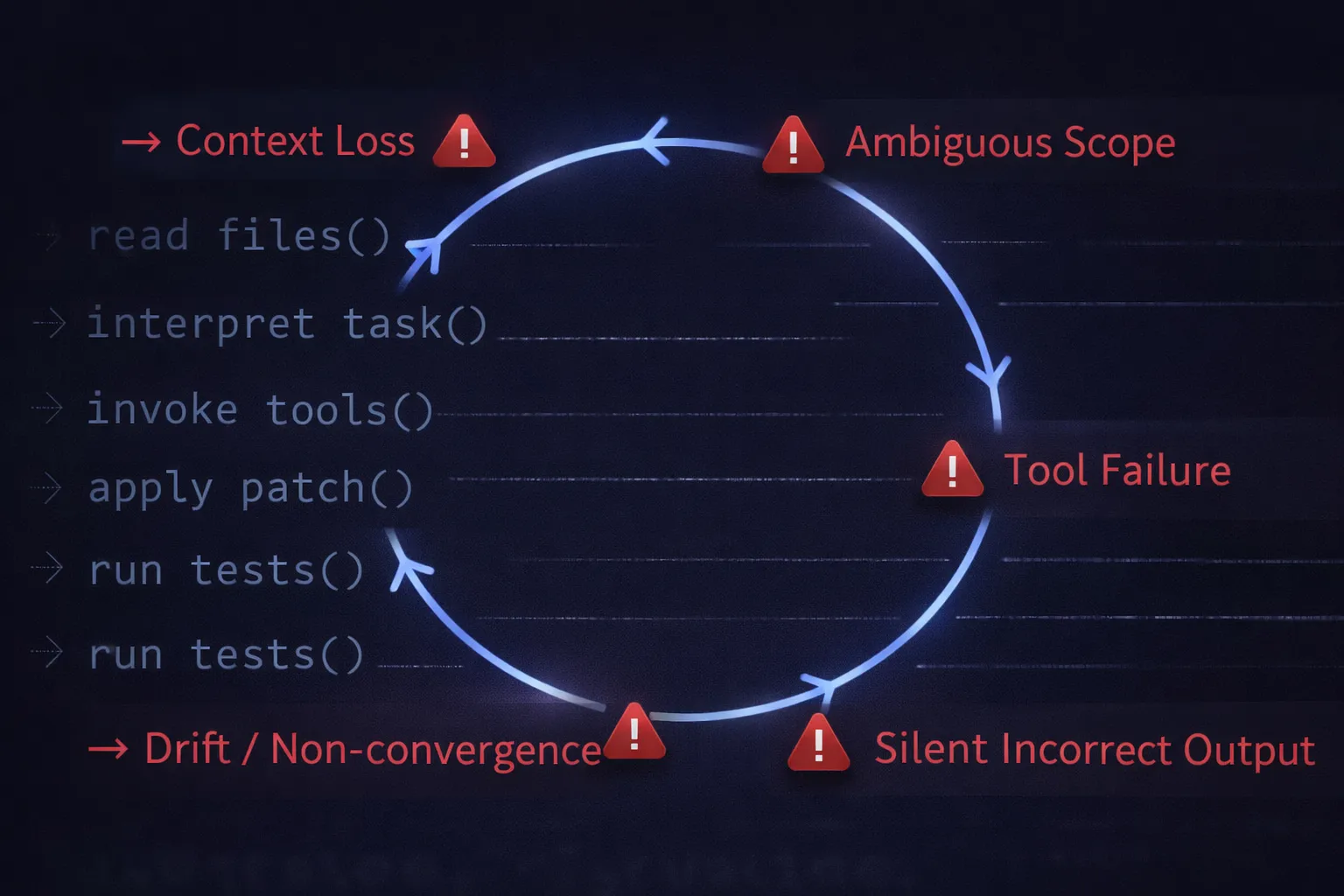
Esta é a parte que as equipes frequentemente ignoram. O modo de falha raramente é dramático. O Claude Code geralmente não produz código obviamente ruim. Ele falha silenciosamente, com edições de aparência plausível que estão sutilmente erradas, mudanças que passam nos testes, mas perdem a intenção, e um raciocínio que se desvia no meio da execução sem um sinal claro.
Perda de Contexto
O fluxo de trabalho começa com os arquivos corretos. Então, mais contexto é carregado, saídas adicionais de ferramentas, patches intermediários e resultados de comandos. A janela de contexto se enche. Algo é descartado. O modelo continua raciocinando, mas contra uma imagem interna diferente. Nada parece obviamente quebrado. É isso que o torna perigoso.
Alterações de Código Alucinadas
Uma chamada de função no patch gerado referencia um objeto inexistente. Uma refatoração introduz uma dependência que nunca foi necessária. O diff parece limpo demais, quase. Ele chega formatado como código correto. É exatamente por isso que ele passa despercebido na revisão.
Falta de Observabilidade
Você vê o diff final. Você não consegue ver a ordem das leituras e novas tentativas que o produziram. Quando a saída está errada, não há um rastro confiável explicando por que o modelo descarrilou. A depuração se torna uma arqueologia retrospectiva em vez de uma instrumentação prospectiva.
Baixa Reprodutibilidade
Execute a mesma tarefa duas vezes, e os resultados divergem. Nem sempre de forma dramática, mas o suficiente para tornar a depuração de padrões irritante. O contexto varia ligeiramente entre as execuções. As saídas das ferramentas diferem. O modelo segue um caminho diferente para o mesmo problema. A reprodutibilidade é um requisito operacional subestimado, especialmente quando esses fluxos de trabalho afetam código crítico.
Falhas de Ferramentas
O modelo funciona com o que as ferramentas retornam. Um comando shell expira. Um executor de testes sai com saída parcial. Uma gravação de arquivo é bem-sucedida, mas o conteúdo é truncado. O modelo responde ao que realmente obteve, não ao que deveria ter. O que parecia robusto quando testado localmente rapidamente se desfaz quando a infraestrutura real está envolvida.
A robustez vista em demonstrações rapidamente cede lugar à fragilidade com infraestrutura real. Essas falhas complicam a escalabilidade dos fluxos de trabalho em equipes e sistemas maiores.
6. Desafios na Escalabilidade de Fluxos de Trabalho com Claude Code
Um desenvolvedor executando um fluxo de trabalho é um experimento de produtividade. Uma equipe de engenheiros executando fluxos de trabalho sobrepostos em uma base de código compartilhada torna-se um problema operacional. As falhas tornam-se facilmente identificáveis em escala, mas mais difíceis de isolar.
Complexidade Multi-Repositório
Em um único repositório, o modelo pode construir uma imagem funcional do código. Essa imagem se desfaz quando você adiciona uma malha de serviço, múltiplos repositórios, bibliotecas compartilhadas e dependências com versão fixa. Uma mudança que parece correta dentro de um repositório cria uma inconsistência sutil em outro. O fluxo de trabalho não sabe o que não pode ver.
Coordenação de Equipe
Dois engenheiros pedem independentemente ao Claude Code por mudanças semelhantes. Eles recebem padrões diferentes. Nenhum está errado, exatamente, mas agora existem duas maneiras de resolver o mesmo problema na base de código. Sem estado compartilhado ou visibilidade sobre o que o agente já tocou, a coordenação se desfaz no nível do fluxo de trabalho, não apenas no nível do código.
Escopo de Segurança e Permissões
Fluxos de trabalho agentivos que podem executar comandos shell ficam próximos dos limites de produção. Permissões muito amplas aumentam o raio de impacto. Permissões muito restritas causam falhas imprevisíveis falhas. Nenhum dos problemas é resolvido ajustando os prompts. Requer configuração deliberada de ferramentas e controle de acesso em nível de infraestrutura.
Governança e Auditabilidade
Em algum momento, alguém acabará perguntando: "Qual fluxo de trabalho alterou este arquivo? Que comando foi executado como parte dessa tarefa? Quem o aprovou?" Se o sistema não consegue responder a essas perguntas, ele carece de governança. Ele tem atividade. Essa distinção importa quando esses fluxos de trabalho tocam em código que lida com dinheiro, autenticação ou dados.
Depuração em Escala
Depurar uma única execução falha já é complicado porque os rastreamentos de execução estão incompletos. Depurar padrões em muitas execuções é mais difícil. As saídas variam ligeiramente por execução. O contexto difere. O comportamento da ferramenta muda. Sem um log de execução estável e estruturado, reproduzir uma falha é uma perseguição em vez de uma investigação.
7. Melhores Práticas para Fluxos de Trabalho em Produção
O uso em produção muda o que importa. Em uma demonstração, o objetivo é a qualidade da saída. Em produção, o objetivo é a execução confiável, auditável e repetível. As práticas que o levam a isso não são sobre o modelo; são sobre como você estrutura o sistema ao seu redor.
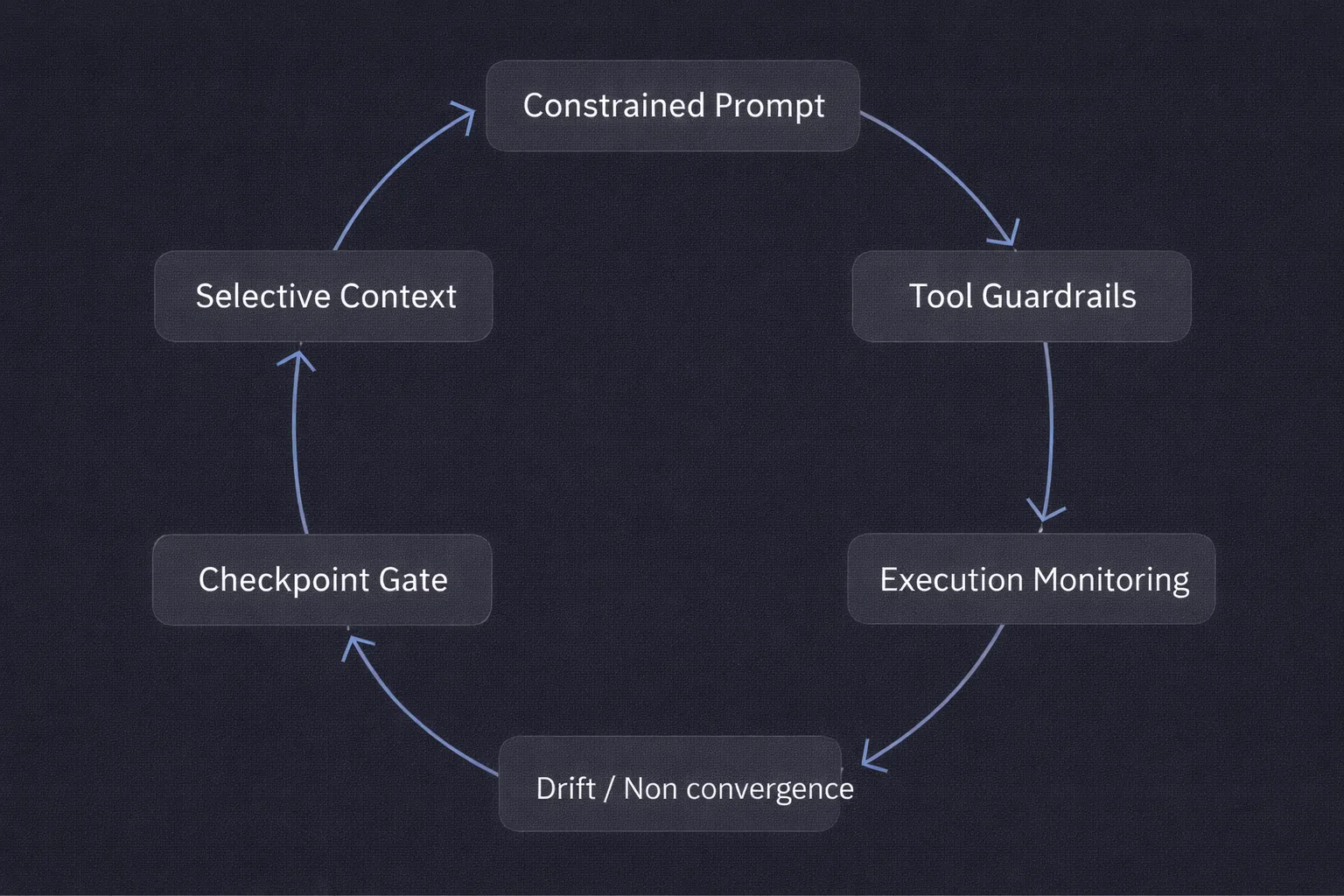
Escreva Prompts com Restrições, Não Apenas Intenção
"Refatorar o módulo de autenticação" é uma direção. "Refatorar o módulo de autenticação para consolidar a lógica de validação de token duplicada, mas não alterar as assinaturas de métodos públicos e não tocar no diretório de migrações" é uma restrição. Restrições são mais úteis do que entusiasmo. Elas dão ao fluxo de trabalho algo concreto para respeitar, não apenas um destino geral.
Controle o Contexto de Forma Deliberada
Mais contexto nem sempre é melhor. Carregar metade do repositório junto com logs desatualizados e arquivos de saída não relacionados aumenta o ruído sem aumentar a precisão. Fluxos de trabalho eficazes são seletivos: alimente o modelo com o suficiente para raciocinar sobre a tarefa, não com tudo o que possa estar tangencialmente relacionado. A disciplina aqui é aparar, não adicionar.
Defina Explicitamente as Permissões das Ferramentas
Se o fluxo de trabalho está gerando testes, provavelmente não precisa de acesso a scripts de implantação. Se está refatorando código de aplicação, acesso amplo ao shell é desnecessário. Restringir o acesso às ferramentas reduz o raio de impacto e diminui a superfície de raciocínio que o modelo precisa navegar. Mais restrito geralmente é mais confiável.
Adicione Pontos de Verificação Antes da Execução
Uma etapa de revisão de diff, um sinalizador de dry-run e um portão de confirmação antes que as alterações sejam aplicadas. Isso retarda ligeiramente o fluxo de trabalho e detecta suposições fracas suposições antes que se tornem commits. Em sistemas agentivos, o ponto de verificação não é burocracia; é o local onde o julgamento humano se integra à execução automatizada. Removê-lo é uma aposta de que o modelo nunca se desviará.
Instrumente o Caminho, Não Apenas a Saída
Saber que o código final compilou não é suficiente. É preciso saber quais arquivos foram lidos, quais comandos foram executados, quantas tentativas ocorreram e como era o estado intermediário. Um fluxo de trabalho pode produzir uma saída correta e ainda assim ser instável. Essa instabilidade geralmente aparece no rastreamento da execução antes de se tornar um incidente.
8. Quando Usar Fluxos de Trabalho de Código Claude (e Quando Não Usar)
Os fluxos de trabalho de Código Claude são úteis para tarefas que são suficientemente estruturadas para serem feitas automaticamente, mas suficientemente entediantes para que as pessoas sempre as adiem. Essa é uma categoria bastante específica, e ser claro sobre isso economiza tempo.
Onde Funcionam Bem
Onde Falham
A decisão não é Claude Code versus nenhum Claude Code. É Claude Code com o escopo certo, versus Claude Code sendo solicitado a fazer algo em que não consegue se restringir de forma confiável.
9. Conclusão
A mudança do preenchimento automático para a execução agêntica já está em andamento. Claude Code não é um motor de sugestões mais inteligente; é um sistema de execução que lê, age, observa e se ajusta. Essa distinção muda o que significa confiabilidade.
Um fluxo de trabalho Claude Code bem executado oferece algo real: menos tempo gasto em refatorações mecânicas, cobertura de testes mais rápida e tarefas de migração que não ficam presas no backlog de alguém. Mas a expressão "bem executado" tem um peso significativo nessa frase. Ele precisa de controle cuidadoso do contexto, permissões de ferramentas definidas, prompts estruturados, pontos de verificação antes da execução e instrumentação do que realmente foi executado.
As equipes que entendem isso tratam o fluxo de trabalho menos como um prompt inteligente e mais como um sistema de execução delimitado, um que precisa da mesma disciplina operacional que qualquer outra peça de infraestrutura que afeta o código de produção.
Uma vez que os fluxos de trabalho começam a modificar repositórios, executar comandos e operar em ambientes reais, eles deixam de ser experimentos. Eles se tornam infraestrutura. A questão então é se o sistema circundante oferece visibilidade e controle suficientes para tornar isso seguro.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.


Fluxos de trabalho no Claude são sequências estruturadas de tarefas que o Claude executa para atingir um objetivo complexo. Em vez de responder a um único prompt, os fluxos de trabalho do Claude encadeiam várias etapas, como ler um arquivo, analisar seu conteúdo, gerar código, executar testes e confirmar alterações em um pipeline automatizado.
O objetivo de um fluxo de trabalho do Claude é permitir que o Claude conclua tarefas de várias etapas e de longo prazo com mínima intervenção humana. Os fluxos de trabalho permitem que os desenvolvedores automatizem tarefas de engenharia repetitivas ou complexas, como refatorar uma base de código, gerar documentação ou executar testes de regressão, definindo a sequência de ações que o Claude deve realizar.
Os três componentes básicos de um fluxo de trabalho do Claude são: (1) a instrução inicial ou prompt que define o objetivo, (2) as ferramentas e servidores MCP que o Claude usa para coletar contexto e realizar ações, e (3) o ciclo de feedback onde o Claude avalia as saídas intermediárias e ajusta seus próximos passos de acordo.
O melhor tipo de fluxo de trabalho do Claude depende da tarefa em questão. Para tarefas bem definidas e repetíveis, como formatação de código ou geração de testes, um fluxo de trabalho roteirizado e determinístico funciona melhor. Para pesquisas exploratórias ou tarefas de depuração onde o caminho não é conhecido antecipadamente, um fluxo de trabalho agêntico, onde o Claude seleciona ferramentas dinamicamente e se adapta com base em resultados intermediários, tende a produzir os resultados mais robustos.






As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.






.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




