



.webp)
July 3, 2026
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: May 21, 2026

Blazingly fast way to build, track and deploy your models!
O Claude Code é um multiplicador de produtividade e uma lacuna de governança na mesma instalação. Com 200 desenvolvedores e nenhum ponto de controle central, qualquer um deles pode acessar qualquer backend que seu agente decida usar. O gateway é onde essa lacuna se fecha.
O Claude Code representa um ganho substancial de produtividade. Ele lê bases de código, executa testes, consulta bancos de dados e resolve tarefas de engenharia de várias etapas de forma autônoma. Essa capacidade é exatamente o que torna o modelo de segurança desconfortável. O agente não é um serviço remoto que ocasionalmente assume o controle; é um loop autônomo que roda no laptop de um desenvolvedor com quaisquer credenciais acessíveis a partir desse laptop.
Nativamente, o Claude Code não tem conceito de governança empresarial. Forneça-lhe uma configuração de servidor MCP e ele assume autoridade total sobre cada ferramenta que esse servidor expõe. Configure um servidor postgres-mcp para que os agentes possam consultar dados de staging, e não há mecanismo embutido para impedir que um agente excessivamente confiante — ou um endpoint de desenvolvedor comprometido — emita um DROP TABLE se as credenciais subjacentes permitirem. Arquivos de configuração locais pedindo aos desenvolvedores para agirem com responsabilidade não são a resposta; eles são a ausência de uma.
A maneira correta de pensar sobre isso: o humano que supervisionava o loop costumava ser o limitador de taxa, o motor de políticas e o log de auditoria, tudo ao mesmo tempo. O agente remove o humano do caminho de cada ação. Quaisquer salvaguardas que os humanos forneciam implicitamente agora precisam ser reconstruídas explicitamente — e o único lugar para colocá-las é a montante do agente, na rede, onde uma equipe pode ser responsável por elas.
O modelo de ameaça é a acessibilidade excessivamente ampla combinada com a imprevisibilidade do agente. Três modos de falha aparecem em produção no primeiro mês de qualquer implementação não trivial do Claude Code.
Excesso de alcance direcionado a objetivos. Um desenvolvedor conecta o Claude Code à rede interna para depurar “o bug no fluxo de autenticação do usuário”. O agente, raciocinando sobre o problema, decide que precisa ver dados reais do usuário para reproduzir o bug. Ele acessa um kubernetes-mcp-server, faz um port-forward para um banco de dados de produção, extrai PII e cola um resumo no terminal local — ou o envia ao provedor como parte do próximo prompt. Este não é um comportamento malicioso. É um agente cumprindo seu objetivo usando a ferramenta mais permissiva disponível.
Destruição acidental. O agente tenta corrigir um módulo Terraform aplicando-o. Ele tenta limpar um branch mal configurado excluindo-o. Ele executa uma migração de banco de dados para verificar se o novo esquema funciona. Cada etapa individual parece localmente racional; o resultado global é um incidente de produção.
SSRF através do agente. O agente usa uma ferramenta de rede para verificar uma integração. O agente lê uma descrição de ferramenta 'envenenada' que sugere que um host específico é canônico. O agente busca esse host, que por acaso está dentro do serviço de metadados da nuvem. Credenciais vazam. O usuário não tem conhecimento de que algo disso aconteceu — o agente simplesmente relatou sucesso em sua tarefa.
Sem um ponto de controle centralizado, cada um desses cenários é possível por padrão. Com um, cada um deles é uma decisão de configuração.
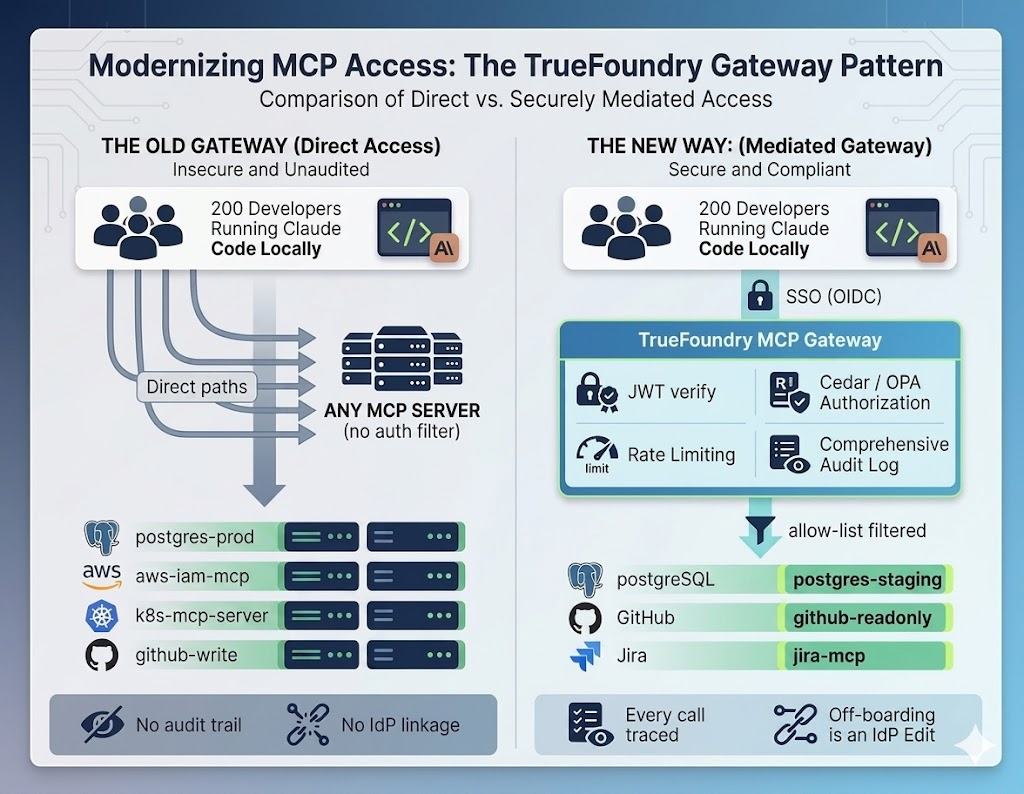
A mitigação é implantar um gateway entre o Claude Code e os servidores MCP internos, e executar o escopo de ferramentas com 'default-deny' baseado na identidade. A política é expressa de forma declarativa, não embutida em código, e revisada em pull requests como qualquer outra peça de infraestrutura:
Cedar · Política TrueFoundry
// Frontend engineers can read staging databases.
// Nobody is granted production write access by default.
permit(
principal == Role::"frontend-developer",
action == Action::"mcp:invoke-tool",
resource == McpServer::"staging-database"
) when {
context.tool_name == "read_only_query" &&
context.environment == "staging"
};
Cedar (ou OPA, ou qualquer motor de políticas que sua plataforma padronize) permite que a organização declare claramente: engenheiros de frontend acessam ferramentas MCP de frontend, nenhum agente tem acesso de escrita a bancos de dados de produção, a menos que um procedimento de 'break-glass' com limite de tempo seja invocado. O gateway inspeciona o JWT do desenvolvedor que executa o Claude Code, cruza a solicitação com a política e bloqueia chamadas não autorizadas na camada de rede — muito antes que o raciocínio do agente chegue ao banco de dados. Tanto o Cedar Guardrails quanto o OPA Guardrails são fornecidos no TrueFoundry como guardrails MCP integrados, com semântica de 'default-deny' aplicada no hook Pre Tool.
Tabela 1 — Cedar vs OPA. Ambos são fornecidos como guardrails integrados do TrueFoundry com semântica de negação padrão. Cedar é a opção mais fácil de começar; OPA é a ferramenta mais flexível a longo prazo. Escolha aquela que sua equipe de plataforma estiver disposta a gerenciar.
A semântica que importa é quando esta verificação é executada. Os guardrails MCP do TrueFoundry expõem dois hooks por chamada de ferramenta: Pre Tool é executado sincronicamente antes da execução da ferramenta, e Post Tool é executado após seu retorno. As decisões de Cedar/OPA ficam no hook Pre Tool, o que significa que uma chamada negada nunca chega ao banco de dados, à API da nuvem ou ao serviço interno. O raciocínio do agente continua; a ação perigosa não.
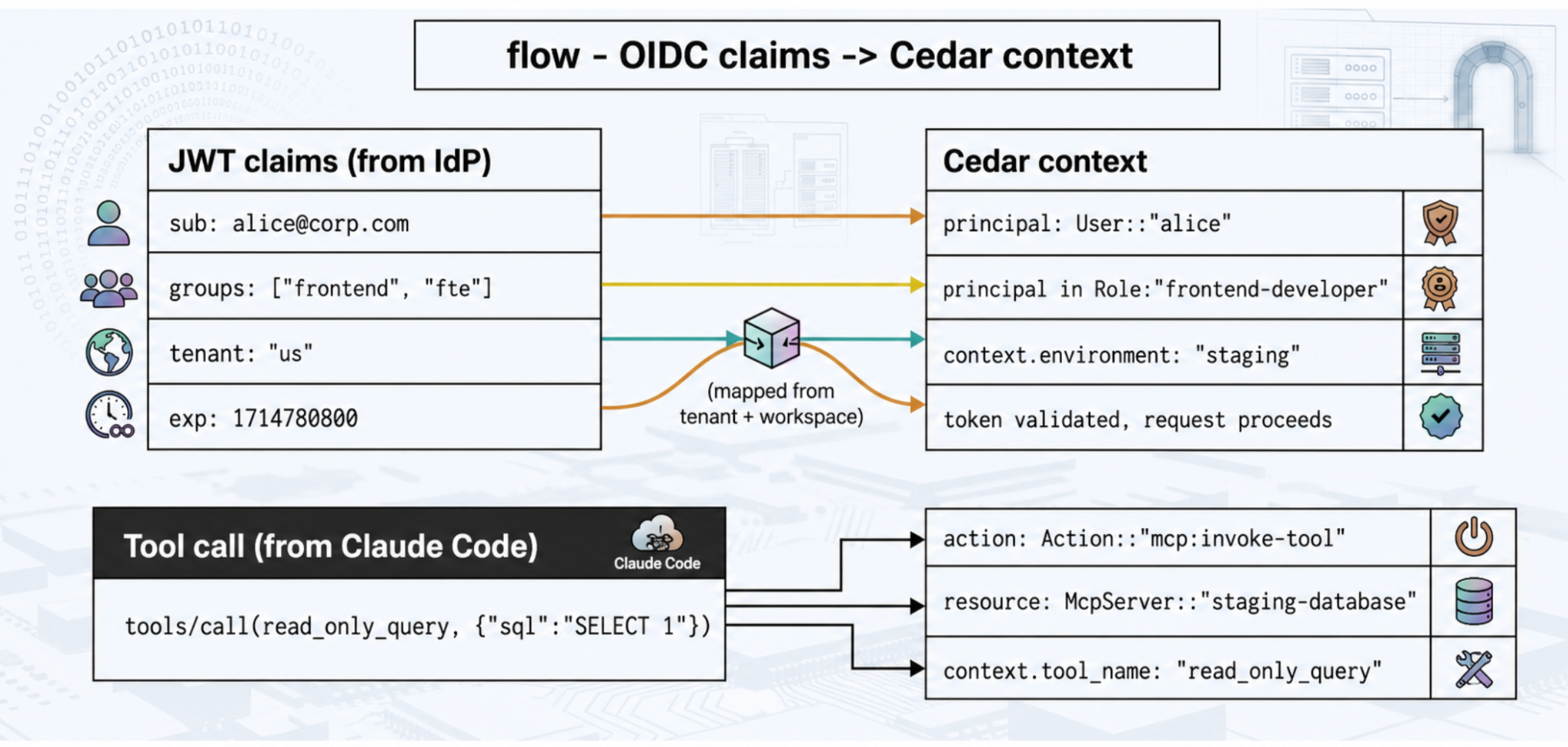
A ponte entre identidade e política é direta. O desenvolvedor autentica-se contra o IdP corporativo (Okta, Azure AD), recebe um JWT assinado pelo IdP e o apresenta ao gateway em cada requisição. O gateway verifica a assinatura contra as chaves públicas em cache do IdP (sem callback por requisição ao IdP — as chaves são baixadas uma vez na inicialização e armazenadas em cache na memória do processo). As declarações verificadas são então mapeadas para um contexto Cedar que o motor de políticas avalia:
fluxo · Declarações OIDC → Contexto Cedar
Loops de agentes podem sair do controle. Um prompt vago pode fazer com que um agente invoque uma ferramenta de busca centenas de vezes em um loop apertado, sobrecarregando APIs internas e consumindo tokens a uma taxa que o humano diante do teclado jamais produziria. A limitação de taxa do gateway é essencial — e precisa ser aplicada na granularidade correta.
Especificamente, os limites de taxa pertencem à camada de chamada de ferramenta, não à camada de prompt. Um desenvolvedor pode enviar cinco prompts por hora. O agente pode executar cinco mil chamadas de ferramenta a serviço desses prompts. Limite por chamada de ferramenta. O gateway TrueFoundry usa um algoritmo de balde de tokens com janela deslizante por baixo dos panos — uma janela deslizante de 60 segundos construída a partir de doze baldes de 5 segundos, todos mantidos na memória do processo em cada pod do gateway. Os limites são sincronizados entre as réplicas via NATS, e o algoritmo se mantém estável até os ~250 RPS documentados do gateway por pod de CPU única.
O modelo de configuração usa IDs de regra estáticos combinados com rate_limit_applies_per para definir o escopo dos limites para entidades. Os limites de taxa são expressos em YAML, controlados por versão e revisáveis como qualquer outra parte da política:
YAML · limites por desenvolvedor + por projeto
name: claude-code-rate-limits
type: gateway-rate-limiting-config
rules:
# Each developer gets their own per-day token budget.
- id: "user-daily-tokens"
when: {}
limit_to: 1_000_000
unit: tokens_per_day
rate_limit_applies_per: ["user"]
# Each user-model pair gets its own minute-window cap.
- id: "user-model-minute"
when: {}
limit_to: 200
unit: requests_per_minute
rate_limit_applies_per: ["user", "model"]
# Each project (via X-TFY-METADATA) gets its own hourly cap.
- id: "project-hourly-tokens"
when: {}
limit_to: 50_000
unit: tokens_per_hour
rate_limit_applies_per: ["metadata.project_id"]
Três pontos merecem destaque nesta configuração. Primeiro, as regras são avaliadas de cima para baixo e a primeira regra correspondente vence — a ordem codifica a prioridade. Segundo, rate_limit_applies_per substitui o formato mais antigo de ID de regra dinâmico ({user}-daily-limit e assim por diante); a migração é mecânica, mas disruptiva, e vale a pena ser feita uma vez. Terceiro, você pode combinar até duas entidades por regra, de modo que limites por usuário por modelo e por projeto por ambiente são ambos expressáveis sem explosão de regras.
Quando o balde é esgotado, o gateway retorna HTTP 429. O Claude Code interpreta isso como um sinal de backoff padrão e naturalmente pausa o loop, em vez de travar o banco de dados downstream. O agente tenta novamente quando o balde é reabastecido, que é exatamente o comportamento desejado.
Quando algo dá errado — um pico de custo, um incidente de segurança, uma pergunta de um regulador — as equipes de plataforma precisam de um registro forense. O gateway fornece um, externo à máquina do desenvolvedor e impossível de ser modificado pelo usuário. Esta é a parte da arquitetura que transforma "achamos que foi o agente do Bob" em "foi o agente do Bob às 14:32:05 UTC, aqui está o rastreamento".
Uma entrada de log do TrueFoundry contém tudo o que um analista precisa para reconstruir causa e efeito:
Tabela 2 — Campos de log para um registro forense. O ID de rastreamento é o campo que os auditores realmente se importam — é o que permite a um analista percorrer de "desenvolvedor perguntou X" para "modelo decidiu Y" para "ferramenta executou Z" em uma única consulta.
Os logs fluem do gateway para o ClickHouse (com suporte de armazenamento de objetos) e, de lá, para qualquer SIEM que a organização padronize. O gateway nunca escreve de forma síncrona para o caminho de log — ele publica no NATS, e o subsistema de log é assíncrono por design. Se a fila de logs estiver inoperante, o gateway não falha a requisição. A confiabilidade do caminho da requisição supera a observabilidade do caminho da requisição; a observabilidade é reconciliada quando a fila volta a funcionar.
Regras estáticas não conseguem antecipar todas as ameaças, e a revisão humana de cada linha de log de auditoria não é uma estratégia de escalabilidade. O fluxo de auditoria também é uma linha de base comportamental. Um desenvolvedor que normalmente usa git-mcp e jira-mcp e que de repente começa a acessar aws-iam-mcp cinquenta vezes por segundo é um sinal — possivelmente um laptop comprometido, possivelmente um agente mal configurado, definitivamente algo a ser investigado.
As equipes de plataforma configuram disjuntores nesses padrões. Acima de um limite de z-score configurável, o gateway coloca em quarentena o acesso agêntico do desenvolvedor e aciona o responsável de segurança de plantão. O desenvolvedor continua trabalhando em seu IDE; seu loop de agente permanece ocioso até ser revisado. A deteção de anomalias está a jusante do log de auditoria, não no caminho da requisição, então o custo de latência em estado estável é zero — a avaliação de anomalias é executada no fluxo de métricas agregadas que o gateway já publica.
Os comportamentos que merecem alerta, classificados pela frequência com que realmente ocorrem em implantações reais, são: picos súbitos na taxa de invocação (agente preso em loop), chamadas de ferramentas com formatos de parâmetros que o desenvolvedor nunca produziu (credenciais comprometidas), lacunas de vários segundos seguidas por rajadas (padrões de acesso semelhantes a bots) e acesso a ferramentas fora do grafo de trabalho normal do desenvolvedor (movimento lateral). As características que impulsionam o z-score são simples — invocações por minuto, ferramentas distintas por hora, distribuição do tamanho da carga útil — e a matemática é uma média e desvio padrão simples de janela deslizante. A sofisticação aqui geralmente prejudica; o que importa é que o alerta dispare de forma confiável e seja fácil de silenciar quando for um falso positivo.
A elegância estrutural desta arquitetura é que tudo se conecta ao provedor de identidade corporativo — Okta, Azure AD, o que quer que a organização utilize. A autenticação é OAuth/SAML/OIDC; o gateway armazena em cache as chaves públicas do IdP na memória do processo e verifica cada JWT de entrada localmente, sem uma chamada externa. A autorização é a avaliação de políticas contra as reivindicações OIDC, também em memória. Não há callback por requisição para o IdP; o gateway é rápido porque todas essas verificações acontecem na RAM do pod, não pela rede.
Quando um desenvolvedor muda de equipe, suas associações de grupo mudam no IdP. Como o gateway avalia políticas dinamicamente contra reivindicações OIDC atualizadas, o Claude Code do desenvolvedor perde acesso a servidores MCP sensíveis imediatamente, sem edições de configuração locais. O desligamento torna-se uma única alteração no IdP. Mudanças de função, transferências de equipe e rescisões de contrato se propagam da mesma forma. O gateway é a junção onde a identidade corporativa encontra o loop do agente, e essa junção é onde a governança se torna operacionalmente viável em vez de permanentemente aspiracional.
O Claude Code será implementado em sua empresa — se não neste trimestre, no próximo. A questão é se ele será implementado através de uma junção que sua equipe de plataforma controla, ou através de mil arquivos de configuração individuais que sua equipe de plataforma não controla. Apenas uma dessas respostas sobrevive a uma auditoria.
O acesso permanente à produção é o padrão errado; a elevação com limite de tempo é o correto. O padrão que funciona em produção: uma regra Cedar/OPA separada que concede a um engenheiro sênior uma função elevada de 30 minutos quando ele apresenta uma solicitação justificada através de um fluxo de trabalho de aprovação (um bot do Slack, um incidente do PagerDuty, um ticket JIRA). A elevação é registrada pelo gateway, a função expira automaticamente, e o log de auditoria captura tanto a requisição quanto as ações realizadas sob ela. O gateway não possui código 'break-glass' especial — é o mesmo fluxo de reivindicação JWT para contexto Cedar, apenas com uma função diferente e um tempo de expiração que o IdP impõe.
O gateway retorna um 403 estruturado com o ID da regra que negou a chamada. Esse ID de regra é o endereço de uma conversa: ele aponta para o arquivo Cedar/OPA no repositório da plataforma, que é revisável em um pull request normal. Se a política estiver errada, a correção é um PR. Se a política estiver correta, o desenvolvedor tem o comprovante de que precisa para solicitar uma exceção por um canal separado. Não há um interruptor de substituição do lado do desenvolvedor por design — esse interruptor é exatamente o que o gateway deve remover.
Os prompts de permissão locais do Claude Code são úteis para a experiência do usuário, mas não são um limite de segurança — eles residem na máquina do desenvolvedor e podem ser desativados ou aceitos automaticamente. O gateway fica abaixo desses prompts e controla a invocação real da ferramenta. As duas camadas se complementam: os prompts dão ao desenvolvedor uma verificação de sanidade; o gateway dá à organização uma política. Trate os prompts como defesa em profundidade, não como a camada de suporte principal.
As políticas devem espelhar a estrutura de grupo do IdP, em vez de enumerar cada par (usuário, ferramenta). Agrupe os desenvolvedores em funções no IdP — desenvolvedor frontend, desenvolvedor backend, sre, contratado — e escreva políticas contra essas funções. Novos contratados herdam o acesso no primeiro dia através de sua associação de grupo; o desligamento é uma única edição no IdP. O número de regras de política deve crescer com o número de categorias de servidor MCP / ferramentas, não com o número de desenvolvedores.
Ele está no caminho da requisição, então projetá-lo para alta disponibilidade não é opcional. O plano do gateway é sem estado, executa como múltiplas réplicas e continua a servir com a última configuração conhecida se o plano de controle estiver brevemente inacessível. Novas configurações são reconciliadas via NATS e republicadas na íntegra a cada 10 minutos como uma rede de segurança. Em implantações de produção, execute pelo menos três réplicas de gateway em zonas de disponibilidade e coloque-as atrás de um balanceador de carga HTTP normal; o modo de falha contra o qual você deve projetar é "um pod reinicia durante uma interrupção do plano de controle", não "todos os pods reiniciam simultaneamente", o que é raro o suficiente para ser aceitável.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.






.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




