



.webp)
July 3, 2026
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: May 21, 2026

Blazingly fast way to build, track and deploy your models!
Todos nós já tivemos aquele momento com o Interpretador de Código do ChatGPT (agora "Análise Avançada de Dados"). Você carrega um CSV bagunçado, pede para ele "corrigir as datas e plotar a tendência", e observa maravilhado enquanto ele escreve e executa código Python em tempo real.
É uma superarma de produtividade. É também uma enorme falha de segurança se você estiver trabalhando com dados sensíveis.
No momento em que você carrega esse CSV, ele está saindo do seu perímetro. Para a nossa equipe, o objetivo era replicar essa capacidade "OpenCode" – dando aos nossos agentes LLM a capacidade de escrever e executar código – sem os riscos de exfiltração de dados. Não queríamos uma API de "caixa preta"; precisávamos de um Interpretador de Código Privado onde o processamento acontece próximo aos dados.
Veja como implementamos o Uso Seguro de Ferramentas e a execução de código usando os componentes de infraestrutura da TrueFoundry.
'OpenCode' não se trata apenas de ter um modelo que pode escrever Python. Ele requer três componentes distintos trabalhando em uníssono:
A maioria das pessoas trava em "As Mãos". Você não pode simplesmente deixar um LLM executar os.system('rm -rf /') no seu cluster de produção. Você precisa de um sandbox.
A TrueFoundry resolve isso permitindo-nos implantar ambientes de execução efêmeros (Serviços ou Jobs) que atuam como o sandbox. O LLM Gateway lida com as definições de uso de ferramentas, e a execução real acontece em um contêiner isolado dentro da nossa VPC.
Aqui está o fluxo de trabalho de como uma solicitação do usuário se transforma em execução segura de código.
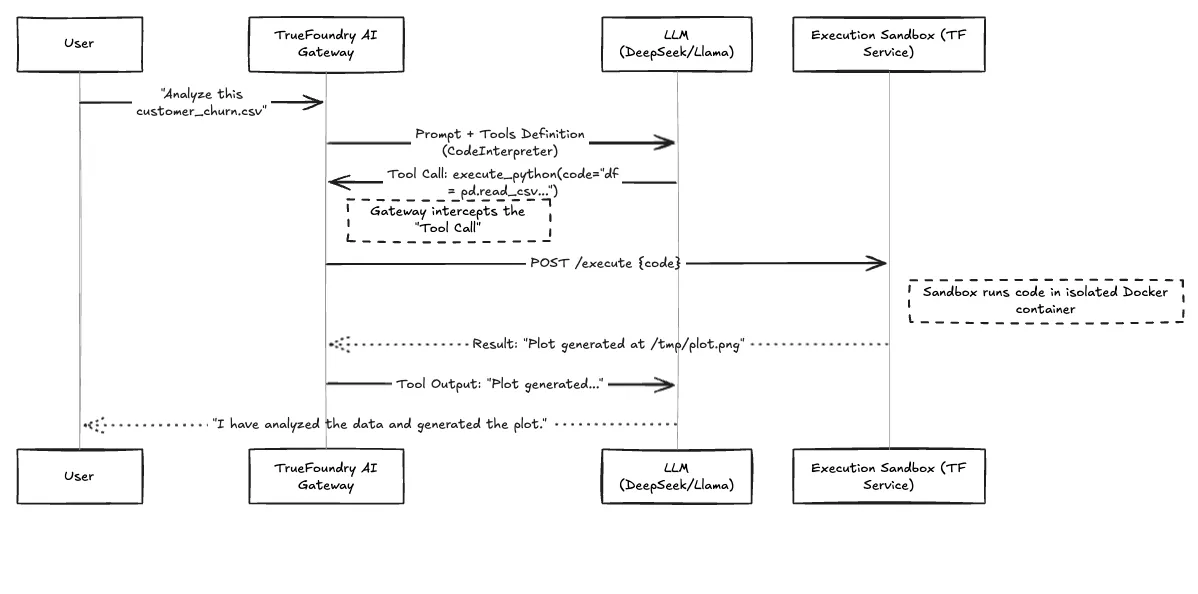
Fig. 1: Fluxo de trabalho do Loop de Execução OpenCode
Quando tentamos construir isso pela primeira vez, subestimamos a complexidade do ambiente de execução. Se você usa uma API de Intérprete de Código SaaS padrão, você está enviando seus dados para eles. Se você o executa localmente, você corre o risco de comprometer o host.
Utilizamos TrueFoundry Serviços para hospedar um "Agente de Execução de Código" personalizado. Isso é essencialmente um serviço Python FastAPI empacotado em um contêiner Docker que possui:
Como a TrueFoundry gerencia o manifesto Kubernetes subjacente, podemos injetar essas restrições de segurança (SecurityContext, NetworkPolicies) diretamente da UI de implantação ou do Terraform, garantindo que o sandbox seja realmente um sandbox.
A compensação sempre foi conveniência vs. controle. Ao alavancar a TrueFoundry para orquestrar o padrão "OpenCode", alteramos o equilíbrio. Obtemos a conveniência de uma implantação gerenciada sem o risco de dados.
Tabela 1: Este é o Exemplo de Comparação de Gateway e Sandbox
O verdadeiro poder se revela quando você combina Uso de Ferramentas com suas APIs internas.
Configuramos o Gateway LLM da TrueFoundry para expor não apenas a ferramenta "Interpretador Python", mas também ferramentas para o nosso data lake interno (por exemplo, get_user_churn_metrics(user_id)).
Como o LLM está roteando através do Gateway, e o Gateway está conectado aos nossos serviços privados, o modelo agora pode:
Tudo isso acontece sem que um único byte de dados do cliente saia da nossa sub-rede privada.
Implementar "OpenCode" não é mais apenas um projeto divertido de hackathon; é um requisito para agentes de IA modernos. Mas você não pode simplesmente improvisar com LangChain e esperar o melhor.
Tratamos nosso Interpretador de Código como infraestrutura crítica. Nós o monitoramos usando a pilha de observabilidade da TrueFoundry – rastreando não apenas os tokens LLM, mas também os picos de CPU no sandbox e a latência de execução. Se um usuário escreve um script que tenta alocar 50GB de RAM, a TrueFoundry encerra o pod antes que ele afete o cluster, e o usuário recebe uma mensagem de erro educada.
Essa é a diferença entre uma demonstração e uma plataforma.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.






.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




