



.webp)
July 3, 2026
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: May 21, 2026

Blazingly fast way to build, track and deploy your models!
Montar uma plataforma de IA Generativa em Microsoft Azure significa integrar primitivos distintos de computação, identidade e IA. Você provisiona capacidade bruta via Azure Kubernetes Service (AKS) e VMs Spot, gerencia a identidade via Entra ID e roteia solicitações para o Azure OpenAI. A fricção surge quando suas equipes de infraestrutura precisam orquestrar essas conexões manualmente para cada nova implantação de modelo.
O TrueFoundry é implantado como uma camada de infraestrutura dentro da sua assinatura do Azure. Nós gerenciamos o ciclo de vida da implantação, a federação de identidade e o autoescalonamento. Esta publicação detalha os padrões exatos de integração que usamos para conectar o TrueFoundry ao Azure, abordando a implantação de plano dividido, os limites de rede e a mecânica da identidade da carga de trabalho.
Utilizamos uma arquitetura de plano dividido para isolar a execução da carga de trabalho do gerenciamento da plataforma. Se você constrói plataformas em Amazon EKS, este modelo parecerá familiar: você separa a superfície de controle do plano de dados.
Conectamos os dois planos usando um seguro, apenas de saída gRPC stream ou WebSocket. O agente do lado do cluster inicia a conexão com o Plano de Controle para buscar manifestos e enviar logs. Você não abre nenhuma porta de entrada em seus Grupos de Segurança de Rede da VNET. Sua VNET nega o ingresso externo da internet por padrão.
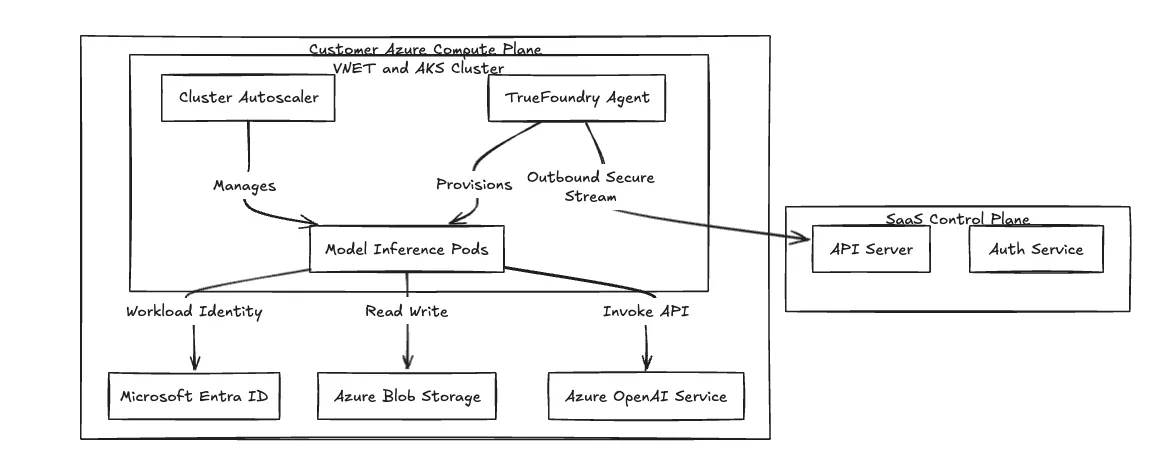
Fig. 1: A Arquitetura de Plano Dividido isola o processamento de dados dentro da VNET do cliente.
Configuramos a rede do plano de computação usando o Azure CNI para atribuição direta de IP no nível do pod. Seus recursos de computação permanecem em sub-redes privadas.
Para limites de conformidade rigorosos, direcionamos o tráfego através do Azure Private Link. As conexões dos seus pods de inferência para Azure OpenAI, Key Vault e Blob Storage são roteadas inteiramente pela rede principal da Microsoft.
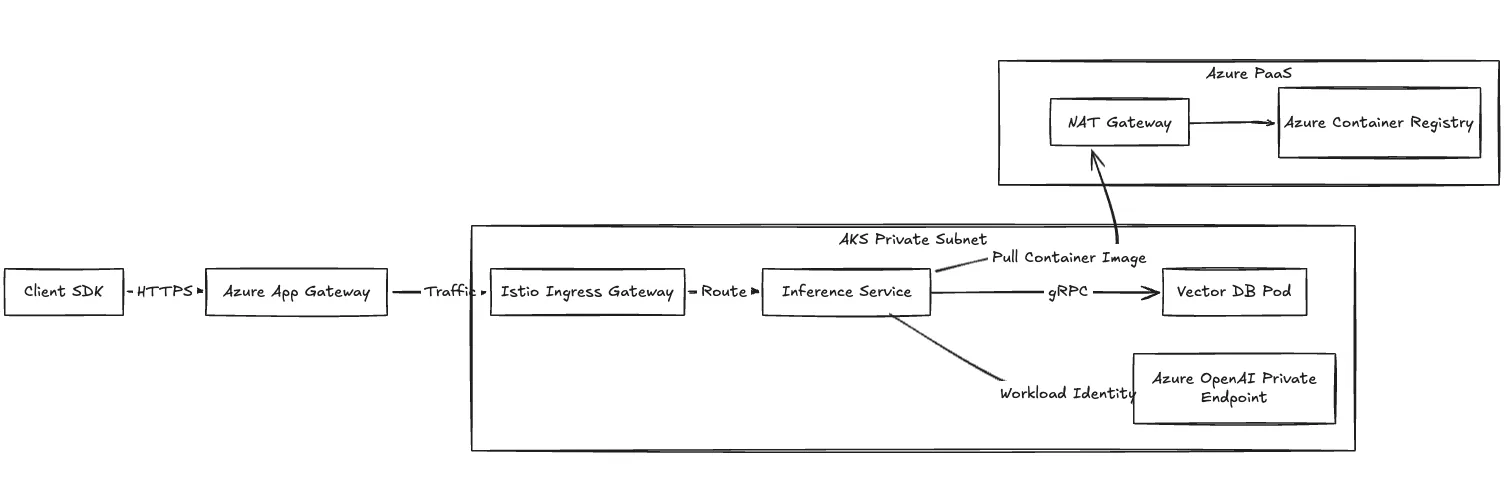
Fig. 2: Fluxo de tráfego de rede detalhando a entrada e a conectividade privada para Azure PaaS.
Segredos estáticos codificados e Service Principals introduzem uma sobrecarga significativa de rotação. Autenticamos cargas de trabalho dinamicamente usando o Microsoft Entra Workload ID. Se você gerencia ambientes AWS, este é o equivalente no Azure a AWS IAM Roles for Service Accounts (IRSA).
Ao implantar um pipeline, executamos esta sequência:
Usamos DefaultAzureCredential no código da aplicação. Isso restringe o raio de impacto estritamente às permissões RBAC concedidas a essa Identidade Gerenciada específica.
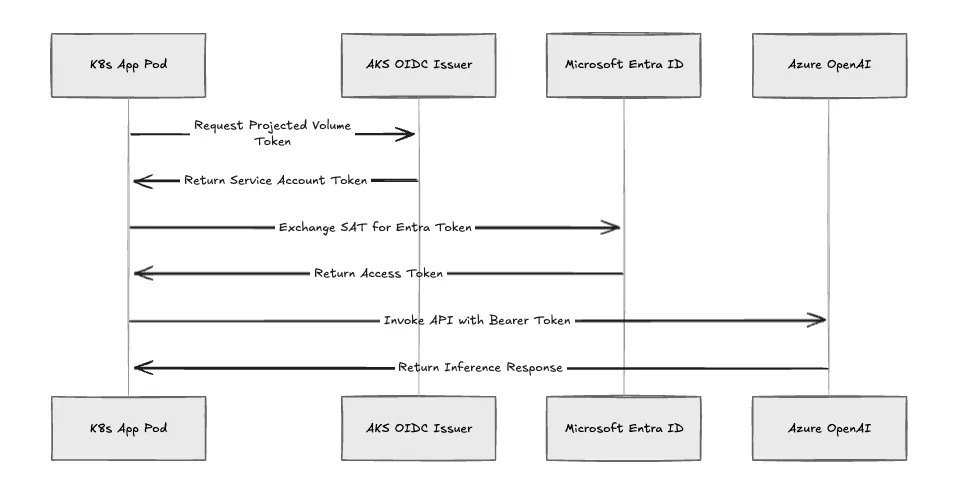
Fig 3: O fluxo de autenticação do Entra Workload ID.
Executar inferência em estado estacionário em VMs sob demanda geralmente resulta em custos base mais altos. Integramos diretamente com pools de nós do AKS para orquestrar Máquinas Virtuais Spot do Azure (semelhante à utilização de Instâncias Spot do Amazon EC2).
Gerenciamos a capacidade Spot usando a seguinte lógica:
Para equipes que executam inferência em lote ou serviço de API tolerante a falhas, essa configuração — muito parecido com a execução de Karpenter na AWS — pode reduzir os custos de instâncias de computação em até 80%, dependendo da flexibilidade da carga de trabalho.
Gerenciar chaves de API distintas e limites de Token-Por-Minuto (TPM) em várias regiões do Azure cria atrito operacional. O TrueFoundry AI Gateway abstrai isso. Semelhante ao roteamento de solicitações através do Amazon Bedrock, os desenvolvedores acessam um único endpoint de API interno.
Alinhamos-nos com práticas padrão de GitOps e IaC. Você provisiona o ambiente Azure subjacente usando nosso mantido Terraform módulos.
Seu estado Terraform gerencia as VNETs, o cluster AKS, os emissores OIDC e os bancos de dados PostgreSQL subjacentes. A camada de sobreposição TrueFoundry simplesmente mapeia para esses recursos nativos, mantendo sua infraestrutura auditável e em conformidade.
A implantação do TrueFoundry no Azure isola a execução de seus recursos de computação e dados enquanto gerenciamos o ciclo de vida do aplicativo. Você mantém autoridade direta sobre suas VNETs, NSGs e perímetros de residência de dados. Nós cuidamos da orquestração. Ao abstrair a complexa interconexão entre AKS, Entra ID e Azure OpenAI, permitimos que suas equipes de engenharia se concentrem em entregar modelos em vez de lutar contra a infraestrutura.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.






.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




