



.webp)
July 3, 2026
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: May 21, 2026

Blazingly fast way to build, track and deploy your models!
Para engenheiros e arquitetos DevOps que operam dentro do perímetro da AWS, Amazon Bedrock Agents—conhecido arquitetonicamente como o AgentCore runtime—é o caminho padrão para a construção de fluxos de trabalho de agentes. Ele padroniza os complexos loops recursivos necessários para os agentes, lidando com o raciocínio, a memória e a orquestração de API que os desenvolvedores anteriormente criavam manualmente usando bibliotecas como LangChain.
A adoção de um framework de agente gerenciado, no entanto, muitas vezes exige uma compensação entre a velocidade inicial e o controle arquitetônico de longo prazo. Ele acopla a lógica da aplicação à filosofia de orquestração de um provedor de nuvem específico. Este relatório analisa a arquitetura técnica dos Agentes Amazon Bedrock, avalia as realidades operacionais em relação à observabilidade e o contrasta com uma abordagem de plano de controle agnóstico usando o TrueFoundry Platform.
Os Agentes Bedrock funcionam como um motor de orquestração projetado para executar tarefas multi-etapas. Ao contrário de uma chamada de API InvokeModel sem estado, um Agente opera como um loop com estado.
Ao definir um Agente no Bedrock, os desenvolvedores configuram três primitivas distintas:
A principal utilidade é automatizar as etapas de raciocínio. Quando um usuário pede para "Verificar o inventário do Item X e atualizar o banco de dados", o tempo de execução decompõe esta solicitação:
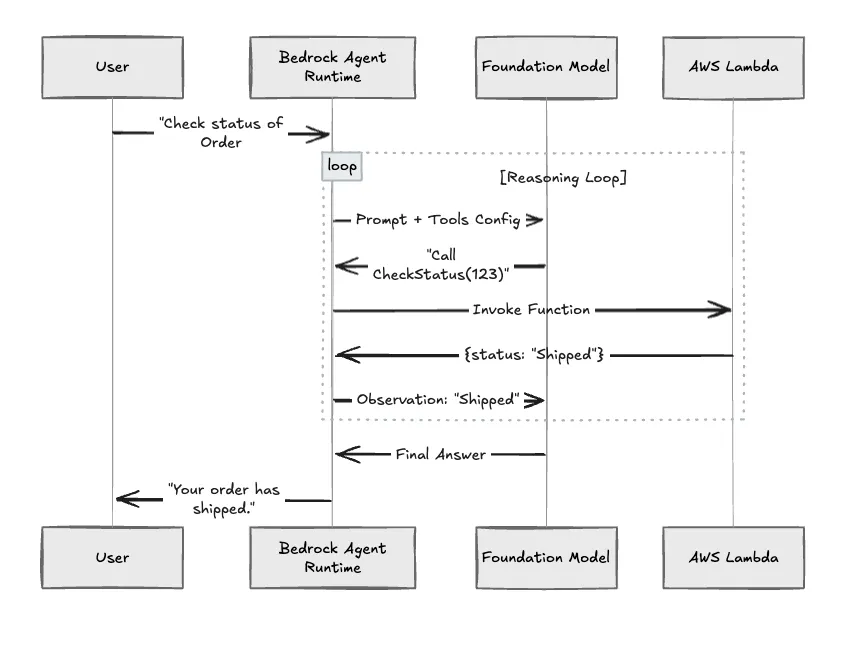
Fig. 1: O loop de orquestração recursivo gerenciado pelos Agentes AWS Bedrock.
Serviços gerenciados aceleram a implantação inicial, mas as operações do Dia 2 — depuração, escalabilidade e migração — frequentemente revelam o custo da abstração.
Em um ambiente de execução totalmente gerenciado, o loop de prompt é abstraído. As instruções do sistema e as definições de ferramentas são construídas pela AWS e enviadas ao LLM por trás do limite do serviço.
Se um agente alucinar ou chamar a ferramenta errada, a depuração pode ser complexa porque a janela de contexto bruta e as etapas de raciocínio intermediárias são frequentemente gerenciadas implicitamente. Isso pode levar as equipes a se concentrarem em depurar a saída final em vez de inspecionar o processo de raciocínio granular.
Arquiteturas que utilizam um AI Gateway como o TrueFoundry mantêm a lógica de orquestração transparente. O "cérebro" do agente é executado na sua infraestrutura, garantindo que cada prompt, token e etapa de raciocínio seja visível em ferramentas de rastreamento como OpenTelemetry ou Arize.
Os Agentes Bedrock são otimizados para o ecossistema AWS. Chamar uma ferramenta nativamente geralmente implica que a ferramenta existe como uma função Lambda.
Se uma empresa utiliza ferramentas externas — como um banco de dados Snowflake, uma API Salesforce ou um serviço hospedado no Azure — os desenvolvedores frequentemente coordenam via Lambdas de wrapper na AWS para preencher a lacuna. Isso pode introduzir latência adicional e sobrecarga de manutenção.
A indústria está atualmente se unindo em torno do Model Context Protocol (MCP), um padrão aberto que permite aos agentes conectar-se a fontes de dados universalmente. O TrueFoundry foi projetado para ser nativo de MCP, atuando como um hub neutro onde um agente pode se conectar a um servidor MCP do Google Drive, um banco de dados Postgres local e uma função AWS Lambda simultaneamente, sem wrappers de infraestrutura personalizados.
A TrueFoundry propõe uma arquitetura de Plano de Controle . Em vez de agrupar o modelo, o tempo de execução e as ferramentas num único serviço de nuvem vertical, esta abordagem os desacopla.
Aqui, o Provedor de Nuvem (AWS, Azure, GCP) funciona como o backend escalável para computação e modelos, enquanto o TrueFoundry Gateway permanece a interface governável para aplicações.
Uma característica definidora dos Agentes Bedrock é a vinculação arquitetônica aos modelos Bedrock (Titan, Claude, Llama no Bedrock). Agentes complexos executam muitos passos, e usar um modelo de ponta como Claude 3.5 Sonnet para cada passo de um loop recursivo pode aumentar os custos.
A TrueFoundry facilita o roteamento semântico. O Gateway analisa a complexidade de um passo; se o agente precisar apenas extrair uma data de uma string, a solicitação é roteada para um modelo mais econômico (como Meta Llama) hospedado em Instâncias Spot da AWS. Se o passo exigir raciocínio complexo, ele é roteado para GPT-4o ou Claude 3.5 Opus.
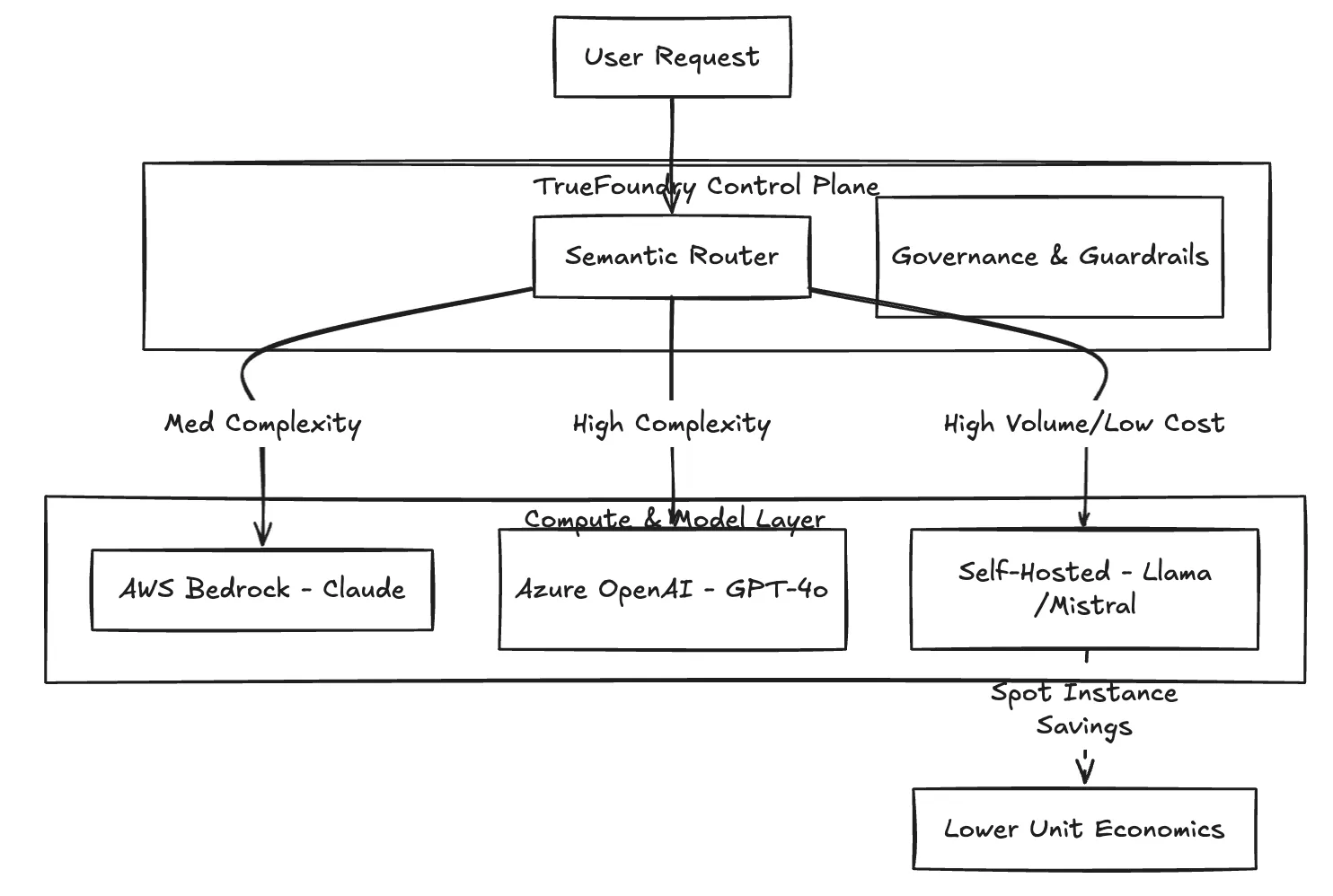
Fig 2: A lógica de roteamento da TrueFoundry otimiza a economia unitária ao corresponder a complexidade da tarefa ao provedor mais econômico.
Esta tabela contrasta as capacidades do serviço gerenciado da AWS com o plano de controle da TrueFoundry.
Para muitas empresas, o futuro não é "Totalmente na AWS" ou "Totalmente no Azure", mas um estado híbrido ditado pela gravidade dos dados e pelo custo.
O AgentCore se destaca quando todo o ciclo de vida dos dados — da ingestão à inferência — reside na AWS. No entanto, à medida que os fluxos de trabalho de agentes escalam, eles frequentemente exigem acesso a dados no Microsoft SharePoint, em Plataformas de Dados de Clientes no Google Cloud ou em data warehouses locais.
A TrueFoundry facilita um padrão de roteamento entre nuvens. A lógica do agente reside no plano de controle, permitindo que ele acesse ferramentas em diferentes nuvens sem atravessar VPNs complexas ou configurar manualmente Gateways de API. Isso torna a pilha à prova de futuro; se Azure OpenAI Service lançar um novo modelo que supere o Claude, ou se o Llama 3 se tornar viável para um caso de uso específico, trocar o motor subjacente é uma mudança de configuração, e não uma reescrita de código.
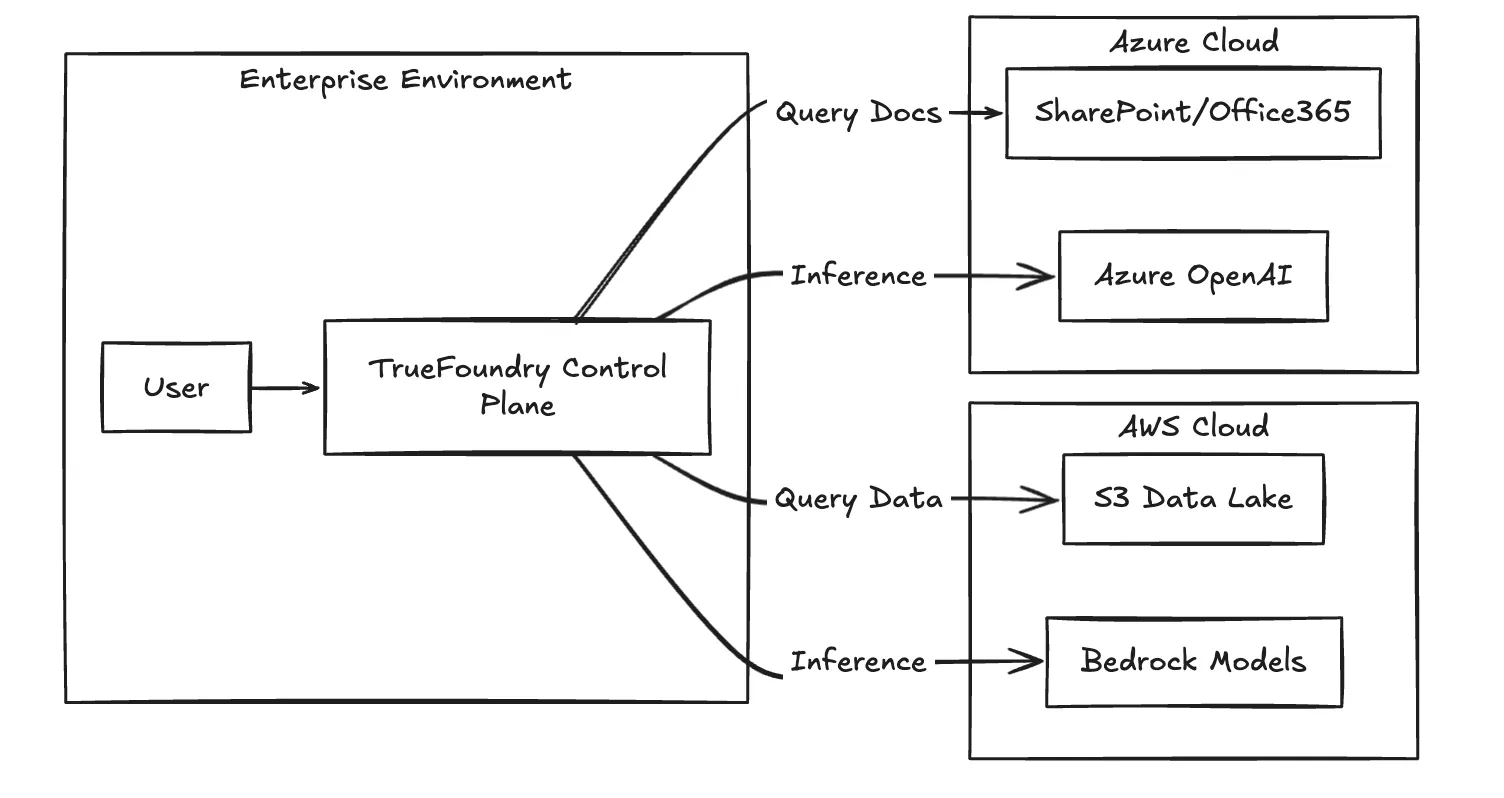
Fig. 3: A arquitetura de roteamento da TrueFoundry que permite o acesso a dados entre nuvens.
A escolha entre o serviço gerenciado da AWS e o plano de controle da TrueFoundry é, efetivamente, uma escolha entre velocidade de integração e opcionalidade arquitetural.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.






.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




