



.webp)
July 3, 2026
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: May 21, 2026
Blazingly fast way to build, track and deploy your models!
A equipe de vendas está em pânico – há uma grande conferência de saúde na próxima semana. O site do evento lista 200 palestrantes – médicos, executivos e pesquisadores – espalhados por uma dúzia de subpáginas paginadas. Para construir uma lista de leads, alguém precisa abrir o site, clicar em um nome, copiar os detalhes para uma planilha, abrir uma nova aba, procurar essa pessoa no LinkedIn, copiar a URL do perfil e colá-la de volta.
Eles precisam fazer isso 200 vezes.

Para engenheiros, essa solicitação geralmente resulta em um script Python rápido usando Selenium ou BeautifulSoup. Você inspeciona o código-fonte da página, encontra a div com a classe speaker-name e extrai o texto. Funciona perfeitamente por cerca de uma semana. Então o site atualiza seu framework de frontend, as classes CSS mudam e o script falha.
Construímos o Profile Crawler acelerador para parar este ciclo. É um agente autônomo que navega em sites e extrai dados com base no que a página diz, não em como o HTML está estruturado.
Veja como arquitetamos a solução usando LangGraph para orquestração, Playwright para interação e TrueFoundry para gerenciar a infraestrutura.
A principal razão pela qual os scripts de scraping falham é a sua dependência do Document Object Model (DOM). Se você instruir um script a procurar por div.content-wrapper > h2.title, ele falhará no momento em que um desenvolvedor mudar o nome de uma classe.
Adotamos uma abordagem agêntica. Não dizemos ao bot onde os dados estão localizados pixel a pixel. Em vez disso, alimentamos o HTML renderizado (convertido para Markdown) a um LLM. O modelo lê o texto como um humano faria. Ele entende que uma seção rotulada como "Keynote Speakers" contém os dados que queremos, independentemente das tags subjacentes.
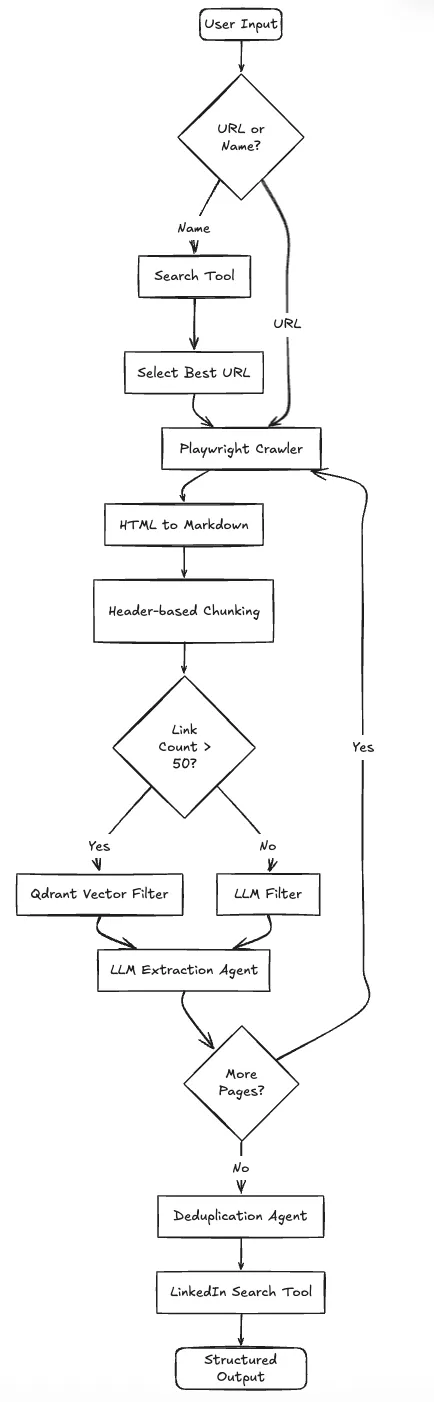
Precisávamos de um sistema capaz de tomar decisões, não apenas um script linear. A aplicação precisa decidir: Esta entrada é um URL ou apenas um nome de empresa? Encontramos um captcha? Esta página é uma lista de pessoas ou uma única biografia?
Escolhemos o LangGraph para modelar este fluxo de trabalho como uma máquina de estados, especialmente onde Langflow vs LangGraph decisões favorecem a orquestração com estado.
O sistema opera em um loop em vez de uma linha reta:
Aqui está a arquitetura do sistema:
Executar navegadores headless e agentes LLM em produção cria dores de cabeça operacionais: vazamentos de memória do Chromium, limites de taxa nas APIs LLM e a necessidade de isolamento de processos.
Nós implementamos isso no TrueFoundry para lidar com essas restrições específicas.
Esta aplicação faz uso intensivo de LLMs para decisões de navegação. Sem governança, os custos aumentam rapidamente. Nós roteamos todas as chamadas de modelo através do TrueFoundry AI Gateway.
Estruturamos a aplicação usando o Protocolo de Contexto do Modelo (MCP). O "Crawler" não é apenas uma função Python; é um Servidor MCP. Isso nos permite isolar o ambiente do navegador. Se o navegador travar (o que acontece frequentemente com sites com muito JavaScript), isso não derruba a lógica principal da aplicação.
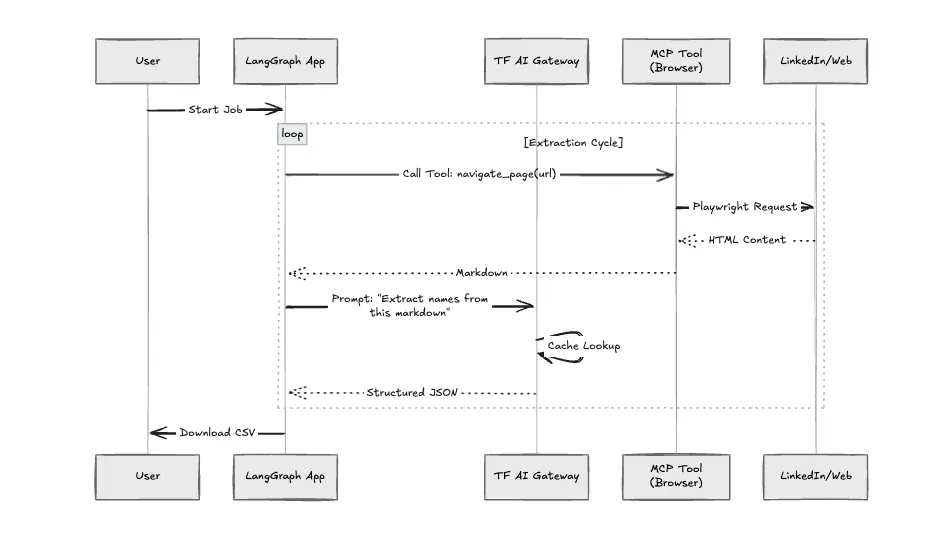
Fizemos um benchmark da abordagem padrão de script Python em comparação com esta arquitetura.
Construir o caminho feliz é fácil. Torná-lo confiável exigiu a resolução de três problemas de engenharia específicos:
Esta arquitetura resolve a "Última Milha" da aquisição de dados, substituindo scripts frágeis por agentes adaptativos. Ao executá-lo no TrueFoundry, garantimos que o sistema seja observável, com custos controlados e escalável.
Você pode implantar esta arquitetura exata -- incluindo a configuração do Gateway e agentes Dockerizados -- da biblioteca de aplicativos TrueFoundry hoje mesmo.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.






.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




