













.webp)
July 4, 2026
|
5 min read

Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
As enterprises scale their AI initiatives, one of the biggest architectural risks they face is vendor lock-in—being tied too tightly to a single model provider or cloud platform. In the rapidly evolving AI ecosystem, where new foundation models and APIs emerge almost weekly, this dependency can quickly limit innovation and flexibility. Teams that commit early to one ecosystem often find themselves unable to adopt newer, better, or more cost-effective models without rewriting large portions of their stack. Preventing lock-in, therefore, is not just a procurement concern—it’s a core technical design challenge.
The risk of vendor lock-in is a critical concern when designing enterprise AI systems. If your AI applications are tightly coupled to a single provider’s APIs, you may find it difficult to adapt when technology, pricing, or compliance needs change. An AI model gateway solves this by acting as an abstraction layer between your applications and multiple model providers. In practice, this means your code talks to the gateway’s unified interface rather than to each vendor directly. The gateway then routes and translates requests to the optimal underlying model (OpenAI, Anthropic, Gemini, a self-hosted LLaMA, etc.) without your application code needing any vendor-specific changes. TrueFoundry’s AI Gateway exemplifies this approach – it offers a single, OpenAI-compatible API to access 1000+ LLMs and vision models, while enforcing enterprise security, governance, and observability. By design, TrueFoundry prevents lock-in: you keep full control over deployment and data formats, and your application code remains vendor-agnostic.
Vendor lock-in occurs when your system becomes so tied to one provider that switching to another is impractical or costly. In AI/ML, this often means writing code directly against one vendor’s SDK or API. While using a single provider (e.g. OpenAI) can be simple at first, it creates dangerous dependencies. For instance, if your integration uses OpenAI’s proprietary API calls, you’ll struggle to migrate if OpenAI’s service is unavailable, changes terms, or a new model (such as Google’s Gemini or a cutting-edge open-source model) becomes superior.
The TrueFoundry team highlights this “Vendor Lock-in Trap”: a hard-coded integration forces you to scramble whenever providers change pricing, deprecate models, or go down for maintenance. More broadly, lock-in shows up as high switching costs – technical (rewriting code for new APIs), contractual (breaking long-term commitments), process (retraining teams), or data formats (moving proprietary data).
Evaluating software for lock-in risk means asking: Can we easily change providers if needed? and Are we forced into proprietary SDKs or data formats? As Progress Software notes, lock-in is less about initial convenience and more about long-term flexibility. You should think of lock-in like any technical debt: plan your architecture to keep options open. In practice, this means favoring open standards (e.g. OpenAI API, Parquet data), containerized deployments, and abstraction layers (like gateways) that allow underlying components to swap out. TrueFoundry’s AI Gateway ensure the application code never contains provider-specific calls, so you won’t be locked to a single AI vendor.
An AI model gateway (also called an LLM or AI gateway) is a middleware layer that sits between your application and any number of AI model providers. It functions like an air-traffic controller or translator: your app issues a single API request to the gateway, and the gateway decides which model instance or vendor to use. The gateway then standardizes the input/output formats and handles security and routing behind the scenes. This unified interface means you never write model-specific code in your application.
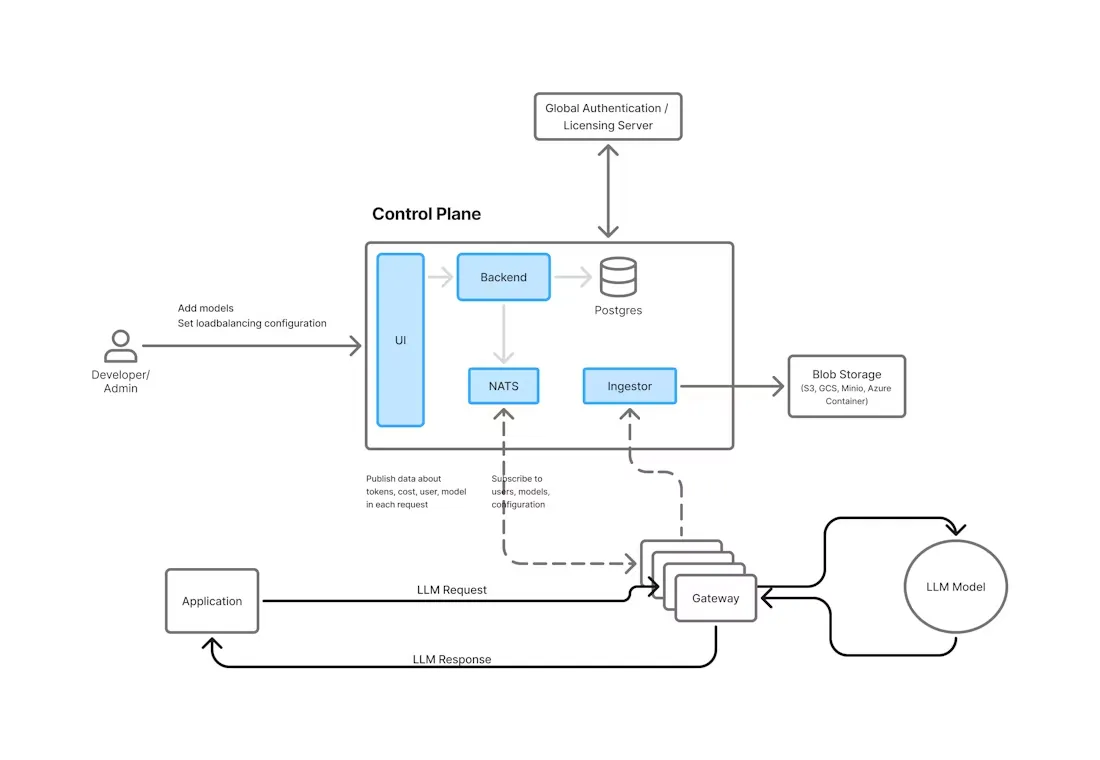
Figure: TrueFoundry AI Gateway architecture (proxy layer between applications and multiple LLM providers).
For example, TrueFoundry’s gateway accepts requests in an OpenAI-compatible format; it can then route the query to OpenAI, Anthropic, a self-hosted model, or any other integrated provider without changing your code.
In essence, an AI gateway provides model abstraction, policy enforcement, and multi-model orchestration in one place. It also adds enterprise capabilities (like RBAC, rate limits, cost controls, and audit logging) on top of each request, treating AI models as managed services. By decoupling the application from provider-specific APIs, gateways dramatically reduce the engineering burden when working with multiple LLMs.
Key Metrics for Evaluating Gateway
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |

AI gateways prevent lock-in by abstracting away provider details. Because your application talks only to the gateway’s unified API, you never hard-code vendor-specific endpoints. For example, TrueFoundry’s gateway supports any OpenAI-compatible model, so if you write your code against TrueFoundry’s OpenAI-style API, you can switch between OpenAI, Azure OpenAI, Anthropic, or your own models with a configuration change – no code rewrite required. This decoupling is critical.
TrueFoundry deliberately uses the standard OpenAI API format for all requests, meaning you can continue using the familiar OpenAI SDK or client libraries. You simply send requests to TrueFoundry’s gateway instead of directly to a vendor. Under the hood, the gateway translates those calls into the appropriate vendor API calls as needed.
TrueFoundry also avoids introducing its own custom SDK. Instead, developers use existing tools and SDKs as before – whether it’s OpenAI’s or another open-source client – and point them at the gateway endpoint. In effect, there is no new “lock-in” created by using TrueFoundry, because you never have to “buy in” to a proprietary interface. Moreover, TrueFoundry’s data formats and logs are all open-standard: for instance, logs are stored in Apache Parquet on customer-managed S3, and metrics use OpenTelemetry. This means you can export and analyze data with any tool you like, further preventing any data-vendor entanglement. In short, by acting as a translator and control plane, AI gateways like TrueFoundry’s ensure you can swap model providers, move workloads to another environment, or even self-host models without rewriting application code.
TrueFoundry’s AI Gateway is engineered for high availability and minimal latency while enforcing policy at scale. Its core is a split control-plane/data-plane architecture. In essence, the control-plane (a central service) manages configuration, models, users, and policies, while lightweight gateway pods process inference requests. These gateway pods are written in a high-performance, event-driven framework (Hono) and are CPU-bound for efficiency.
When a request arrives, the gateway performs all checks in-memory: it validates your JWT token and permissions, applies rate limits or budget caps, and determines which model to use. Importantly, the request enters in the standard OpenAI-compatible JSON format. The gateway then uses its configured routing rules to pick a model provider (e.g. the fastest or cheapest). A built-in adapter component translates the request into the specific format expected by that provider’s API. For example, if the chosen model is on AWS Bedrock or Anthropic, the gateway converts the OpenAI-style request appropriately. This means your app’s code never changes, even though different providers may expect different parameters.
Once the model responds, the gateway returns the output to your app. Simultaneously, it asynchronously logs the request and response (tokens, latency, cost, etc.) into a central store. These logs flow into the analytics backend in your own cloud (TrueFoundry writes them as Parquet into S3 or an S3-compatible store). In brief, TrueFoundry’s design ensures no external calls are needed in the request path (aside from caching), all policy decisions are in-memory, and request logs are decoupled and durable. The result is an AI gateway that adds only ~3–5ms of overhead per call, even at hundreds of requests per second. Its clustered deployment on Kubernetes (via Helm charts) gives you the freedom to run it anywhere – public cloud, private data center, or edge – without changing the application layer.
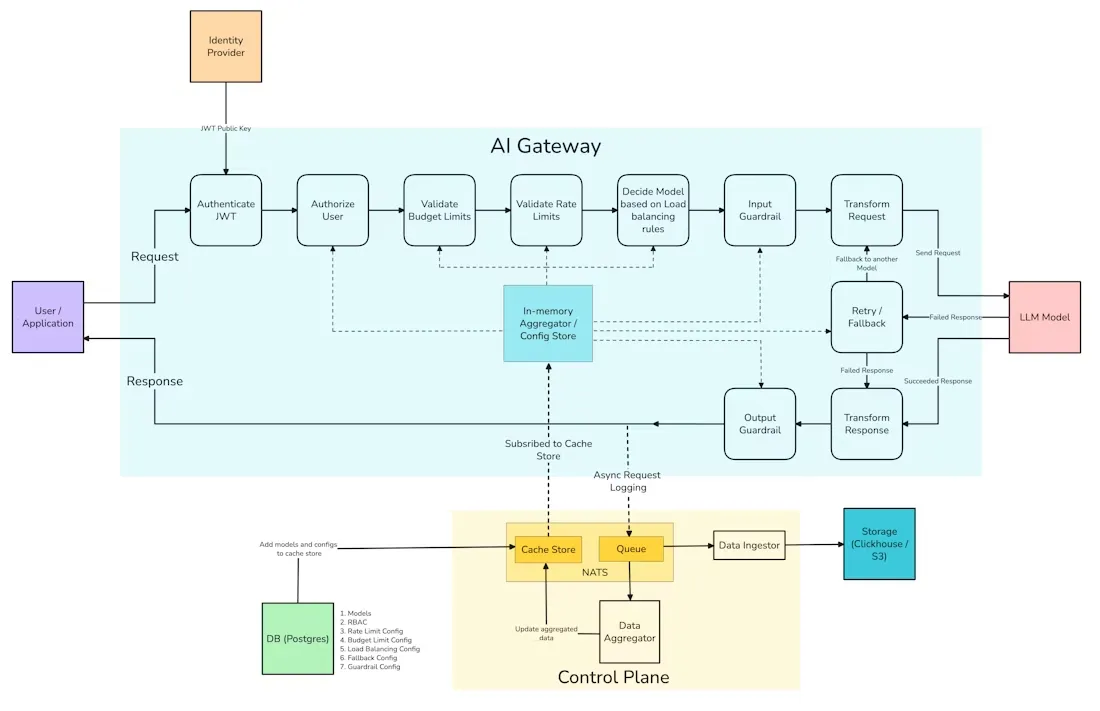
Figure: High-availability architecture of TrueFoundry’s AI Gateway (control-plane & gateway pods).
Internally, TrueFoundry uses a central database (e.g. PostgreSQL) and NATS message queue for configuration distribution. All gateway pods subscribe to real-time updates (users, models, quotas, metrics) via NATS, so policy changes propagate instantly. If a primary provider is unavailable, the gateway can automatically retry or failover to a fallback model. This modular, Kubernetes-native design – combined with an API-driven approach – guarantees you’re never locked into TrueFoundry’s infrastructure. You get the manifests and helm charts, and you retain full control over deployment details.
1. Vendor Agnosticism & Flexibility: By design, an AI gateway makes your AI stack provider-agnostic. TrueFoundry’s unified API lets you seamlessly connect to any OpenAI-compliant endpoint or 1000+ supported LLMs and vision models. You can switch underlying models (e.g. GPT, Claude, LLaMA, Mistral, Gemini, etc.) without touching your application code – a direct defense against lock-in.
2. Unified Interface & Multi-Model Support: One gateway endpoint replaces numerous vendor APIs. This simplifies development (one integration to maintain) and enables intelligent multi-model orchestration. You gain features like smart routing (send requests to the fastest or cheapest model) and fallback handling automatically.
3. Enterprise Controls: Gateways natively handle enterprise needs. TrueFoundry’s gateway enforces authentication (API keys, OAuth, etc.), fine-grained RBAC, rate-limiting, and content guardrails on every call. It also captures audit logs for compliance. These safeguards apply uniformly across all models and providers, unlike custom integrations.
4. Cost and Usage Management: Since AI gateways see every request, they can track token usage and budgets. TrueFoundry provides real-time cost tracking and budget caps per team or model, helping avoid runaway charges. This centralized cost control is far easier than poking holes into each vendor’s console.
5. Observability & Open Standards: ゲートウェイ中心のロギングとテレメトリーにより、AIワークロードに対する比類ない可視性が得られます。TrueFoundryのログはOTel準拠でオープンフォーマットであるため、あらゆるオブザーバビリティツール(例:Datadog、Grafana)にルーティングできます。データはParquet形式で独自のS3バケットに保存されるため、真に 分析データを所有でき、 隠れたデータロックインを回避できます。
6. スケーラビリティと信頼性: 適切に構築されたゲートウェイは、オーバーヘッドを最小限に抑えます。TrueFoundryのベンチマークでは、シングルCPUコアで約250 RPSの場合、追加レイテンシーはわずか3~4msです。ゲートウェイは水平にスケールし、その設計(リクエストパスに単一障害点がない)により高可用性を確保します。要するに、パフォーマンスを犠牲にすることなく、エンタープライズグレードの信頼性を手に入れることができます。
7. エコシステム統合: TrueFoundryは 100% API駆動型の プラットフォームを提供します。CI/CD (GitOps) に統合したり、TerraformプロバイダーやHelmチャートを使用したり、外部ツールと連携させたりできます。例えば、TrueFoundryからのガードレール結果やメトリクスは、OpenTelemetryを介してSIEMやガバナンスツールに供給できます。このようなオープン性により、ツール選択の自由が保たれます。
ロックインを防ぐために、以下の原則を適用してください。
抽象化、標準化、制御といった習慣を身につけることで、ロックインのリスクを劇的に低減できます。
表が示すように、小規模な単一モデルの概念実証では直接統合が最もシンプルかもしれませんが、本番環境ではすぐに脆くなります。TrueFoundryのAIゲートウェイは、わずかな予測可能なパフォーマンスコスト(わずか数ミリ秒)と引き換えに、柔軟性と制御において大きなメリットをもたらします。ほとんどのエンタープライズシナリオでは、ベンダーロックインを回避し、すぐにエンタープライズグレードの機能を得るために、このトレードオフは十分に価値があります。
AIゲートウェイ(または任意のAIプラットフォーム)を選択する際には、以下のロックイン要因を考慮してください:
要するに、オープンでモジュール式の設計(TrueFoundryの分割プレーンやプラグインベースのモジュールなど)、ポータブルなデータ、そしてシステムがどのように動作するかを完全に可視化できるものを探すべきです。TrueFoundryのアプローチは、モジュール式でKubernetesネイティブ、そしてオープンスタンダードを使用しており、これらの要件を満たしてロックインを最小限に抑えます。彼らの哲学は明確です。「ベンダーロックインゼロ」により、AIスタックを自身の条件で移行または進化させることができます。
ベンダーロックインは、AI開発における隠れたコストであり、組織を価格高騰、システム障害、停滞に対して脆弱にする可能性があります。AIモデルゲートウェイを使用することは、これらの落とし穴を回避するための最も効果的な方法の一つです。ゲートウェイは、すべてのモデルリクエストを統一されたベンダー非依存のインターフェースを介して処理することで、特定のプロバイダーへのハードコードされた依存関係を排除します。TrueFoundryのAIゲートウェイはこのアプローチを具現化しています。アプリケーションを特定のLLM APIから切り離し、オープンスタンダードを採用し、インフラストラクチャとデータの完全な制御を維持できるようにします。その結果、より高い俊敏性が得られます。コアコードを書き直すことなく、新しいモデルを評価したり、クラウド間でワークロードを移行したり、オンプレミスにデプロイしたりできます。
要するに、AIゲートウェイは ロックインに対する保険だと考えてください。 TrueFoundryの 実装は、エンタープライズグレードの機能(RBAC、可観測性、コスト管理)とオープンなポータビリティを提供することで、さらに一歩進んでいます。これにより、AIシステムは柔軟性、スケーラビリティ、将来性を維持できます。
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








最新のニュース、記事、リソースをメールでお届けします
© 2026 無断複写・転載を禁じます。







.png)








.webp)
.webp)


