













.webp)
July 4, 2026
|
5 min read

Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
毎週金曜日、私は決まってこう入力します。
「プラタメシュです。TrueFoundryのシニアソフトウェアエンジニアです。メモリサービスを担当しています。形式: 出荷したもの、進行中のもの、障害。簡潔に。」
そして、週報を依頼します。
AIは完璧に作成します。しかし、次の金曜日には?同じ習慣です。私の名前、役割、プロジェクト、そして3週連続で同じ障害について言及したことを覚えていません。
このアシスタントは自分で構築しました。シンプルなチャットUI、バックエンドにはTrueFoundryのAI Gatewayを使用しています。朝会、メール、Slackメッセージ、ドキュメントの下書きなどを処理します。本当に便利です。しかし、どのセッションもゼロから始まります。私はAIのメモリを使っていません。私が AIのメモリなのです。
ChatGPTは組み込みのメモリでこれを解決しました。しかし、独自のLLMアプリケーションを構築する場合、そのインフラは存在しません。自分で構築しない限り、頼れるのは自分だけです。
だから、私はそうしました。 TrueMem はAIアプリケーションのための永続メモリレイヤーです。あらゆるLLMに、セッション間や異なるモデル間でも機能する長期記憶を与えます。もう同じことを繰り返す必要はありません。AIが実際に記憶します。
明らかな解決策には明らかな問題があります。
ChatGPTの組み込みメモリはOpenAIのエコシステム内にロックされています。プログラムでアクセスしたり、他のモデルと連携させたり、何が保存されているかを監査したりすることはできません。 Truefoundry’s AI Gateway は、複数のモデルにアクセスし、保存されているものを監査するのに役立ちます。しかし、独自のアプリケーションを構築する人にとっては、それは出発点にもなりません。
検索拡張生成 (RAG) 別の問題を解決します。RAGはドキュメントから情報を取得し、「このPDFには何が書かれていますか?」という問いに答えます。ユーザーの記憶は根本的に異なります。それは個人的で、進化し、関係性に基づいています。会話で共有する事実は、インデックス化されるべきドキュメントではなく、将来のあらゆるやり取りを形作るべきコンテキストなのです。
コンテキストウィンドウを拡張するのは、会話履歴全体を含めるという力ずくのアプローチです。最新のモデルは128Kトークン以上をサポートしているので、なぜそうしないのでしょうか?それは、トークンは高価であり、コンテキストが増えると推論が遅くなり、セッションが終了するとすべてが消えてしまうからです。それは、余計な手間をかけて記憶喪失に高額な料金を払っているようなものです。
私たちが必要としているのは、ユーザーに関する抽出された事実を永続的に保存し、各クエリに関連するものだけを取得する専用のレイヤーです。それが、このギャップを TrueMem 埋めます。
人間の記憶は、すべての会話を一字一句そのまま保存するようにはできていません。私たちには、現在のタスクのためのワーキングメモリと、永続的な知識のための長期記憶があります。これら2つのシステムは常に相互作用しています。長期記憶は新しい情報の解釈方法に影響を与え、重要な新しい経験は長期記憶として定着します。
TrueMem は、このアーキテクチャを2つの異なるコンポーネントで模倣しています。 短期記憶(STM) 会話のコンテキストのための 長期記憶(LTM) 永続的なユーザーの事実のための
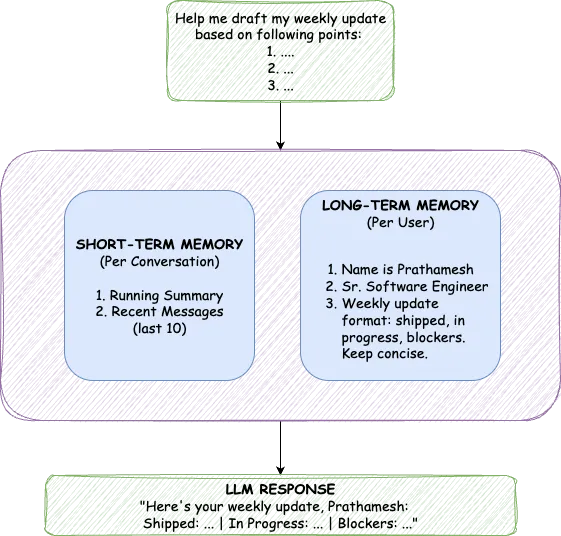
この分離は重要です。なぜなら、これらの記憶タイプは異なる目的を果たすからです。STMは、今何が起こっているか、現在の会話の完全な流れを捉えます。LTMは、すべての会話にわたって永続する抽出された事実を保存します。STMは常にコンテキストに含まれますが、LTMは意味的な関連性に基づいて取得されます。両方を1つのメカニズムで解決しようとすると、妥協を強いられます。この二重アプローチは、それを完全に回避します。
単一のチャットセッション内で、AIは5分前に話した内容を覚えておく必要があります。これがSTMの役割であり、古いメッセージの継続的な要約と、直近20件のメッセージを完全な形で保持するという2つのコンポーネントを維持します。
会話が長くなるにつれて、私たちは総トークン数を継続的に追跡します。それがしきい値を超えると、バックグラウンドワーカーが古いメッセージを継続的な要約に圧縮し、最近のメッセージはそのまま保持します。

要約は非同期で行われるため、ユーザーが待つことはありません。しきい値を超えると、バックグラウンドジョブが未要約のメッセージを取得し、既存の要約と結合して、更新された包括的な要約を生成します。これらのメッセージは「要約済み」としてマークされ、このサイクルが繰り返されます。段階的な圧縮により、1時間にも及ぶ会話でさえ、妥当なコンテキスト制限内に収まります。
しかし、会話のコンテキストだけでは不十分です。ユーザーが明日戻ってきたらどうなるでしょうか?そこで長期記憶の出番です。
LTMは、ユーザーの名前、職業、好み、コミュニケーションスタイル、その他会話を通じて記憶しておく価値のあるあらゆる情報など、ユーザーに関する事実を永続的に保存します。これらは生テキストとして保存されるのではなく、ベクトル埋め込みに変換され、セマンティックな 類似性検索。
ユーザーが「どのプログラミング言語を使えばいいですか?」と尋ねたとき、保存された記憶に対してキーワードマッチングは行いません。クエリを埋め込み、意味的に関連する記憶を見つけます。「ユーザーはPythonを好む」や「MLインフラストラクチャで作業している」といった記憶は、共通のキーワードがなくても概念的に関連しているため、浮上します。
システムは2つのチャネルを通じてLTMに情報を入力します。明示的な記憶は、「箇条書きが好きだと覚えておいてください」や「ピーナッツアレルギーであることを忘れないでください」といった直接のリクエストから得られます。トリガーフレーズを検出し、核となる事実を抽出し、最大限の重要度で保存します。これらの記憶は自動的に削除されることはありません。
自動記憶は会話分析から得られます。ユーザーが「MLプラットフォームチームを率いてきました」と述べた場合、それは明示的な保存リクエストがなくても貴重なコンテキストとなります。各インタラクションの後、バックグラウンドワーカーが会話を分析し、保存する価値のある事実を抽出し、それぞれに重要度スコアを付与します。
重要度スコアは1から5の範囲です。5は、明示的なユーザー指示、強い好み、アレルギーなど、決して忘れてはならない重要な情報です。4は、職業や場所などの主要な個人情報です。3は、趣味や興味などの一般的なコンテキストです。2は、現在のプロジェクトなどの一時的な情報です。1は、些細な詳細です。明示的な記憶は自動的に5が割り当てられ、自動抽出は、事実の重要度に応じて通常1から4のスコアが付けられます。
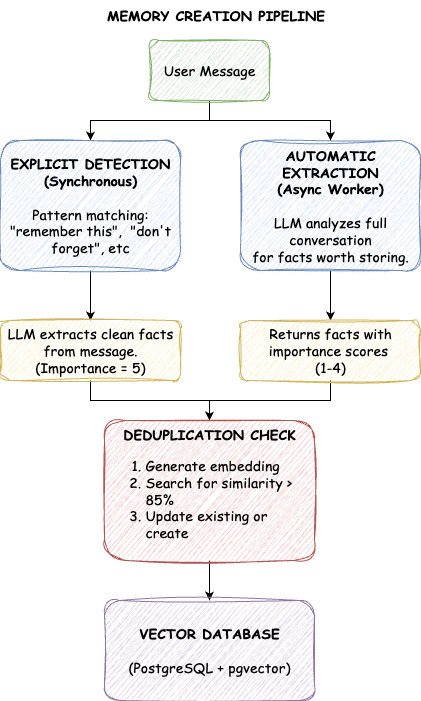
自動抽出には課題があります。あるセッションでユーザーが「Pythonが好き」と言い、別のセッションで「JavaScriptよりPythonの方が好き」と言った場合はどうなるでしょうか?単純な保存方法では重複が生じます。TrueMemはセマンティックな重複排除でこれを解決します。保存する前に、類似度が85%を超える既存の記憶を検索します。ほぼ重複するものが存在する場合、新しいエントリを作成するのではなく、それを更新します。データベースは、各事実が最も完全な形で正確に1回だけ出現するようにクリーンに保たれます。
プライバシーは透明性を通じて扱われます。ユーザーは保存された記憶を閲覧、編集、削除できます。すべての記憶はユーザーごとに厳密に分離されています。エンタープライズ展開の場合、システム全体はお客様のインフラストラクチャ上で動作します。お客様の環境から何も出ることはありません。
抽出の精度についてはどうでしょうか?これにはいくつかのメカニズムがあります。重要度スコアリングにより、自動抽出は明示的な記憶よりも先に剪定されます。ユーザーは間違いを確認し、修正できます。会話を通じて強化された正しい情報はより高い重要度を蓄積する一方、一度限りの誤抽出は自然な剪定によって薄れていきます。
記憶を保存するだけでは問題の半分しか解決しません。ユーザーがメッセージを送信したとき、適切なサブセットが必要です。すべてではなく、関連するものだけです。パワーユーザーは150もの事実を保存しているかもしれませんが、それらすべてを含めると、コンテキストウィンドウがパンクしてしまいます。
このプロセスはユーザーのメッセージを埋め込み、コサイン類似度検索を実行し、上位10件の一致を返します。適切なインデックス付けを行えば、これは10ミリ秒未満で完了します。
1つの例外: 新規ユーザーです。記憶が10個未満の場合、類似度に関係なくすべて含めます。関係の初期段階では、すべてのコンテキストが重要です。10個を超えると、純粋な類似度ベースの検索に切り替えます。
この取得は、より大きなコンテキスト準備フローの一部であり、高速性が求められます。
メモリレイヤーは、体感できる遅延を発生させない場合にのみ役立ちます。ユーザーは遅延に敏感で、200ミリ秒でももたつきを感じます。コンテキスト準備の目標は80ミリ秒未満でした。
鍵は並列化です。コンテキスト準備には、埋め込みの生成、最近のメッセージの取得、明示的なトリガーの確認、長期記憶の検索といった、いくつかの独立した操作が含まれます。これらを順次実行する代わりに、並列で実行します。
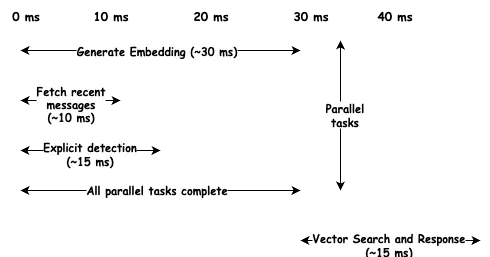
埋め込みの生成は最も遅く約30ミリ秒かかりますが、10ミリ秒で完了するデータベースクエリと並行して実行されます。合計時間ではなく、最も長い処理時間で決まるため、全体のレイテンシは約45ミリ秒となり、目標を大幅に下回ります。
要約や記憶の抽出といった重い操作は、応答が送信された後に非同期で実行されます。ユーザーが待つことはなく、処理はバックグラウンドワーカーで行われます。この高速な同期パスと低速な非同期パスの分離は、本番環境での使用に不可欠です。
メモリが確実に機能するようになったことで、予期せぬ利点が生まれました。私たちは偶然にもモデルに依存しないものを構築していたのです。
私たちが予期していなかったのは次の点です。メモリがモデルの外部に存在するようになれば、単一のプロバイダーに縛られることはありません。
GPT-4からClaudeに切り替えても、あなたの記憶は維持されます。複雑な推論にはあるモデルを、クリエイティブな文章作成には別のモデルを使うなど、タスクごとに異なるモデルを使用しますか?それらすべてが、あなたに対する同じ理解を共有します。カスタムモデルをファインチューニングしますか?それは初日から既存のユーザー関係を継承します。
メモリレイヤーはあなたの不変の存在となり、モデルは交換可能になります。
統合は最小限に抑えられます。LLM呼び出しの前にコンテキストを取得し、その後インタラクションをログに記録するだけです。2つのAPI呼び出しで、あらゆるステートレスモデルを永続的なメモリを持つモデルに変えることができます。SDKロックインも、複雑な統合もありません。どんなアーキテクチャにも適合するHTTPエンドポイントだけです。
もちろん、記憶は永遠に増え続けるわけではありません。ライフサイクル管理のないシステムは、古くなった事実に埋もれてしまうでしょう。
すべての記憶には、1から5までの重要度スコアがあります。明示的な指示は5、重要な個人情報は4、一般的なコンテキストは3、一時的な情報は2、細かい詳細は1です。
数がソフトリミット(デフォルトで150)を超えると、プルーニングが開始されます。システムは重要度4以上の記憶には手をつけません。重要度の低い記憶の中から、最もスコアの低いものから削除し、古さをタイブレーカーとして使用します。
明示的なユーザー指示は無期限に存続します。価値の低い自動抽出は、新しい情報のためのスペースを確保するために再利用されます。記憶は手動でのキュレーションなしに、関連性を保ちます。
ユーザーがチャットを開いて入力します。 「以下の点に基づいて、週次報告のドラフト作成を手伝ってください…」
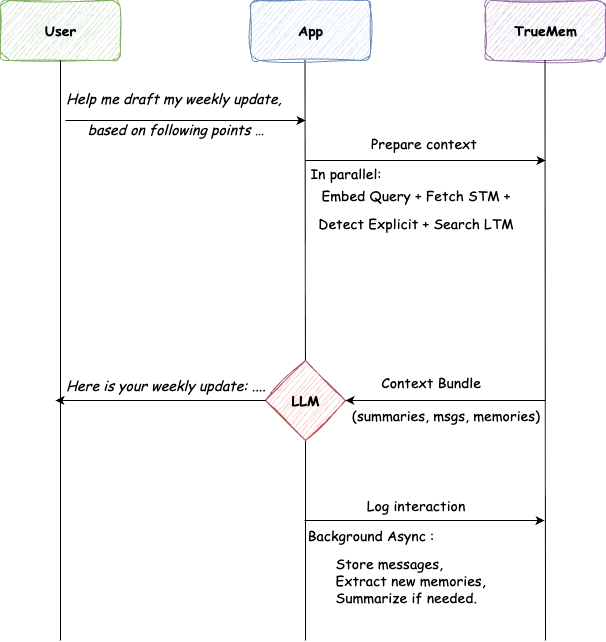
アプリはコンテキストのためにTrueMemを呼び出します。TrueMemは「名前はプラタメシュ」「シニアMLエンジニア」「メモリサービスを担当」などのSTMと関連するLTMを組み立てます。これには45ミリ秒かかります。
LLMはパーソナライズされた応答を生成します。「プラタメシュさん、週次報告です…」決まり文句も、自己紹介も不要です。AIは誰が質問しているかを知っています。
応答後、アプリはインタラクションをログに記録します。バックグラウンドワーカーはメッセージを保存し、新しい事実を抽出し、必要に応じて要約を更新します。大量の処理は目に見えない形で行われます。
実用的な理由から、専用のベクトルデータベースではなく、pgvectorを搭載したPostgreSQLを選択しました。ほとんどのチームはすでにPostgresを使用しています。メモリはユーザーデータと並んで、完全なACID保証付きで存在します。ユーザーごとの100〜200個のベクトルコレクションの場合、pgvectorは10ミリ秒未満の類似性検索を提供します。ユーザー範囲のメモリには、それが適切な選択です。
LLMの呼び出しには数秒かかり、リクエストをブロックするには長すぎるため、バックグラウンドワーカーはRedisをバックエンドとするキューで実行されます。ワーカーは、ユーザーに影響を与えるレイテンシなしに、失敗を再試行し、操作をバッチ処理し、独立してスケーリングできます。
あの金曜日の決まり文句を覚えていますか?「プラタメシュです。シニアMLエンジニアで、メモリサービスを担当しています。」
TrueMemがあれば、それは一度だけ行われます。AIが記憶します。次の金曜日の更新は、ただ機能します。来月のメールの下書きには、私の署名が認識されています。コンテキストは常に存在します。
さらに良いことに、別のモデルに切り替えても、メモリは引き継がれます。日常のアシスタントは、追加の作業なしにモデルに依存しなくなります。
それが目標です。あなたを覚えているAI。あなたが繰り返し思い出させるからではなく、実際に覚えているからです。
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








最新のニュース、記事、リソースをメールでお届けします
© 2026 無断複写・転載を禁じます。







.png)








.webp)
.webp)


