













.webp)
July 4, 2026
|
5 min read

Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
Transformerは、コンピュータが人間の言語を理解する方法を再構築する画期的な技術として登場しました。単語を一つずつ処理する従来のモデルとは異なり、Transformerは文全体を一度に処理できるため、言語のニュアンスを捉える上で非常に効率的です。Transformerは、次のタイトルの論文で初めて紹介されました。 Attention Is All You Need。これらは主に、音声翻訳やテキストから音声への変換など、入力シーケンスを出力シーケンスに変換するあらゆる種類のタスクを解決するために開発されました。
言語モデルは、単純なルールベースのアルゴリズムから洗練されたニューラルネットワークへと大きく進化してきました。当初、これらのモデルは事前に定義されたルールに従うか、単語の頻度を数えることしかできませんでした。その後、統計モデルが登場し、前の単語に基づいて次の単語を予測しましたが、長い文では苦戦しました。ニューラルネットワーク、特にRNNとLSTMの導入は、モデルがより多くの文脈を記憶できるようになり、大きな進歩をもたらしました。しかし、これらは依然としてテキストを順次処理していたため、複雑な言語構造の理解には限界がありました。

Transformerは、文のすべての部分を同時に処理できる能力によって、言語処理に革命をもたらしました。これにより、処理時間が短縮されるだけでなく、文中の単語がどれだけ離れていても、文脈をより深く理解できるようになりました。Transformerの主なアイデアは「自己注意メカニズム」であり、これによりモデルは文中の各単語の重要性を他のすべての単語との関連で評価できます。この技術の飛躍は、機械翻訳、コンテンツ生成、さらには人間のようなテキストの理解と生成における進歩を促進し、NLPの分野で新たな標準を確立しました。
このブログでは、バニラTransformerのアーキテクチャについて詳しく探っていきます。

新しいAIアーキテクチャであるTransformerは、機械が言語を理解し生成する方法において新たな基準を打ち立てました。その核となるいくつかの重要な概念が、膨大な量のテキストデータを処理する上で非常に優れている理由です。Transformerを定義するアーキテクチャと主要コンポーネントを詳しく見ていきましょう。
Transformerのアーキテクチャは、エンコーダとデコーダという2つの柱で成り立っています。エンコーダは入力テキストを読み込み処理し、モデルが理解できる形式に変換します。それは、文を吸収し、その本質に分解するようなものだと想像してください。一方、デコーダはこの処理された情報を受け取り、それを段階的に進めて出力を生成します。まるで文を別の言語に翻訳するかのようです。この相互作用こそが、文脈の理解と正確な応答の生成が鍵となる翻訳のようなタスクにおいて、Transformerを非常に強力なものにしているのです。
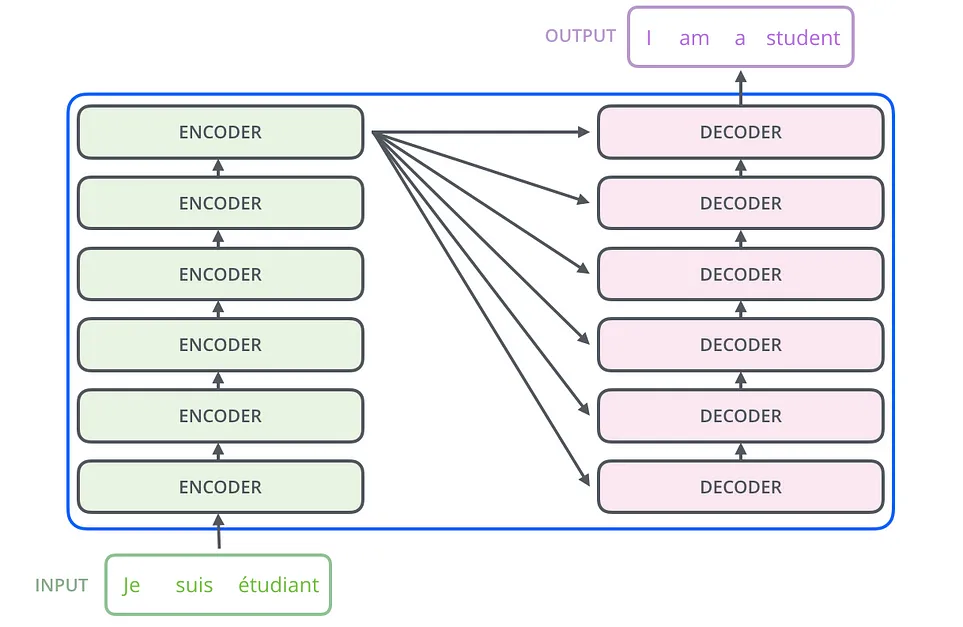
Transformerのエンコーダとデコーダの核となるのは、自己注意メカニズムです。これにより、モデルは文中の各単語が他のすべての単語とどのように関連しているか、その重要度を評価できます。したがって、長い文で以前の単語を見失いがちだった従来のモデルとは異なり、Transformerは文脈全体を包括的に理解し続けます。

Transformerは文中のすべての単語を同時に処理するため、単語の順序を理解する方法が必要です。ここで位置エンコーディングが役立ちます。各単語には、文中の位置を表す固有のコードが与えられ、これによりモデルは言語の流れと構造を把握でき、文の背後にある意味を理解するために不可欠です。
自己注意の考え方に基づいて、マルチヘッド注意は、モデルが文を異なる視点から見ることを可能にします。注意メカニズムを複数の「ヘッド」に分割することで、Transformerは文法や意味論など、テキストの多様な側面を同時に処理でき、入力のより豊かな理解をもたらします。

Transformerのメカニズムを深く掘り下げると、複雑な言語理解と生成のために設計された洗練されたアーキテクチャが見えてきます。ここでは、エンコーダとデコーダの複雑な仕組み、そしてそれらが連携して言語を処理し生成する方法を探ります。
エンコーダの主な機能は、入力シーケンスを処理することです。入力文の各単語はベクトルに変換されます。これは、単語の意味の本質を含む豊かな数値表現です。しかし、エンコーダの役割はそれだけではありません。各単語を取り巻く文脈、つまりその単語が前後の単語とどのように関連しているかを理解する必要もあります。
これを実現するために、エンコーダは自己注意メカニズムとフィードフォワードニューラルネットワークで構成される一連の層を利用します。自己注意メカニズムにより、エンコーダは特定の単語を考慮する際に、文中の他の単語の重要度を評価できます。このプロセスは、Q(クエリ)、K(キー)、V(値)ベクトルを生成することで数学的に表現され、文の文脈を動的に理解することを促進します。

デコーダはエンコーダからバトンを受け取り、出力シーケンスを生成する役割を担います。出力の開始を示す特殊なトークンから始まり、エンコーダが提供する文脈を使用して一度に1つの単語を生成します。デコーダの自己注意層は、生成される各単語がそれ以前の単語に基づいて適切であることを保証し、エンコーダ・デコーダ注意層は、デコーダが入力シーケンスの関連部分に焦点を当てることを可能にします。
Transformerモデルのこの段階で、実際の言語生成が行われます。それは、文を別の言語に翻訳することであれ、テキストを要約することであれ、あるいは創造的なコンテンツを生成することであれ、です。デコーダが、直接的な文脈(出力における前の単語)とより広範な文脈(エンコーダによって処理された入力シーケンス)の両方を考慮できる能力は、首尾一貫した文脈に沿った言語を生成するために不可欠です。
Transformerの真の力は、エンコーダーとデコーダー間の相乗効果にあります。エンコーダーが入力文を深く理解する一方で、デコーダーはこの情報を活用して、正確で関連性の高い出力を生成します。この相互作用は、エンコーダー・デコーダーアテンションメカニズムを介して行われ、これによりデコーダーは生成プロセスの各ステップでエンコーダーの出力を照会できます。
この協調的なメカニズムにより、出力が言語的に意味をなすだけでなく、入力の忠実な表現または変換であることが保証されます。機械翻訳からコンテンツ生成まで、幅広い言語処理タスクでTransformerが優れた性能を発揮できるのは、このエンコーダー・デコーダー間の相乗効果によるものです。
Transformerは自然言語処理(NLP)の分野に革命をもたらしただけでなく、その汎用性を示し、他の領域にも適用範囲を広げています。その影響力は以下の通りです。
翻訳: Transformerは機械翻訳を大幅に改善し、人間に近いレベルの流暢さと理解力を提供しています。Google翻訳はその代表例であり、BERTやGPTのようなTransformerモデルが、多数の言語における翻訳品質の向上に極めて重要な役割を果たしています。

テキスト要約: Transformerモデルを搭載した自動要約ツールは、長い記事、レポート、文書の簡潔な要約を生成できるようになりました。元のテキストの文脈とニュアンスを維持しながら、要約を作成します。OpenAIのGPTシリーズのようなツールは、この分野の進歩に貢献しており、ユーザーに長文コンテンツからの迅速な洞察を提供しています。
テキストの壁を打ち破り、Transformerは視覚の世界に進出しました。Vision Transformer (ViT) は、自己注意の原則を画像ピクセルに適用し、画像認識タスクで最先端の結果を達成しています。このアプローチは、従来の畳み込みニューラルネットワーク(CNN)に挑戦し、視覚情報の処理に新たな視点を提供しています。

Googleの検索エンジンは、BERT(Bidirectional Encoder Representations from Transformers)によって大幅に強化され、検索クエリの文脈をより良く理解できるようになりました。これにより、検索結果の関連性が大幅に向上し、世界中のユーザーにとって情報検索がより正確になっています。
Transformer技術を活用したAI駆動型チャットボットは、より魅力的で人間らしい対話を提供します。企業はこれらの高度なチャットボットを顧客サービスに導入し、即座に文脈を理解したサポートを提供することで、顧客満足度と業務効率を向上させています。
OpenAIのGPT-3.5とGPT-4は、 大規模言語モデルにおいて画期的な存在であり、人間のようなテキストを生成し、質問に答え、さらにはコードを書くという驚くべき能力を示しています。その応用範囲はコンテンツ作成からプログラミング作業の支援まで多岐にわたり、さまざまな業界におけるTransformerの大きな可能性を示しています。
進化し続ける人工知能の状況を乗り越える中で、Transformerはその最前線にあり、多くの可能性と将来性を秘めています。その急速な発展と様々な分野への統合は、さらなる画期的なイノベーションへの道を示唆しています。ここでは、今後の進歩と方向性、そして待ち受ける課題と機会について深く掘り下げていきます。
OpenAIによるGPT-4の発表は、大規模言語モデルの分野における記念碑的な飛躍を意味し、AIが言語理解と生成において達成できることの限界を押し広げています。GPT-4は、その規模だけでなく洗練度においても先行モデルを凌駕し、より繊細なテキスト生成、問題解決能力、そして人間言語のニュアンスに対する理解の向上を提供します。GPT-4の展望は、人間とAIのインタラクションの改善、複雑なタスクの自動化、そして無数のアプリケーションにおける革新的なソリューションの提供にまで及びます。GPT-4の先を見据えると、これらのモデルをより効率的で、解釈可能で、さらに幅広いタスクを処理できるようにすることに焦点が当てられ、真にインテリジェントなシステムへの大きな一歩を記しています。
GPT-4のようなモデルと共に未来を見据える中で、私たちはスケーラビリティ、解釈可能性、倫理に関する重要な課題と機会に直面しています。これらの強力なモデルをより大規模かつ複雑にするには、膨大な計算能力とエネルギーが必要であり、コストと環境への影響について疑問を投げかけます。同時に、これらのモデルがどのように意思決定を行うかを理解できることが重要です。特に医療や金融のような重要な分野で使用される場合には。さらに、誤情報の拡散を防ぐ方法や、AIによる雇用の代替がもたらす影響を理解するなど、倫理的な側面も考慮する必要があります。これらの問題に取り組むには、開発者から政府関係者まで、AIに関わるすべての人の努力が必要であり、Transformerモデルの成長が責任あるものであり、社会に利益をもたらすものであることを保証するためです。
要約すると、Transformerは人工知能と自然言語処理の状況を大きく変革しました。言語の文脈とニュアンスを理解できるその独自のアーキテクチャは、翻訳、テキスト要約などのタスクにおいて目覚ましい進歩をもたらし、テキストの領域を超えて画像認識などにも及んでいます。
主要なポイントとしては、Transformerがデータシーケンス全体を同時に処理することを可能にする自己注意メカニズムの重要性、そしてデータ処理におけるシーケンス順序を維持するための位置エンコーディングの革新的な使用が挙げられます。さらに、これらのモデルのスケーラビリティは、解釈可能性と倫理的考察の必要性と相まって、この分野における将来の発展のためのロードマップを示しています。
Transformerは単なる技術的進歩にとどまらず、AIの能力に対する私たちの見方を一変させるものです。それらは、AIが前例のない深さと柔軟性で人間の言語を理解し、対話できる未来を垣間見せ、業界全体で自動化、創造性、効率性の新たな道を開きます。Transformer技術の境界を探求し拡大し続ける中で、AIの未来を形作る上でのその役割は極めて重要であり、人間と機械のパートナーシップが協力と革新の新たな高みに達する未来を約束します。
LLMトランスフォーマーアーキテクチャは、入力シーケンス全体を同時に処理する革新的なニューラルネットワーク設計です。従来のモデルとは異なり、自己注意メカニズムを活用して単語の文脈を深く理解します。これにより、大規模言語モデルは人間のようなテキストを効率的に理解し生成できるようになり、米国全土における機械翻訳やコンテンツ作成の進歩を推進しています。
はい、現在、大規模言語モデル(LLM)の開発において、トランスフォーマーアーキテクチャは非常に重要です。トランスフォーマーは、文全体を同時に処理することで言語処理に革命をもたらし、文脈理解と処理速度を向上させました。この核となる革新は、現代のLLMが人間のようなテキストを生成し、米国のユーザーのために複雑な言語タスクを効率的に実行するために不可欠であり続けています。
LLMにおけるトランスフォーマーとは、文全体を同時に処理するAIアーキテクチャです。自己注意メカニズムを使用して、単語間の関係と文脈を深く理解します。この画期的な技術は、大規模言語モデルが人間のようなテキストを学習し生成する方法に革命をもたらし、高度なアプリケーションと効率的な言語理解に不可欠です。
大規模言語モデル(LLM)の基盤となるアーキテクチャは、LLMトランスフォーマーアーキテクチャとして知られています。この巧妙な設計により、LLMは情報を独自の方法で処理することで、人間のようなテキストを理解し生成することができます。これにより、膨大な量のデータから複雑なパターンを学習することが可能になります。
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.







最新のニュース、記事、リソースをメールでお届けします
© 2026 無断複写・転載を禁じます。







.png)








.webp)
.webp)


