













.webp)
July 4, 2026
|
5 min read

Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
生成AIは、実験段階から実運用へと急速に移行し、現在では製品、運用、顧客体験のあらゆる側面に組み込まれています。しかし、企業が導入を拡大するにつれて、構造的な問題が浮上しています。 AIの利用が、コストを制御するために必要なメカニズムよりも速く増加している。閉じられたパイロットプロジェクトとして始まったものが、複数のチームが個別に開発を進め、複数のモデルを呼び出すアプリケーション、多段階の推論を実行するエージェントワークフローへと急速に拡大します。その結果、支出が増加するだけでなく、組織全体で予測不能かつ複合的なコストがますます増大しています。
この課題はGartnerのレポートで強調されています。 “生成AIおよびエージェントAIのコスト最適化のための10のベストプラクティス” は、アーキテクチャ上の決定と運用規律の欠如が、大規模なコスト超過をどのように引き起こすかを検証しています。レポートでは次のように述べています。「2028年までに、生成AIプロジェクトの少なくとも50%が、不適切なアーキテクチャ選択と運用ノウハウの不足が原因で予算超過となるでしょう。」これはツールの問題ではなく、根本的にアーキテクチャと運用モデルの失敗です。
この変化はGartnerのレポートで詳しく解説されています。 「生成AIおよびエージェントAIのコスト最適化のための10のベストプラクティス」 は、AIシステムが本番稼働に移行するにつれて、企業がコスト、ガバナンス、運用管理をどのように再考する必要があるかに焦点を当てています。
TrueFoundryはこのレポートで言及されています。 AIゲートウェイ、つまりAIワークロード全体のコスト、信頼性、ガバナンスを管理するための新たな制御レイヤーの文脈で。
Gartnerは、この課題の規模を明確に強調しています。「GenAIのパイロット運用から本番環境への移行を進める組織は、コスト面で厳しい現実に直面します。本番環境に対応したGenAIシステムを構築するには、パイロット運用よりも桁違いに費用がかかることがあります。これは転換点を示しています。AIのコストは、システムのオーケストレーション、統制、大規模運用方法によって、構築時の懸念ではなく実行時の問題となるのです。

この問題を理解するには、AIシステムが大規模な環境でどのように動作するかを分析することが重要です。
1 推論が主要なコスト層となる
従来のシステムとは異なり、AIは使用されるたびにコストが発生します。
ガートナーはこの変化を次のように指摘しています。
「2028年までに、モデル推論の累積コストは、モデルのライフタイム総コストの少なくとも70%を占めるようになるでしょう…」
これは、コスト管理の方法を根本的に変えるものです。
2 エージェント型ワークフローがリクエストあたりのコストを増大させる
現代のAIシステムは単一ステップではありません。
1つのリクエストが以下を引き起こす可能性があります。
これにより 非線形なコスト増大。
3 断片的な導入が非効率性を招く
ほとんどの企業では、
その結果、
4. ランタイムガバナンスの欠如がコストの肥大化を招く
一元的な管理がない場合:
ここでコストは 大規模になると管理不能になります.
Gartnerの提言は、明確な転換を示しています。
これは、より良いモデルに関する話ではありません。
重要なのは 本番環境でモデルがどのように使用されるかを制御することです。
主な実践事項は以下の通りです。
1 AIシステムへの集中アクセス
すべてのモデルとツールのインタラクションを管理する単一の制御レイヤー。
2 インテリジェントなモデルルーティング
コスト、レイテンシー、パフォーマンスに基づいてモデルを動的に選択。
3 ガバナンスとポリシーの適用
すべての利用にわたり、クォータ、制限、ガードレールを適用。
4 エンドツーエンドのオブザーバビリティ
利用状況、パフォーマンス、コストをきめ細かなレベルで追跡。
5 コスト最適化メカニズム
キャッシュと再利用を通じて冗長な推論を削減。
ガートナーはこの変化を次のように定義しています。
「AIゲートウェイと呼ばれる新しい種類のツールは、ポリシーを適用することでコスト管理に役立ち、…また、キャッシュやモデルルーティングなどの機能を提供することで、コストを削減できます。」
これは新しいレイヤーを定義しています。
AIコントロールプレーン
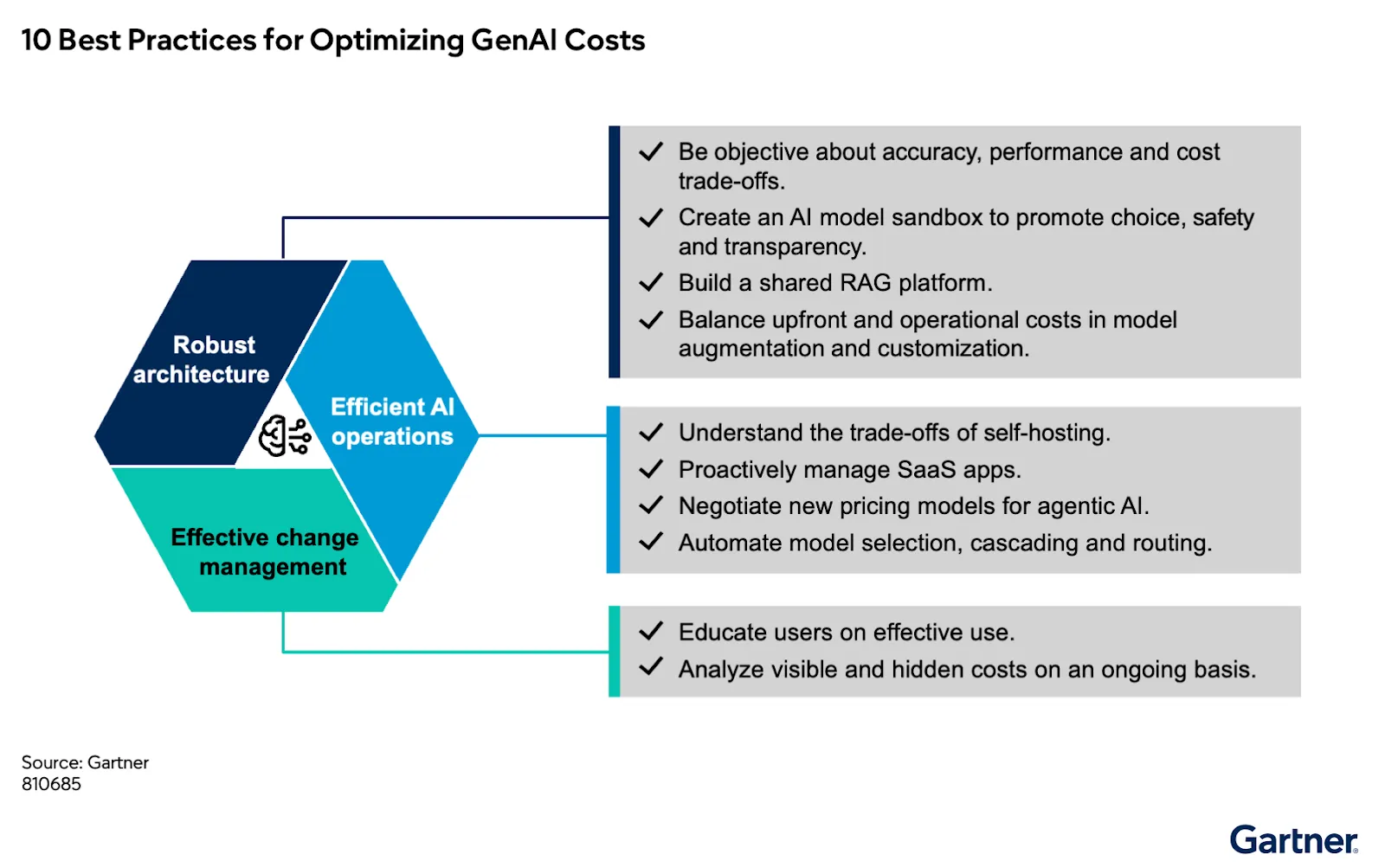
ガートナーが示す方向性は、明確な要件を示していると私たちは考えています。
企業全体でAIがどのように利用されるかを統制する、一元化された制御レイヤーです。
TrueFoundryは このレポートで言及されています この新たなAIゲートウェイエコシステムの一環として。
TrueFoundryは、 AI利用が発生し、コストが生じるレイヤーで機能します。
1 事後的な追跡から事前的な制御へ
これまでのやり方:
TrueFoundryが実現すること:
2 ランタイムでの動的な最適化
3 AIシステム全体の完全な可視性
4 エンタープライズ規模でのガバナンス
5つのエンタープライズ向けデプロイメント
これにより、運用モデルは以下のように変化します。
「AIへの支出はいくらか?」
から
「AIを効率的に利用しているか、そしてこのリクエストはそもそも実行すべきか?」
生成AIは第二段階に入っています。
第一段階はアクセスが中心でした。
次の段階は コントロールと経済性です。
同時に、料金モデルも進化しています。
「2030年までに、エンタープライズSaaS支出の少なくとも40%が、利用量、エージェント、または成果ベースの料金体系に移行するでしょう。」これにより、コストは次のようになります。
ランタイム層に制御を導入する組織は、次のことを実現します。
最終的な見解
ガートナーは、生成AIのコストを モデル選択ではなく、ランタイムの動作に根ざしたシステムレベルの課題であると定義しています。 なぜなら、大規模な運用では:
成功を収める企業は、AIの導入が速い企業ではありません。
そうではなく、導入するのは:
AIシステムがどのように動作するかにおいて、制御、ガバナンス、そして経済的規律です。
優位性はモデルへのアクセスから生まれるのではなく、
それらのモデルがどのように使用されるかを制御することから生まれます。
さらに詳しく見る
Gartnerレポート全文を読む
TrueFoundryについて詳しくはこちら: https://www.truefoundry.com
Gartnerは、その調査出版物に記載されているいかなるベンダー、製品、サービスも推奨するものではありません。また、テクノロジーユーザーに対し、最高の評価やその他の指定を受けたベンダーのみを選択するよう助言するものではありません。Gartnerの調査出版物は、Gartnerの調査組織の意見で構成されており、事実の表明として解釈されるべきではありません。
Gartner、生成AIおよびエージェントAIのコスト最適化のための10のベストプラクティス、Arun Chandrasekaran 他、2026年3月20日
GARTNERは、Gartner, Inc.および/またはその関連会社の商標です。
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.

You can optimize generative AI costs by using the right model for each task and avoiding unnecessary usage. For example, simple tasks do not require large and expensive models, so choosing smaller ones can reduce spend. In addition, keeping prompts focused helps avoid extra token usage that does not add value. Similarly, limiting response length prevents paying for unnecessary output. Over time, regularly tracking usage makes it easier to identify where costs are increasing and take corrective action.
You can reduce LLM costs by cutting down on long prompts and repeated queries. Since longer inputs increase token usage, keeping them concise helps control costs. At the same time, repeated queries without caching can lead to avoidable spending. Using smaller models for basic tasks is another effective way to reduce costs without impacting performance. Overall, maintaining control over both input and output length ensures more efficient and predictable usage.
An AI gateway helps optimize costs by controlling how different AI models are used. It routes requests to the most cost-effective model based on the task, so simple queries do not end up using expensive models. This prevents unnecessary spend and improves efficiency. With TrueFoundry, the AI gateway goes a step further by giving teams a unified layer to connect, observe, and govern AI usage across applications. It also provides clear visibility into token usage, enables smart routing, and helps enforce limits to keep spending under control.
Yes, you can use generative AI for free through limited plans offered by providers. These plans are useful for testing and small-scale usage. However, they come with restrictions on usage and features. Once usage increases, you will need to move to paid plans.
Generative AI is expensive because it requires high computing power for every request. Large models run on costly infrastructure, which increases overall expenses. Costs also come from embeddings, integrations, and repeated workflows. This makes the total cost higher than just token usage.
The best practices for AI cost optimization include using the smallest effective model and reducing unnecessary usage. Keeping prompts clear and output limited helps control token usage. Monitoring usage regularly helps identify cost-heavy areas. Reducing repeated tasks and optimizing workflows also improves efficiency.
LLM inference cost is affected by model size, token usage, and request frequency. Larger models cost more because they require more computing power. Longer prompts and outputs increase token usage and cost. Frequent or multi-step requests can quickly increase overall expenses.
Token usage impacts AI costs by determining how much you are charged per request. Every input and output is measured in tokens. Longer prompts and responses lead to higher costs. Managing token usage carefully helps keep overall spending under control.
The cost of running LLMs in production includes token usage, infrastructure, and system-related expenses. You also need to account for storage, monitoring, and integrations. Token costs are often only a part of the total spend. As usage grows, these additional costs increase significantly.
Agentic AI is a system where AI performs tasks through multiple steps and decisions. It affects costs by increasing the number of model calls required to complete a task. Each step adds to token usage and compute cost. This makes it more expensive than single-step AI interactions.






最新のニュース、記事、リソースをメールでお届けします
© 2026 無断複写・転載を禁じます。







.png)








.webp)
.webp)


