













.webp)
July 4, 2026
|
5 min read

Published: July 4, 20269:30
Blazingly fast way to build, track and deploy your models!
何十年もの間、企業は ルールベースの自動音声応答(IVR)システム で顧客からの電話を管理してきました。これらのシステムは効率性を提供するために設計されました。発信者をメニューに誘導し、いくつかのキーワードを認識し、適切なチームやスクリプトにルーティングするものです。小規模であれば、これは機能しました。しかし、 年間数億件もの電話を処理する企業では、これらの限界は痛いほど明らかになります。顧客はスクリプト通りには話しません。彼らは自然で、自由で、予測不可能な言葉で話します。時には感情的になり、時には専門的になり、時には我慢できなくなります。ルールベースのシステムは、このような多様な要求を処理するようには作られていませんでした。
その結果は? 高い呼放棄率、不満を抱く顧客、そして深刻なブランドイメージの毀損です。 人間との会話を硬直した意思決定ツリーに無理やり当てはめようとする企業は、解決時間の長期化、エージェントへの引き継ぎ率の増加、そして運用コストの膨張に直面します。さらに悪いことに、顧客体験は顧客維持と収益に直接影響を与える形で損なわれます。業界の分析によると、2021年のIVRセルフサービスの全体的な顧客満足度(Csat)は75%であり、IVRナビゲーションの全体的なCsatはわずか53%でした![リンク]
ルールベースのシステムとは異なり、 LLMベースのエージェントシステム は、意図を解析し、文脈に適応し、自然で人間らしい言葉で応答できます。理論的には、大規模な実際の会話の流動性に対応できます。これらは待望の大きな変化をもたらします。単に電話のルーティングを自動化するだけでなく、パーソナライズされ、共感を呼ぶ方法で顧客と対話するのです。
しかし、 問題は、市販のLLMは、大企業の業界固有の運用プロセス向けに訓練されておらず、データプライバシー、信頼性、展開に関するエンタープライズグレードの基準を満たすように強化されていません。その可能性にもかかわらず、今日のLLMは依然として、CIOやコンプライアンス担当者を不安にさせるような失敗モードを示します。彼らは応答を「幻覚」したり、規制に敏感なクエリを誤解したり、対話ごとにトーンが異なったりする可能性があります。信頼性、一貫性、コンプライアンス — これらはFortune 500企業のカスタマーサービスチームにとって譲れない要素ですが — まだ保証できません。
これにより、企業は 移行期の課題旧システムは技術的には通話量に対応できますが、サポートが不十分なユースケースや現代のユーザーからの期待の高まりにより、多くの顧客が不満を抱える結果となっています。一方、新しいシステムは、今日のユーザーニーズにより合致しているものの、まだ旧システムを完全に置き換えるほど信頼性が高くありません。
テクノロジーリーダーにとって、この時期はデリケートな緊張関係によって特徴づけられます。レガシーシステムに過度に依存すれば顧客の不満が増大するリスクがあり、LLMを性急に導入すれば信頼を損なう高額なエラーを招く可能性があります。
多くの経営者にとって、最も安全な選択肢は LLMが「成熟」するまで待つことのように思えるかもしれません。 しかし、実際には、それは選択肢ではありません。競争圧力は非常に高く、何もしないことの代償は大きいからです。
まず、 顧客の期待は不可逆的に変化しました。消費者は、AIを搭載したチャットボット、スマートアシスタント、レコメンデーションエンジンと日常的に接しています。数十億ドル規模の大企業に電話をかける際、彼らはIVR体験においても同レベルの流暢さ、パーソナライゼーション、応答性を期待します。それ以下のものを提供すれば、時代遅れだと感じられます。銀行、保険、通信などの業界では、そのギャップは単なる不便さにとどまらず、すでにAIに投資している競合他社に顧客を奪われる原因となります。
第二に、コールセンターの経済性は非常に厳しいものです。 年間5億件の通話 を人間のオペレーターだけで処理するのは不可能です。わずかな効率改善でも、年間数千万ドルの節約につながります。今AIを導入しないことは、単に遅れをとるだけでなく、利益を損なう不必要なコスト構造を固定化することを意味します。
第三に、 競合他社は動いています。業界全体で、市場のリーダーたちがAIを活用した顧客体験を試しているのがすでに見て取れます。中にはつまずく企業もあるかもしれませんが、顧客や投資家へのシグナルは明確です。イノベーションは起きており、AIをリードするブランドが差別化を図るでしょう。傍観しているだけでは、顧客離れだけでなく、「導入が遅い企業」としての評判を損なうリスクがあります。
最後に、 組織の学習曲線があります。 Fortune 500企業のような環境でAIを責任を持って導入するには時間がかかります。法務チームとの連携、スタッフのトレーニング、レガシーシステムとの統合、オブザーバビリティフレームワークの構築などです。これらは一朝一夕に実現できる能力ではありません。たとえ明日LLMが完全に信頼できるようになったとしても、AI導入のための体制をまだ構築していない企業は、何年も遅れをとることになるでしょう。
要するに、企業は待っている余裕はありません。. 行動しないことのリスク(コスト増大、顧客喪失、競争力低下)は、慎重に管理された導入のリスクをはるかに上回ります。課題は導入するかどうかではなく、 混乱期にどのように責任を持って導入するかです。
ルールベースのIVRも既製のLLM搭載ソリューションも単独ではフォーチュン500企業のニーズを満たせないことを認識し、TrueFoundryは米国最大の薬局チェーンの1つと協力して、 ハイブリッド音声AIエージェントを設計しました。その目標は野心的でした。処方箋の状況、再処方、店舗情報、在庫確認、その他日常的な顧客のニーズにわたる何百万もの日常的な通話において、熟練した人間の薬剤師の有効性を再現することです。
この設計の中心にあるのは、 ハイブリッド最適化アプローチです。 決定論的なルールベースシステムの効率性 と AI駆動型会話の柔軟性を組み合わせることです。店舗の営業時間確認や、受け取り準備ができた再処方箋の確認など、一般的で反復的な問い合わせは、 ルールベースの高速パス処理を通じてルーティングされます。これにより、 日常的なリクエストの90~95%を処理し、不要なLLM呼び出しを回避し、レイテンシーを削減し、計算コストを削減します。
顧客がより複雑または曖昧なリクエストを提示した場合、 インテリジェントルーティングシステム が引き継ぎます。 意図認識分類器を使い、 以前の会話から顧客のリクエストに自動的に追加された背景となる文脈も考慮に入れた上で、インテントマネージャーは、そのリクエストがルールによって解決できるか、それともLLMを活用した会話フローにエスカレートすべきかを判断します。これにより、精度が重要な場面では予測可能な応答を、柔軟性が不可欠な場面では自然な対話を、という適切なバランスが保たれます。
微妙なニュアンスを含むやり取りには、処方薬の補充促進やキャンセルといったフローなど、当社は会話型エージェントを構築しました。 LangGraphを使用しています。これらのエージェントは、バックエンドシステムと ツール呼び出しを通じて連携し、補充リクエストをリアルタイムで安全に処理できます。顧客は「処方薬の補充を早めてもらえますか?」のように自然に質問でき、システムは意図を解釈しながら必要なバックエンドアクションを実行します。
バックエンド操作中であっても人間らしい感覚を維持するため、当社は フィラーテキスト応答 (「詳細情報を取得していますので、少々お待ちください」のような)を導入しました。このような細やかな配慮は、システムが機械的ではなく応答性が高いと感じさせることで、顧客の信頼を強化します。
このソリューションは薬局向けであるため、処方箋の解釈における正確性は譲れないものでした。そこで当社は、 業界特化型の音声認識モデル (医薬品の専門用語に合わせて微調整されたもの)を統合し、複雑な薬剤名を正確に認識できるようにしました。これにより、顧客を苛立たせたり、患者の安全を危険にさらしたりする可能性のある転記ミスを大幅に削減します。
すべてのLLMインタラクションは、専用の ゲートウェイサービス (プロンプト管理サービスによって支えられています)を通じて行われます。これにより、プロンプトの一元管理が可能になり、 一貫性のある、事前設定された応答 (規制要件とブランドボイスの両方に準拠したもの)を保証します。更新は、多数のサービスに手を加えることなく迅速に展開でき、システムのアジリティを保ちつつコンプライアンスを確保します。
顧客体験を保護するため、音声AIエージェントには リアルタイム感情分析が含まれています。否定的な応答の繰り返しや感情的な強さの増加など、不満や不満が検出された場合、システムは 人間オペレーターへのエスカレーションをトリガーできます。これにより、デリケートな状況が共感をもって対応され、顧客体験の悪化を防ぎます。
パフォーマンスモニタリング は、システム全体のイベントを分析するために構築されたエージェントサービスであるAnalytics AIによって処理されます。これにより、ビジネス運営は以下の点で改善されます。
これにより、テクノロジーとビジネスの連携が強化され、透明性と実用的なインサイトの両方が提供されます。
このシステムはすでに 10,000店舗中約2,000店舗で導入されており、毎日何千もの顧客に対応しています。ハイブリッドモデルは、信頼性を損なうことなく規模を確保します。LLMは必要に応じて顧客との対話を強化し、ルールはほとんどの場合で信頼性と速度を保証します。初期導入では、効率、通話解決率、顧客満足度において大幅な改善が見られます。
要するに、ハイブリッド設計は妥協ではなく、 戦略的な架け橋。これにより企業は今日、責任を持ってAIを導入できると同時に、LLMがさらに多くの負荷を担う未来への道を開きます。
ハイブリッド音声AIアプローチは移行期の問題を解決する一方で、それ自身のトレードオフも生じさせます。 数億件の顧客対応を管理する企業にとって、これらのトレードオフは些細なことではありません。それらは総所有コスト、組織の準備状況、および長期的な持続可能性を左右します。
純粋なルールベースシステムでは、ロジックは決定論的であり、追跡が比較的簡単です。純粋なLLMシステムでは、アーキテクチャは理論上、会話エンジンとバックエンド統合に簡素化できます。 ハイブリッドシステムでは、しかし、両方が必要となります。 これは、並行するインフラストラクチャを維持することを意味します。
利点は柔軟性と回復力ですが、トレードオフは より複雑なアーキテクチャ であり、クロスファンクショナルチームが設計、監視、継続的な調整を行う必要があります。
従来のIVRは時折スクリプトの更新を必要とします。対照的に、ハイブリッドシステムは 多岐にわたる継続的なメンテナンス:
これにより、 ソフトウェア製品のライフサイクル管理 従来の電話サポートよりも近い新たな保守サイクルが導入されます。
ルールベースのファストパスが 単純かつ単一の意図を持つ通話の90~95%を効率的に処理する一方で、ハイブリッド型は依然として以下のコストを発生させます。
企業は、 顧客体験の向上 が追加コストに見合うものかを検討する必要があります。多くの場合、見合うものですが、ROIの計算は業界の利益率や 規制リスク、顧客の期待。
特に医療、銀行、保険業界の企業は、厳格なコンプライアンスを遵守する必要があります。ハイブリッドシステムでは、考慮すべき要素が増えます。
これはガバナンスの複雑さを増しますが、同時に機会も提供します。ハイブリッドシステムは、 より高い透明性 いずれかのアプローチを単独で用いるよりも。
最後に、ハイブリッドシステムの導入には新たなスキルセットが必要です。企業はIVRデザイナーだけでなく、以下の人材も必要とします。
この人材の変化は、レガシーなコールセンターITチームを抱える企業にとって、無視できない検討事項です。
ハイブリッドな音声AIアプローチは「設定したら終わり」ではありません。それは 生きたシステム であり、慎重な設計、継続的な監視、組織的な投資を必要とします。その見返りは、企業が信頼性を犠牲にすることなくAIを活用できるようにする、強靭な架け橋です。しかし、トレードオフは現実的です。 複雑さの増大、保守コストの増加、そして継続的なガバナンスの必要性です。
今日意思決定を行うリーダーにとって、これらのトレードオフを公に認めることは、技術、運用、コンプライアンスの各関係者間の信頼を築く上で極めて重要です。
顧客インタラクション技術の進化は一直線ではなく、サイクルを辿ります。新しいイノベーションは大きな期待とともに登場し、避けられない後退を経験しながら、最終的には企業のツールキットに定着します。同時に、 従来の技術が単に消え去るわけではありません。それらは修正され、安定し、その強みが他に類を見ないニッチな分野で価値を提供し続けます。
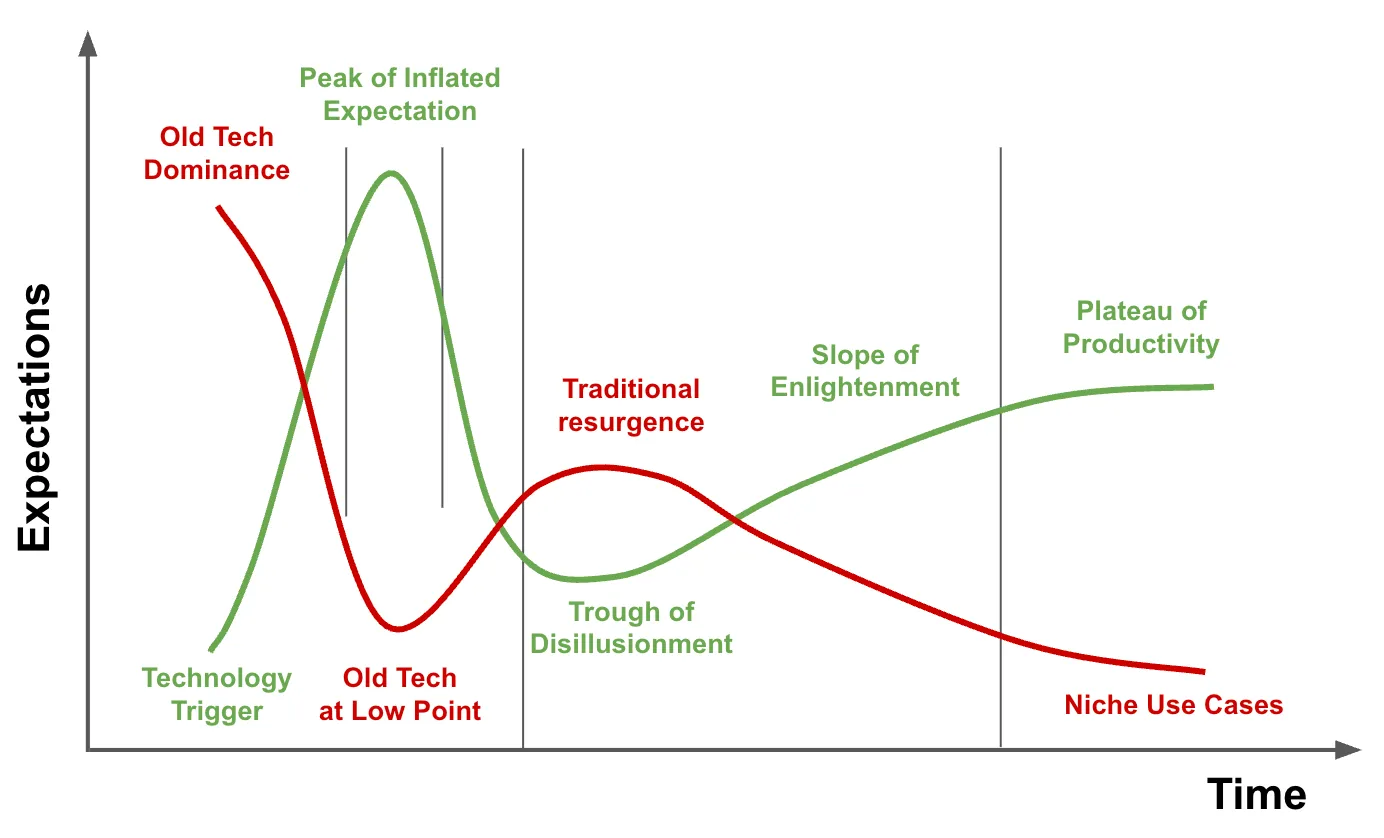
これを考える一つの方法は、 ガートナーのハイプサイクルを拡張することです。これは、新しい技術が「イノベーションの引き金」から「過度な期待のピーク」、「幻滅期」、そして最終的に「生産性の安定期」へとどのように移行するかを示しています。このカーブと並行して、鏡像を描くことができます。それは 従来の技術の「生存」カーブです。
図1:新技術のハイプサイクルと旧技術の抵抗
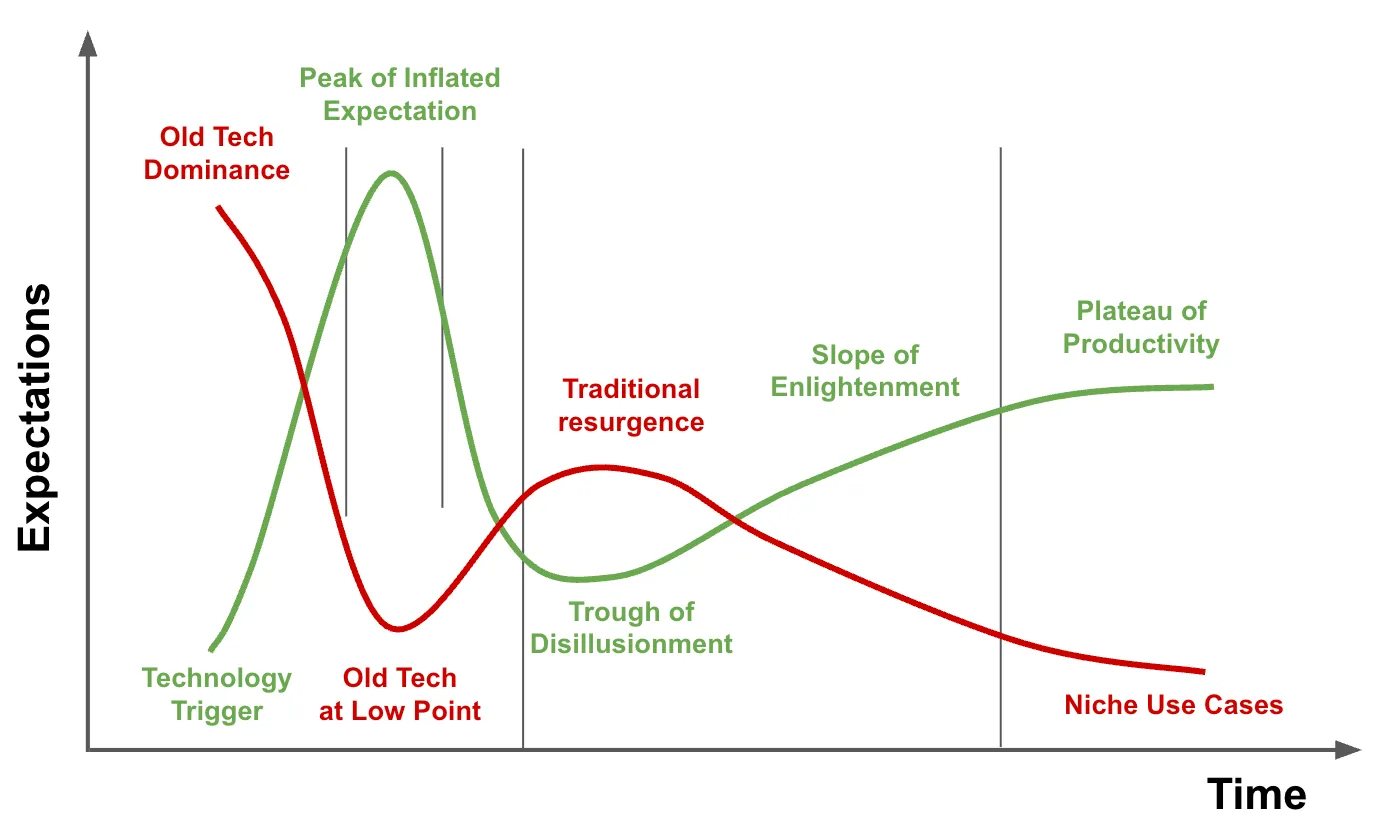
ほとんどの指標によると、 AI駆動型音声エージェントは、未だ「過度な期待のピーク」に近づいている段階です。 企業はその変革の可能性に興奮していますが、大規模な運用におけるその脆弱性にも直面し始めています。実のところ、私たちはまだ 適切なバランスを見つけ出す過程にあります。AIが体験を向上させ、ルールが安全策を提供する場所です。
このバランスは妥協ではなく、 カーブを越える戦略的な架け橋です。 今、ハイブリッドアプローチを採用することで、企業は実証済みのシステムの信頼性を捨てることなく、AIイノベーションの恩恵を享受できる立場になります。時間が経ち、AIが生産性の安定期に向かうにつれて、従来のIVRの役割は狭まりますが、決して消滅することはありません。それは、 予測可能性が最も重要であるニッチでミッションクリティカルな状況で存続するでしょう。
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








最新のニュース、記事、リソースをメールでお届けします
© 2026 無断複写・転載を禁じます。







.png)








.webp)
.webp)


