













.webp)
July 4, 2026
|
5 min read

Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
今日のデータ駆動型社会において、膨大なデータの中から類似する項目を見つけ出すことは、データベースから検索エンジン、レコメンデーションシステムまで、様々なアプリケーションで利用される基本的な操作です。このプロセスは類似性検索として知られ、特定の基準に基づいて類似する項目を特定するものです。
固定された数値基準(特定の給与範囲内の従業員を見つけるなど)に基づく従来のデータベース検索は単純ですが、類似性検索はより複雑なクエリに対応します。例えば、ユーザーが「靴」、「黒い靴」、または「Nike AF-1 LV8」のような特定のモデルを検索する場合があります。これらのクエリは曖昧で多様であり、システムが異なる種類の靴といった概念を理解し、区別する必要があります。
類似性検索は、以下を含む多くの分野で不可欠です。
類似性検索における主要な課題は、検索対象の項目が持つより深い概念的意味を正確に理解しつつ、大規模なデータを扱うことです。記号的なオブジェクト表現に依存する従来のデータベースは、このようなシナリオでは不十分です。その代わりに、データの意味的表現を処理し、大規模なデータでも効率的に検索を実行できる、より高度な技術が必要です。これには、新たな表現方法、距離指標、様々な検索アルゴリズムなどが含まれます。
類似性検索を活用することで、複雑で抽象的なクエリを実行可能な洞察へと変換し、様々な分野で強力なツールとして活用できます。以下のセクションでは、類似性検索がどのように機能するかを、ベクトル表現、距離指標、および様々な検索アルゴリズムの役割に焦点を当てて詳しく見ていきます。
.webp)
機械学習では、現実世界のオブジェクトや概念を、埋め込み(embeddings)として知られる連続した数値の集合であるベクトルとして表現します。このアプローチにより、項目のより深い意味的意味を捉えることができます。画像やテキストのようなオブジェクトがベクトル埋め込みに変換されると、高次元空間におけるこれらのベクトル間の距離を測定することで、それらの類似性を評価できます。
例えば、ベクトル空間では、類似する画像は互いに近いベクトルを持ち、類似しない画像はより離れたベクトルを持ちます。これにより、数学的な演算を実行して、類似する項目を効率的に見つけ出し、比較することが可能になります。
.webp)
これらのベクトル埋め込みの生成には、いくつかのモデルが使用されます。
これらのモデルは、大規模なデータセットとタスクで訓練されており、アイテムの意味内容を効果的に表現する埋め込みを生成できます。
2つのベクトル埋め込みがどれほど類似しているかを判断するために、距離指標を使用します。これらの指標は、ベクトル空間におけるベクトル間の「距離」を計算し、距離が小さいほど類似性が高いことを示します。
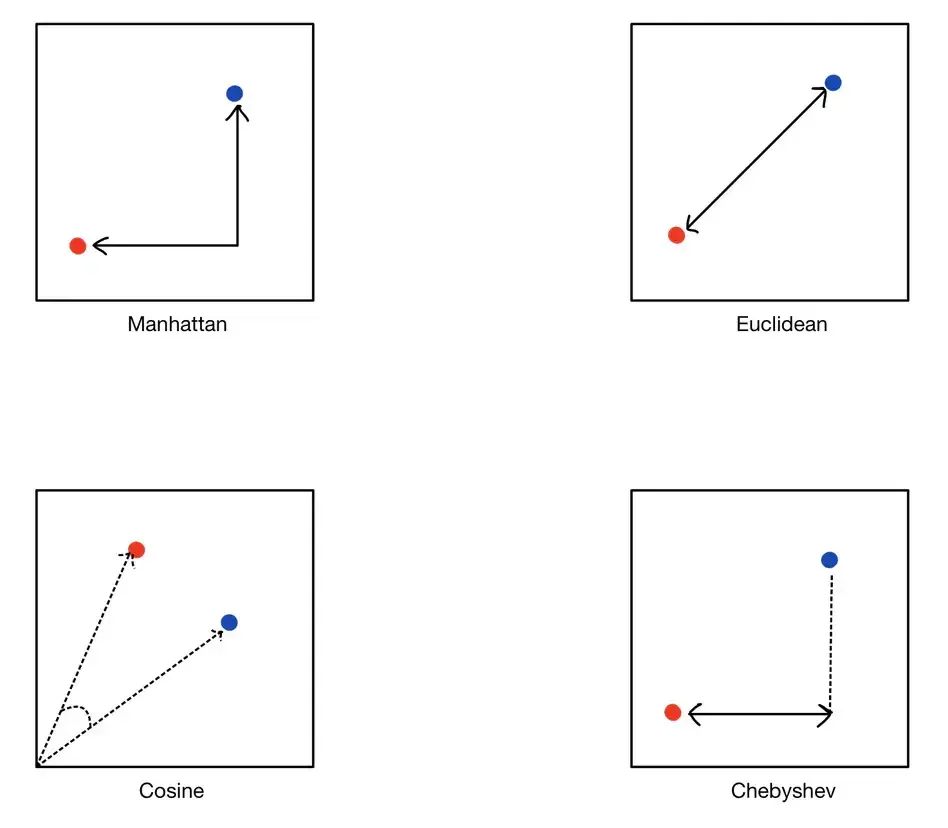
ユークリッド距離は、高次元空間における2点間の直線距離を測定します。これは距離を測定する最も直感的な方法であり、定規で測る幾何学的距離に似ています。データが密で、物理的な距離の概念が関連する場合に役立ちます。
計算式:
.webp)
L1距離とも呼ばれるマンハッタン距離は、座標の絶対差を合計します。この指標はグリッド状のデータ構造に適しており、グリッド内の点間を移動する際の総「市街地ブロック」距離として視覚化できます。
計算式:
.webp)
コサイン類似度は、2つのベクトルのなす角のコサインを測定し、大きさではなく方向に着目します。これは、ベクトルの大きさ(単語の頻度)は変動する可能性がありますが、方向(単語の使用パターン)の方が重要であるテキストデータに特に有用です。
.webp)
チェビシェフ距離は、2つのベクトルの座標間の最大距離を測定します。これは、斜め方向を含むあらゆる方向に移動できるチェスのようなグリッド状のシナリオでよく使用されます。
.webp)
適切な距離尺度の選択は、アプリケーションの特定の特性と要件によって異なります。適切な指標を選択するためのガイドラインをいくつか紹介します。
K近傍法 (k-NN) は、与えられたクエリベクトルに最も近いベクトルを見つけるために使用される一般的なアルゴリズムです。その仕組みと長所・短所は以下の通りです。
.webp)
大規模なデータセットにおけるk-NNの非効率性を解決するため、近似最近傍探索 (ANN) 手法は、精度は劣るものの、より高速な代替手段を提供します。ANNアルゴリズムは、速度のために多少の精度を犠牲にし、最近傍の「良い推測」を見つけることを目指します。
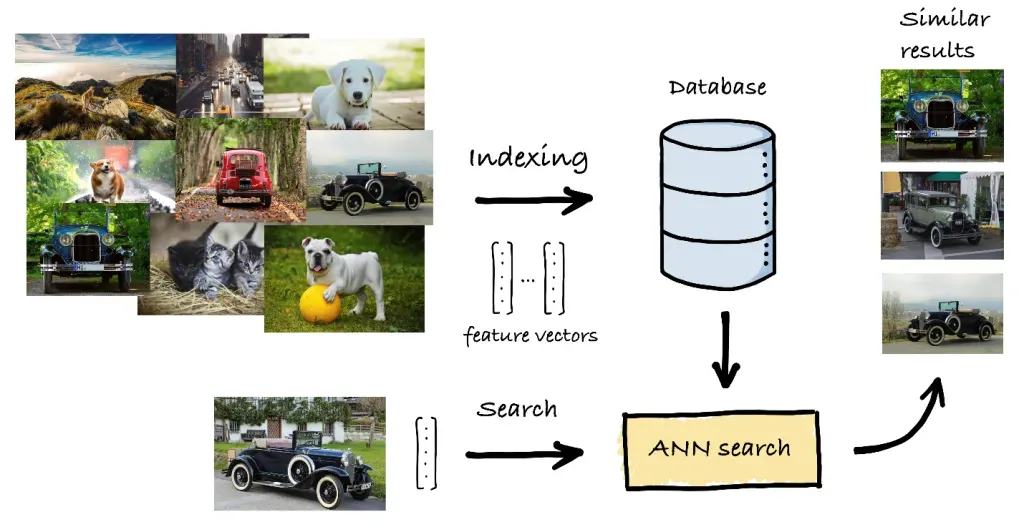
実際に類似性検索を実装する際には、いくつかのライブラリやフレームワークが役立ちます。
類似度検索は、類似する項目を迅速かつ正確に発見・比較できる能力を活用し、さまざまな分野で幅広い応用が可能です。主な応用例をいくつかご紹介します。
レコメンデーションシステムは、ユーザーの好みや行動に基づいて、製品、コンテンツ、またはサービスを提案するために類似度検索を利用します。
類似度検索は、大規模なデータベースから視覚的に類似した画像や動画を検索するために不可欠です。
NLPにおいて、類似度検索は意味的に類似した文書やフレーズを見つけることで、さまざまなテキストベースのアプリケーションで役立ちます。
通常の行動から逸脱するパターンや異常を見つけることで、不正行為を検出します。
類似性検索は、患者データと遺伝子配列を比較することで、医療診断と遺伝子研究に役立ちます。
類似性検索における主要な課題の1つは、ユーザーのクエリの性質です。クエリは、「靴」のような非常に一般的な用語から、「Nike AF-1 LV8」のような非常に具体的なアイテムまで多岐にわたります。システムは、これらのニュアンスを識別し、異なるアイテムが互いにどのように関連しているかを理解できる必要があります。これは、単純なキーワードマッチングを超えた、クエリの背後にある意味論的な意味を深く理解することを必要とします。
もう1つの重要な課題はスケーラビリティです。実際のアプリケーションでは、数十億のアイテムを含む膨大なデータセットを扱うことがよくあります。このような大量のデータを効率的に検索するには、高度な技術と強力な計算リソースが必要です。厳密な一致と記号表現のために設計された従来のデータベースシステムは、これらのシナリオではうまく機能しません。
ベクトル検索とも呼ばれる類似性検索は、さまざまな現代のアプリケーションにおいて極めて重要な役割を果たします。ベクトル埋め込みと高度な距離指標を活用することで、類似性検索は意味に基づいてアイテムを検索・比較することを可能にします。主なポイントは以下の通りです。
類似性検索の真の力を活用するには、その根底にある原則を理解し、特定のニーズに合った適切なツールと手法を選択することが不可欠です。レコメンデーションエンジン、コンテンツベースの検索システム、不正検出メカニズムを構築しているかどうかにかかわらず、類似性検索は、ソリューションの精度と効率を大幅に向上させることができます。
類似性検索とは、膨大なデータセットの中から類似するアイテムを見つけるための手法です。データの概念的な意味を捉えるベクトル埋め込みに依存し、多くの場合、ベクトル表現と距離指標を使用します。このプロセスは、製品レコメンデーションやテキストマッチングなどのアプリケーションにとって非常に重要であり、システムが関連情報を効率的かつ正確に特定できるようにします。
類似性検索を実行するには、テキストや画像などのオブジェクトは、まず専門のモデルを使用してベクトル埋め込みに変換されます。次に、ユークリッド距離やコサイン距離などの距離指標が、高次元空間におけるこれらのベクトル間の「距離」を測定します。距離が小さいほど類似性が高いことを示します。あるいは、コサイン類似度のような類似度指標は近さを直接スコア化し、スコアが高いほど(1に近いほど)類似性が高いことを意味します。
類似性検索の優れた例は、ユーザーが閲覧または購入した商品に類似した商品を推奨するEコマースプラットフォームです。これにより、買い物客は関連商品を簡単に見つけることができます。膨大なデータベースから視覚的に類似した画像を見つける画像検索も、類似性検索技術を用いた重要なアプリケーションです。
LLMを活用したシステム、特にRAG(Retrieval-Augmented Generation)パイプラインにおいて、類似性検索は、テキストを意味を捉えるベクトル埋め込みに変換することで、モデルと連携して機能します。検索レイヤーはこれらのベクトルを検索してクエリに最も類似するコンテンツを見つけ、これらのベクトル間の距離を測定することで結果をLLMに渡します。これは、関連情報を取得し、文脈に応じた応答を生成するために不可欠であり、モデルの理解度とユーザーにとっての有用性を大幅に向上させます。
類似検索は、多くのアプリケーションにおいて不可欠です。Eコマースの製品レコメンデーションを強化し、画像や動画の検索を容易にし、テキストマッチングにおける自然言語処理を向上させます。ヘルスケア分野では、類似の医療ケースの特定に役立ち、複雑なデータを業界全体の実行可能な洞察へと変革します。
セマンティック検索は、キーワードだけでなく意味に基づいて項目を見つけるために類似検索を利用します。データをセマンティックに表現するためにベクトル埋め込みを使用します。類似検索がこれらのベクトルを比較する手法であるのに対し、セマンティック検索は、より深い文脈理解のためにそれを活用するアプリケーションです。
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








最新のニュース、記事、リソースをメールでお届けします
© 2026 無断複写・転載を禁じます。







.png)








.webp)
.webp)


