













.webp)
July 4, 2026
|
5 min read

Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
厳密一致キャッシュは、30年間適切なデフォルトでした。しかし、LLMにとっては不適切なデフォルトです。なぜなら、テキストは意図そのものではなく、意図の表面に過ぎないからです。セマンティックキャッシュの役割は、その下にあるものをキャッシュすることです。
従来のAPIキャッシュはハッシュテーブルです。リクエストはハッシュ化され、レスポンスはそのハッシュに対してキー付けされ、次にバイト単位で同一のリクエストが来た場合、キャッシュされた値が返されます。このモデルは、決定論的なAPIに対しては正しいです。なぜなら、ハッシュがリクエストに関する重要なすべてを捉えているからです。呼び出しには、そのバイトに含まれていない情報はありません。
LLMのワークロードは、この前提を表面レベルで打ち破ります。カスタマーサポートの流れで、3人のユーザーが同じことを3つの異なる形で尋ねます。
ユーザーのトラフィック · 60秒間
-- ユーザーA: 「パスワードをリセットするにはどうすればいいですか?」
-- ユーザーB: 「パスワードを忘れました。どうすればいいですか?」
-- ユーザーC: 「パスワードリセットページはどこにありますか?」
SHA-256キャッシュにとって、これらは3つのキー、3つのキャッシュミス、そして3回のプロバイダーへの完全な呼び出しです。モデルにとっては、意図は同じであり、応答も同じであるべきです。生のテキストをハッシュ化するキャッシュは、間違ったキャッシュではありません。それは、意味の層が間違っているキャッシュなのです。テキストは意図を伝える上で情報が失われやすい媒体であり、同じ意図でも多くの表面的な表現があります。厳密一致キャッシュは、本質ではなく表面をキーとしています。
このギャップは無視できないほど大きいです。バイト単位で同一のリクエストのみにヒットするキャッシュは、意図にヒットするキャッシュが捉える呼び出しのごく一部しか捉えられません。そのギャップを埋めるのがセマンティックキャッシュの目的です。
プロダクションレベルのセマンティックキャッシュは、単に埋め込みと検索を行うだけでは済みません。ポリシー境界を強制し(異なるシステムプロンプトが衝突しないように)、テナント分離を尊重し、「左腕が痛い」と「右腕が痛い」を混同しないようにする必要があります。TrueFoundryゲートウェイは、これら4つの懸念事項すべてを単一のホットパスに統合する4段階のパイプラインを実行します。
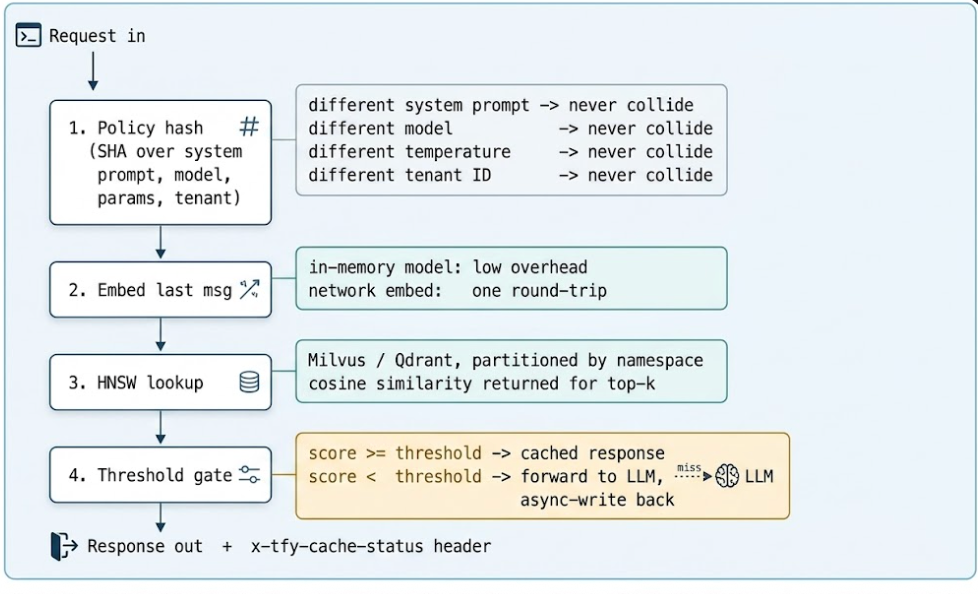
微妙な詳細ですが、セマンティックに比較されるのは最後のメッセージのみです。それ以外のすべて(モデル名、温度、以前のメッセージ、システムプロンプト、テナントID)は厳密にハッシュ化されます。これらのいずれかが一致しない場合、ユーザーの最新の行が文字通り同一であっても、キャッシュはリクエストを異なるものとして扱います。それが正しいデフォルトです。事前に読み込まれた会話コンテキストは、ほとんどのエンジニアが予想する以上に意味を変えるため、キャッシュはそれらを統合しないことを優先すべきです。
埋め込みベクトルは高次元空間に存在します。MiniLMでは384次元、BGE-baseでは768次元、text-embedding-3-smallでは1536次元です。その幾何学において、ユークリッド距離は主にノイズであるベクトルの大きさに支配されます。意味的な意味を伝えるのは方向です。コサイン類似度は、2つのベクトル間の角度のコサインを計算することで大きさを正規化します。これはスケールに対して不変であるため、同じ方向を指す2つのベクトルは、長さに関係なく1.0のスコアになります。
現代のすべてのセマンティックキャッシュはコサインを使用しています。ユークリッド距離を使用するのは、埋め込みモデルがそもそも単位正規化されたベクトルを生成する場合に限られます。その場合、2つのメトリクスは定数倍を除いて同等であり、コサインの方が依然として理解しやすいです。ユークリッド距離が正しい答えとなる実用的なワークロードは存在しません。
素朴な最近傍探索はO(N)であり、各クエリはキャッシュされたすべてのベクトルと比較されます。100万件のエントリでは、比較にかかるコストは現実的ではありません。HNSW(Hierarchical Navigable Small World)は、各ノードが少数の近傍ノードに接続され、上位層ではより疎なリンクを持つ階層型グラフを構築します。クエリは最上位層から開始し、最も近い一致に向かって貪欲に探索を進め、層を降りてこれを繰り返します。この探索はO(log N)個のノードを訪れます。これは近似的ですが、厳密な探索と比較して通常95~99%のリコール率を達成し、桁違いに安価です。MilvusとQdrantはどちらもHNSWを搭載しており、TrueFoundryはデプロイメントが設定されている方を使用します。
セマンティックキャッシュは、計算コストをレイテンシとプロバイダー費用と引き換えにするため、埋め込みモデルはシステムにおいて最も重要な決定事項となります。主に2つの選択肢があります。
OpenAIのtext-embedding-3-small、Cohere、Voyageなどのマネージドモデルは、すぐに使える状態で強力なクロスドメインのセマンティック理解を提供します。その代償として、すべてのリクエストでネットワークのラウンドトリップが発生し、キャッシュによるレイテンシ改善効果を直接的に損ないます。TrueFoundry SaaSでは、text-embedding-3-small(1536次元)がデフォルトであり、ユーザーによる設定はできません。これはマネージド層における意図的な選択であり、あらゆる呼び出しで償却できるほど安価で、実績のある優れたベースラインです。
BGE-micro(384次元)やall-MiniLM-L6-v2(384次元)のようなインメモリの代替モデルは、ゲートウェイプロセス内で実行され、ネットワークへの依存を完全に排除し、リクエストパスから埋め込みのラウンドトリップを取り除きます。オンプレミス層では、埋め込みモデルはダッシュボード(コントロール → 設定 → セマンティックキャッシュ)から設定可能です。この選択はゲートウェイ全体に適用されます。コーディングアシスタント、技術文書、カスタマーサポートフローといった社内向けワークロードの場合、ドメイン固有の語彙で小さなローカルモデルをファインチューニングすることが、通常、スタック全体で最もROIの高い施策となります。「k8s」と「Kubernetes」はほぼ同じベクトルに埋め込まれるべきです。汎用モデルはこれらを「いとこ」のように扱いますが、ファインチューニングされたモデルは「同義語」として扱います。ヒット率はそれに応じて変化します。
次元数に関して実用的な考察があります。高次元の埋め込み(1536次元)はより多くのセマンティック情報を含みますが、インデックス作成と検索にはより多くのコストがかかります。1536次元のHNSWは、384次元の場合と比較して、約4倍のメモリと2倍の検索時間を要します。ほとんどのキャッシュワークロードにおいて、ファインチューニングされた384次元モデルに対する1536次元モデルのわずかなリコール率向上は小さく、運用上の節約がそれを上回ります。まずは384次元から始め、実際のトラフィックでの測定された精度とリコール率がそれを正当化する場合にのみ、次元数を増やすことを検討してください。
表1 — 埋め込みモデルは、セマンティックキャッシュがレイテンシ改善となるか、あるいは効果がないかを決定する要素です。本番環境では、インメモリパスがそれ自体で費用対効果を生み出す道筋となります。
類似度しきい値は、節約とリスクの間のスライダーです。これを下げると、ヒット率が上がり、コストは下がりますが、同時に誤ったヒット(古くなった、または文脈的に間違った回答を返すこと)の可能性も高まります。この設定は、x-tfy-cache-configを介してリクエスト内に存在します。
HTTP · リクエストヘッダー
x-tfy-cache-config: {
"type": "semantic",
"similarity_threshold": 0.94,
"ttl": 600,
"namespace": "tenant-123"
}TrueFoundryが推奨する開始点は0.9で、その許容範囲は誤ったキャッシュヒットに対する許容度によって異なります。
表2 — しきい値の範囲。グローバルな「正しい」値というものは存在しません。適切な閾値は、あなたのドメインにおける誤ったヒットのコストに見合うものです。
医療トリアージの思考実験は、その危険性を具体的に示します。「左腕が痛い」と「右腕が痛い」は、汎用埋め込み空間では0.91のスコアになる可能性があります。しきい値が0.90の場合、キャッシュは物理的に正反対の2つの症状に対して、喜んで同じアドバイスを返してしまいます。一般的なFAQボットであれば0.88でも完全に安全かもしれませんが、トリアージにおいては医療過誤となります。このしきい値はグローバルなハイパーパラメータではなく、誤った回答がどれほどコストがかかるかを示す、ワークロードごとのエンコーディングなのです。
しきい値を選択することは、あなたのトラフィックに特化した適合率/再現率曲線上の点を選択することです。以下は、カスタマーサポートのワークロードにおける典型的な曲線の形状です。あなたの曲線は左右にシフトするかもしれませんが、形状は同じです。
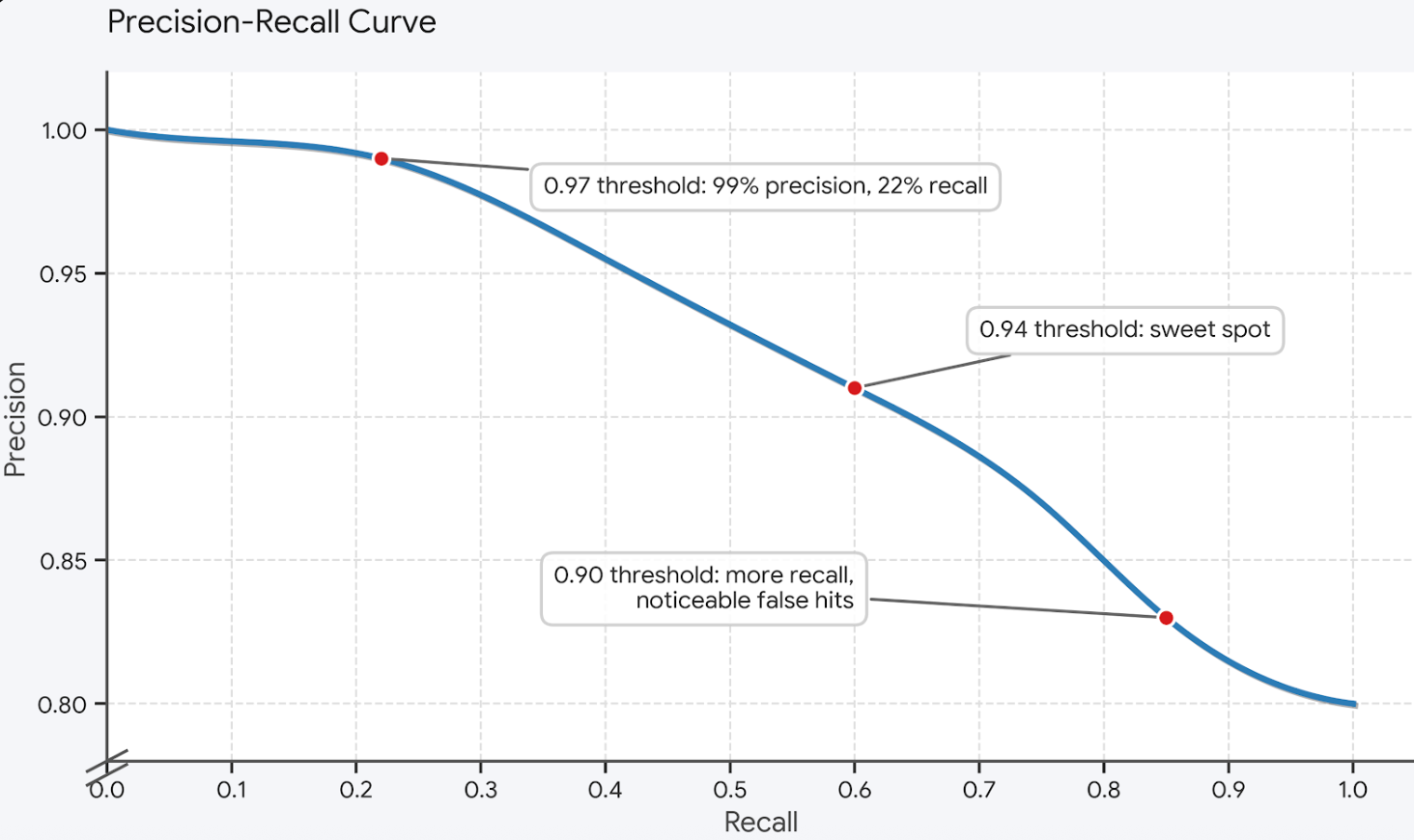
最適な点を選択するための適切な方法はシャドウモードです。設定可能な期間(通常は1週間)にわたり、キャッシュは類似度を計算し、実際にキャッシュされた応答を提供することなく、各閾値で何が一致したかをログに記録します。エンジニアはログをレビューし、実際のトラフィックに基づいて上記の曲線の独自のバージョンをプロットし、ワークロードが許容できるレベルまで誤ったヒットを抑える閾値を選択します。この閾値はグローバルな定数ではなく、ワークロードごとのチューニングノブであり、チューニングデータは合成クエリではなく、本番トラフィックから取得する必要があります。
すべての応答において、ゲートウェイは、このループをデバッグ可能にする3つのヘッダーを返します。それらは、x-tfy-cache-status(ヒット/ミス/エラー)、x-tfy-cache-similarity-score(ヒット時のコサインスコア)、およびx-tfy-cached-trace-id(エントリを生成した元のリクエストのトレースID)です。3番目のヘッダーは、あなたが何度も参照することになるでしょう。これにより、キャッシュされた回答を生成した会話まで遡って追跡することができ、これが誤動作をデバッグする唯一の方法です。
根本的な事実が変わってしまった場合、セマンティックな類似性は危険なものとなります。「現在の金利はいくらですか?」という質問は、昨日と今日では意味的には同じですが、事実としては異なります。キャッシュは、類似度スコア1.0で先月の数値を平然と提供してしまうでしょう。
ワークロードには、それぞれに特化したTTLが必要です。静的なドキュメントアシスタントは、根本的な情報源がドキュメントであり、ドキュメントの変更がリリースサイクルに依存するため、数日間のTTLでも問題ありません。RAGアプリケーションはドキュメントハッシュによる無効化を利用します。ソースドキュメントが変更されると、そこから派生したすべてのキャッシュエントリが自動的にフラッシュされます。時間に敏感な事実(レート、価格、スケジュールなど)には、短く厳格なTTLが設定され、日をまたいで統合されることはありません。これらの場合、セマンティックキャッシュは不適切なツールであることが多く、完全一致またはキャッシュなしに切り替えるべきです。
セマンティックキャッシュが苦手なことについて正直になる価値はあります。世界の変化とともに変わるべきものは、いかなる閾値においてもキャッシュに適さない情報です。適切な経験則は、「人間が回答が古くなっていることに気づくなら、キャッシュも同様に古い」ということです。
明示的に設計で考慮すべき運用上の危険が1つあります。それはキャッシュスタンピードです。人気のあるクエリが期限切れになり、同じ秒間に1000件の同一リクエストが到着した場合、単純なキャッシュはそれらすべてをLLMに通過させ、その後、1000件すべてが結果を書き戻そうとします。TrueFoundryゲートウェイはシングルフライトセマンティクスを使用します。つまり、キャッシュミスした最初のリクエストがキーごとのロックを取得し、LLM呼び出し中の後続の同一リクエストはその単一の応答を待って再利用します。ライトバックは非同期(応答はすぐにクライアントに返され、ベクトルはバックグラウンドでMilvus/Qdrantにコミットされます)であるため、キャッシュへの書き込みがリクエストパスのレイテンシに影響を与えることはありません。
どのようなB2B SaaS展開においても、テナントAがテナントBのために生成されたキャッシュ応答を受け取ることは、バグではなく、情報漏洩です。キャッシュアーキテクチャは、事後的なフィルタリングではなく、設計段階からそのような結果を許さないものでなければなりません。
TrueFoundryはキャッシュエントリを2つのレベルで分離し、ユーザーは最初のレベルについて考慮する必要はありません。
ほとんどのチームにとって、レベル1で十分です。レベル2は、1つの仮想アカウントが多数のダウンストリームエンドユーザー(例えば、自社の顧客のためにLLMリクエストをプロキシするSaaSなど)に展開され、顧客ごとのキャッシュがデータレジデンシーの要件を満たす必要がある場合に利用する手段です。いずれの場合も、情報漏洩の原因となるグローバルなベクトルプールは存在しません。これは、SOC 2およびHIPAAの審査官を満足させる実装です。
AnthropicとOpenAIは両社ともプロンプトサイドキャッシュを導入しています。プロバイダーはシステムプロンプトのプレフィックスをハッシュし、キャッシュヒット時に内部状態を再利用することで、キャッシュされた入力トークンの料金を低く抑えています。これはこれまで議論してきたものとは異なるレイヤーですが、両者は連携して機能します。
プロバイダーのプロンプトキャッシュは、最初のトークンまでの時間を短縮し、キャッシュされた入力トークンのコストを削減しますが、モデルは依然として新しい補完を生成します。ゲートウェイのセマンティックキャッシュは、モデル呼び出しを完全に排除します。片方から恩恵を受けるほとんどのチームは両方から恩恵を受けますが、ゲートウェイ側のキャッシュの方がより大きな効果をもたらします。ヒット時のレイテンシを桁違いに改善し、コストを完全に排除し、プロバイダーの関与なしに組織がデバッグ、監査、調整できるレイヤーを提供します。プロバイダーのキャッシュは不透明ですが、ゲートウェイのキャッシュはあなた自身のものです。
分散システムには古くからの観察があります。キャッシュは、それが捉えるように設計された意味のレイヤーにおいてのみ、正確性を維持します。ページキャッシュが機能するのは、ページが正確性の単位だからです。クエリキャッシュが機能するのは、同一のクエリが同一の結果を生成するからです。テキストをハッシュするLLMキャッシュは、意味の誤ったレイヤーでキャッシュしており、その誤りはヒットすべき場所でのミスという形で現れます。
セマンティックキャッシュは、キャッシュキーをテキストから意図へと移行させる作業です。意図は文字列よりも抽象的なオブジェクトであるため、より多くのインフラストラクチャ(埋め込みモデル、ベクトルインデックス、閾値)が必要です。しかし、それはワークロードにとって適切な抽象化であり、キャッシュ層が意味層と一致すれば、その節約は単なる最適化ではなく、最初から正しいアーキテクチャであったかのように感じられるでしょう。
いいえ。セマンティックキャッシュは厳密なスーパーセットであり、完全一致はコサイン類似度1.0に過ぎません。TrueFoundryでは、キャッシュタイプをセマンティックに設定すると、完全一致のヒットも返されます。両方のレイヤーを別々に実行することは、無効化を複雑にする重複したインフラストラクチャであり、ゲートウェイはそれらを単一のレイヤーとして扱います。
それは、ほとんどの呼び出しがキャッシュミスするようなワークロードで、ネットワークホスト型の埋め込みモデルを使用した場合に限られます。ゲートウェイノードで小さなインメモリモデルを実行する主な目的は、埋め込みコストを、ヒットによるメリットを帳消しにするような閾値よりもはるかに低く抑えることです。SaaSティアでは、デフォルトの埋め込みモデルはtext-embedding-3-smallであり、おおよそ1回のネットワークラウンドトリップを追加します。これは、埋め込みインフラを自分で運用しないことのコストです。
少なくとも1週間はシャドウモードで実行してください。実際のトラフィックに対してどのような結果をもたらすかを確認せずに、閾値をリリースしてはいけません。合成データと本番データで同じ質問のスコアがわずかに異なることが、キャリアを終わらせるような驚きとなることがありますが、これは1つのログと1つのJupyterノートブックで完全に回避できます。
キャッシュは、モデル呼び出しが始まる前に事前に決定されます。ヒットした場合、応答はストリーミングの遅延なく即座に返されます。ミスした場合、ストリーミング応答は非同期でキャプチャされ、呼び出し完了後にキャッシュにコミットされます。ストリーミングとキャッシュのトレードオフを管理する必要はありません。
ゲートウェイは、すべてのリクエストをLLMプロバイダーに転送するようフォールバックします。キャッシュミスは、キャッシュがなかった場合と同じコストがかかり、何も壊れません。唯一の運用上のシグナルは、応答のx-tfy-cache-status: errorヘッダーであり、これはダッシュボードのアラートに接続されるべきです。リクエストパスの信頼性は、キャッシュ層の可用性よりも優先されます。
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








最新のニュース、記事、リソースをメールでお届けします
© 2026 無断複写・転載を禁じます。







.png)








.webp)
.webp)


