













.webp)
July 4, 2026
|
5 min read

Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
Anthropicは2024年11月にModel Context Protocolを導入し、1年以内にほぼすべてのAPIツールベンダーといくつかの独立したジェネレーターが、OpenAPI仕様を動作するMCPサーバーに機械的に変換する方法を提供しました。基本的なマッピングはほとんどがクリーンです。パスはツール名に、パラメータは入力スキーマに、成功応答は出力スキーマになります。興味深いのは、マッピングで情報が失われる部分(ページネーション、マルチパートアップロード、Webhook、ストリーミング応答など)と、生成されたサーバーが実際に使用可能かどうかを決定する運用上の要素(認証情報の注入、スキーマ検証、説明の品質)です。この記事では、完全なアルゴリズムと、変換できない特定のパターンについて解説します。
Northwindでの火曜日。 物流プラットフォームチームのインテグレーションリーダーであるプリヤは、「ルーティング最適化エージェントからshipment-tracking-svcを呼び出せるようにする」というチケットを受け取りました。このサービスには、47のRESTエンドポイント、保守されたOpenAPI 3.1仕様、OAuth2認証、カーソルベースのページネーション、2つのWebhookエンドポイント、およびライブトラックテレメトリ用のストリーミングエンドポイントがあります。エージェントのMCPツールボックスには現在、他の3つのサービスにまたがる12のツールがあり、それぞれ約1週間かけて手作業でコーディングされたものです。そのペースで47のエンドポイントを実装すると、エンジニアリング時間の四半期の大半を占めることになるでしょう。
OpenAPI仕様は、パス、パラメータ、スキーマ、応答形式、さらには操作ごとのOAuth2スコープに至るまで、すでに機械可読な形式でサービスを記述しています。彼女が行ってきた手作業でのコーディングは、仕様にすでに含まれていない情報を追加するものではありません。その作業は、ほとんどが1つのスキーマ言語から別のスキーマ言語への変換であり、少数の明確に定義されたエッジケースを伴うものでした。その作業はビルドステップに属するものであり、エンジニアリング時間の四半期を費やすべきものではありません。
この記事では、変換アルゴリズム、つまり何がクリーンにマッピングされ、何がそうでないか、そして生成されたサーバーを実際に使用可能にする運用上の要素(認証、検証、説明の品質)について説明します。
変換はOpenAPIドキュメントを走査し、(パス, メソッド)のペアごとに1つのMCPツールを出力します。各ペアについて、ツール名、説明、入力スキーマ、そして(ターゲットMCPリビジョンがサポートしている場合)出力スキーマの4つの要素を計算します。
ツール名。 仕様作成者がoperationIdを提供している場合は、そちらを優先します。operationIdは慣用的な識別子であり、通常は読みやすさのためにすでに選ばれています。存在しない場合は、メソッドとパスから合成します。メソッドを小文字にし、パスの非英数字をアンダースコアに置き換え、重複するアンダースコアを結合します。例えば、GET /users/{user_id}/repos は get_users_user_id_repos となります。合成された形式は構文的には有効ですが冗長であるため、operationIdが存在する場合はそちらが優先されます。
ツール説明。 summary、description、そしてメソッドとパスから生成されたスタブの順に優先します。この一見些細なフィールドが、人々が予想する以上に重要である理由については、セクション6で説明します。
入力スキーマ。 パスパラメータ、クエリパラメータ、およびリクエストボディスキーマを単一のJSONスキーマオブジェクトに統合したもので、適切な必須/オプションマーカーが付与されます。詳細はセクション2を参照。
出力スキーマ。 application/jsonに対する最初の2xx応答に付随するスキーマです。その他のコンテンツタイプや2xx以外の応答は表現されません。詳細はセクション3を参照。
YAML — OpenAPIパスアイテム(shipment-tracking-svcからの抜粋)
paths:
/users/{user_id}/repos:
get:
operationId: listUserRepos
summary: List a user's repositories
description: Returns repositories accessible to the
authenticated user, owned by user_id, paginated by cursor.
parameters:
- name: user_id
in: path
required: true
schema: { type: string }
- name: per_page
in: query
schema: { type: integer, default: 30, maximum: 100 }
- name: cursor
in: query
schema: { type: string, nullable: true }
responses:
'200':
description: OK
content:
application/json:
schema:
$ref: '#/components/schemas/RepoListPage'
'401': { $ref: '#/components/responses/Unauthorized' }
'404': { $ref: '#/components/responses/NotFound' }
security:
- oauth2: [repo:read]JSON — 生成されたMCPツール
{
"name": "list_user_repos",
"description": "List a user's repositories. Returns repositories accessible to the authenticated user, owned by user_id, paginated by cursor.",
"inputSchema": {
"type": "object",
"properties": {
"user_id": { "type": "string" },
"per_page": { "type": "integer", "default": 30, "maximum": 100 },
"cursor": { "type": "string", "nullable": true }
},
"required": ["user_id"]
},
"outputSchema": { "$ref": "#/$defs/RepoListPage" }
}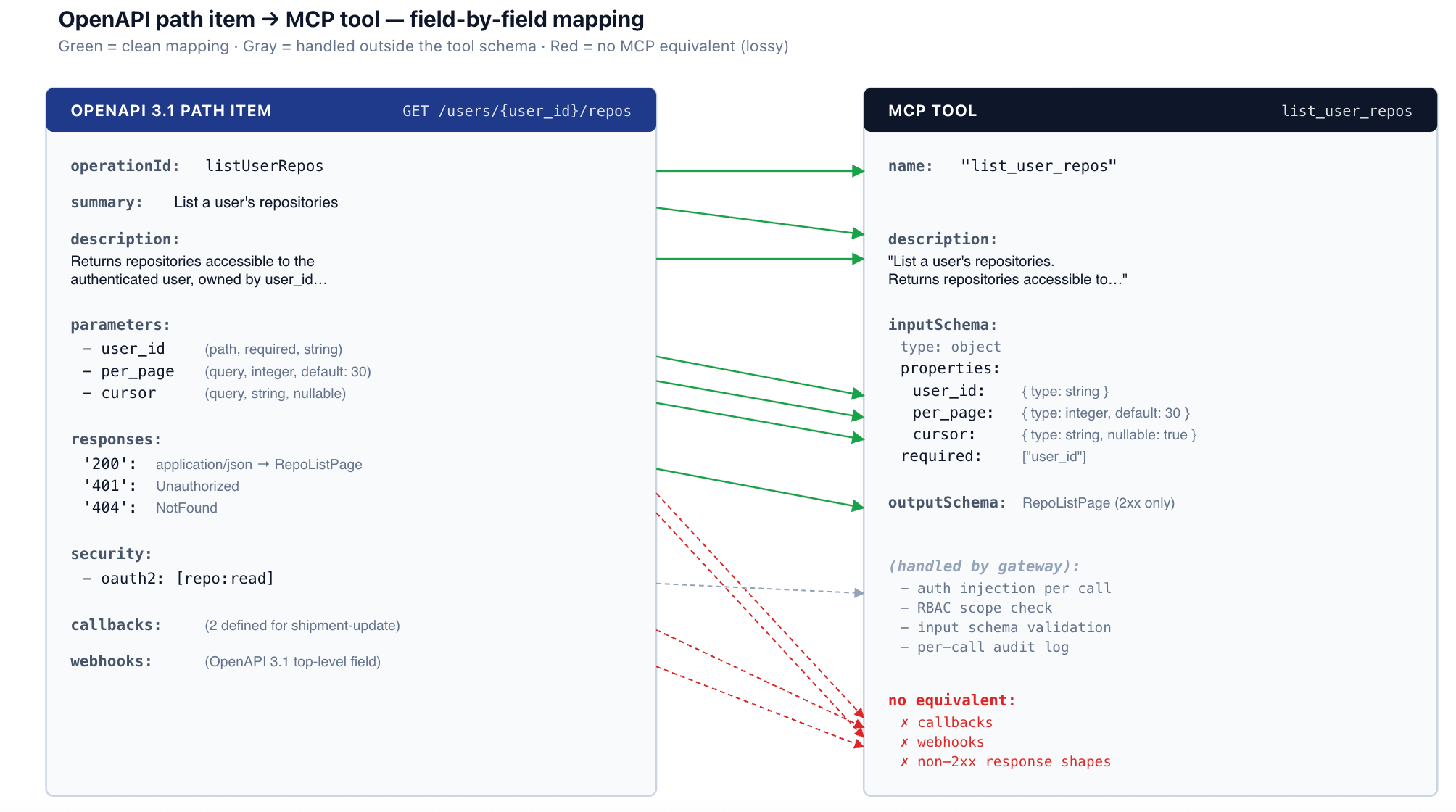
パスパラメータは常に必須であり、入力スキーマの必須エントリとなります。クエリパラメータは、明示的に必須とマークされていない限りオプションであり、デフォルト値があれば引き継がれます。ヘッダーは通常、エージェントが扱う入力からは省略されます(エージェントがContent-Typeを選択すべきではないため)。ただし、セマンティック情報(X-Org-Id、X-Idempotency-Keyなど)を持つヘッダーは明示的に例外とされます。
application/jsonのリクエストボディは、入力スキーマ内のネストされたオブジェクトにマッピングされます。リクエストボディ全体が1つの構造化された引数となり、通常はボディスキーマの$refにちなんで命名されます(例えば、#/components/schemas/CreateRepoRequestを参照するリクエストボディは「create_repo_request」プロパティになります)。OpenAPIのリクエストボディと入力スキーマがどちらもJSON Schemaであるため、これは変換において最もクリーンなケースであり、ほとんどがコピーで済みます。
multipart/form-dataおよびapplication/x-www-form-urlencodedは、部分的にサポートされるケースです。MCPツールはJSON引数を受け入れますが、生成されたサーバーは転送前にJSONを適切なボディ形式に再シリアライズする必要があります。バイナリファイルのアップロード(multipartの最も一般的な理由)には、クリーンな同等物がありません。MCPはbase64エンコードされた文字列を渡すことができますが、ほとんどのAPIはmultipartエンドポイントでそれを受け入れません。バイナリアップロードに関する正直な答えは、生成されたツールではなく、手書きのツールが必要となることが多いということです。
成功レスポンスのみがツールの出力スキーマとして公開されます(ただし、ターゲットMCPリビジョンがoutputSchemaをサポートしている場合に限ります。このフィールドは2025-06-18の仕様改訂で追加されたため、古いランタイムでは無視されます)。変換では、application/jsonコンテンツに対して最初の2xxレスポンス(200、201、202)が選択されます。その他のコンテンツタイプは公開されません。2xx以外のレスポンスは、代替の出力形式としてではなく、ツールエラーとしてエージェントに返されます。
これには微妙な結果が伴います。エージェントは成功パスのレスポンス形式を見るだけで、構造化されたエラーレスポンス形式を見ることはありません。これはほとんどの場合正しいことです(エージェントはエラーレスポンススキーマに対して有用な計画を立てることはないため)が、エラー処理が型付けされたものではなく、汎用的なもの(HTTPステータスコードとメッセージ)でなければならないことを意味します。豊富な構造化エラー(検証の詳細、部分的な成功レスポンスなど)を持つAPIの場合、この情報が失われます。
また、ページネーションが最初に破綻する点でもあります。ページネーションされたリストエンドポイントの出力スキーマは、概念的な完全なリスト結果ではなく、単一ページのレスポンス形式です。ツールを呼び出すエージェントは、リスト全体ではなく1ページを取得します。これが次のセクションにつながります。
REST APIはページネーションを行います。MCPツールは、プロトコル設計上、単一の結果を返します。これらを調和させることは、変換における最も難しい決定です。それぞれ異なるトレードオフを伴う、3つの現実的な選択肢があります。
(a) エージェントがページネーションを処理できるほど賢い必要がある(多くのモデルは最初のページを取得して停止します)(b) 内部で全てフェッチする。生成されたサーバーがページをループし、フラットな集約結果を返します。エージェントはクリーンな単一の結果を見ます。結果のサイズに応じてレイテンシとメモリがスケーリングし、多くのページにヒットするクエリではテールレイテンシの災害が発生します。(c) 次ページツールを分離する。最初のツールがページとnext_cursorを返し、2番目のツールがカーソルによって後続のページをフェッチします。コストは予測可能ですが、ページネーションされたエンドポイントごとにエージェントのツールインベントリが2倍になり、2つのツールの関係がモデルにとって常に明確であるとは限りません。ほとんどのジェネレーター(TrueFoundryのものを含む)はオプション(a)をデフォルトとしています。これを機能させるための規律は、セクション6で述べたツールの説明の品質です。ツールの説明は、ページネーションの契約を明示的に記述し、カーソルパラメータを命名し、「next_cursorを使ってさらに呼び出す」という指示を明記する必要があります。それがなければ、エージェントは確実に最初のページを取得し、タスクが完了したと判断します。
オプション(b)は、エージェントがリスト全体を本当に必要とする小規模で境界のあるデータセット(50行の設定テーブル、固定されたリージョンリストなど)の場合に時折適切ですが、それ以外の場合は通常不適切です。オプション(c)は、次ページのセマンティクスが自明ではない(カーソルの有効期限、スナップショット分離など)ドメインで現れ、明示的な分離がより大きなツールサーフェスに見合う価値がある場合に採用されます。
生成されたMCPサーバーは、基盤となるAPIにHTTPリクエストを行います。これらのリクエストには認証情報が必要です。アーキテクチャ上のルールとして、生成されたサーバーは認証情報を保持しません。認証情報はゲートウェイに存在し、ゲートウェイが呼び出し時にそれらを注入します。
その順序は次のとおりです。
shipment-tracking-svcに対するツール呼び出しの認証情報注入チェーン
1. User (or service identity) authenticates to the MCP gateway
- Personal access token or OAuth, established once
- Gateway stores no per-tool secrets in agent code
2. Gateway resolves which underlying-API token corresponds to this
identity × this MCP server
- Tokens live in the gateway's secret store
- Refreshed automatically before expiry
- Per-tool OAuth scopes enforced from the OpenAPI security spec
3. Gateway forwards the tool call to the generated MCP server with
the resolved token already attached
- Typically as an Authorization: Bearer header on the HTTP client
the server uses for its outbound requests
- The credential never lands in the generated server's code path
4. Generated MCP server constructs the HTTP request from the tool
arguments and dispatches on the auth'd client
- Pure function: (tool name, arguments, http_client) -> responseこれは、このシリーズの以前の投稿で紹介したゲートウェイパターンを、特定の種類のMCPサーバーに適用したものです。このデカップリングにより、生成されたサーバーはステートレスで使い捨て可能になります。これは純粋な変換であり、認証情報、RBAC、監査ログ、レート制限は1つ上のレイヤーに存在します。
自動生成された説明は、構文的には有効ですが、意味的にはひどいものです。OpenAPI仕様にサマリーや説明がない場合、「Get users user id repos」は、シンセサイザーがGET /users/{user_id}/reposに対して生成するものです。実際には、エージェントはそのような説明から不適切なツールを選択する傾向があります。つまり、間違ったツールを選んだり、間違った引数を入力したり、正しいツールであるにもかかわらずスキップしたりします。この影響は、複数のエンドポイントが類似した形状を持ち、モデルが曖昧さを解消するために説明に頼らなければならないツールインベントリで最も顕著です。
変換パイプラインは、次の3つのステップで改善できます。
まず、OpenAPIのサマリーと説明フィールドを優先してください。優れた仕様作成者はこれらを適切に記述しますし、それらを使用するのにコストはかかりません。
次に、サマリーがない場合や役に立たない場合は、LLMによる強化パスを適用します。パス、メソッド、パラメータ、レスポンススキーマ、および任意のドキュメント文字列を安価なモデルに渡し、エージェントにとって分かりやすい説明を求めます。「認証されたユーザーがアクセスでき、指定されたユーザーIDが所有するすべてのリポジトリを、デフォルトで1ページあたり30件にページ分割して取得します。リポジトリのメタデータ(名前、所有者、主要言語、最終更新タイムスタンプなど)を返します。」Claude Haiku 4.5の料金(入力トークン100万件あたり約1ドル、出力100万件あたり5ドル)では、この強化にかかる費用はツールあたり約0.0005ドル程度であり、仕様が変更されたときにのみ実行すれば済みます。
第三に、明確でない引数については、説明に例を含めます。フォーマット文字列、IDの慣例、列挙型値などは、曖昧さをなくすために例が必要となることがよくあります。「user_idは数値のユーザーID(例:'12345')であり、ユーザー名ではありません。」
これを誤ると、エージェントが実行されるたびにコストが発生します。正しく行うためのコストは、生成時に一度支払われ、その後すべてのツール呼び出しに償却されます。
自動生成は、仕様の品質を変換の品質とします。一般的な現実世界の問題(影響の大きい順):
これらは変換バグではなく、変換が忠実に伝播する仕様バグです。実用的な対応策は、OpenAPIからMCPへの生成を仕様品質の強制機能として扱うことです。メンテナンスの不十分な仕様を最初に再生成すると、質の悪いMCPサーバーが生成されますが、これは通常すぐに明らかになり、仕様を修正する十分な動機付けとなります。この変換により、OpenAPIドキュメントを単独で内部使用するだけでは見えにくい仕様の品質が可視化されます。
大規模なAPIを単純に1エンドポイントにつき1ツールとして変換すると、それ自体が問題となるツールリストが生成されます。500エンドポイントのAPIは500ツールのMCPサーバーを生成します。そのツールインベントリをエージェントのコンテキストにロードすると、エージェントが有用な作業を行う前に数万トークンを消費し、利用可能なツールの数が増えるにつれてモデルのツール選択精度が低下すると報告されています。Priyaが変換している出荷追跡サービスは47のエンドポイントを持っており、これは管理可能です。しかし、大規模な公開RESTサーフェス(Stripe、GitHub、AWSなど)を丸ごと生成することはできません。
4つの実用的な戦略(通常は組み合わせて使用):
登録時のオペレーターレベルのフィルタリング。 ほとんどのジェネレーター(TrueFoundryのものも含まれ、openapi-mcp-generator CLIはこのためにOpenAPI x-mcp拡張機能を使用します)は、オペレーターが公開するエンドポイントを選択できるようにします。「仕様内のすべて」というデフォルト設定は、数十のエンドポイントを超えると適切でないことがほとんどです。
タグベースのグループ化。 OpenAPIタグは論理的なグループ化にマッピングされます。ゲートウェイはタグセットごとに1つのMCPサーバーを公開できます(読み取り専用操作には「shipment-tracking-reads」、破壊的な操作には「shipment-tracking-admin」など)。これはツールごとのRBACと自然に連携し、読み取りエージェントは読み取りサーバーのみを参照します。
仮想MCPサーバー(TrueFoundryのパターン、他でも同様の概念があります)。 複数の物理MCPサーバーにまたがる、厳選されたツールのサブセットを集約する論理サーバーです。エージェントは、すべてのバックエンドの集合ではなく、小規模でタスクに特化したツールインベントリ(Stripe、社内請求書サービス、CRMから抽出された12のツールを公開する「billing-agent-tools」など)を参照します。
動的ディスカバリ。 エージェントは、事前にすべてのツールリストをロードしません。その代わりに、ゲートウェイはエージェントが説明によってツールを検索またはフィルタリングするために呼び出すことができるメタツールを公開し、タスクに関連するサブセットのみを返します。これは実装と考察がより複雑になります(エージェントはディスカバリについて賢くなる必要があります)が、あらゆる静的フィルタリング戦略よりもさらにスケーラブルです。
適切な組み合わせはユースケースによって異なります。チームごとの特化型エージェントプラットフォームは、通常、オペレーターフィルタリングと仮想MCPサーバーを使用し、動的ディスカバリは避けます。プラットフォーム全体のツールサーフェスで機能することが期待される汎用エージェントは、静的なキュレーションでは十分に小さくできないため、最終的には動的ディスカバリが必要になります。
OpenAPIが記述するもののうち、2026年半ば時点でMCPに明確な同等物がないものの一部を以下に示します。
これらすべてに共通する実情として、OpenAPIの機能にMCPの同等物がない場合、変換ではエンドポイントを省略すべきであり、サイレントに壊れたツールを生成すべきではありません。ほとんどのプロダクションジェネレーター(TrueFoundryのものを含む)は、変換時にこれらを検出し、影響を受ける操作をスキップするか手動でコーディングするために、オペレーターによる明示的なアクションを要求します。
生成されたMCPサーバーへのすべてのツール呼び出しはゲートウェイを経由します。ゲートウェイは、サーバーに転送する前に、入力スキーマに対して呼び出し引数を検証し、3種類のエラーを早期に捕捉します。型の不一致(整数が必要な場所に文字列)、必須フィールドの欠落(エージェントが必須のパスパラメータを省略)、列挙型の違反(エージェントが列挙型セットにない値を渡した)です。
検証エラーは、基盤となるAPIからの生の400エラーとしてではなく、エージェントが推論できる構造化された形式でエージェントに返されます。
JSON — 不適切なツール呼び出し時にエージェントに返される検証エラー
{
"isError": true,
"content": [{
"type": "text",
"text": "Argument validation failed for tool 'list_user_repos'."
}],
"errorDetails": {
"type": "schema_validation",
"tool": "list_user_repos",
"issues": [
{ "path": "per_page", "code": "type",
"expected": "integer", "got": "string", "value": "thirty" },
{ "path": "user_id", "code": "required" }
]
}
}なぜ生成されたサーバーではなくゲートウェイでなのか?理由は2つあります。第一に、一貫性です。生成されたものであれ手動でコーディングされたものであれ、すべてのMCPサーバーが同じ検証動作をします。第二に、ゲートウェイは生成されたコードを変更することなく、検証ポリシー(厳格か寛容か、カスタムエラーフォーマットなど)を適用できます。生成されたサーバーは可能な限りシンプルな状態を保ちます。検証済みのリクエストが入り、HTTP呼び出しが行われ、レスポンスが返されるだけです。
ジェネレーターを使わなければならないのですか?MCPサーバーを手動でコーディングしてはいけないのですか?
エンドポイントが約10個未満のAPI、または生成されたツールが大幅な後処理(カスタム引数名、マージされたエンドポイント、複雑なビジネスロジックなど)を必要とする場合、手動でのコーディングは妥当な選択肢となり得ます。それを超えると、生成されたサーバーの方が通常はメンテナンスが安価になります。APIにエンドポイントが追加された場合、再生成によって自動的にそれが取り込まれます。手動でコーディングされたサーバーは乖離していきます。
生成されたサーバーはどのようにバージョン管理するのですか?
生成されたサーバーはビルド成果物であり、編集するソースではありません。OpenAPI仕様が変更されるたびに再生成し、理想的にはCIで行います。ツール名はoperationIdが安定している限り安定します。これは仕様作成者がいずれにせよ維持すべき規律です。以前のツールリストをキャッシュしている長時間稼働のエージェントは、次回のMCPディスカバリ呼び出しで更新を認識します。
OpenAPI仕様を持たないAPIについてはどうなるのですか?
難しいケースです。3つの現実的な選択肢がありますが、どれも理想的ではありません。(a) 観測されたトラフィックまたはSDKソースから仕様を生成する。いくつかのツールがこれを実行していますが、精度はまちまちです。(b) 変換をスキップし、MCPサーバーを直接手動でコーディングする。(c) OpenAPI仕様を手動で記述する。オプション(c)は、小規模なAPIでは(b)よりも手間がかかりますが、大規模なAPIでは手間が少なく、副次的な利点として、組織の他の部門が利用できるOpenAPI仕様を作成できます。
これはAIゲートウェイのトレースごとのコスト帰属とどのように連携するのですか?
MCPゲートウェイを介した各ツール呼び出しは、このシリーズの以前の投稿からのチームおよびアプリのメタデータを含むOTelスパンを発行します。ツールレイテンシ、成功率、および基盤となるAPIに付随するあらゆるコストは、呼び出し元エージェントとチームに帰属します。
ジェネレーターの認証スコープにとって適切な粒度は何ですか?
ツールごとです。OpenAPI仕様の操作ごとのセキュリティ要件は、OAuth2スコープ(または他の認証スキーム)のリストに変換され、ゲートウェイはこれらをサーバーごとではなく、ツール粒度で強制します。リポジトリエンドポイントに対する読み取りスコープを持つが書き込みスコープを持たないエージェントは、list_user_reposを呼び出すことはできますが、delete_repoは呼び出せません。
TrueFoundryはどこに位置づけられるのですか?
TrueFoundryの MCPゲートウェイ ゲートウェイのコントロールプレーンで動作するOpenAPI-to-MCPジェネレーターを提供しています。変換は登録時に行われ、生成されたサーバーはゲートウェイがルーティングするマネージドプロキシとして動作します。この記事で説明されている認証インジェクションチェーン、スキーマ検証、RBAC、監査ロギングは、生成されたサーバーがゲートウェイの背後にあることで継承するゲートウェイのプリミティブであり、ゲートウェイに登録されている他のMCPサーバーにも適用されるものと同じです。このジェネレーターは、いくつかの本番環境向けオプション(Speakeasy、Stainless、FastMCP、およびいくつかのオープンソースの同等品も同様の変換を行います)の一つです。選択は通常、結果として得られるサーバーがどこでホストされるか、チームの既存の認証および可観測性とどのように統合されるか、そしてチームがすでに何を実行しているかによって決まります。
47のエンドポイントをそれぞれ1エンジニア週で開発すると、エンジニアリングの四半期の大半を占めます。ジェネレーターを介した47のエンドポイントは、ビルドステップに過ぎません。残りの作業、つまり説明のキュレーション、エンドポイントごとのページネーション戦略の決定、変換できない半ダースの操作の手動コーディングは、現実的ではあるものの範囲が限定されています。機械的な作業にエンジニアリングのリソースを割くべきではありません。
Northwind、Priya、shipment-tracking-svcは例示的なものです。変換アーキテクチャ、マッピングルール、およびエッジケースは、2026年5月現在、本番環境のOpenAPI-to-MCPジェネレーター(TrueFoundry、Speakeasy、Stainless、FastMCP、およびいくつかのオープンソースの同等品)が実際にどのように動作するかを反映しています。OpenAPIおよびMCPの仕様は進化を続けており、新しい機能(OpenAPIウェブフック、MCPエリシテーション、readOnlyHintのようなMCPツールアノテーション)のマッピングは、将来の改訂で変更される可能性があります。
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








最新のニュース、記事、リソースをメールでお届けします
© 2026 無断複写・転載を禁じます。







.png)








.webp)
.webp)


