













.webp)
July 4, 2026
|
5 min read

Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
これらの用語は、問題が発生するまで互換的に使われています。しかし、それぞれが異なる保証を持つ明確なアーキテクチャを指し、それらを混同することの代償は、セキュリティの欠陥、監査の失敗、そして本来不要だったはずの再構築という形で支払われます。
モデルコンテキストプロトコルがAIエージェントをデータソースやツールに接続するための標準的な手段となるにつれて、インフラストラクチャの用語は複雑化しています。ベンダー、ブログ記事、社内設計ドキュメントでは、「プロキシ」「ルーター」「ゲートウェイ」が互換的に使われています。全てが開発者のラップトップ上にあるうちはその区別は曖昧ですが、本番環境のエージェントをデプロイし始めると致命的になります。なぜなら、これら3つの言葉は構造的に異なるものを指しており、その違いは監査人がいずれか一つでは答えられない質問をしたときに初めて明らかになるからです。
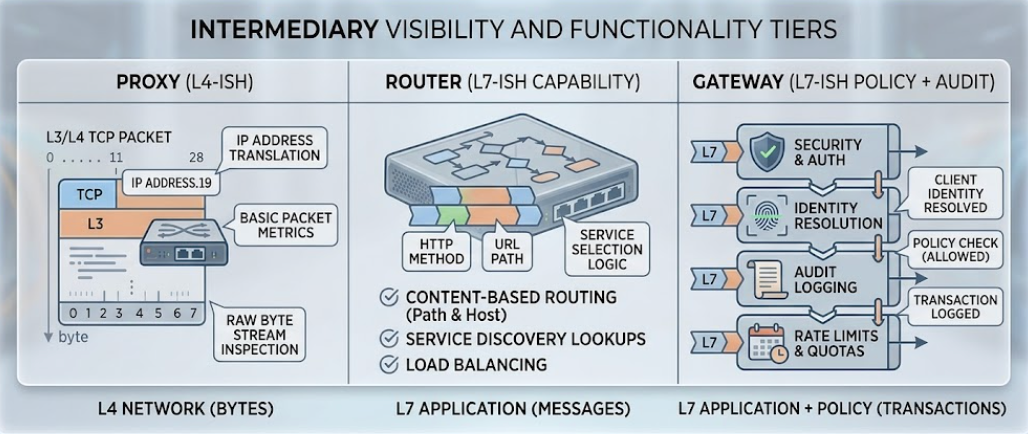
ネットワークの概念を借りると、最も明確なメンタルモデルが得られます。プロキシはL4で動作し、バイトを転送するだけで解釈しません。ルーターはL7の機能ディスパッチで動作し、ツールは知っていますが、それを呼び出す主体は知りません。ゲートウェイはL7のポリシーで動作し、ツール、主体、予算、監査証跡をすべて把握しています。各層は、厳密に言えばより高機能で、運用コストも厳密に高く、各リクエストについてより多くの質問に答えることができます。
プロキシは図の中で最もシンプルな要素です。その役割はプロトコル調停です。MCPはローカル実行のためにstdioを多用しますが、プロキシはstdioベースのMCPサーバーをラップし、HTTP/SSEまたはWebSocket経由で公開することで、リモートクライアントがそれにアクセスできるようにします。それがその仕事の全てです。
プロキシはペイロードを一切解釈しません。JSON-RPCをパースせず、ツール呼び出しを理解せず、「ツール」が何を意味するかも知りません。バイトを転送するだけです。そのため、ミリ秒以下の速度で動作し、運用コストもほとんどかかりません。単一の開発者が、同じマシン上のDockerコンテナ内のMCPサーバーにClaude Desktopを接続する — これがプロキシのユースケースです。ガバナンスも状態も不要です。
プロキシがスケールすると考えるのは間違いです。スケールしません。開発者が複数になったり、ダウンストリームのMCPサーバーが複数になったりした途端、プロキシは負荷を支えきれなくなり、ルーターがその役割を引き継ぎます。プロキシはエンタープライズスタックの構成要素ではなく、ゲートウェイが内部でトランスポート適応のためにラップする可能性のある個人的な利便性ツールです。それをそれ以上でもそれ以下でもなく扱うこと — 過剰に構築したり、過小評価したりすること — は、時代遅れになるアーキテクチャを生み出します。

環境が拡大するにつれて、クライアントにサーバーURLをハードコーディングすることは保守不可能になります。ルーターはディスカバリを解決します。クライアントがgithub-mcp-serverの場所を知る代わりに、ルーターに接続して利用可能なツールを問い合わせます。ルーターはダウンストリームサーバーのレジストリと機能マップを維持します。
LLMがsearch_repositoriesを呼び出すと、ルーターはJSON-RPCペイロードを検査し、ターゲットツールを特定し、適切なバックエンドに呼び出しをディスパッチします。機械的には、ルーティングテーブルを持つアグリゲーターであり、高速でシンプル、そしてクリーンな抽象化です。ほとんどの社内チームは、MCPサーバーが2つ以上になるとすぐにルーターを導入しますが、それは間違いではありません。
ルーターがしないのは、本番環境で最も重要な質問をすることです。つまり、「この呼び出しを行っている主体は、実際にこのツールを呼び出す権限があるのか?」という問いです。ルーターは機能に基づいてルーティングします。ポリシーによるゲートは行いません。モデルは、公開リポジトリでlist_issuesを呼び出すのと同じくらい簡単に、本番環境でdelete_branchを呼び出すことができます。ルーターは両方を忠実にディスパッチし、生成される監査ログはワイヤーによってのみ形成され、誰がワイヤーを保持していたかには左右されません。
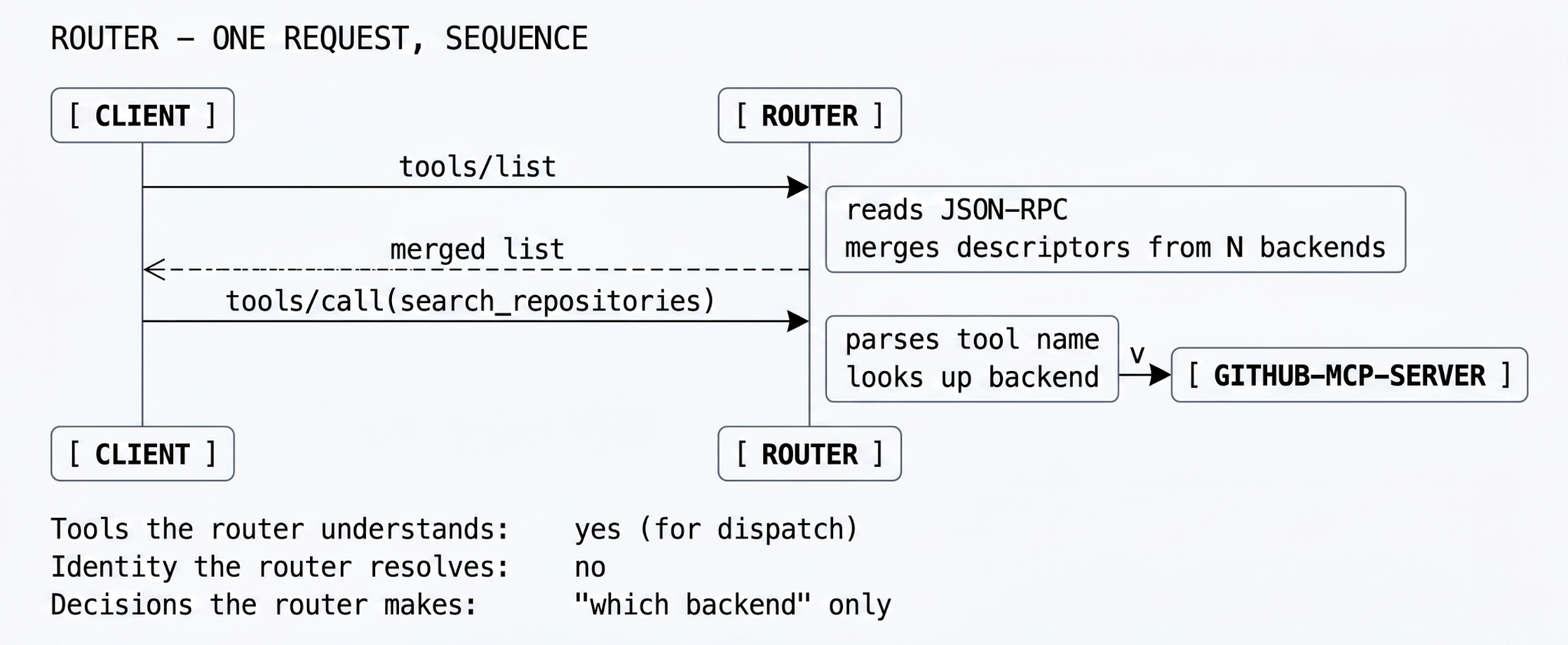
エージェントが内部にあり、ネットワークが信頼され、最悪の事態が元に戻せる場合、ルーターは適切な層です。チームを悩ませる移行はルーターからゲートウェイへの移行であり、それは通常、誰かが先週火曜日に本番環境でdelete_branchを呼び出したのは誰かと尋ねた日に起こります。ルーターは何も答えることができません。なぜなら、それを知らなかったからです。
ゲートウェイはプロキシとルーターを包含し、その上にL7コントロールプレーンを追加します。ここはエンタープライズAIの運用が実際に発生する層であり、設計時に誰がそう呼んだかに関わらず、セキュリティレビューが開始される層でもあります。
ゲートウェイはすべてのパケットを検査します。企業ID(OAuth 2.0、SAML、OIDC)と統合し、エージェントが誰の代理として動作しているかを確立します。ツールレベルのRBACを強制します。MCPポイズニングを捕捉するスキーマサニタイズを実行します。予算割り当てのためにトークン使用量を追跡します。改ざん防止ログを外部SIEMに書き込みます。構造的には、組織のAIポリシーがエンコードされる場所であり、契約終了した請負業者のエージェントが適切なタイミングで動作を停止する唯一の場所でもあります。
設計ドキュメントをざっと読むレビュー担当者向けに、同じ比較を表形式で示します。列を読んでください。各列はリクエストに関する質問に答えています。
表1 — 機能マトリックス。右の列は監査人が尋ねる内容、中央の列はチームが最初に参照する内容、左の列はあなたのラップトップで動作する内容です。
短い意思決定ツリーです。これは、本番環境チームが実際に質問に答える順序で書かれています。
ほとんどのチームが苦労する移行は、ルーターからゲートウェイへの移行です。それは常に同じ瞬間に起こります。誰かがIDと関連付けられたログを必要とする監査の質問をし、ルーターは誰が呼び出しているのかを知らなかったため、答えられないという状況です。その時点での安価な解決策は、ゲートウェイを追加することです。高価な解決策は、セキュリティインシデント後にエージェントプラットフォームを再構築することです。安価な解決策はインシデントが発生するまで目に見えないため、一部のチームは結局、後者の方法をとることになります。
TrueFoundryはフェデレーテッドゲートウェイとして構築されています。コントロールプレーン(ポリシーが作成され、モデルが登録され、可観測性が存在する場所)は、ゲートウェイプレーン(トラフィックが流れる場所)から分離されています。ゲートウェイプレーンは完全にステートレスです。各ゲートウェイポッドはNATSを介してコントロールプレーンから設定更新を購読し、実行するすべてのチェックは同期された状態に対してインメモリで行われます。エージェントとバックエンドの間に単一障害点はありません。コントロールプレーンがダウンした場合でも、ゲートウェイは最後に認識していた設定でサービスを継続します。コントロールプレーンが復旧すると、NATSが調整を行います。最終的なフェイルセーフとして、コントロールプレーンは10分ごとに設定全体を再公開します。これにより、中間更新が失われた場合でも、結果整合性が保証されます。
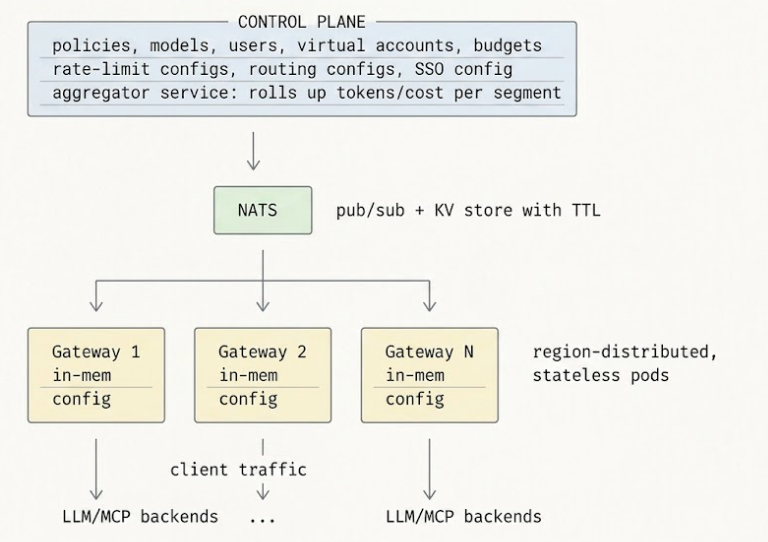
データプレーンは、エッジ向けに最適化されたWeb Fetch API準拠のフレームワークであるHono上に構築されており、すべてのレート制限、認証、ルーティングチェックをプロセスメモリ内で実行します。コントロールプレーンはNATSを介してサブ秒単位で設定を同期します。リクエストパス自体は、キャッシュまたはネットワークベースのガードレールが呼び出されない限り、外部呼び出しを行うことはありません。重要な構造的特性はステートレス性です。ゲートウェイポッドは、進行中のポリシー決定を失うことなくいつでも終了できます。なぜなら、進行中のポリシー決定は存在せず、すべての決定は非同期に到着した設定に対してローカルメモリから行われるからです。
このアーキテクチャをまとめる機能は、仮想MCPサーバーコンポジションです。ゲートウェイは、数十のバックエンドMCPサーバーからのスキーマを単一のAPIサーフェスにマージし、呼び出し元ごとに動的にスコープを設定します。フロントエンド開発者のIAMトークンは、プラットフォームエンジニアとは異なる統合ツールリストを生成し、どちらも相手が使用を許可されていないツールを見ることはありません。モデルの観点からは、MCPサーバーは1つです。プラットフォームチームの観点からは、ポリシーを設定する場所は1つです。監査人の観点からは、すべてのツール呼び出しには、モデルの決定をそれを承認した開発者のIDにリンクするトレースIDがあります。
同じクライアント、同じバックエンド、しかしミドルは大きく異なります。ミドルは、時が経っても陳腐化しにくい部分です。
アーキテクチャとは、ほとんどの場合、どこに境界線を引くかを選択する行為であり、その選択を誤った場合のコストは、設計時ではなく、次のインシデント、次の監査、次の移行時に支払われます。プロキシ/ルーター/ゲートウェイの区別は、単なる用語の問題ではありません。それは、企業IDがエージェントループと出会う接合部にプラットフォームが制御点を持っているか、それとも制御点があるべき場所にルーティングテーブルがあるかという問題です。
ほとんどのチームは、この区別の重要性を困難な方法で学びます。あるチームは事後分析中に、あるチームはコンプライアンスレビュー中に、またあるチームは、契約終了した請負業者のエージェントが本来よりも1週間長く稼働し続けたときに、それを発見します。これら3つのケースすべてにおいて、発見の瞬間は同じです。異なるのは、その発見にかかるコストです。
はい、ほとんどのチームがそうしています。移行パスはスムーズです。ゲートウェイは同じMCPワイヤープロトコルを使用するため、既存のクライアントは引き続き動作します。変更されるのは、クライアントが指すURLと、含める認証ヘッダーのみです。移行は2つのフェーズで計画してください。まず、ゲートウェイを監査モード(ログ記録のみ、強制なし)で立ち上げ、ログが期待通りであることを検証します。その後、リスクの低いMCPサーバーから始め、最終的に本番データベースに適用する形で、サーバーごとに強制を有効にします。
ゲートウェイは、最後に取得した設定でトラフィックを無期限に提供し続けます。ライブアップデートのためにNATSを購読し、バックアップとしてコントロールプレーンのバックエンドサービスからHTTP経由で設定の取得を再試行します。NATSとバックエンドの両方がダウンした場合、既存のゲートウェイポッドは最後に認識された設定で稼働し続けます。障害中に起動しようとする新しいポッドは、レディネスプローブに失敗し、トラフィックを受信しません。複数のゲートウェイレプリカを実行することをお勧めします。コントロールプレーンの障害中にすべてのレプリカが再起動する可能性は、対策を講じるべきリスクですが、それは小さいです。
HonoはWeb Fetch APIをベースに構築されており、エッジランタイム(Cloudflare Workers、Deno、Bun、Node)向けに設計されています。小さく、高速で、どのランタイムでも同じように動作します。これは、ゲートウェイがSaaS、オンプレミスのKubernetes、およびエアギャップされたSquidプロキシ環境間でポータブルである必要があるため重要です。Expressは表面積が広すぎます。Fastifyは悪くありませんが、Node固有の機能に縛られています。重要な特性は、高並行性下での一貫した低オーバーヘッドであり、Honoはこれを確実に提供します。
呼び出し元ごとにスコープを設定します。ゲートウェイは、ツール/リストを提供するたびに、プリンシパルのIAMおよびABAC属性をポリシーバンドルに対して評価し、フィルタリングされたツール記述子の結合を出力します。数秒違いでログインした2人の開発者が、同じゲートウェイエンドポイントから異なるツールリストを受け取ることができます。モデルは複数のバックエンドが存在することを知らず、現在の呼び出し元がアクセスできないツールがあることも知りません。これは、クリーンなマルチテナントデプロイメントを実現する方法でもあります。同じゲートウェイが異なるテナントに異なる世界を提供します。
3つのメカニズムがあります。設定ペイロードは冪等です。コントロールプレーンは変更があるたびに現在の状態全体をNATSに公開するため、同じメッセージを2回受信しても影響はありません。NATSは少なくとも1回の配信を保証するため、ゲートウェイはすべての更新を少なくとも1回は確認します。そして、念には念を入れる対策として、コントロールプレーンは10分ごとに完全な設定を再公開します。中間の更新が失われたとしても、ゲートウェイは最悪でも10分以内に正しい状態に収束します。ずれは設計上制限されています。
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








最新のニュース、記事、リソースをメールでお届けします
© 2026 無断複写・転載を禁じます。







.png)








.webp)
.webp)


