













.webp)
July 4, 2026
|
5 min read

Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
Moonshot AIがKimi K2をオープンソース化した際、AIコミュニティは注目しました。その後、数百ものツール呼び出しを驚くべき一貫性で推論できるモデルであるKimi K2 Thinkingを発表すると、実務家たちは真剣に注目し始めました。そして今、 Kimi K2.6、Moonshotはさらに前進しました。これは、コーディングおよび長期的エージェントベンチマークの最上位に位置し、世界最高のクローズドソース製品に匹敵する最先端のオープンソースモデルです。
この記事では、K2.6が注目に値する理由、ベンチマークの数値が実際のワークロードにとって何を意味するのか、そして6週間のデプロイメントプロジェクトなしでそれをどのように活用できるかについて深く掘り下げます。
Kimi K2.6は、Moonshot AIの次世代マルチモーダルモデルであり、Hugging FaceおよびKimi APIを通じて利用可能です。その前身モデルと同様に、262,144トークンのコンテキストウィンドウを持つMixture-of-Experts (MoE) アーキテクチャに基づいて構築されています。しかし、K2.6は単なる漸進的な改善にとどまらず、前世代が不安定に処理していた3つの点において、意味のある設計変更を表しています。 長期的コーディング、 コーディング主導の設計、および エージェントスウォームの協調。
「長期的」が実際に何を意味するのか、簡単な例を挙げます。あるベンチマークデモでは、K2.6はMac上にQwen3.5-0.8Bモデルを自律的にデプロイし、Zig(ニッチなシステムプログラミング言語)で推論を実装し、そして 4,000回以上のツール呼び出しと12時間以上の連続実行、スループットを毎秒約15トークンから約193トークンに改善しました(LM Studioよりも約20%高速)。これは質問に答えるチャットボットではなく、継続的な関与を通じてシニアパフォーマンスエンジニアとして機能するAIです。
別のデモンストレーションでは、K2.6は13時間のセッションで8年前のオープンソースの金融マッチングエンジンを刷新し、1,000以上の的を絞ったコード変更を行って、 平均スループットを185%向上 と ピークスループットが133%向上 — 初期タスク指定後は、人間の指示なしに。
数字も重要ですが、文脈はさらに重要です。実運用エージェントシステムにとって最も重要なベンチマークにおいて、K2.6がどのような性能を発揮するかをご紹介します。
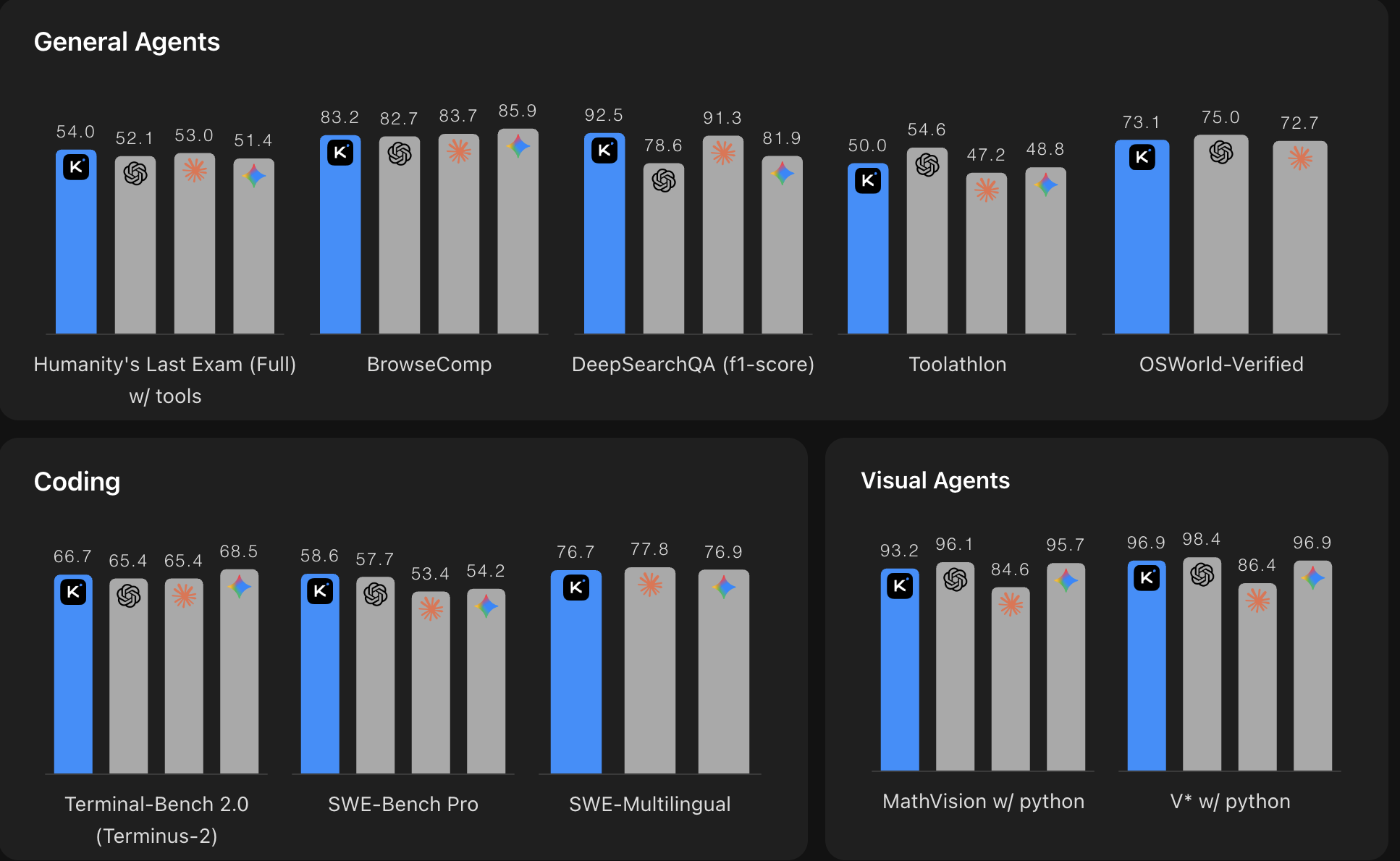
*出典:Moonshot AI Kimi K2.6ベンチマーク比較。数値が高いほど優れています。このグラフは、Kimi K2.6を、汎用エージェント、コーディング、ビジュアルエージェントの各ベンチマークにおいて、主要なクローズドソースモデルと比較したものです。*
K2.6は、最高峰のクローズドソースモデルに匹敵します、Claude Opus 4.6やGPT-5.4を含む、エージェントコーディングや長期的タスクにとって重要なほぼすべての側面において。しかも、オープンウェイトモデルとして、この性能を達成しています。 100万入力/出力トークンあたり$0.74 / $3.50。これは、同等のプロプライエタリな代替品と比較して、ごくわずかなコストです。
Kimi K2.5からの飛躍もまた顕著で、Toolathlonでは約80%の改善、BrowseCompとSWE-Bench Proでは約8パーセントポイントの向上を達成しています。これらはわずかな改善ではありません。
早期アクセスを利用したエンタープライズパートナーも、同様に説得力のある結果を報告しています。AugmentcodeのCTOは、K2.6の「大規模コードベースにおける外科的精度」を指摘し、Vercelは、K2.5と比較してNext.jsベンチマークで50%以上の改善を達成しました。また、CodeBuddyは、コード生成精度が12%向上し、ツール呼び出しの成功率が96.6%に達したと測定しました。
ほとんどのLLMは、単発のコード生成には十分です。K2.6は、複数ファイルのコードリファクタリング、複数言語間の最適化、ビルドパイプラインの改善、そしてモデルがコンパイラの出力を読み取り、仮説を調整し、再試行する必要がある反復的なデバッグループなど、数時間かかるタスクのために構築されています。
このモデルは、Python、Rust、Goといった言語だけでなく、Zigのような珍しい言語にも高い汎化性能を示します。これは、モデルが訓練データからパターンを記憶するだけでなく、プログラミングの概念を深く内面化し、それらを転用できるほどであることを示唆しており、注目に値します。
K2.6は、単一の自然言語プロンプトから、完全な本番レベルのフロントエンドを生成できます。これは静的なモックアップにとどまらず、インタラクティブな要素、スクロールアニメーション、データベース連携の認証機能を備えたものです。Moonshot社内のKimiデザインベンチマークにおいて、K2.6は視覚入力タスク、ランディングページ構築、フルスタックアプリケーション開発、および一般的なクリエイティブプログラミングの全般において、Google AI Studioを上回る性能を発揮します。
AI支援開発ワークフローを構築するチームにとって、これは実質的に、アーキテクチャ、ロジック、UI、デプロイメントの足場といったフルスタックを処理する単一のモデルを意味します。
K2.6は、K2.5で初めて公開されたエージェントスウォームシステムの大幅なアーキテクチャ拡張を導入します。スウォームは現在、 300のサブエージェントが4,000の協調ステップを同時に実行する規模にまでスケールします。これはK2.5の100エージェント、1,500ステップから増加しました。これは単なる規模の改善にとどまらず、実行可能なタスクの種類における質的な変化を意味します。
以前は人間が調整する必要があったタスク(例えば、「半導体企業100社を調査し、5つの定量的投資戦略を構築し、マッキンゼー風のプレゼンテーションを作成する」といったもの)が、K2.6への単一の指示として発行され、完全な成果物として返されるようになりました。
会話は通常ここで止まります。チームはベンチマークの数字を読み、興奮し、その後3週間かけてモデルをいかに確実に提供するかを解明しようとします。
K2.6は大規模なMoEモデルです。その262Kのコンテキストウィンドウは、かなりのメモリ要件を意味します。エージェントワークロードは、その性質上、非常に変動の大きいトラフィックパターンを生成します。数時間は静かだったかと思えば、突然何百もの並行サブエージェントが一斉にリクエストを送信する、といった具合です。稚拙なデプロイ戦略では、その負荷に耐えられません。
これこそが、 TrueFoundry AI Gateway が解決するために設計されたインフラの問題です。
独自のGPUクラスターをプロビジョニングしたり、カスタムロードバランサーを構築したり、推論パラメータを手動で調整したりする代わりに、TrueFoundryはアプリケーションを単一のエンドポイントに向けるだけで、残りの処理をすべて引き受けます。ゲートウェイはプロバイダー間でリクエストをインテリジェントにルーティングし、バーストワークロード(300のサブエージェントが一斉に起動するスウォームのようなもの)の同時実行を管理し、そして、本来なら自分で構築しなければならないオブザーバビリティツール(トレース、レイテンシーヒストグラム、チームごとのトークン使用量など)を提供します。
Kimi K2 Thinkingを用いた社内テストでは、TrueFoundryのゲートウェイは、単一のvCPUで350以上のRPSを約10msのオーバーヘッドで処理しました。単一のユーザー開始タスクが数十または数百のAPIコールに分岐するエージェントワークロードでは、この余裕が重要になります。
実用的な組織的側面もあります。K2.6を運用するエンタープライズチームは通常、データサイエンス、プロダクトエンジニアリング、プラットフォームなど、複数のチームが同じモデルで実験したいと考えています。ゲートウェイは、各チームが独自のAPIキー管理を必要とすることなく、レート制限、コスト配分、アクセスポリシーのための単一のコントロールプレーンを提供します。
マネージドで本番環境に対応した環境でK2.6を稼働させる最も手軽な方法:
1. TrueFoundry AIゲートウェイ(API)経由
OpenAI SDKまたはOpenAI互換のクライアントをすでにご利用の場合、モデル文字列を1つ変更するだけでK2.6に切り替えることができます:
from openai import OpenAI
client = OpenAI(
api_key="<your-truefoundry-api-key>",
base_url="https://llm-gateway.truefoundry.com/api/inference/openai"
)
response = client.chat.completions.create(
model="moonshotai/kimi-k2.6",
messages=[
{"role": "user", "content": "Refactor this codebase for better performance..."}
]
)ゲートウェイがプロバイダーの選択、フォールバックルーティング、レート制限を透過的に処理します。
2. エージェントワークロード向け
K2.6のツール呼び出しインターフェースは、標準のOpenAI関数呼び出しスキーマに準拠しています。長期的なタスクの場合、次のことをお勧めします:
- `max_tokens` を十分に大きく設定する(モデルは大きな生成予算を有効活用できます)
- 長いツールチェーンから増分出力を得るためにストリーミングを有効にする
- TrueFoundryのトレーシングダッシュボードを使用して、どのツール呼び出しに時間がかかっているか、どこでコンテキストが消費されているかを視覚化する
3. エージェントスウォームオーケストレーション向け
マルチエージェントシステムを構築している場合、TrueFoundryのゲートウェイはリクエストレベルのメタデータを提供します。各サブエージェントのリクエストに親タスクIDをタグ付けし、後で完全な実行トレースを再構築できます。これは、スウォームの動作をデバッグし、並列処理がどこで役立っているか(または悪影響を及ぼしているか)を理解する上で非常に貴重です。
エージェント型コーディングツールを構築しているエンジニアリングチーム:K2.6は、SWE-Bench ProにおいてGPT-5.4やClaude Opusと真剣に競合する初のオープンソースモデルです。本番レベルのコードベースタスクを処理できるオープンウェイトモデルを待っていたなら、これこそがそれです。
モデルアクセスを管理するMLプラットフォームチーム:K2.6を他の最先端モデルと並行して評価している企業は、すべてを単一のゲートウェイ経由で実行することでメリットが得られます。TrueFoundryのモデルカタログアプローチにより、実際のワークロードでK2.6をClaudeやGPT-5.4とA/Bテストでき、コストとレイテンシの追跡を並行して行えます。
データレジデンシー要件を持つチーム:K2.6のオープンウェイトは、自社で管理するインフラストラクチャにデプロイできることを意味します。TrueFoundryのデプロイプラットフォームがオーケストレーションを処理するため、推論パスにプロプライエタリなベンダーが介在することなく、企業モデルのガバナンスを享受できます。
クローズドソースモデルの価格支払いにうんざりしているすべての方: K2.6は、100万トークンあたり0.74ドル/3.50ドルという価格設定でありながら、ほとんどのエージェントタスクにおいてプロプライエタリな代替製品と同等かそれ以上のベンチマーク性能を発揮するため、その費用対効果は無視できません。
Kimi K2.6は、真のフロンティアモデルです。「オープンソースとしては優秀」というレベルではなく、実際のエンジニアリング作業で重要となるベンチマークにおいて、世界最高峰のモデルと真に競合する性能を持っています。その長期的な信頼性、エージェントスウォームアーキテクチャ、そして競争力のある価格設定により、今日のプロダクションエージェントシステムで利用可能なオープンウェイトモデルの中で最も魅力的な選択肢となっています。
実際に問われるべきは、K2.6が使う価値があるかどうかではありません。使う価値は十分にあります。問題は、いかに迅速かつ確実に本番環境に導入できるかです。TrueFoundry AI Gatewayはその問いに答えます。これにより、チームはモデルを使った開発に時間を費やし、その周辺インフラの構築に時間を費やす必要がなくなります。
今すぐ試す: [TrueFoundry AI Gateway](https://www.truefoundry.com/ai-gateway)を通じてKimi K2.6にアクセスするか、[デモを予約](https://www.truefoundry.com/book-demo)して、チームのワークフローにどのように適合するかをご確認ください。
*すべてのベンチマーク数値は、Kimi K2.6の公式技術ブログおよびOpenRouterでの検証済み第三者評価から引用しています。インフラストラクチャのパフォーマンス数値は、TrueFoundryの社内テストによるものです。*
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








最新のニュース、記事、リソースをメールでお届けします
© 2026 無断複写・転載を禁じます。







.png)








.webp)
.webp)


