













.webp)
July 4, 2026
|
5 min read

Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
あなたの会社の社内AIハッカソンでの出来事です。ある参加者のコーディングエージェントが、意図しないリトライループに陥ってしまいました。そのエージェントは何時間も、高コストなモデルに対して長文コンテキストのリクエストを送り続けました。
主催者が参加者全員にプロバイダーの生キーを配布したため、支出やリクエスト速度に対するチームレベルの制御がありませんでした。月曜の朝までに、暴走したワークフローが共有LLM予算の大部分を使い果たし、組織をレート制限の苦境に陥れました。
この話は、あり得る話だからこそ響きます。しかし、本当の教訓はもっと広範です。ハッカソンにおける適切な企業パターンは、生のプロバイダー認証情報を配布してチームが適切に振る舞うことを期待することではありません。それは、チームを分離し、メタデータにポリシーを付与し、制御された運用モデル内で実験を維持できる、ガバナンスされたゲートウェイを介してすべてのリクエストをルーティングすることです。
TrueFoundryは、Kubernetesネイティブのワークスペース境界、シークレットの間接化、メタデータ認識型ポリシー制御、エージェントのガードレール、およびゲートウェイネイティブのプレイグラウンドを組み合わせているため、このパターンに非常に適しています。より正確に言えば、あらゆるバーストパターンにおいて「情報漏洩ゼロ」や完璧なハードストップ会計を保証するものではありません。より強力で説得力のある主張は、ハッカソンを管理不能なコストやセキュリティイベントに変えることなく、プラットフォームチームに信頼できる制御プレーンを提供することです。

安全なハッカソンの第一のルールはシンプルです。参加者はプロバイダーの生APIキーを見る必要がありません。キーがノートブック、ローカル環境、またはエージェントの設定ファイルにコピーされると、それはセキュリティ上の問題であると同時に、課金上の問題にもなります。
TrueFoundryのワークスペースモデルは、ワークスペースの分離がKubernetesの名前空間境界にマッピングされるため、ここで役立ちます。実際には、あるワークスペースのワークロードは別のワークスペースのワークロードとは異なる名前空間で実行され、プロバイダー認証情報は、アプリケーションマニフェストやソースファイルに直接貼り付けるのではなく、シークレットグループやシークレットFQNsを介して公開できます。
これがハッカソンチームにとって適切なアーキテクチャです。各チームにワークスペースを与え、ワークロードが必要なシークレットグループにのみアクセスを許可し、実際のプロバイダー認証情報は常にプラットフォームの管理下に置きます。ユーザーエクスペリエンスはシンプルに保たれつつ、影響範囲は小さく、監査可能になります。
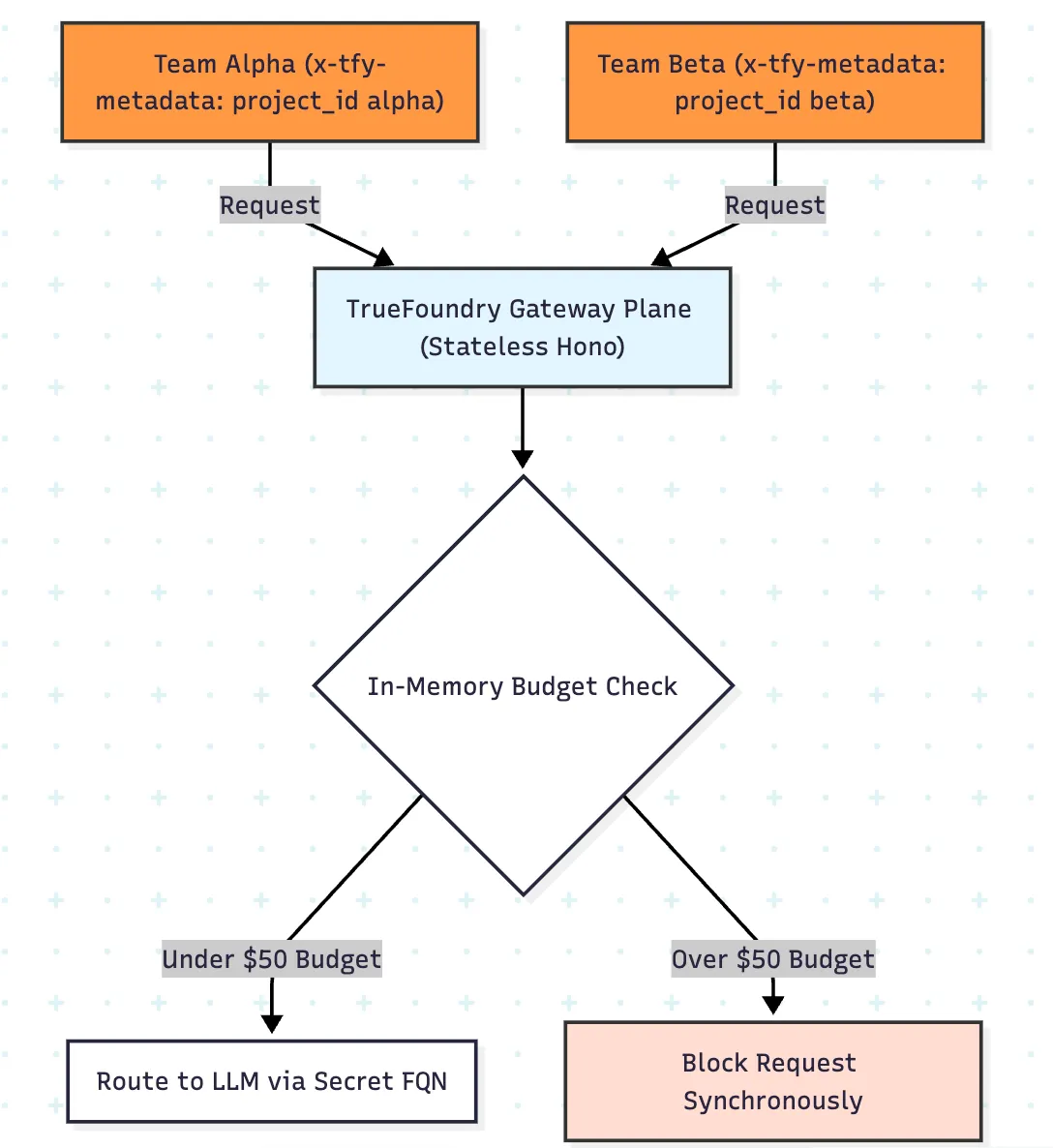
AIハッカソンにおける最も重要な運用上の問題は、事後に支出を確認できるかどうかではありません。暴走したワークロードが高額になる前に、プラットフォームがリクエストパス上でポリシーを評価できるかどうかです。
TrueFoundryのゲートウェイプレーンは、インメモリ状態を使用してホットパス上で認証、ルーティング、ガードレール、レート制限、および予算ポリシーを評価します。これにより、モデル呼び出し前に低遅延での適用が可能になります。これは、信頼できるコストビューがログの下流処理後にしか得られない設計よりも、はるかに優れています。
ハッカソンで特に役立つのはメタデータスコープです。チームごとに手作業でルールを作成する代わりに、x-tfy-metadataにチームIDを付与し、metadata.project_idのようなフィールドを使ってポリシーを動的に適用できます。これにより、1つの予算ルールと1つのレート制限ルールが、チームごとに分離されたカウンターと支出枠に展開されます。
ハッカソンでは、チームがMCPサーバー、ツール呼び出しエージェント、データベースコネクタ、内部APIなどを試します。まさに、従来のLLMのみのセキュリティモデルが破綻し始めるのはここです。
TrueFoundryのガードレールモデルは、LLM入力、LLM出力、MCPツール前、MCPツール後という4つの実行ポイントを公開しているため、ここで特に重要です。これにより、プラットフォームチームは、モデルの前に単一の汎用フィルターに頼るよりも、エージェントをより運用的に管理できるようになります。
重要な違いは、異なるリスクが異なる段階で現れることです。プロンプトインジェクションは入力時に現れる可能性があります。安全でないツール引数は実行前に現れます。機密性の高い記録は、ツールが結果を返した後になって初めて現れることがあります。4つのフックモデルにより、フローの適切なポイントに適切な制御を配置できます。
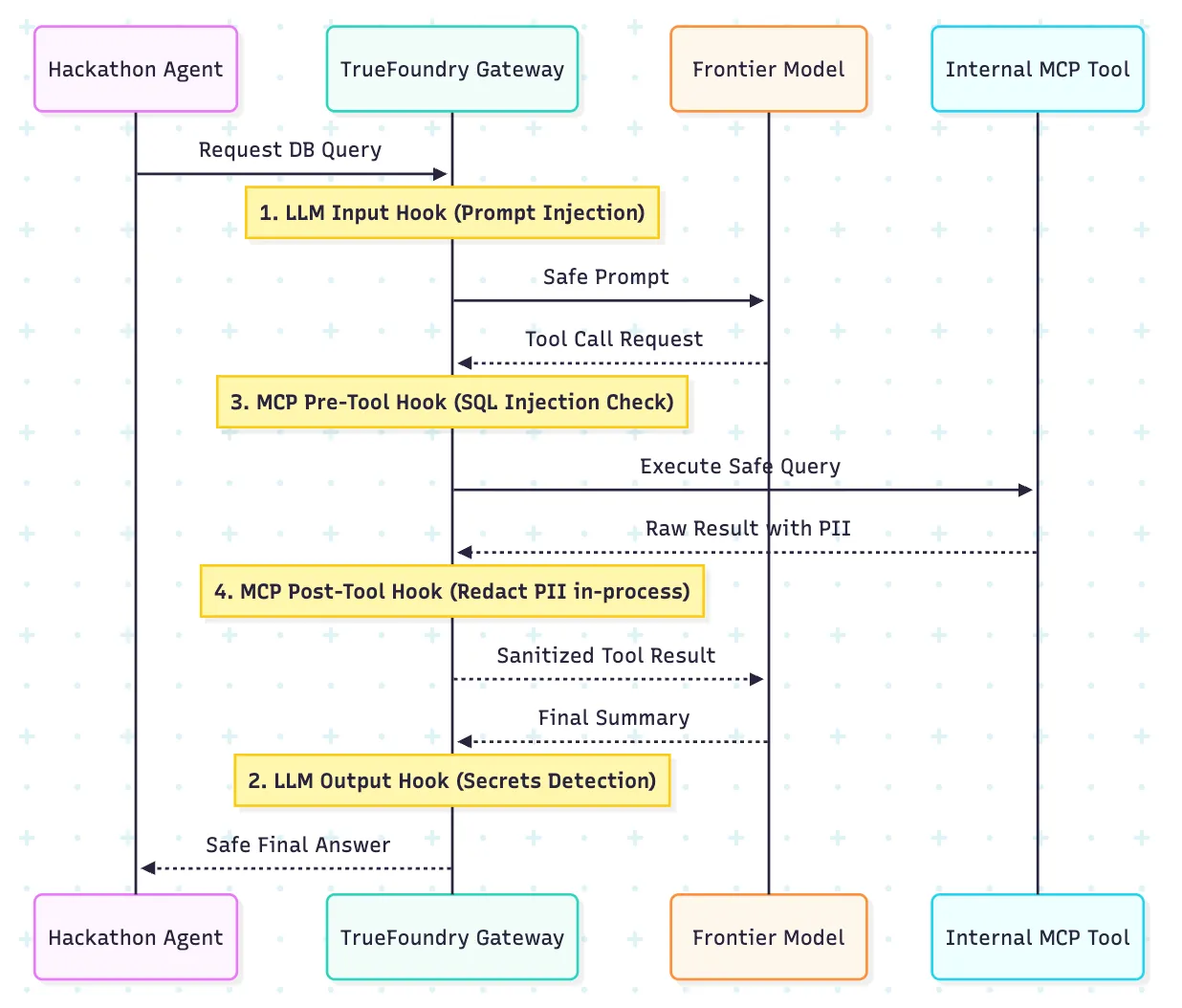
ここでも、インプロセス検出が重要になります。シークレットスキャンや関連チェックが、追加の外部依存関係なしにゲートウェイパス内で実行できる場合、ライブイベント中に制御モデルについて推論しやすくなります。基本的なガードレールはチーム間で共通にし、機密性の高いツールやデータセットを使用するチームにはより厳格なポリシーを重ねて適用します。
安全なハッカソンであっても、迅速であると感じられる必要があります。チームがプロンプトを試すたびにチケットが必要な場合、彼らはプラットフォームを迂回するでしょう。解決策は、制御を減らすことではありません。解決策は、制御されたパスを最も簡単なパスにすることです。
ここで、ゲートウェイネイティブのプレイグラウンドが重要になります。役立つアーキテクチャ上のポイントは、テストトラフィックが本番ポリシーに使用されるのと同じゲートウェイプレーンを通過できることです。これにより、チームはデプロイ後に初めてポリシーの動作を発見するのではなく、ループ内でプロンプト、ルーティング、ガードレールを検証できます。
プラットフォームが応答レベルのデバッグシグナルを公開すると、開発者エクスペリエンスも向上します。x-tfy-resolved-modelやx-tfy-applied-configurationsのようなヘッダー、およびサーバータイミングの内訳は、フォールバック、ガードレール、またはルーティングルールが発動したかどうかを推測するのではなく、チームがテストリクエストで実際に何が起こったかを理解するのに役立ちます。
企業の読者は、投稿がデータレジデンシーについて過度に約束した場合、すぐに反発するでしょう。それは当然です。有益な主張は、すべてのデプロイが魔法のように「エアギャップ」されているということではありません。そうではなく、スプリットプレーン設計により、チームはゲートウェイプレーンを自社のインフラストラクチャで実行できる一方で、推論、ポリシーチェック、モデルアクセスに関するホットパスをより厳密な運用管理下に置くことができるということです。
もう一つの側面は可観測性です。プラットフォームチームがトレース、レイテンシー、ポリシーの挙動を素早く確認できる場合、ハッカソンは管理しやすくなります。しかし、可観測性はデータガバナンスの側面でもあります。プロンプトや応答データが分析のためにエクスポートされる場合、それは適切な保持期間と宛先制御を伴う意図的な選択である必要があります。
デプロイモード、ロギングの挙動、エクスポートパスを明示的に記述することで、レジデンシーに関する説明はより説得力を持つようになります。それは「情報漏洩ゼロ」と言って、読者が追加の質問をしないことを期待するよりも、より信頼を築きます。
はい、明示的なオーナーワークフローを追加するのは良いアイデアです。それは、投稿をアーキテクチャの解説から実行ガイドへと変えます。
1. イベントの1週間前:制御モデルを定義する
チームごと、または競技トラックごとに1つのワークスペースを作成します。許可されるモデル、デフォルトのプロバイダーパス、チームごとの予算、チームごとのレート制限、およびどのチームがMCPツールや機密性の高い内部データを使用できるかを決定します。
2. キックオフ前:安全なパスを事前ロードする
参加者向けに小さなスターターキットを公開します。ゲートウェイエンドポイント、必要なメタデータ形式、SDKスニペットの例、プレイグラウンドの簡単なガイドを含めます。チームは、生のプロバイダーダッシュボードからではなく、管理されたパスから開始する必要があります。
3. 登録時:各チームにproject_idを割り当てる
初日からproject_idを必須のメタデータフィールドとします。それにより、クリーンな費用セグメンテーション、より明確なトレース、より明確なインシデントレビューが可能になり、後での手動マッピングが少なくなります。
4. 構築時間中:イベントをライブシステムのように監視する
チームレベルの費用、レート制限の負荷、異常なトレースパターンを監視します。目標は、後で障害を分析するだけでなく、早期にチームを救済することです。
5. エージェントチーム向け:広範なアクセス前にツールレビューを義務付ける
チームがデータベースアクセス、MCPサーバー、または内部APIを必要とする場合、これらのツールを有効にする前に、より厳格なガードレールプロファイルに移行させてください。エージェントの実験は、最初から信頼されるのではなく、段階的に信頼を得るべきです。
6. デモの前に:最終的なプレイグラウンドでの検証を強制する
各チームに、プレイグラウンドまたは公式のテスト環境を通じて最終的なフローを検証させてください。これにより、デモの前にメタデータの欠落、予期せぬルーティング、ガードレールの予期せぬ動作などを発見できます。
7. イベント後:観察結果をプラットフォームのデフォルト設定に反映させる
トレース、予算超過、ブロックされた呼び出し、サポートに関する質問を確認します。その後、ベストプラクティスを次のハッカソン向けにデフォルトのワークスペーステンプレート、スニペット、ポリシーベースラインに変換します。
元の投稿の核心となる主張は今も有効です。企業AIハッカソンを開催する場合、最も安全なパターンは、プロバイダーの生キーを配布することではありません。それは、チームを分離し、費用を測定し、スループットを制御し、エージェントのワークフローを管理できるゲートウェイを介してリクエストをルーティングすることです。
改訂版が優れている点は、懐疑的な購入者でも納得できる形でこれを述べていることです。TrueFoundryの最も強力なハッカソン事例は、漠然とした完全な安全性の約束ではありません。それは、ワークスペースの分離、シークレットの間接化、メタデータスコープのポリシー、管理されたエージェントフック、リクエストパス制御、そしてチームが出荷時に使用するのと同じポリシーサーフェスを通じてテストを支援するプレイグラウンドの実用的な組み合わせです。
それで十分です。ハッカーたちは引き続き未来を築くことができます。プラットフォーム、セキュリティ、財務の各チームは、その過程で週末を犠牲にする必要はありません。
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








最新のニュース、記事、リソースをメールでお届けします
© 2026 無断複写・転載を禁じます。







.png)








.webp)
.webp)


