













.webp)
July 4, 2026
|
5 min read

Published: July 4, 2026
Blazingly fast way to build, track and deploy your models!
AIコーディングツールは、今や日々の開発に欠かせないものとなっています。開発者は、Claude Code、Cline、Cursor、Gemini CLI、OpenAI Codex CLI、Qwen Code CLI、Roo Code、Gooseといった製品を使い、エディタやターミナルから直接、コードの生成、リファクタリング、デバッグ、大規模なコードベースの説明を行っています。ほとんどの企業における問題は、導入ではなくガバナンスです。各ツールは、1つまたは複数のモデルベンダーと通信できます。各ツールは、多くの場合、キーをローカルに保存します。チームはすぐに、外部モデルへの管理されていない多数のエントリポイントを抱えることになります。これにより、どのモデルが承認されているか、コードとコンテキストがどこに送信されるか、支出がどのように割り当てられるか、インシデントがどのように調査されるかに関して、実際のリスクが生じます。また、ルーティングとフォールバックがツール間で一貫していないため、信頼性の確保も困難になります。
これを手動で解決しようとすると、通常、すべてのIDEとCLIが参照する内部プロキシを構築することになります。そのプロキシには、認証、認可、承認済みモデルの許可リスト、プロバイダールーティング、監査ログ、レート制限、予算管理、および可観測性が必要です。また、これらのツールが期待するAPIと互換性がある必要もあります。多くのツールはOpenAI互換APIを使用しますが、モデルの命名や特別な動作に関して、対処する必要がある癖もあります。
これがなぜ実際のエンジニアリング作業になるのかを示す、小さなダミーの例を挙げます。これは本番環境向けではありません。問題の全体像を示すことのみを目的としています。
from fastapi import FastAPI, Request, HTTPException
import time
import httpx
app = FastAPI()
APPROVED_MODELS = {
"gpt-4o": {"provider": "openai", "target": "gpt-4o"},
"claude-3-5-sonnet": {"provider": "anthropic", "target": "claude-3-5-sonnet"},
}
OPENAI_URL = "https://api.openai.com/v1/chat/completions"
ANTHROPIC_URL = "https://api.anthropic.com/v1/messages"
def verify_token(auth_header: str) -> dict:
# In reality this is JWT validation against Okta or your IdP.
if not auth_header or not auth_header.startswith("Bearer "):
raise HTTPException(status_code=401, detail="missing token")
return {"user": "alice", "team": "platform"}
@app.post("/v1/chat/completions")
async def chat_completions(req: Request):
user_ctx = verify_token(req.headers.get("authorization"))
body = await req.json()
model = body.get("model")
if model not in APPROVED_MODELS:
raise HTTPException(status_code=403, detail="承認されていないモデルです")
route = APPROVED_MODELS[model]
started = time.time()
async with httpx.AsyncClient(timeout=60) as client:
if route["provider"] == "openai":
upstream = await client.post(
OPENAI_URL,
headers={"Authorization": "Bearer " + "UPSTREAM_OPENAI_KEY"},
json={**body, "model": route["target"]},
)
else:
# ここにはリクエストとレスポンスの変換も必要になります。
upstream = await client.post(
ANTHROPIC_URL,
headers={"x-api-key": "UPSTREAM_ANTHROPIC_KEY"},
json={"model": route["target"], "messages": body.get("messages", [])},
)
latency_ms = int((time.time() - started) * 1000)
# 実際には、ここでOpenTelemetryトレースと構造化ログを出力します。
print("llm_request", {"user": user_ctx["user"], "model": model, "latency_ms": latency_ms})
return upstream.json()
この簡略化されたバージョンでも、不足している部分が見られます。ベンダー間の堅牢な変換、ストリーミングサポート、リトライ、フォールバック、安全なパススルーヘッダー、テナントおよびチームスコープ、永続的な監査ログが依然として必要です。さらに、チーム間で拡張可能な設定システムも求められます。
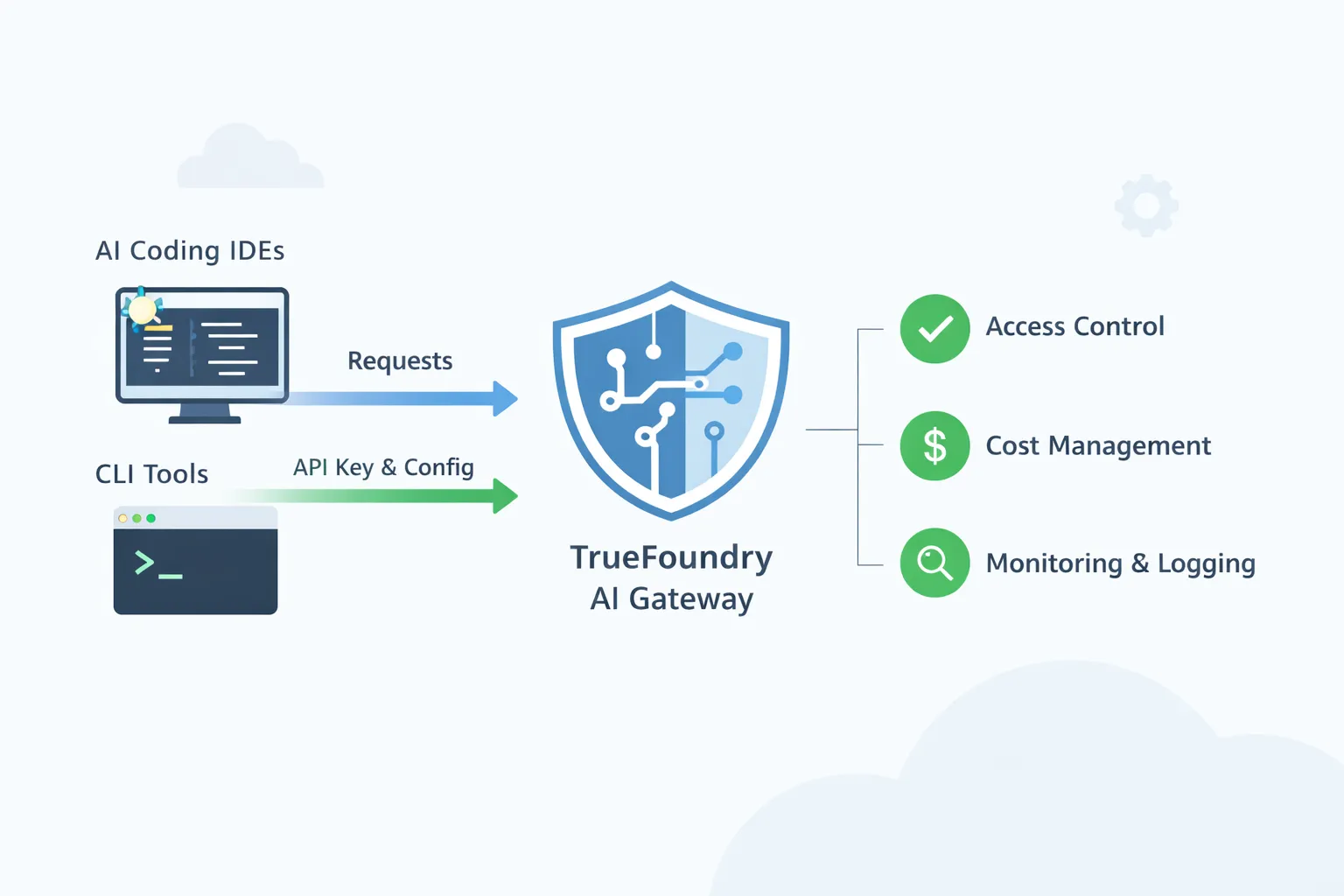
TrueFoundry AI Gatewayは、共有の制御点となるように設計されています。開発者はこれまで通り使い慣れたワークフローをIDEやCLIで利用できますが、トラフィックは単一の管理されたゲートウェイを経由します。このゲートウェイは、プラットフォームチームが承認されたモデルへのアクセスを強制し、ポリシーを適用し、利用状況を完全に可視化するための場所となります。
IDEガイド全体に共通する主要なテーマはシンプルです。TrueFoundry AI GatewayのプレイグラウンドからベースURLとモデル名を取得し、そのベースURLとTrueFoundryトークンを使用するようにIDEまたはCLIを設定します。
ほとんどのAIコーディングIDEやデスクトップツールは、単一のOpenAI互換エンドポイントを指すことができます。TrueFoundry AI Gatewayは、そのエンドポイントを提供します。Gatewayプレイグラウンドで開始し、統合スニペットをコピーします。このスニペットには、使用すべきベースURLとモデル名が含まれています。次に、IDEの設定を開き、カスタムベースURLをサポートするプロバイダーオプションを選択します。多くのツールでは、これをOpenAI互換と呼んでいます。GatewayのベースURLを貼り付け、APIキーとしてTrueFoundryトークンを貼り付けます。このトークンは、開発者向けの個人トークン、または共有・自動化された使用のための仮想アカウントトークンのいずれかです。TrueFoundryは両方のオプションを文書化しており、本番環境での使用には仮想アカウントトークンを推奨しています。 詳細はこちら
一部のIDEは、gpt 4oのような短い標準モデル名を見たときに最もよく機能します。TrueFoundryのモデル名は、しばしば完全修飾されています。推奨される解決策は、IDEが短い名前を使い続けられるように、Gatewayでルーティングまたはロードバランシングルールを定義し、Gatewayがそれを完全修飾されたターゲットモデルにマッピングすることです。CursorとCodexは、標準モデル名に結びついた内部ロジックを持っているため、このパターンを両方とも文書化しています。 Cursorドキュメント
ネットワークの制約も発生する可能性があります。Cursorは、そのリクエストフローがCursorサーバーを介する可能性があると文書化しています。つまり、GatewayのURLはCursorのインフラストラクチャから到達可能である必要があります。実際には、ガイドに記載されているようにCursorが機能するためには、Gatewayエンドポイントがパブリックに到達可能である必要があります。
CLIツールは通常、環境変数またはローカル設定ファイルを介して統合されます。OpenAI互換のCLIの場合、一般的なパターンは、OPENAI_BASE_URLをTrueFoundry Gatewayエンドポイントに設定し、OPENAI_API_KEYをTrueFoundryトークンに設定することです。TrueFoundryは、これをGatewayのサポートされている認証アプローチとして文書化しています。 詳細はこちら:認証
一部のCLIはプロバイダー固有の変数を使用します。Gemini CLIはGeminiのベースURLとAPIキーを使用します。TrueFoundryのガイドでは、GOOGLE_GEMINI_BASE_URLをTrueFoundry GeminiプロキシURLに設定し、GEMINI_API_KEYをTrueFoundryトークンに設定することで、すべてのリクエストがGatewayを経由するようにする方法が示されています。 詳細はこちら:Gemini-cli
他のCLIは設定用のJSONファイルに依存しています。Claude Codeは、ベースURLと認証ヘッダーの環境変数を設定するsettings.jsonファイルを通じて構成されます。TrueFoundryのガイドでは、ANTHROPIC_BASE_URLがGatewayを指し、カスタムヘッダーでBearerトークンを使用することで、Claude CodeのトラフィックがGatewayを通じて管理されることが示されています。詳細はこちら: Claude Code
一部のツールでは、前述の標準的な名前マッピングも必要です。Codex CLIガイドでは、Codexが標準的なモデル名を想定しており、完全修飾名では誤動作する可能性があると説明されています。Gatewayルーティングを使用することで、CLIでgpt 5を呼び出し、Gatewayが舞台裏で正しい完全修飾モデルにルーティングすることを推奨しています。 詳細はこちら:Codex
AIコーディングツールが企業全体に普及するにつれて、モデルの承認とアクセス制御は最も基本的なガバナンス要件となります。開発者は数分でCursorやClineをインストールし、任意のモデルプロバイダーに接続できます。Gatewayがない場合、企業はコードコンテキストやプロンプトが個人キーを使用してネットワーク外に流出する、管理されていない多くの経路を抱えることになります。TrueFoundry AI Gatewayを使用すると、コーディングでの使用が許可されたモデルの承認済みカタログを作成し、それらのモデルをチームやユーザーグループにマッピングできます。開発者は好みのIDEを使い続けることができますが、すべてのリクエストはGatewayを経由するため、承認されていないモデルへのリクエストはブロックされます。これにより、リスクレベルに応じてアクセスを分離することも可能になります。ジュニアエンジニアは迅速な編集のために安価なモデルにアクセスできる一方、スタッフエンジニアや本番環境のインシデント対応チームは、困難なデバッグのために強力なモデルにアクセスできます。重要なのは、すべての開発者がポリシー文書に従うことに依存するのではなく、承認が中央で強制されることです。
AIコーディングツールは、誰も気づかないうちに大量のトークンを生成する可能性があるため、コストの所有権が重要になります。コードベースを反復処理するエージェントを使用する一人の開発者が、短期間に数百または数千の呼び出しを生成する可能性があります。Gatewayがない場合、費用は個人キーやベンダーアカウントに分散されるため、経理部門は請求書を見ることはできますが、どのチームやアプリケーションがそれを引き起こしたのかを把握できません。Gatewayを使用すると、IDベースのトークンを発行し、各IDEまたはCLIセッションにユーザーまたはサービスIDを使用して認証を要求できます。これにより、使用状況を個人、チーム、または内部ツールに帰属させることができます。帰属が確立されれば、制御が実用的になります。チームの月間予算を設定したり、意図しない無限ループを防ぐためのレート制限を設定したりできます。ツールがリクエストをスパムし始めた場合、Gatewayは予算を静かに使い果たすのを許すのではなく、それをスロットリングできます。
インシデント対応と監査は、プラットフォームチームが日々違いを実感する部分です。開発者がアシスタントが遅い、または失敗していると言うとき、トラフィックがラップトップからベンダーに直接送信されている場合、デバッグは困難です。問題がベンダー、ネットワーク、誤って設定されたモデル名、またはツール固有の設定のいずれであるかを知ることはできないかもしれません。リクエストがGatewayを経由する場合、プラットフォームチームはGatewayのメトリクスとログを調べて、どのモデルが呼び出されたか、レイテンシはどのようであったか、どのエラーが発生したか、そして障害が特定のプロバイダーまたは特定のリージョンに限定されているかどうかを確認できます。これは監査要件の基盤でもあります。セキュリティおよびコンプライアンスチームは、コードコンテキストがどこに送信され、誰がアクセスしたかを頻繁に尋ねます。Gatewayは、どの宛先が使用され、誰がそれらを呼び出したかの記録を保持できます。また、リクエストが外部プロバイダーに到達する前に機密文字列をマスクしたり、特定のチームが外部エンドポイントにプロンプトを送信することを完全に制限したりするなど、リスクを軽減するポリシーをサポートすることもできます。
モデルプロバイダーは定期的に速度低下やタイムアウトを経験するため、プロバイダーの問題発生時の信頼性は重要です。AIコーディングツールは対話型であるため、特に影響を受けやすいです。数回のタイムアウトでツールが壊れているように感じられ、開発者は動作するものに切り替えてしまうでしょう。多くのIDEは特定のモデル名を想定しています。Cursorや同様のツールは、モデル名が標準的なOpenAIスタイルの名前のように見える場合に最もよく機能します。プロバイダーを変更する場合、通常はすべての開発者設定を変更する必要があります。Gatewayルーティングを使用すると、IDE設定で同じモデル名を維持し、舞台裏でそれが何にマッピングされるかを変更できます。あるプロバイダーがタイムアウトしている場合、別のプロバイダー、別のアカウント、または別のリージョンにルーティングできます。開発者は同じIDE設定を使い続け、ツールが引き続き機能するのを単に確認するだけです。これは、新しいモデルを展開したい場合にも役立ちます。ユーザーエクスペリエンスを安定させながら、新しいモデルにトラフィックを徐々に移行させることができ、品質やレイテンシが許容できない場合は迅速にロールバックできます。
AIコーディングIDEは開発者の作業を高速化します。企業は、ソース管理システムやCIシステムにすでに適用しているのと同じレベルのガバナンスを必要としています。現実的な方法は、開発者にツール変更を強制することなく、制御を一元化することです。TrueFoundry AI Gatewayは、その制御点に位置するように構築されています。Claude Code、Cline、Cursor、Gemini CLI、OpenAI Codex CLI、Qwen Code CLI、Roo Code、Gooseのすべての統合ガイドは、同じ原則に従っています。開発者のワークフローを維持します。ポリシー、可視性、および制御をGatewayで一元化します。
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








最新のニュース、記事、リソースをメールでお届けします
© 2026 無断複写・転載を禁じます。







.png)








.webp)
.webp)


