













.webp)
July 4, 2026
|
5 min read

Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
TrueFoundry AI Gatewayは、LLMインフラストラクチャのための統合実行レイヤーです。認証、プロバイダー間のルーティング、レート制限、ポリシー適用、MCPツール呼び出し管理、そしてこの統合にとって特に重要なOpenTelemetry準拠のトレーシングを処理します。ゲートウェイを介したすべてのリクエストは、標準の gen_ai.属性(モデル名、トークン数、終了理由)とともに、 tfy.input、 tfy.output、および tfy.span_typeのようなTrueFoundry固有の属性を運ぶスパンを生成します。これらのスパンは、リクエスト完了後にNATSメッセージキューに非同期で公開されるため、エクスポートパスが処理中のリクエストを停止させることはありません。専用のOTELエクスポーターサービスがそのキューから読み取り、設定された任意のOTLPエンドポイントにHTTPまたはgRPC経由でスパンを転送します。
Pydantic Logfireは、Pydantic(OpenAIのSDK、AnthropicのSDK、および今日のほとんどのAIフレームワークに組み込まれている検証レイヤー)の開発チームによって構築された可観測性プラットフォームです。Logfireは標準のOTLPデータを取り込み、その上にAIネイティブなレンダリングを適用します。つまり、 gen_ai.属性をスパン上で検出すると、 LLMパネル が自動的にアクティブになり、完全な会話履歴、ツール呼び出し引数、リクエストごとのトークン数、計算されたコストを、送信側のSDK統合なしで表示します。LogfireのクエリはPostgreSQL互換のSQLで記述されているため、本番環境のトレースは人間だけでなくコーディングエージェントもアクセスできます。米国およびEUの地域エンドポイントを持つマネージドクラウドサービスとして利用可能です。
この統合は単一のポイントで接続されます。それはTrueFoundryの OTEL ConfigOTLP HTTPエンドポイントと認証ヘッダーを受け入れます。AI Gateway → Controls → Settings → OTEL Config に移動し、編集ボタンをクリックして設定パネルを開きます。

TrueFoundryのOTEL設定セクション — トレースエンドポイントはLogfireのEU取り込みURLを指しており、認証ヘッダーが設定されています。
エンドポイントをLogfireの地域別取り込みURLに設定し、プロトエンコーディングでHTTPを選択し、Logfireの書き込みトークンを 認証 ヘッダー値として追加します。同じ書き込みトークンで、トレースとメトリクスの両方のエクスポーターをカバーします。
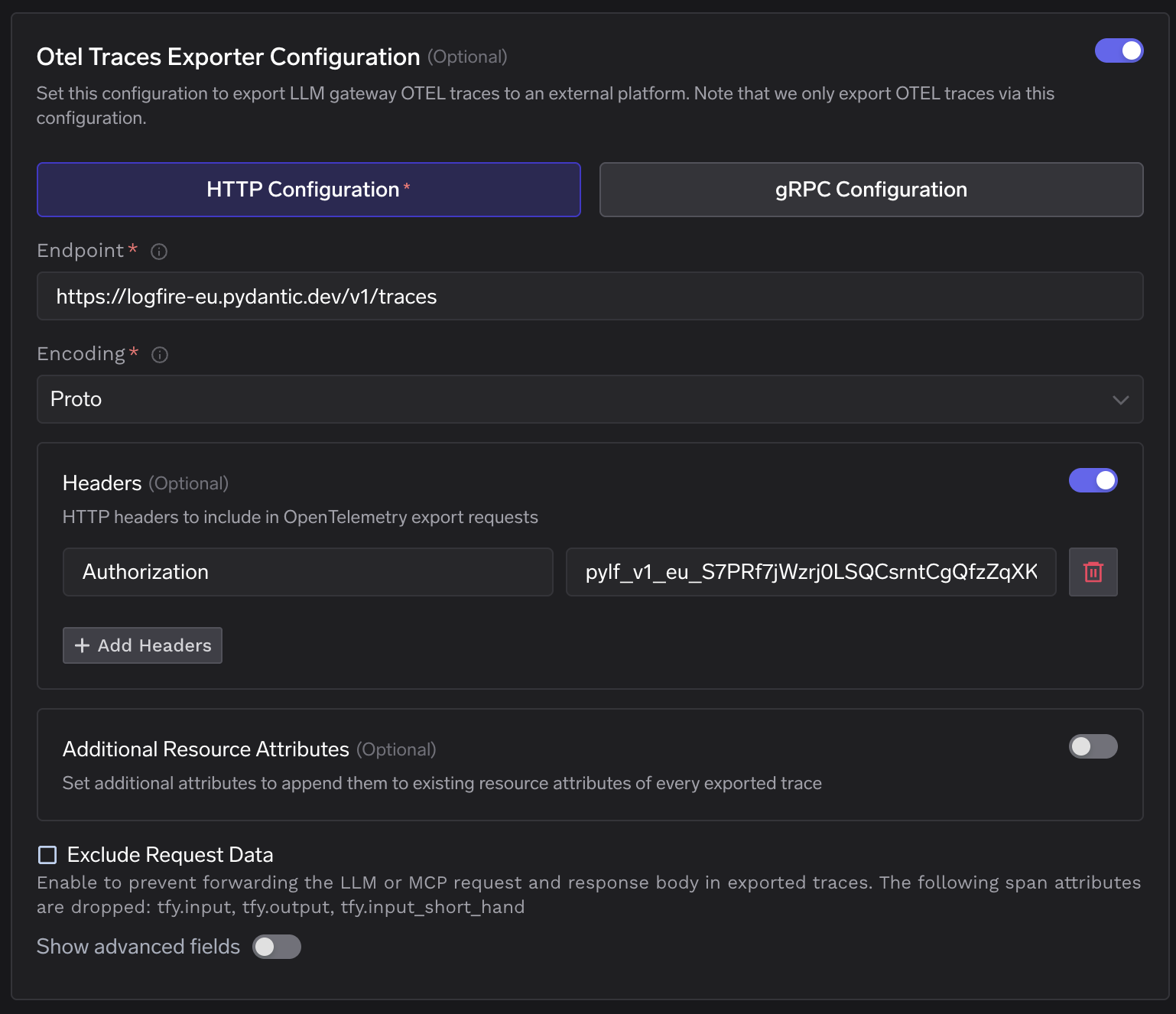
トレースエクスポーターフォームが入力済み — エンドポイントは https://logfire-eu.pydantic.dev/v1/traces、エンコーディングはProto、認証ヘッダーにはLogfireの書き込みトークンが設定されています。
ゲートウェイ経由でリクエストを送信するアプリケーション側でコード変更は不要です。トレーシングパイプラインは、インフラ層で完全に動作します。どのチームからのリクエストでも、どのモデルを使用しても、どのプロバイダー経由でも、ゲートウェイで何が起こったかの完全なコンテキストを持つスパンが生成され、Logfireに流れます。
ゲートウェイにリクエストが到着すると、以下のシーケンスで処理されます。
設定が完了すると、tfy-llm-gatewayからのスパンがLogfireのライブビューにリアルタイムで表示され始めます。その tfy.span_type 属性は ChatCompletion、 AgentResponse、および MCPGateway スパンを区別し、チームが操作タイプでフィルタリングしたり、SQLでそれらを横断的にクエリしたりできるようにします。

Logfireのライブビューには、tfy-llm-gatewayのスパンが表示され、AgentResponse、ChatCompletion、MCPGatewayの各操作が完全なタイミング、ステータス、ネストされた子スパンとともに表示されます。
個々のトレースだけでなく、メトリクスエクスポーターはプロバイダー、モデル、チーム全体の集計された使用状況データを表示します。Logfireの使用状況概要は、これらをスコープとスパン名でグループ化し、プラットフォームの責任者にトラフィックの行き先と量に関する全体像を提供します。
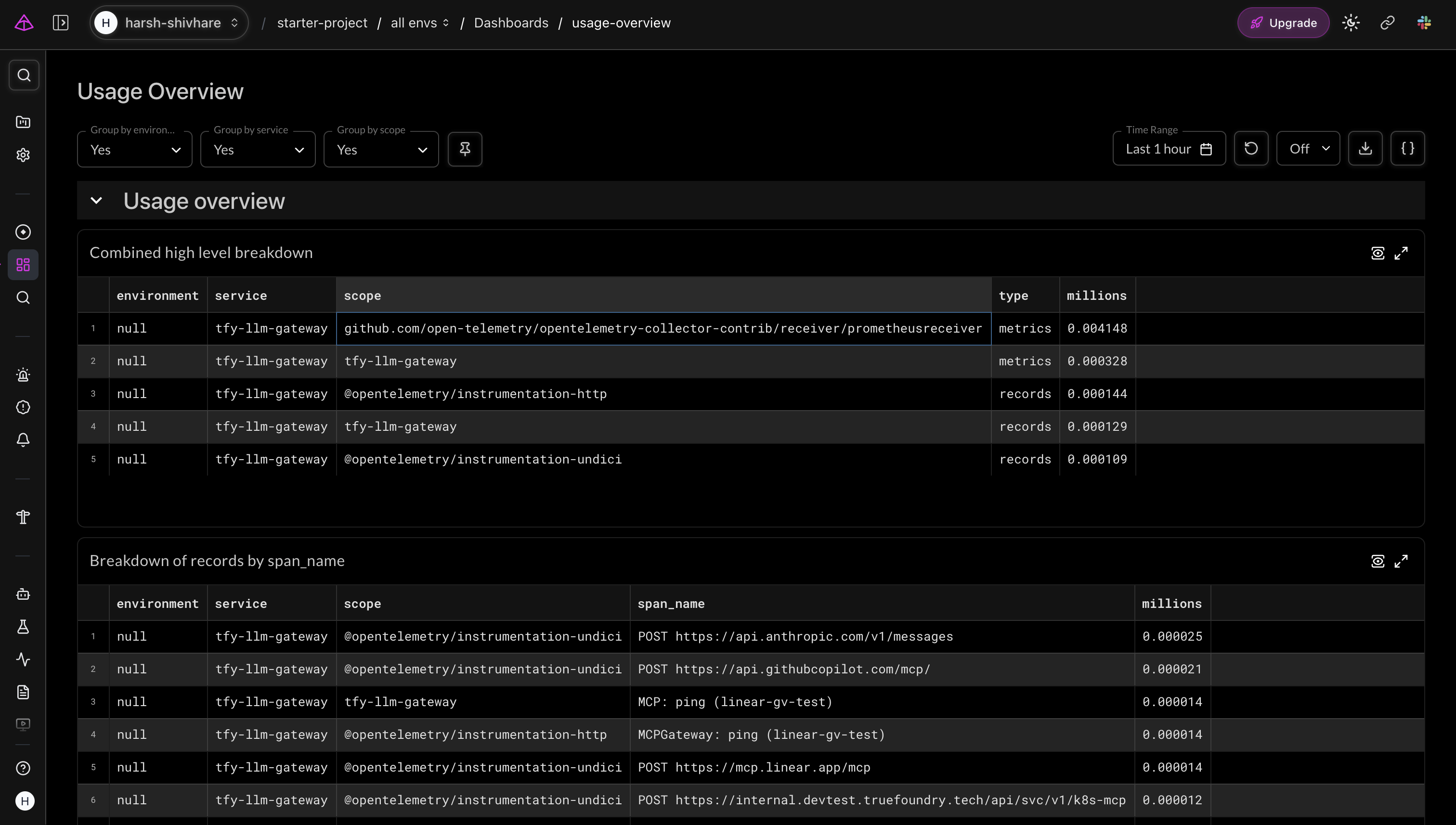
Logfireの使用状況概要 — tfy-llm-gatewayからのメトリクスをインストゥルメンテーションスコープ別に分類し、プロバイダー全体のChatCompletionおよびMCPGatewayトラフィックを表示。
まずLogfireで書き込みトークンを作成します。プロジェクトに移動し、 プロジェクト設定 → 書き込みトークンをクリックし、「新しい書き込みトークン」をクリックします。トークンはすぐにコピーしてください。Logfireは完全な値を再度表示しません。

Logfireの書き込みトークンページ — TrueFoundry専用のトークンを作成し、ダイアログを閉じる前に安全に保管してください。
次に、 AI Gateway → コントロール → 設定 → OTEL設定 TrueFoundryで、Logfireの地域エンドポイントと書き込みトークンを使用して、トレースとメトリクスの両方のエクスポーターを設定します。完全なエンドポイントリファレンスと設定ガイドはTrueFoundryのドキュメントで利用できます。Logfireは永続的な無料枠を提供しており、データレジデンシー要件を持つチーム向けにはセルフホスト型エンタープライズオプションも用意しています。
この統合から得られる重要な洞察は、アーキテクチャに関するものです。TrueFoundryとLogfireは直接連携する必要がありませんでした。ゲートウェイはgen_ai.*属性を持つ標準のOpenTelemetryスパンを出力し、Logfireはその同じ標準を読み取り、LLM対応ビューを自動的に有効にします。OpenTelemetryは両者間の契約であり、ゲートウェイは実行を管理しテレメトリを生成し、Logfireは動作を記録・可視化し、この標準が、どちらのシステムも他方の内部に依存することなく両者を接続します。
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








最新のニュース、記事、リソースをメールでお届けします
© 2026 無断複写・転載を禁じます。







.png)








.webp)
.webp)


