













.webp)
July 4, 2026
|
5 min read

Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
TrueFoundry AI Gatewayは、処理するすべてのリクエストに対してOpenTelemetryトレースを発行し、NATS経由で非同期にOTELエクスポーターに公開します。このエクスポーターは、HTTPまたはgRPC経由でOTLP互換の任意のバックエンドにトレースを転送します。Honeycombはそのようなバックエンドの一つです。OTLPデータは以下で受け入れられます。 https://api.honeycomb.io/v1/traces HTTP経由でprotobufエンコーディングを使用し、認証には x-honeycomb-team ヘッダーを使用します。トレースが到着すると、Honeycombはすべてのスパン属性をインデックス化し、事前宣言されたスキーマを必要とせずにアドホッククエリで利用できるようにします。
この記事では、TrueFoundryゲートウェイがどのようにトレースを生成およびエクスポートするか、トレースが到着した後にHoneycombがそれらをどう処理するか、そして両システムがプロトコルレベルでどのように接続するかについて説明します。
TrueFoundry AI GatewayはHonoフレームワーク上に構築されており、1 vCPUと1 GB RAMでステートレスなゲートウェイポッドとして動作し、毎秒250以上のリクエストを約3ミリ秒の追加レイテンシで処理します。このゲートウェイはOpenTelemetryに準拠しており、すべてのインバウンドリクエストのライフサイクル全体にわたってスパンを生成します。
スパンツリーは5つのステージをカバーします。最初のステージはインバウンドHTTPハンドラーで、クライアントメタデータとともにリクエストの到着を記録します。2番目のステージは認証で、ゲートウェイはIDプロバイダーからダウンロードされたキャッシュ済みの公開鍵に対してJWTトークンを検証します。このステップでは外部認証呼び出しは行われません。3番目のステージはモデル解決で、ゲートウェイはNATS経由でコントロールプレーンから同期されたインメモリルーティングテーブルを使用して、論理モデル識別子を物理プロバイダーエンドポイントに解決します。4番目のステージはアウトバウンドプロバイダー呼び出しで、ゲートウェイはアダプターを介してリクエストをOpenAI互換形式からターゲットプロバイダー形式に変換して転送します。5番目のステージはストリーミング応答処理で、ゲートウェイは応答がストリーミングで返される際にトークン数と終了理由をキャプチャします。
スパン属性は gen_ai.* セマンティック規約にTrueFoundry固有の属性とともに従います。 gen_ai.request.model 属性はモデル識別子を記録します。 gen_ai.usage.prompt_tokens および gen_ai.usage.completion_tokens 属性はトークン消費量を記録します。 tfy.input と tfy.output 属性には、プロンプトとレスポンスの全文が含まれます。 tfy.input_short_hand 属性には、表示用に短縮されたバージョンが含まれます。 tfy.span_type 属性は、スパンのカテゴリ(例: ChatCompletion または MCPGatewayなどです。
リクエストが完了すると、ゲートウェイはこれらのスパンをNATSに非同期で公開します。バックグラウンドのOTELエクスポーターは、この非同期パスから読み取り、スパンを設定済みの外部エンドポイントに転送します。この設計により、トレースのエクスポートがリクエストパスにレイテンシーを追加することはありません。外部OTELエンドポイントに到達できない場合でも、ゲートウェイはリクエストを失敗させません。エクスポートパスは追加的なものであり、TrueFoundry独自の内部トレースストレージを置き換えるものではありません。

プロンプトとレスポンスのコンテンツが環境外に出るべきではないワークロードの場合、ゲートウェイは リクエストデータを除外 トグルを提供します。これを有効にすると、 tfy.input と tfy.output と tfy.input_short_hand エクスポート前のスパンから。トークン数、レイテンシー、モデルのメタデータなど、その他のすべてのスパン属性は引き続き流れます。
MCPゲートウェイも同じトレーシングモデルに従います。各ツール呼び出しは、呼び出し元のユーザー、MCPサーバー、ツール名、完全なリクエストとレスポンスのペイロード、およびレイテンシーを記録するスパンを生成します。これらのスパンは、LLM呼び出しスパンと同じトレースツリーに表示され、エージェントワークフロー全体でエンドツーエンドのトレース可視性を実現します。
HoneycombはOTLPデータを取り込み、各スパンを任意の列を持つ行として保存します。固定されたスキーマはありません。TrueFoundryが発行するすべての属性は、それが gen_ai.usage.prompt_tokens または tfy.span_type または http.response.status_code それを運ぶ最初のスパンが到着した瞬間に、Honeycombでクエリ可能な列になります。
Honeycombのコアクエリプリミティブは BubbleUp 分析です。遅い、または失敗した一連のトレースが与えられた場合、BubbleUpは、ベースラインと比較して、そのセット内で統計的に過剰に表現されている属性値を計算します。LLMゲートウェイのトラフィックの場合、これは、手動でクエリを作成することなく、レイテンシーの急増が特定のモデル、特定のユーザー、または特定のMCPサーバーと相関しているかどうかを特定することを意味します。
Honeycombはデータを データセット。TrueFoundryゲートウェイは service.name を tfy-llm-gateway と設定し、Honeycombはデフォルトでその名前のデータセットにスパンをルーティングします。異なるデータセットにスパンをルーティングするには、 x-honeycomb-dataset ヘッダーがエクスポーター設定に とともに追加されます x-honeycomb-team。複数のデータセットを使用して、本番環境とステージング環境のトラフィックを分離したり、LLMゲートウェイのトレースとMCPゲートウェイのトレースを分離したりできます。
トレース タブにはスパンウォーターフォールビューが表示されます。各行はスパンです。階層は親子関係を示しており、ルート MCPGateway: resources/list スパンと、その中にネストされた MCP: resources/templates/list スパン、およびアウトバウンドの POST https://... スパンは、ゲートウェイが実行した内容に直接マッピングされます。期間バーにより、レイテンシーの分布が一目でわかります。その エラーのあるスパン カウンターは、障害を伴うトレースを分離します。
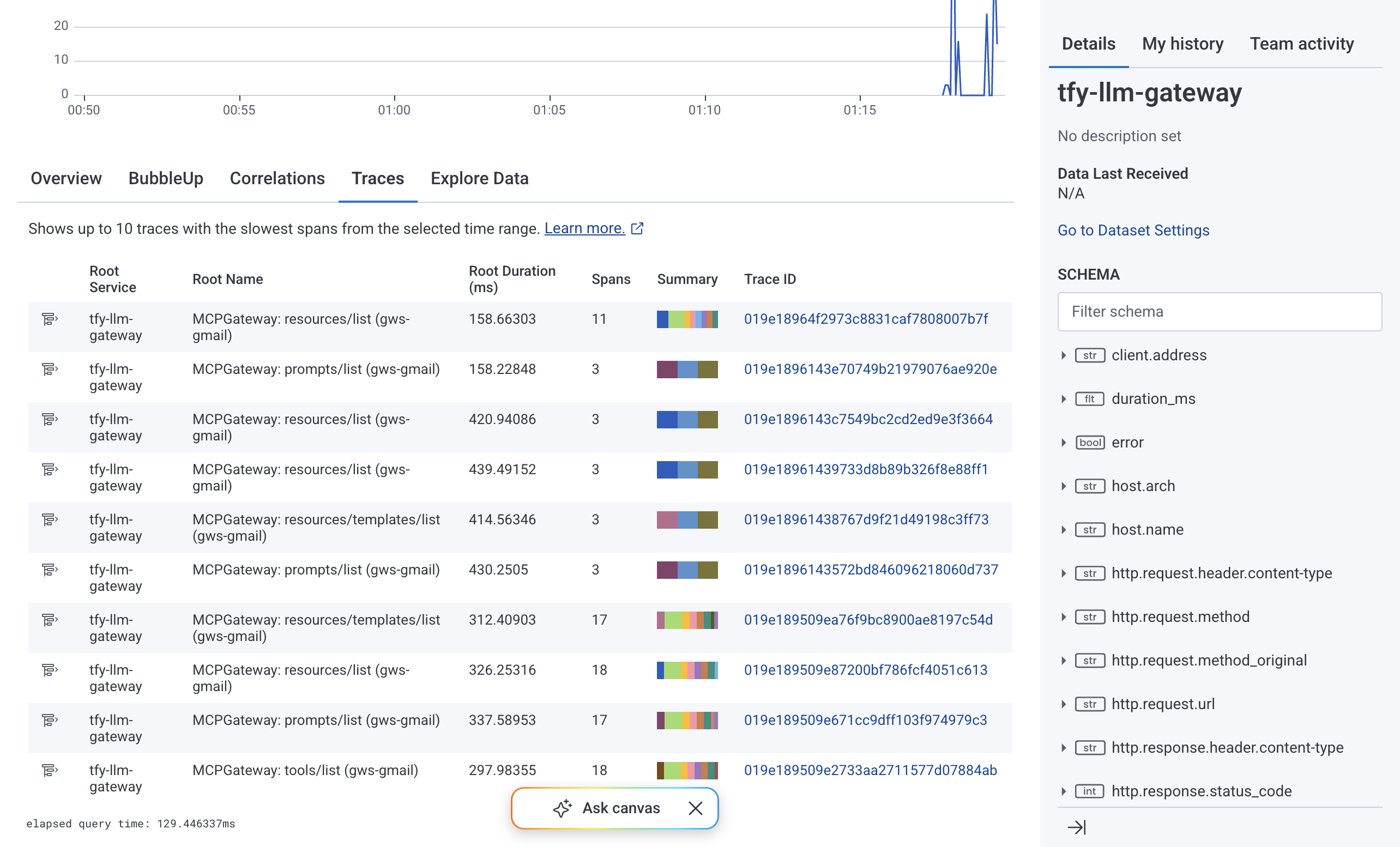
概要 タブは、選択された時間枠における合計スパン、合計エラー、合計例外を集計し、トレース量、スパン量、エラー量を時系列チャートとして表示します。このビューは、ダッシュボードをゼロから構築することなく、ゲートウェイの健全性を一目で反映します。

任意のトレースIDをクリックすると、そのトレースの完全なスパンウォーターフォールが展開されます。各スパンは、そのサービス名、期間、およびエラーフラグを表示します。ネストされた子スパンは、ゲートウェイの内部呼び出し階層を反映しており、リクエストごとにどのステージがレイテンシーを引き起こしたかを特定できます。

TrueFoundryゲートウェイは、OTLP HTTP経由でprotobufエンコーディングのトレースをエクスポートします。Honeycombは、この形式を2つの地域エンドポイントで受け入れます。
認証には単一のヘッダーを使用します。その x-honeycomb-team ヘッダーにはHoneycombのインジェストAPIキーが含まれます。キーには イベント送信 権限スコープが必要です。OAuthフローやベアラートークンの交換はありません。キーは、すべてのエクスポートリクエストでプレーンなヘッダー値として送信されます。
x-honeycomb-team: <your-honeycomb-ingest-api-key>
データセットのルーティングは、2番目のオプションヘッダーによって制御されます。 x-honeycomb-dataset が省略された場合、Honeycombは service.name リソース属性からターゲットデータセットを決定します。明示的に設定されている場合、そのエクスポートバッチ内のすべてのスパンは、 service.nameにかかわらず、指定されたデータセットに書き込まれます。
x-honeycomb-dataset: tfy-llm-gateway-production
TrueFoundryゲートウェイは、設定されたエンドポイントにシグナルパスを自動的に追加しません。 /v1/traces を含む完全なパスがエンドポイントフィールドに存在する必要があります。これは、OpenTelemetry CollectorのOTLP HTTPエクスポーターとは異なります。OTLP HTTPエクスポーターは、 /v1/traces をパイプラインのシグナルタイプに基づいて自動的に追加します。Collectorでは、次のような単一のベースURLが https://api.honeycomb.io:443 Collectorがパイプライン定義からパスを解決するため、これで十分です。TrueFoundryでは、エンドポイントはそのまま使用されます。
TrueFoundryの設定画面は、Honeycombが必要とするフィールドに直接対応しています。
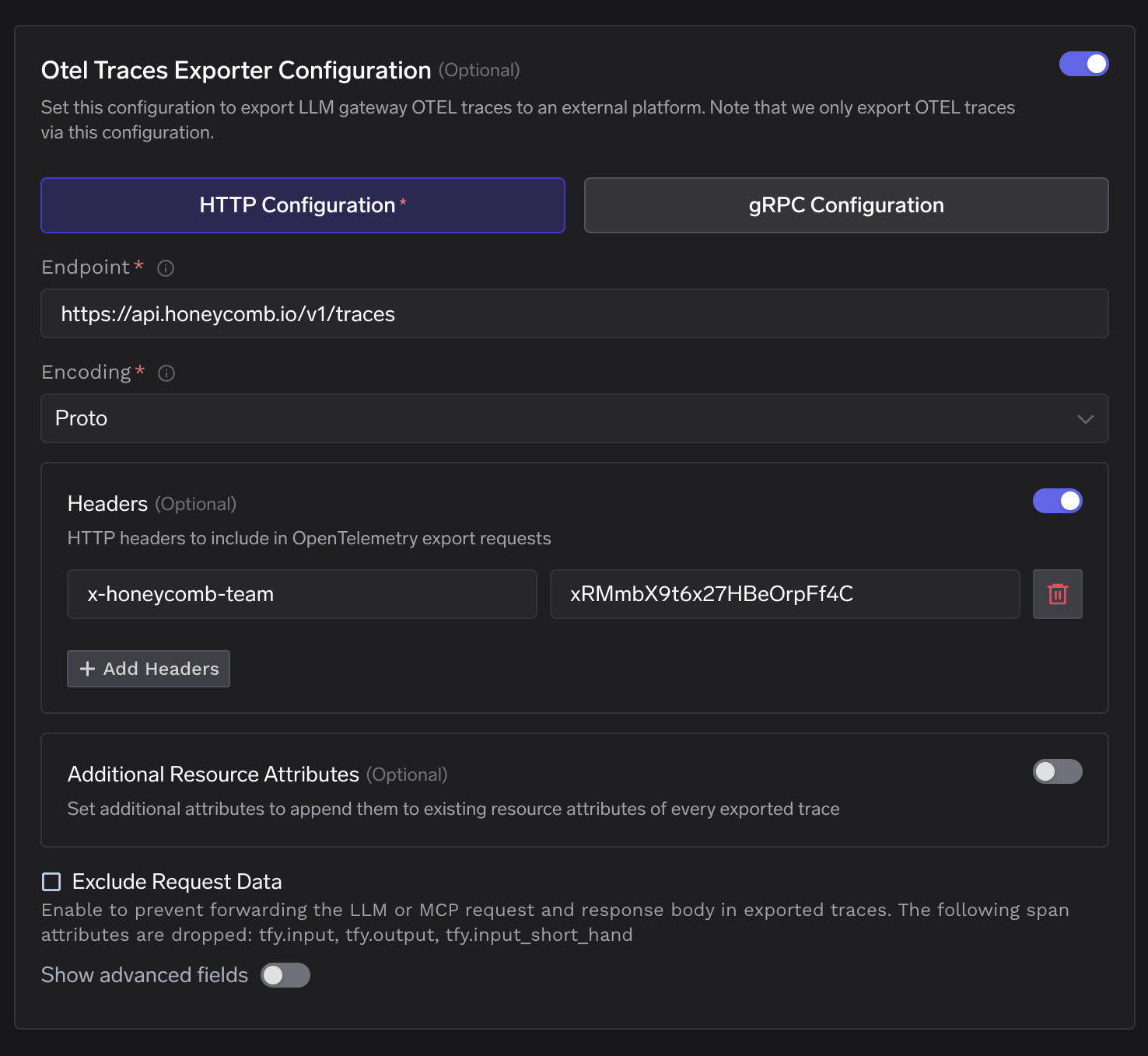
この 追加のリソース属性 フィールドは、エクスポートされるすべてのスパンのリソースブロックにキーと値のペアを追加します。これは、スパン属性にまだ存在しないデプロイ環境タグやクラスター識別子を追加するのに役立ちます。
この リクエストデータを除外 チェックボックスをオンにすると、 tfy.input および tfy.output および tfy.input_short_hand がスパンがゲートウェイを離れる前に削除されます。Honeycombは、トークン数、レイテンシー、モデル名、エラーフラグなど、すべての構造属性を引き続き受け取ります。
リクエストがTrueFoundryゲートウェイに到達すると、リクエスト処理中に完全なスパンツリーがメモリ内で組み立てられ、レスポンス完了後にNATSに公開されます。OTELエクスポーターはこのNATSサブジェクトを購読し、スパンをバッチ処理してから送信します。 https://api.honeycomb.io/v1/traces HTTPS経由で、 x-honeycomb-team ヘッダーが存在します。Honeycombは各スパンを、その行として tfy-llm-gateway データセットに書き込みます。スパンは到着後数秒でクエリ可能になります。
アプリケーションコードの変更は不要です。ゲートウェイの横にサイドカーコンテナはデプロイされません。クライアントにSDKは組み込まれません。この統合はゲートウェイ上の設定インターフェースであり、エンドポイントURLと認証ヘッダーを1つずつ設定するだけです。OpenAI互換APIを介してゲートウェイを呼び出す既存のクライアントは、変更なしで引き続き機能します。
この統合を信頼性の高いものにしている原則は、非同期エクスポートパスです。トレースのエクスポートは、NATSを介してリクエストのライフサイクルから切り離されています。ゲートウェイとHoneycombの取り込みエンドポイント間のHoneycomb APIの停止やネットワーク分断は、推論の可用性に影響を与えません。ゲートウェイは、ダウンストリームのエクスポートが成功するかどうかにかかわらず、リクエストを処理し、スパンをNATSに公開します。これは、オブザーバビリティパイプラインが、リクエスト処理パスに影響を与えることなく、設定、再設定、再起動できることを意味します。
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








最新のニュース、記事、リソースをメールでお届けします
© 2026 無断複写・転載を禁じます。







.png)








.webp)
.webp)


