













.webp)
July 4, 2026
|
5 min read

Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
TrueFoundry AIゲートウェイ OpenTelemetryトレースを Traceloop へOTLP/HTTP経由で、 https://api.traceloop.com/v1/traces エンドポイントと、 Authorization ヘッダーにBearerトークンを含めてエクスポートします。ゲートウェイを通過するLLMリクエストはすべて、アプリケーションコードやデプロイメントトポロジーを変更することなく、Traceloopダッシュボードに表示されるスパントレースを生成します。
この記事では、 TrueFoundry AIゲートウェイ の内部でのトレース生成パスと、 Traceloop がそのデータを取り込み、表示するかについて説明します。また、ゲートウェイレベルで利用可能な設定インターフェースとデータプライバシー制御についても解説します。
この TrueFoundry AIゲートウェイ はHonoフレームワーク上に構築されており、シングルvCPUで1秒あたり250以上のリクエストを処理し、リクエストあたり約3ミリ秒の追加レイテンシで動作するステートレスなPodです。このゲートウェイは分割アーキテクチャで動作し、コントロールプレーンが設定を管理し、1つ以上のゲートウェイPodが推論トラフィックを処理します。
リクエストが到着すると、ゲートウェイはホットパスで以下のシーケンスを実行します。
これらのステップは、プロバイダー呼び出し自体を除いて、外部呼び出しを行いません。レート制限は、インメモリの状態に対してスライディングウィンドウトークンバケットアルゴリズムを実行します。ガードレール評価(設定されている場合)は、入力チェックのためにモデル呼び出しと並行して実行され、出力チェックのために順次実行されます。
リクエスト完了後、ゲートウェイはスパンツリーをNATSに非同期で公開します。OTELエクスポーターはこの非同期パスから読み取り、設定された外部エンドポイントにスパンを転送します。エクスポートパスがリクエストパスから完全に分離されているため、遅い、または到達不能なOTELバックエンドがクライアントにレイテンシを追加したり、リクエストの失敗を引き起こしたりすることはありません。もし Traceloop が到達不能な場合、スパンはエクスポーターで破棄され、内部的にログに記録されます。エクスポートは追加的なものであるため、TrueFoundry独自の内部トレースストレージには影響しません。
ゲートウェイは、インバウンドHTTPハンドラー、認証、モデル解決、アウトバウンドプロバイダー呼び出し、ストリーミングレスポンスアセンブリの5つのステージにわたってスパンを生成します。各スパンは一貫した属性セットを保持します。
gen_ai. *属性は、生成AIシステム向けのOpenTelemetryセマンティック規約に従います。これは、Traceloopに到着するトレースデータが、OpenLLMetryで計測されたどのアプリケーションが生成するものとも構造的に同一であることを意味します。

Traceloopは、オープンソースのOpenTelemetry計測レイヤーであるOpenLLMetry上に構築されたLLM可観測性プラットフォームです。TraceloopのバックエンドはOTLP/HTTPトレースデータを受け入れ、Traceloopダッシュボード用にインデックス化します。このプラットフォームはトレースネイティブです。トークン使用量、レイテンシ、コストなどのメトリクスは、個別のOTLPメトリクスストリームからではなく、スパン属性から計算されます。このため、TrueFoundryでトレースエクスポーターのみを設定すれば十分です。 /v1/metrics エンドポイントはTraceloopの取り込みインターフェースにはありません。
Traceloopは、3つの主要な抽象化を中心にデータを整理します。トレースは最上位の単位であり、LLMリクエストまたはエージェントワークフローに直接対応します。トレース内のスパンは、個々の操作(LLM呼び出し、ツール呼び出し、検索ステップ)を表します。環境はデプロイメントステージにマッピングされ、各環境には独自のAPIキーがあり、開発、ステージング、本番のトレースをダッシュボード内で分離したままにできます。
Traceloop ダッシュボードには、時間経過に伴うトークン使用量、レイテンシー分布、エラー率、モデルの内訳が直接表示されます。 gen_ai。* スパン属性。TrueFoundryがこれらの属性をすべてのスパンに設定するため、Traceloopダッシュボードはアプリケーション層でのSDK計測なしに完全に情報が入力されます。

Traceloop はプロンプトのバージョン管理と回帰テストパイプラインもサポートしていますが、これらの機能はアプリケーションSDKレベルで動作するため、この統合の範囲外です。ゲートウェイレベルの統合は、完全な可観測性サーフェスをカバーします。TrueFoundryを通過するすべてのリクエストは、どのLLMプロバイダーやモデルが呼び出されたかに関わらず、Traceloopでトレースを生成します。
TrueFoundryとTraceloop間の接続は、への単一のOTLP/HTTP POSTです https://api.traceloop.com/v1/traces Protoエンコードされたスパンバッチを運びます。認証は、のBearerトークンです Authorization ヘッダーです。このトークンは、特定の環境にスコープされたTraceloop APIキーです。
TrueFoundryは、この設定を以下で公開しています AI Gateway → Controls → Settings → OTEL Config。Otel Traces Exporterセクションでは、以下のフィールドを受け入れます。
エンドポイントには、完全な /v1/traces パスを含める必要があります。TrueFoundryのエクスポーターは、シグナルパスを自動的に追加しません。これはOTel Collectorの otlphttp ベースURLからパスを自動的に追加するエクスポーター。どちらも同じ宛先に解決されます。
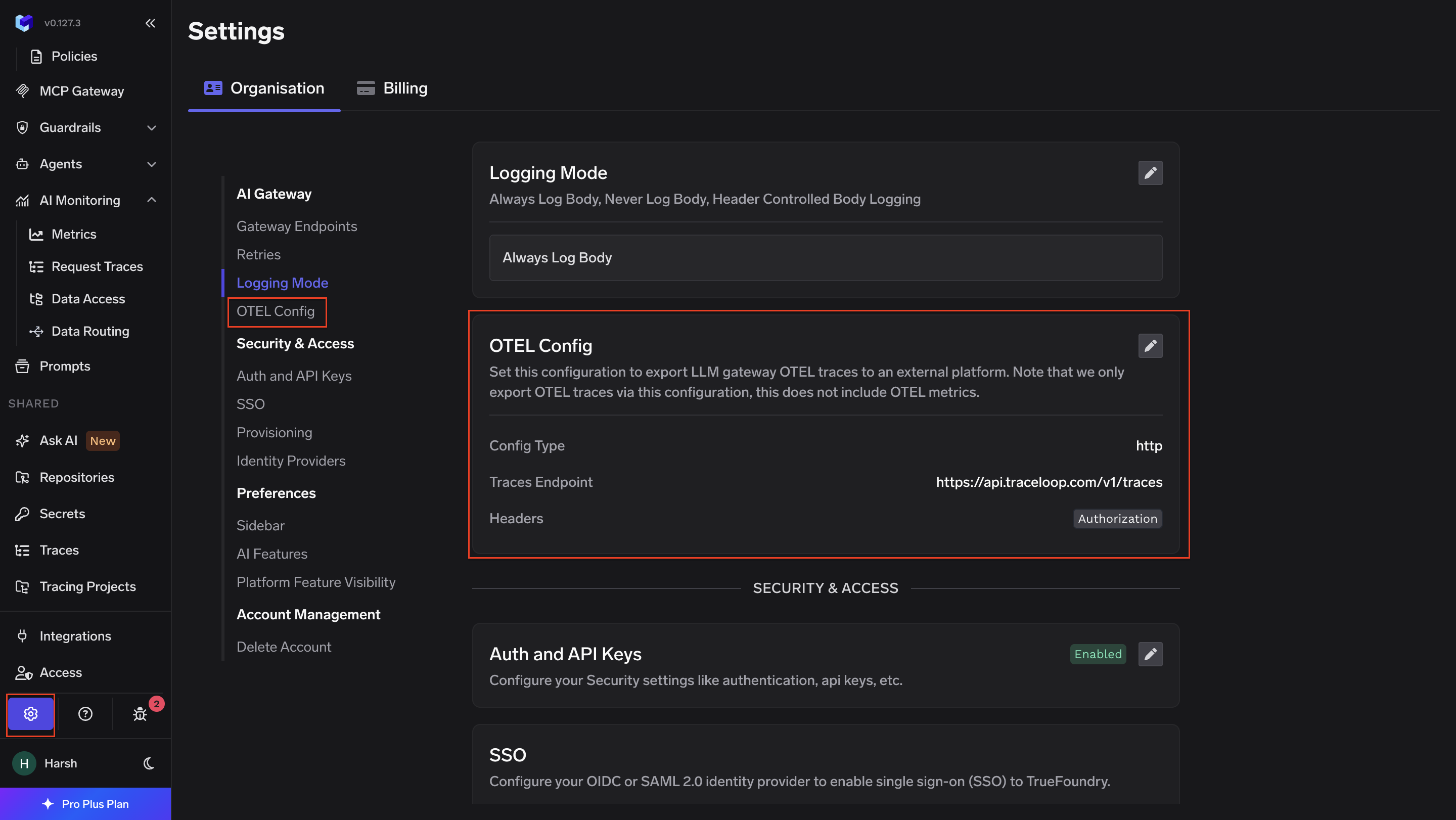
Traceloop APIキーは、Traceloopダッシュボードの「環境」ページから環境ごとに生成されます。キーは作成時に一度だけ表示されます。キーの値はヘッダーに次のように渡されます。 Bearer <key> を含む Bearer プレフィックスをリテラル文字列として。
ゲートウェイには リクエストデータを除外 OTEL設定セクションにあるトグルがあります。有効にすると、エクスポーターは tfy.input および tfy.output および tfy.input_short_hand をTraceloopに転送する前に、すべてのスパンから削除します。残りのスパン属性(トークン数、モデル名、レイテンシー、ルーティングメタデータ)は影響を受けません。このトグルは、プロンプトや完了にユーザーのPIIや、クラスターの境界を越えてはならない独自のコンテンツが含まれる場合に適切です。
この 追加リソース属性 フィールドでは、エクスポートされるすべてのスパンにカスタムのキーと値のペアを追加できます。これは、環境のタグ付け、コストセンターの割り当て、単一のTraceloop環境内でのマルチテナントフィルタリングに役立ちます。
すべてのLLMリクエストは TrueFoundry AI Gateway を介して、認証とルーティング、プロバイダー呼び出し、および応答をカバーするスパンツリーを生成します。リクエスト完了後、ゲートウェイはこのスパンツリーをNATSに非同期で公開します。OTELエクスポーターはNATSから読み取り、Protoエンコードされたバッチを https://api.traceloop.com/v1/traces にBearerトークンを使用してPOSTします。Traceloopはスパンをインデックス化し、ダッシュボードでトークン使用量、レイテンシー、モデルの内訳を、 gen_ai.* 属性から表示します。
サイドカーは不要です。アプリケーションコードの変更は不要です。ゲートウェイを呼び出すサービスにOpenLLMetry SDKを追加する必要はありません。この統合はゲートウェイ層で完全に動作し、呼び出し元アプリケーションの計測状態に関わらず、ゲートウェイを通過するトラフィックの100%をカバーします。
このクリーンな設計を可能にしているのは、非同期NATSパブリッシュです。スパンのエクスポートがリクエストパスから分離されているため、この統合は推論呼び出しにレイテンシーを一切追加せず、Traceloopへの可用性依存性も生じさせません。Traceloopが到達可能であるかどうかにかかわらず、ゲートウェイはフルスループットでリクエストを処理します。
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








最新のニュース、記事、リソースをメールでお届けします
© 2026 無断複写・転載を禁じます。







.png)







.webp)
.webp)



.webp)