













.webp)
July 4, 2026
|
5 min read

Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
50 Questions to Ask Every Vendor in 2026
Enterprise AI platform evaluations fail in predictable ways. The vendor's demo runs against a curated test prompt. Their pricing slide uses 5,000-token-per-call assumptions that don't match your actual workload. The security architecture diagram they show is for a deployment mode you haven't asked about. The MCP capability they claim is available “in our next release.” Six weeks later you're signing a contract for a product that's a 70 percent fit, and your platform team spends the contract term filling the other 30 percent with custom work.
A scored RFP changes the dynamic. Every vendor answers the same questions, in writing, before any demo runs. Their non-answers (a question dodged, a capability that “requires our integration partner,” a compliance claim that doesn't survive a scope question) surface in the written record where they can't be re-spun in a follow-up call. The same record holds the vendor accountable when post-signature reality starts diverging from the pre-signature pitch, which is the single most common procurement complaint at year-one renewal.
Three things push this template beyond what generic enterprise procurement frameworks already cover. MCP governance, the protocol stack your AI agents will use to talk to tools, where most AI gateway products are still bolting on access control they didn't design for. Agentic AI controls, the trace correlation, cost attribution, and isolation boundaries that turn a multi-step agent task into a debuggable, billable, governable unit instead of a fog of disconnected LLM calls. AI-specific compliance, including audit log field parity between LLM and tool invocations, structured data-residency answers that account for model-provider routing across regions, and the BAA architectural controls that make HIPAA enforcement real rather than paperwork.
Use this as a starting point. Adjust the weights to your environment. Send the same document to every vendor on your shortlist. TrueFoundry's solutions team is set up to answer all 50 questions in writing with evidence as part of the formal enterprise evaluation.
Now to the questions themselves.

Figure 1. Split-plane reference architecture: control plane and compute plane separated by a metadata-only boundary, with one IdP feeding identity into both.
The order of operations matters more than the questions themselves. Most failed evaluations skip step one: getting written answers to the full template before any vendor is allowed to demo. Demos are for verification of written claims, not for discovery. If a vendor's first communication of a feature comes from a slide, you've handed them control of the evaluation narrative.
Send the template to every vendor on your shortlist simultaneously, with a written response deadline two weeks out. Use the responses to score against a weighted rubric. Only after scoring do you book demos, and in those demos your platform team's job is to verify that what's in writing matches what's running. Treat any claim that surfaces in the demo but wasn't in the written response as a discovery to investigate, not a feature to score positively.
A few specifics on running this well:
If you've ever sat through a security review where the vendor's compliance scope only covered the SaaS option you weren't planning to use, you know the cost of skipping the rubric step. A scored RFP forces that detail out before the contract.
Security and compliance is where most AI platform evaluations fall apart in the second meeting. Not because vendors lack certifications. Most have SOC 2 Type II somewhere. The failure mode is alignment: the certification scope, the architectural controls implementing it, and the deployment mode you're actually buying don't match. A SOC 2 covering the vendor's marketing portal does nothing for an AI gateway processing PHI on-prem. A BAA that exists in template form but doesn't describe how PHI is isolated in the data plane is paperwork, not a control. The questions below force the alignment between certification scope and architectural reality that prevents “we're certified” answers from carrying weight they shouldn't.
The other failure mode worth naming early: vendors who answer security questions in the abstract because their concrete architecture is split between two products with different control postures. Their on-prem version is feature-thin and not separately certified. Their SaaS version has the certifications but doesn't fit your environment. Spot this by asking the same question twice with the deployment mode specified each time. If the answers differ, you're looking at two products marketed as one.
Score this section ruthlessly.
A split-plane deployment where the data plane (the proxy that handles prompts, model responses, embeddings, MCP tool invocations) runs entirely in the customer's VPC and never opens an outbound connection to vendor infrastructure for request payloads. The control plane (configuration, RBAC settings, dashboards) may run in vendor infrastructure or customer infrastructure depending on the deployment mode, but exchanges only metadata. Audit logs, prompt-response data, and embeddings land in customer-controlled blob storage (S3, GCS, Azure Blob), not vendor-managed databases. If the vendor's “VPC deployment” still ships prompts to a vendor-managed log aggregator, that's a SaaS deployment in a different wrapper.
Check the System Description section for explicit naming of the deployment modes covered. Look for language like “the multi-tenant SaaS environment hosted in [cloud]” versus “the customer-deployed gateway and control plane components.” If the description names only one, the certification covers only one. Check the Trust Services Criteria covered. Security is the baseline, but Availability, Confidentiality, and Processing Integrity matter for AI workloads handling regulated data. A SOC 2 covering only Security is half the story.
The platform pulls model provider keys from the customer's Vault or Secrets Manager at gateway startup or on-demand using a customer-managed IAM role, with key references (not key values) stored in platform configuration. Rotation is a Vault operation: rewrite the key in Vault, the gateway picks up the new value on next read or on a configurable refresh interval. The platform never persists provider keys at rest. If the vendor's answer is “you upload keys into our admin UI and we store them encrypted,” that's a different (and weaker) security model. The keys are now in vendor infrastructure even in a “VPC” deployment.
{
"event_type": "llm_inference",
"timestamp": "2026-04-28T14:22:31.482Z",
"request_id": "req_01H8X2YZ...",
"trace_id": "4bf92f3577b34da6a3ce929d0e0e4736",
"user": {
"id": "u_4821",
"email": "ana@company.com",
"team": "applied-ml"
},
"application": {
"id": "app_chat_support",
"env": "prod"
},
"model": {
"provider": "anthropic",
"id": "claude-sonnet-4-6",
"version": "20260217"
},
"tokens": {
"input": 1842,
"output": 619,
"cached": 1200
},
"latency_ms": {
"ttft": 312,
"total": 2180
},
"cost_usd": 0.01443,
"policy": {
"guardrails_evaluated": [
"pii",
"content_filter"
],
"decision": "allow"
},
"status": "success"
}The MCP tool invocation log should have field parity for the shared dimensions (timestamp, request_id, trace_id, user, application, latency_ms, status, policy decision) plus the tool-specific fields:
{
"event_type": "mcp_tool_invocation",
"timestamp": "2026-04-28T14:22:32.014Z",
"request_id": "req_01H8X2YZ...",
"trace_id": "4bf92f3577b34da6a3ce929d0e0e4736",
"user": {
"id": "u_4821",
"email": "ana@company.com",
"team": "applied-ml"
},
"application": {
"id": "app_chat_support",
"env": "prod"
},
"mcp_server": {
"id": "github-prod",
"version": "1.4.2"
},
"tool": {
"name": "github.create_issue",
"schema_version": "v2"
},
"parameters_hash": "sha256:7c8b...a31e",
"response_size_bytes": 412,
"latency_ms": 528,
"policy": {
"rules_evaluated": [
"repo_allowlist",
"rate_limit"
],
"decision": "allow"
},
"status": "success"
}Notice the same trace_id on both: the LLM call and the MCP invocation correlate to one user request, which is the answer to Section 4 question 8 made concrete. Hash the parameters rather than logging them raw. Full parameter logging is a data-leakage risk in regulated environments. If the vendor's sample MCP log is missing policy.decision, trace_id, or user attribution, MCP governance is post-hoc reporting, not enforcement.

Figure 2. Audit log data flow: field parity between LLM inference events and MCP tool invocation events, both correlated by one trace_id.
“Encrypted at rest” is universal. Whose key is doing the encrypting is the actual control. In a self-hosted deployment, customer-controlled keys are achievable because the data stores are in the customer's account; in a SaaS deployment, customer-controlled keys are a vendor-side capability that has to be designed in. Ask the question with the deployment mode specified.
For self-hosted deployments, “patch availability” means a tagged release the customer's platform team can deploy. “Customer-applied window” is the SLA the customer signs up for internally. If the vendor proposes a 30-day customer window for critical CVEs, that's a long time to be exposed; push back.
Most enterprise procurement falls apart in deployment. The platform looks great in the SaaS demo, then the security review surfaces three things that block it: outbound connectivity to vendor infrastructure for telemetry, a configuration database hosted in vendor cloud, and a control plane that's tightly coupled to a specific cloud region. By the time those constraints are visible you've already negotiated pricing on the wrong product, and the path forward is either renegotiating from a position of sunk cost or accepting a deployment that creates compliance debt.
This section surfaces deployment constraints upfront. The vendors who can answer it cleanly are the ones who've already deployed in environments like yours. The vendors who need a discovery call to answer Section 2 haven't, and you'll be doing the integration engineering on the discovery call you're paying them for.
Watch the answers carefully.
┌──────────────────────────────────────────────────────┐
│ Customer VPC (one region, two AZs for HA) │
│ │
│ [ALB / NLB] │
│ │ │
│ ├──> Gateway pods (3+ replicas, HPA enabled) │
│ │ ↕ reads keys from │
│ │ [Secrets Manager / Vault] │
│ │ ↕ writes audit + metrics to │
│ │ [S3 / GCS / Azure Blob] │
│ │ ↕ reads config from │
│ │ [Postgres (HA, multi-AZ)] │
│ │ │
│ └──> egress to: model provider APIs, │
│ MCP servers (in-VPC or │
│ allowlisted external) │
│ │
│ [Control plane endpoint] ──> metadata only, │
│ (vendor or self-hosted) no payload data │
└──────────────────────────────────────────────────────────┘
Order-of-magnitude sizing for ~500 RPS sustained: 3 to 4 gateway replicas at 2 vCPU / 4 GB RAM each, Postgres at 4 vCPU / 16 GB RAM with 100 GB SSD, blob storage scaled with retention (a 90-day retention at 10 KB/log entry and 500 RPS is roughly 1.2 TB). The vendor should produce numbers like these in writing before signing, not “depends on workload.”

Figure 3. One control plane managing compute planes across AWS, Azure, GCP, and on-prem Kubernetes simultaneously, each with its own data residency boundary.
Anything worse than this for a multi-region production setup should come with a written explanation. “We don't support multi-region” is acceptable from a small vendor; “we support it but won't commit to RTO” is not.
Every AI gateway product page reads the same: unified API, intelligent routing, cost controls, observability. The specifics behind those words are what separates a gateway you can run in production from a thin proxy with a marketing site. “Intelligent routing” can mean anything from a static round-robin between two models to a real cascading policy with cost ceilings, capability matching, and fallback chains. “Cost controls” can mean a dashboard that shows you yesterday's bill, or it can mean hard token budgets that actually return a 429 to the application when a team hits its limit.
The questions in this section force the specifics out. Reject responses that restate the marketing copy back to you. The vendor who says “we support intelligent routing” without describing the rule language, the cascade behavior, the failure handling, and the budget integration doesn't have routing. They have a config flag.
Make them prove the architecture exists.
route: chat-support
match:
application: app_chat_support
team: applied-ml
strategy: cascade
cascade:
- model: claude-sonnet-4-6
provider: anthropic
conditions: { max_input_tokens: 1000000 }
- model: gpt-5.5
provider: openai
conditions: { fallback_on: ["rate_limit", "5xx"] }
- model: claude-haiku-4-5
provider: anthropic
conditions: { fallback_on: ["all_above_failed"] }
guardrails: [pii, content_filter]
budget_ref: budget_applied_ml_q2
The application sends a standard OpenAI-compatible request. The gateway picks the provider based on the rule, falls down the cascade on failure, attaches the budget reference for cost attribution, and applies guardrails inline. No application code changes when the route is reconfigured. If the vendor's “intelligent routing” requires application-level changes for every variant, that's not gateway-level routing. It's a wrapper.
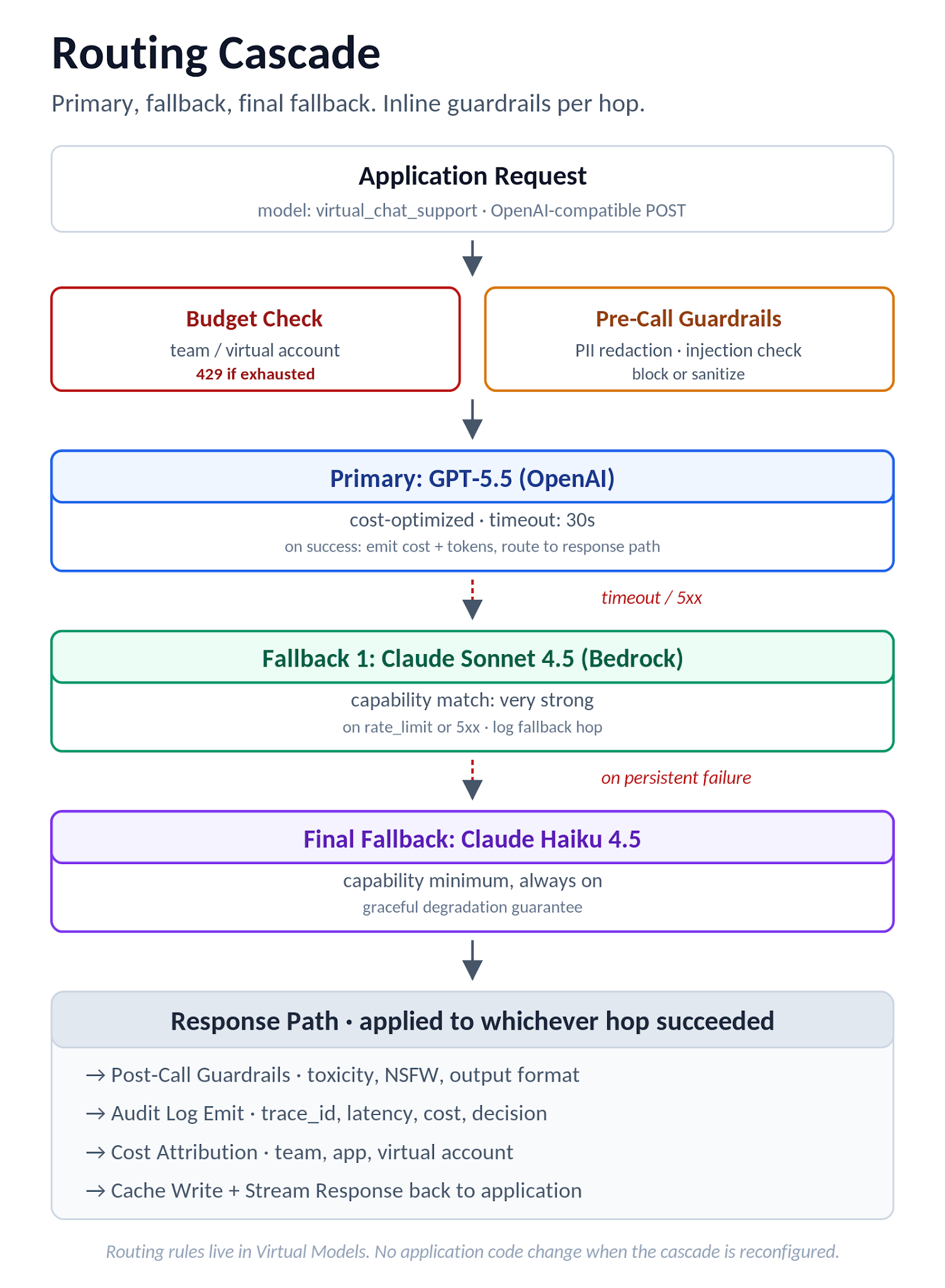
Figure 4. Routing cascade flow: budget check, pre-call guardrails, primary model attempt, fallback chain, and a unified response path with audit, cost, and cache.
This section is where most AI gateway products will struggle, because most of them were designed for the LLM-call era and predate the moment MCP started showing up in real enterprise environments. MCP isn't “more observability for tool calls.” It's a separate governance plane: a registry of approved servers, an enforcement point for which tools each role can invoke, audit logs that match the LLM call logs in field coverage, and a policy engine that runs at invocation time rather than as a post-hoc report. Vendors who don't have this plane will try to answer Section 4 questions with descriptions of LLM observability. Watch for the substitution. The more direct the answer, the more real the capability.
The pattern to expect: a strong AI gateway vendor will describe the MCP gateway as a separate product surface with its own registry, its own RBAC mapping, its own audit log schema, and its own policy language. A weaker vendor will describe it as “extended observability” over their existing LLM observability stack, which is the giveaway that the governance is sparse. Score Section 4 specifically; do not roll it into Section 3.
Read each answer for direct enforcement language.
policy: github-write-restriction
applies_to:
mcp_server: github-prod
tool_pattern: "github.*"
rules:
- match:
tool: github.delete_repo
action: deny
reason: "Destructive operations require change-management ticket"
- match:
tool: github.create_pr
user.team: ["junior-engineers"]
parameters.target_branch: "main"
action: deny
reason: "Direct-to-main PRs require senior-engineer approval"
- match: {tool: "github.*"}
action: allow
log_level: full
この規則の更新は、数秒以内にゲートウェイに伝播されるべきです(再デプロイではなく、設定のプッシュによる)。ベンダーの回答が「ポリシーはMCPサーバー自体によって評価される」というものであれば、それはゲートウェイによって強制されるポリシーではありません。サーバーによって強制されるものであり、カタログ内のすべてのMCPサーバーでポリシーの同等性を維持する必要があります。それは別の問題です。
traceparent: 00-4bf92f3577b34da6a3ce929d0e0e4736-00f067aa0ba902b7-01
└─ trace-id (32 hex) └─ span-id (16 hex)
ゲートウェイは、アウトバウンドヘッダーにトレースIDを挿入することで、すべてのダウンストリーム呼び出し(LLMプロバイダー、MCPサーバー、セカンダリゲートウェイホップ)にわたってトレースIDを保持し、各呼び出しを同じトレースIDの下でスパンとして出力します。Datadog、Grafana Tempo、またはJaegerでは、結果は単一のウォーターフォールとして表示されます。ユーザーリクエスト → LLM呼び出し(claude-sonnet-4-6、2.1秒) → ツール呼び出し(github.create_issue、528ミリ秒) → LLM呼び出し(出力フォーマッター、380ミリ秒) → レスポンス。これがない場合、同じフローは4つの無関係なエントリとして表示され、根本原因分析は推測に頼ることになります。

図5. MCPゲートウェイアーキテクチャ:クライアントとMCPサーバーの間に認証、レジストリ、ポリシー、ロギング層を持つ、開発者ツールとエージェントのための単一のエンドポイント。
優れた監視を行うAIプラットフォームと、優れた可観測性を持つAIプラットフォームの違いは、月末に財務チームが尋ねる質問に現れます。監視は、請求額が40パーセント増加したことを伝えます。可観測性は、マーケティングチームのチャットボットが3週間前にコンテキストウィンドウのエッジケースでループし始めたこと、増加分の70パーセントが単一のアプリケーションによるものであること、そして暴走したリクエストにはより安価なモデルにルーティングできる特定のシグネチャがあることを伝えます。最初の回答は財務部門を怒らせます。2番目の回答は財務部門を味方につけます。
同じ区別はエージェントのデバッグにも現れます。監視は、エージェントタスクが失敗したことを伝えます。可観測性は、どのLLM呼び出しが不正な応答を返したか、その結果としてどのダウンストリームツール呼び出しがタイムアウトしたか、そしてその障害がどのユーザーリクエストに起因するかを伝えます。LLMおよびMCPプレーン全体にわたる相関トレースがない場合(セクション4の質問8)、すべてのエージェント障害はフォレンジック調査となります。以下の質問は、ベンダーに、呼び出しごとに実際に何がキャプチャされるか、それがどのようにクエリ可能か、そして財務システムが必要とするときにデータがプラットフォームからどのように出力されるかを説明するよう促します。
ここでは具体性が重要です。
agent_task: trace_id 4bf92f35...
user: ana@company.com (team: applied-ml)
initiating_request: app_chat_support, 2026-04-28 14:22:31
duration: 4.8s
components:
- llm: claude-sonnet-4-6 | tokens 1842 in / 619 out | $0.0144
- tool: github.create_issue | latency 528ms | n/a
- llm: claude-haiku-4-5 | tokens 412 in / 87 out | $0.0011
total_cost_usd: $0.0155
total_tokens: 2960
これが、「エージェントのコスト帰属」を技術的な好奇心ではなく、財務レベルのシグナルにするものです。

図6. 単一のエージェントタスクのトレースウォーターフォールビュー:LLM呼び出し、MCPツール呼び出し、および2回目のLLM呼び出しがすべて1つのtrace_idの下にあり、コストはスパン全体でロールアップされています。
連携のギャップによるコストは、調達段階ではほとんど見えません。それは6ヶ月後に顕在化します。SCIMが実用的でないため、退職した従業員のアクセス権の取り消しに48時間かかる場合、午前2時のP1障害に対して、SLAが願望に過ぎないため「営業時間内に対応します」という自動返信が来る場合、プラットフォームのSSO連携がグループライフサイクルイベントでテストされていなかったため、Oktaグループ名の変更がロール割り当てを壊す場合などです。これらはいずれも限定的なエンジニアリングコストですが、それらが積み重なって運用上の負担となり、プラットフォームチームは3年目の更新時に、本来は優れた製品であっても静かに別の製品へ移行することになります。
第6章では、運用上の現実が浮き彫りになります。2つの診断パターンがあります。プロトコルサポートに関する質問への「はい」という回答は、現在そのプロトコルを本番環境で運用している顧客と、それを最初に試すことになる顧客はどちらかについて、さらに掘り下げて確認する必要があります。また、明確なクレジットが付帯していないSLAのコミットメントは、マーケティング目標として扱うべきです。契約上のSLAには、ベンダーが達成できないリスクを価格に織り込んでいるため、クレジットが付帯します。願望的なSLAはマーケティング部門が作成するものであり、クレジットは付帯しません。
クレジットは書面で入手してください。
プラットフォームが固定された1つのクレーム形式しか消費できない場合、Okta/Azure AD以外のものとの連携は困難になります。上記の柔軟性は一度限りの設定コストです。それがなければ、すべてのIdPオンボーディングがカスタムエンゲージメントになってしまいます。
POST /scim/v2/Users
Authorization: Bearer <scim-token>
Content-Type: application/scim+json
{
"schemas": ["urn:ietf:params:scim:schemas:core:2.0:User"],
"userName": "ana@company.com",
"name": {"givenName": "Ana", "familyName": "Ruiz"},
"emails": [{"value": "ana@company.com", "primary": true}],
"groups": [{"value": "applied-ml"}, {"value": "ai-platform-developer"}],
"active": true
}IdPでユーザーがデプロビジョニングされると、同じエンドポイントがactiveをfalseに切り替えるPATCHを受け取り、プラットフォームは次回のログイン試行時ではなく、速やかにユーザーのアクセスを取り消すべきです。これを概念実証でテストしてください。IdPでテストユーザーをデプロビジョニングし、その後、まだ有効なプラットフォームトークンを使用しようとして、デプロビジョニングのライフサイクルがエンドツーエンドで機能することを確認します。プラットフォームが次回のユーザーログイン時にのみデプロビジョニングを尊重する場合、それは書面で指摘すべきコンプライアンス上のギャップです。
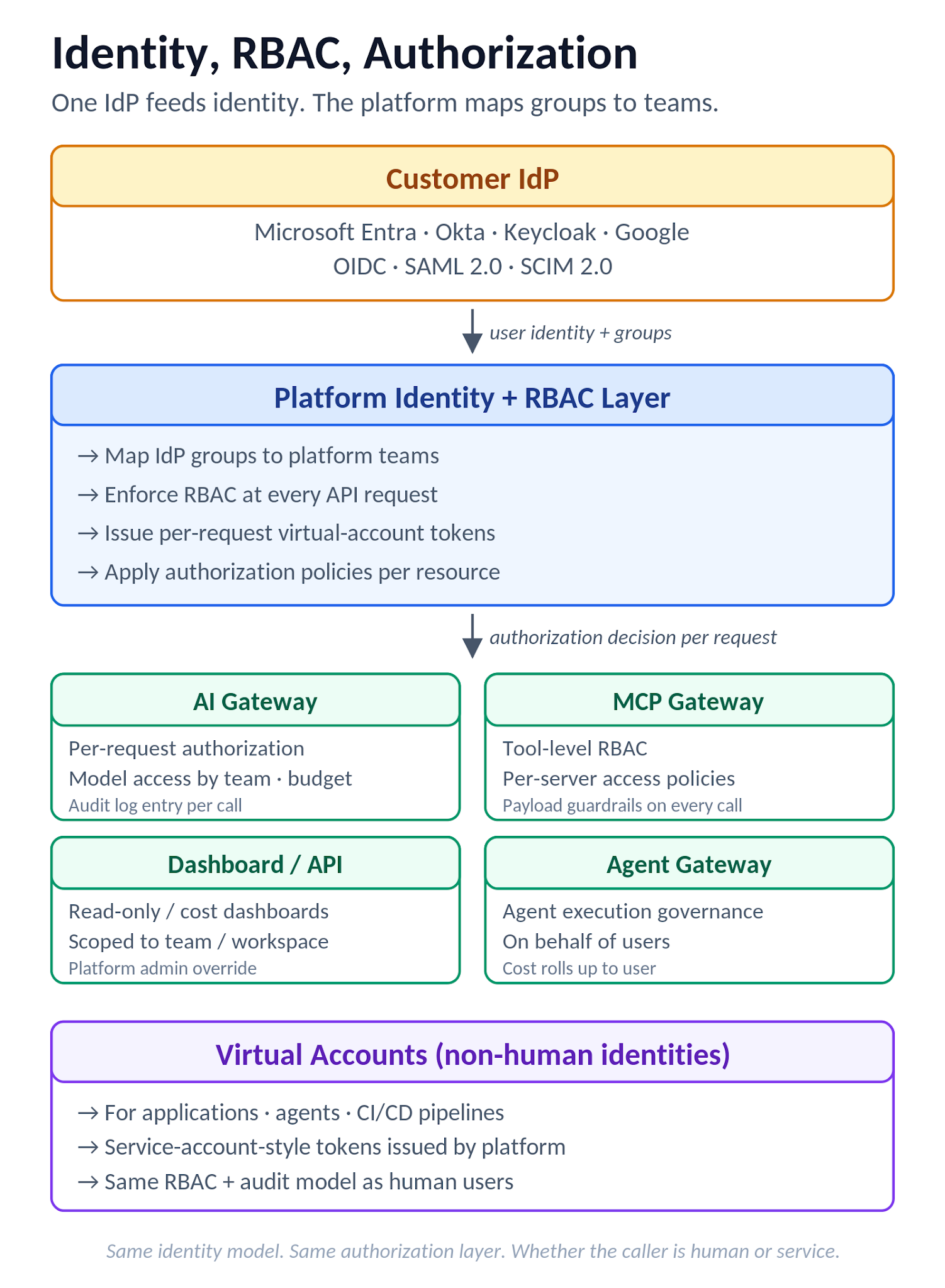
図7. IDとRBACのフロー:IdPがIDを提供し、プラットフォームがグループをチームと仮想アカウントにマッピングし、AI Gateway、MCP Gateway、ダッシュボード、およびAgent Gatewayで強制します。
「チケットを受け付けました」という自動メールを「応答時間」と定義している場合は注意してください。それは応答ではありません。真の応答とは、エンジニアが問題に取り組むことです。そして、クレジット条項が試金石です。契約上のSLAにはクレジットが付帯しますが、マーケティングSLAには付帯しません。
TrueFoundryのソリューションチームは、このRFPを営業資料ではなく、正式な評価と見なしています。すべての質問には、SOC 2 Type IIレポート、ヘルスケア展開向けのBAAドキュメント、侵入テストの概要、リファレンスアーキテクチャ、サンプル監査ログ、顧客リファレンスといった証拠を添えた書面での回答が提供されます。その成果物は、セキュリティ、調達、プラットフォームの各チームが、ギャップを埋めるためのディスカバリーコールを必要とせずに意思決定を行うために使用できるドキュメントです。
回答の根底にあるアーキテクチャは、このテンプレートのセクション構造に直接対応しているため、ほとんどの質問が明確に解決されます。詳細を見ていきましょう。
デプロイモデルはスプリットプレーンです。コントロールプレーンはオーケストレーションの中核であり、設定、RBAC、ダッシュボードをホストします。コンピュートプレーンはエージェントを介して接続し、AI Gateway、MCP Gateway、およびデプロイされたアプリケーションやセルフホスト型モデルを含む実際のワークロードをホストします。コンピュートプレーンは、顧客のクラウドアカウント(AWS、GCP、Azure)またはオンプレミスのKubernetesで実行でき、複数のコンピュートプレーンが1つのコントロールプレーンに接続することで、単一のコントロールサーフェスでマルチ環境運用を可能にします。AI Gatewayは、データレジデンシーおよび主権管理のために、顧客インフラストラクチャ内でセルフホストできます(デプロイオプションは別途文書化されています)。監査ログとトレースデータは、Gatewayリクエストロギングおよびトレースプロジェクトを使用して保存され、RBACがトレースとログへのアクセスを管理します。このスプリットプレーンアーキテクチャにより、SaaS、シングルクラウド、マルチクラウド、セルフホスト型デプロイメント全体で同じデータレジデンシーの姿勢が可能になり、それぞれを個別の制御姿勢を持つ別個の製品として扱う必要がなくなります。
データ主権は、マーケティング文句ではなく、アーキテクチャそのものです。
認証には、OIDCまたはSAML 2.0を介したエンタープライズSSOを使用し、APIアクセス制御のためにAI Gatewayで直接IdPトークン検証をオプションで実行できます。一般的なIdP(Microsoft Entra ID、Okta、Keycloak、Google)がサポートされており、IdPからのIDクレームとグループメンバーシップがTrueFoundryチームにマッピングされ、大規模なRBACを推進します。すべてのSSO構成(OIDCとSAMLの両方)でSCIMプロビジョニングがサポートされているため、IdPでのプロビジョニング解除は、次回のユーザーログインを待つことなく伝播します。RBACはテナントレベル(管理者/メンバーロール)で機能し、さらにユーザー、チーム、クラスター、ワークスペース、デプロイメント、AI Gatewayプロバイダーアカウント、MCPサーバー、およびトレースプロジェクトにわたるスコープ付き権限を持つカスタムロールも利用できます。非人間ID(アプリケーション、エージェント)には、サービスアカウントスタイルのトークンを持つ仮想アカウントが与えられ、AI Gateway境界(モデル、エージェント、MCPサーバー、ツール)でのリクエストごとの承認は、最小特権パターンをサポートします。プロバイダーキーは顧客管理のシークレットストアと統合されます。ゲートウェイ認証はIdPを置き換えるのではなく、その上にレイヤー化されているため、MFAと条件付きアクセスは顧客のIdPによって引き続き強制されます。
AIゲートウェイは、単一のOpenAI互換エンドポイントを介して1,000以上のLLMにルーティングします。これには、OpenAI、Anthropic(直接およびAWS Bedrock経由)、Azure OpenAI、GCP Vertex AI、Groq、Mistral、およびvLLM、TGI、またはTritonを介して提供されるセルフホスト型モデルが含まれます。ルーティングは仮想モデルを介して構成され、単一のモデルインターフェースを公開し、複数の基盤となるプロバイダーとモデル間でロードバランスまたはフェイルオーバーを行います。TrueFailoverは、障害および劣化を認識するルーティングをその上に重ね、マルチリージョンおよびマルチクラウドの回復性を組み込んでいます。ユーザー、チーム、または仮想アカウントごとの厳格なトークンおよびリクエスト制限は、チームが予算に達した場合に、リクエストが通過し続けるソフトアラートではなく、構造化された拒否を返します。プロバイダーのフォールバックは自動であり、遅延ペナルティは合計遅延に埋もれるのではなく、呼び出し時に個別のメトリックとして捕捉されます。セマンティックキャッシュは、設定可能なしきい値とTTLを持つ埋め込みとコサイン類似度を使用します。ドキュメントには、繰り返しまたは類似のクエリで最大約20倍の遅延改善が記載されています。ガードレールはルールベース(モデル、ユーザー、またはメタデータでターゲット設定)であり、それぞれが検証(ブロック)または変更(書き換え/編集)でき、FastAPIテンプレートを使用したカスタムガードレールサーバーを介してBring-Your-Own Guardrailがサポートされます。
ここでのルーティングは、単なる設定フラグではなく、製品そのものです。
MCPとエージェントスタックが差別化要因です。TrueFoundryはネイティブのMCP GatewayとMCP Registryを実行し、統制されたアクセス制御とエンタープライズ認証フローを介して、MCPサーバーとツールを一元的に登録、発見、安全に接続します。プロキシ接続用のストリーマブルHTTPを含む最新のMCPトランスポートがサポートされており、プロトコル層はMCP仕様に準拠した標準JSON-RPCメッセージングを使用します。認証は階層化されており、ゲートウェイ認証、MCPサーバーへのアクセス制御、およびサーバーごとまたはツールごとの認証(エンタープライズMCPサーバー向けに文書化されたOAuthベースのパターンを含む)が含まれます。一元化された構成により、開発ツールは各開発者が独自のMCP接続を配線する代わりに、1つのゲートウェイエンドポイントと通信します。これは、レジストリが防止するように設計されたシャドウツーリングパターンです。Agent Hubは、複雑なエージェントおよび既存のエージェントの組織的なカタログ化とオーケストレーションを提供し、Agent Gatewayは、それらのエージェントを本番環境で実行するためのエンタープライズガバナンス層(安全なツールアクセス、可観測性、コスト管理)を提供します。LLMアクセスを管理するのと同じIDがツールアクセスを管理するため、両方の承認は1つのIdP構成に存在します。そして、多段階のLLMエージェントタスクを結びつけるのと同じトレースコンテキストが、その下のMCP呼び出しを結びつけます。これにより、タスクごとのコスト集計とエンドツーエンドのデバッグが理論的ではなく、実用的なものになります。
可観測性には、トレース付きのGatewayリクエストロギングを使用します。トークン数、コスト、レイテンシ(TTFTおよび合計)、ガードレール決定、ポリシー決定、チームおよびアプリケーションの帰属が呼び出しごとにキャプチャされ、トレースとして保存され、独自のRBACを持つトレースプロジェクトを介してアクセスできます。テレメトリのエクスポートは標準ベースであり、OpenTelemetryデータエクスポートに加え、Grafana、Datadog、Prometheusなどの外部システムへのログおよびトレースエクスポートが可能です。そのため、顧客は独自のものを学習するのではなく、既存の可観測性スタックと統合できます。コストダッシュボードはリアルタイムであり、読み取り専用RBACを介してチームリーダーと共有できます。同じロギング/トレースストアが、プロンプトインジェクションの試行、ポリシーヒット、および顧客が時間とともにガードレールチューニングのためにマイニングできる悪用パターンの監査可能なデータセットを作成します。
既存の可観測性スタックは、そのまま既存の可観測性スタックとして機能します。
これらすべての裏付けとなるスループットの証拠:顧客ベース全体で月間100億件のリクエストを処理、プラットフォームによって管理される1,000以上のKubernetesクラスター、ゲートウェイ側のオーバーヘッドはp95で10ms未満(TTFT)、単一vCPUで350+ RPSを維持。本番環境で稼働している顧客には、Resmed、Siemens Healthineers、Automation Anywhere、Zscaler、Nvidiaが含まれます。シリーズAは2025年2月にIntel Capitalが主導し、Peak XV Partners (Surge)、Eniac Ventures、Jump Capitalが参加して、総資金調達額は約2,100万ドルに達しました。
パイロットスケールではなく、本番スケールです。
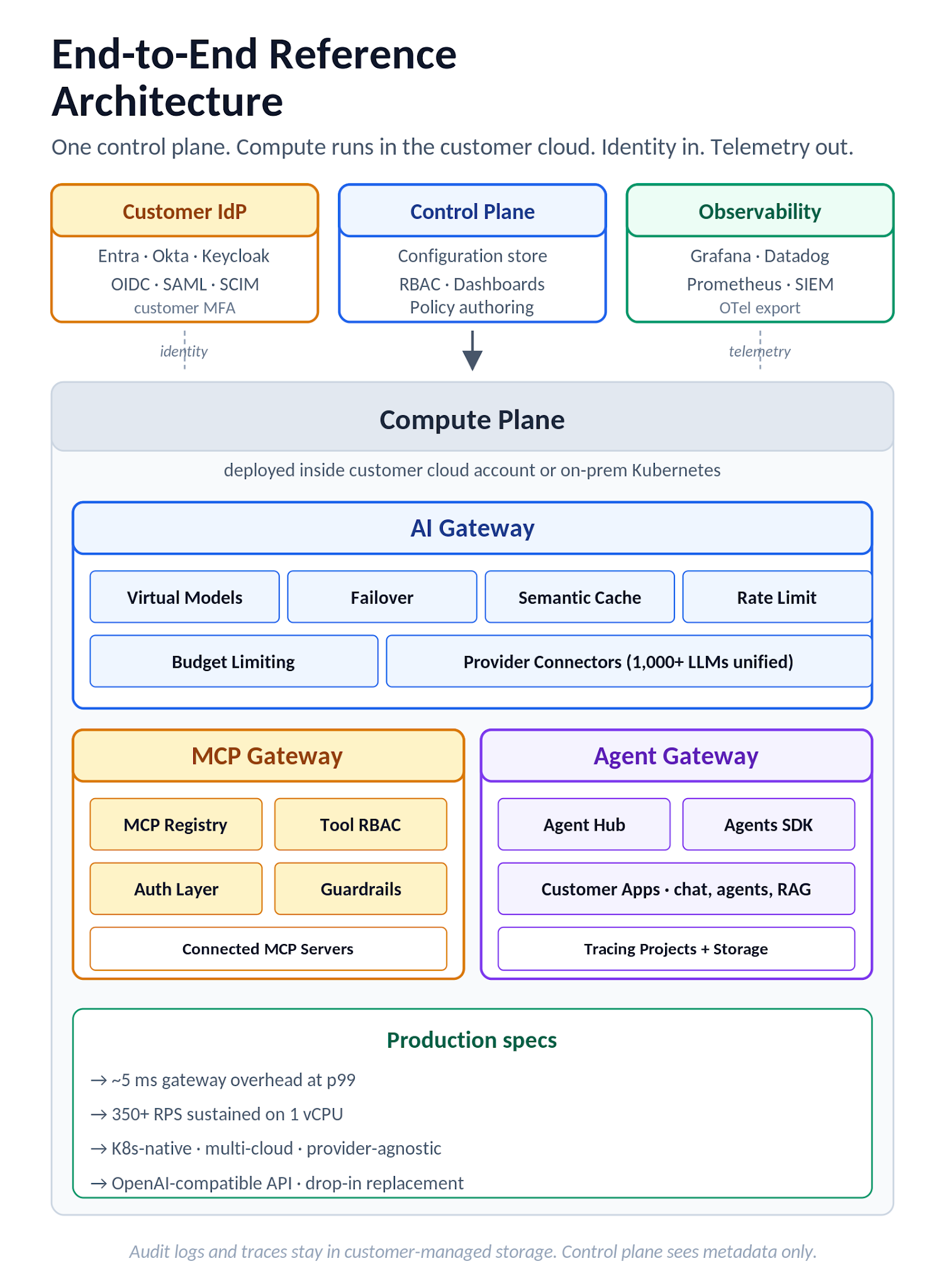
図8. TrueFoundryエンドツーエンドリファレンスアーキテクチャ:コントロールプレーン、コンピュートプレーン(AI Gateway、MCP Gateway、Agent Gateway、顧客アプリを含む)、顧客IdP、および可観測性ターゲット。
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








最新のニュース、記事、リソースをメールでお届けします
© 2026 無断複写・転載を禁じます。







.png)








.webp)
.webp)


