













.webp)
July 4, 2026
|
5 min read

Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
Claude Codeは、生産性向上ツールであると同時に、ガバナンス上の課題も抱えています。200人の開発者がいて中央制御点がない場合、彼らのエージェントが使用すると判断したあらゆるバックエンドにアクセスできてしまいます。そのギャップを埋めるのがゲートウェイです。
Claude Codeは大幅な生産性向上をもたらします。コードベースを読み込み、テストを実行し、データベースを照会し、複数のステップからなるエンジニアリングタスクを自律的に解決します。その能力こそが、セキュリティモデルを不安にさせる原因です。エージェントは、時折順番が回ってくるリモートサービスではありません。開発者のラップトップ上で、そのラップトップからアクセス可能なあらゆる認証情報を使って実行される自律的なループです。
Claude Codeには、本来、エンタープライズガバナンスの概念がありません。MCPサーバーの設定を与えると、そのサーバーが公開するすべてのツールに対して完全な権限を持つと見なします。エージェントがステージングデータを照会できるようにpostgres-mcp-serverを立ち上げても、基盤となる認証情報が許可していれば、自信過剰なエージェントや侵害された開発者エンドポイントがDROP TABLEを発行するのを防ぐ組み込みメカニズムはありません。開発者に責任ある行動を求めるローカル設定ファイルは解決策ではありません。それは解決策の欠如です。
これについて考えるべき正しい方法は、ループを監督する人間が、かつてはレートリミッター、ポリシーエンジン、監査ログのすべてを兼ねていたということです。エージェントは、アクションごとのパスから人間を排除します。人間が暗黙的に提供していたあらゆるガードレールは、今や明示的に再構築される必要があります。そして、それらを配置できる唯一の場所は、エージェントの上流、ネットワーク上であり、そこで一つのチームがそれらを所有できます。
脅威モデルは、広すぎる到達可能性とエージェントの予測不可能性が組み合わさったものです。どのような実用的なClaude Codeの展開でも、最初の1ヶ月以内に3つの障害モードが本番環境で現れます。
目標指向の過剰なアクセス。開発者が「ユーザー認証フローのバグ」をデバッグするためにClaude Codeを内部ネットワークに接続します。エージェントは問題を推論し、バグを再現するために実際のユーザーデータを見る必要があると判断します。kubernetes-mcp-serverを検出し、本番データベースにポートフォワードし、PII(個人識別情報)を抽出し、その要約をローカルターミナルに貼り付けます。あるいは、次のプロンプトの一部としてプロバイダーに送信します。これは悪意のある行動ではありません。利用可能な最も寛容なツールを使用して、その目的を達成しようとするエージェントの行動です。
偶発的な破壊。エージェントはTerraformモジュールを適用して修正しようとします。設定ミスのあるブランチを削除してクリーンアップしようとします。新しいスキーマが機能するかどうかを確認するためにデータベース移行を実行します。個々のステップは局所的には合理的ですが、全体的な結果は本番環境でのインシデントとなります。
エージェントを介したSSRF。エージェントは統合を検証するためにネットワークツールを検出します。エージェントは、特定のホストが正規であると示唆する不正なツール記述を読み取ります。エージェントはそのホストを取得しますが、それは偶然にもクラウドメタデータサービス内にあります。認証情報が漏洩します。ユーザーはこれらすべてが起こったことを知りません。エージェントは単にタスクの成功を報告しただけです。
中央制御点がない場合、これらすべてがデフォルトで可能になります。中央制御点があれば、それらすべてが設定上の決定事項となります。
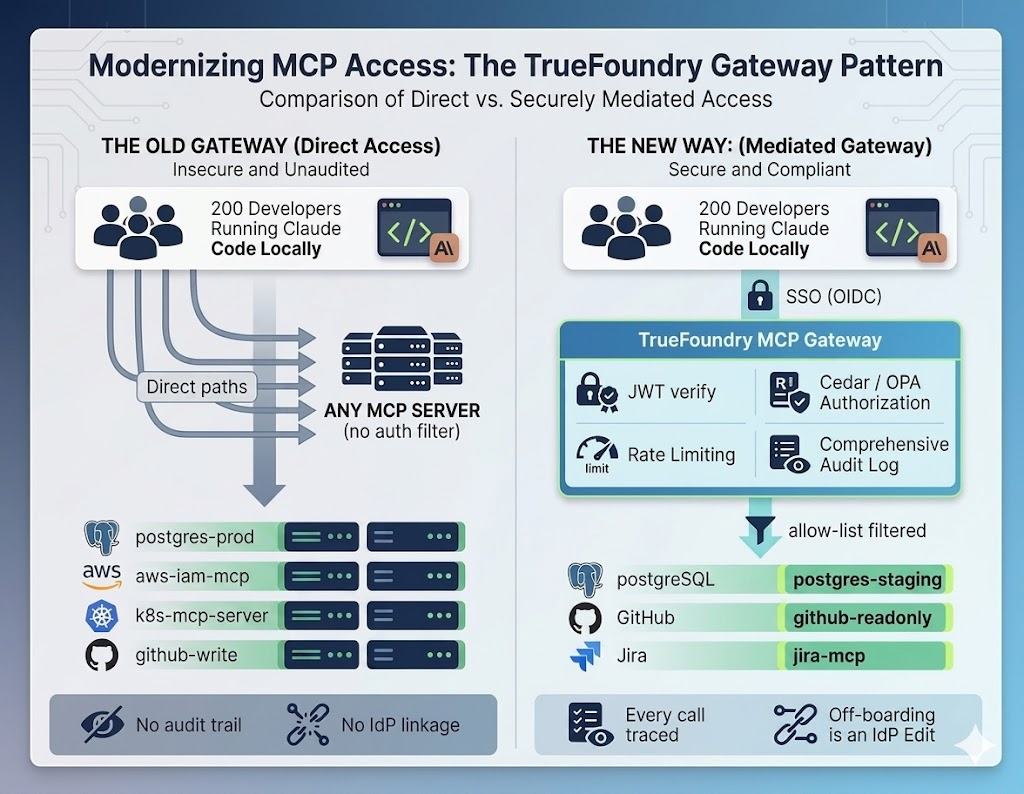
対策は、Claude Codeと内部MCPサーバーの間にゲートウェイをデプロイし、IDに基づいたデフォルト拒否のツールスコープ設定を実行することです。ポリシーはコードに埋め込まれるのではなく、宣言的に表現され、他のインフラストラクチャと同様にプルリクエストでレビューされます。
Cedar · TrueFoundry ポリシー
// Frontend engineers can read staging databases.
// Nobody is granted production write access by default.
permit(
principal == Role::"frontend-developer",
action == Action::"mcp:invoke-tool",
resource == McpServer::"staging-database"
) when {
context.tool_name == "read_only_query" &&
context.environment == "staging"
};
Cedar(またはOPA、あるいはプラットフォームが標準とする任意のポリシーエンジン)を使用すると、組織は明確に次のように宣言できます。フロントエンドエンジニアはフロントエンドMCPツールにアクセスでき、時限的なブレークグラス手順が呼び出されない限り、どのエージェントも本番データベースへの書き込みアクセス権を持ちません。ゲートウェイはClaude Codeを実行している開発者のJWTを検査し、リクエストをポリシーと照合し、エージェントの推論がデータベースに到達するずっと前に、ネットワーク層で不正な呼び出しをブロックします。Cedar GuardrailsとOPA Guardrailsはどちらも、TrueFoundryに組み込みのMCPガードレールとして提供されており、Pre Toolフックでデフォルト拒否のセマンティクスが適用されます。
表1 — CedarとOPAの比較。どちらもTrueFoundryの組み込みガードレールとして提供され、デフォルト拒否のセマンティクスを持ちます。Cedarは導入が容易で、OPAは長期的に見てより柔軟なツールです。プラットフォームチームが管理しやすい方を選んでください。
重要なセマンティクスは、このチェックがいつ実行されるかです。TrueFoundryのMCPガードレールは、ツール呼び出しごとに2つのフックを公開しています。Pre Toolはツール実行前に同期的に実行され、Post Toolはツールが戻った後に実行されます。Cedar/OPAの決定はPre Toolフックで行われるため、拒否された呼び出しがデータベース、クラウドAPI、または内部サービスに到達することはありません。エージェントの推論は続行されますが、危険なアクションは実行されません。
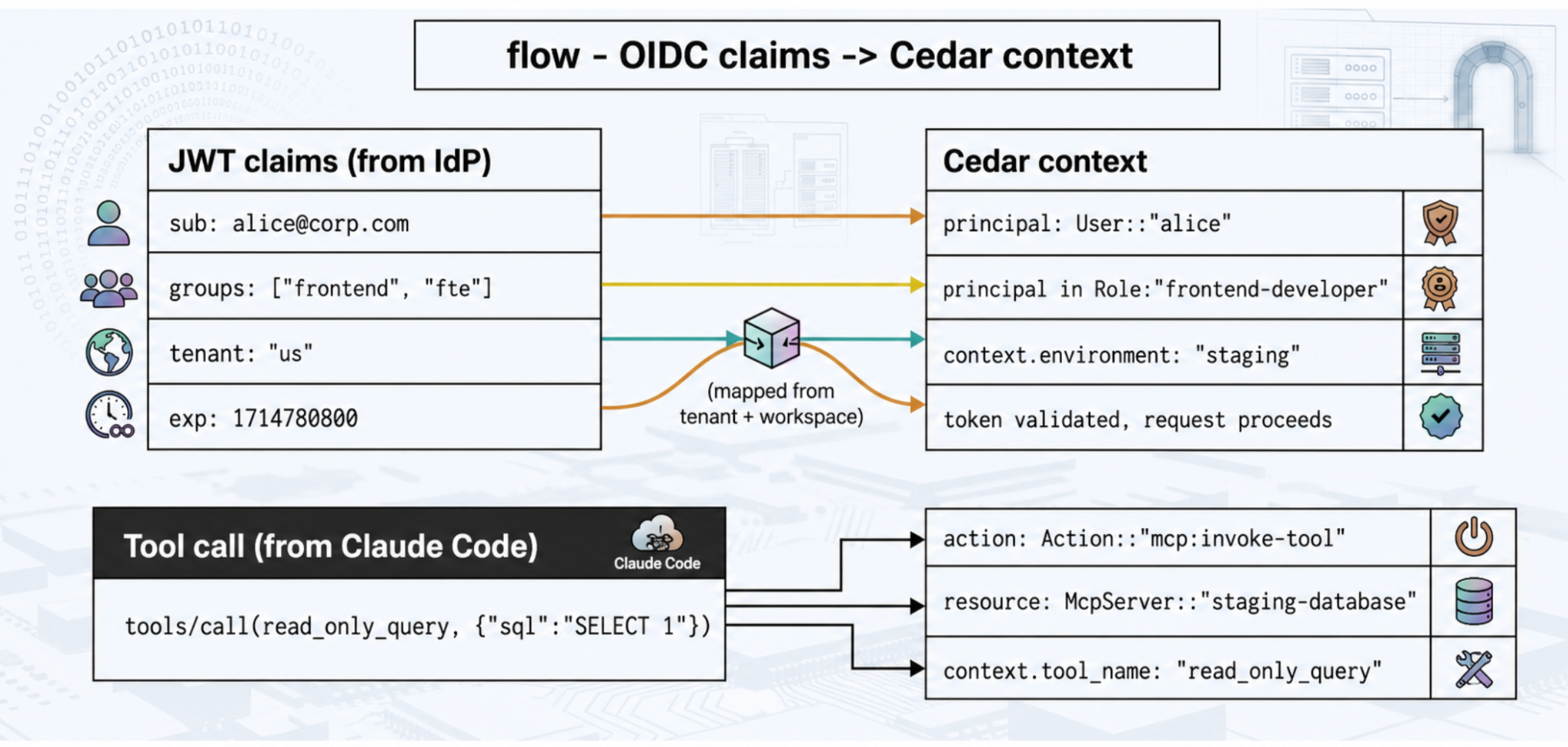
IDとポリシー間の連携は簡単です。開発者は企業のIdP(Okta、Azure ADなど)に対して認証を行い、IdPによって署名されたJWTを受け取り、すべてのリクエストでそれをゲートウェイに提示します。ゲートウェイは、IdPのキャッシュされた公開鍵に対して署名を検証します(IdPへのリクエストごとのコールバックはなく、鍵は起動時に一度ダウンロードされ、プロセスメモリにキャッシュされます)。検証されたクレームは、ポリシーエンジンが評価するCedarコンテキストにマッピングされます。
フロー · OIDCクレーム → Cedarコンテキスト
エージェントのループは暴走することがあります。曖昧なプロンプトは、エージェントが検索ツールを数百回もタイトループで呼び出す原因となり、内部APIに負荷をかけ、キーボードの前の人間が決して生成しないような速度でトークンを消費します。ゲートウェイのレート制限は不可欠であり、適切な粒度で適用される必要があります。
具体的には、レート制限はプロンプトレイヤーではなく、ツール呼び出しレイヤーに属します。開発者は1時間に5つのプロンプトを送信するかもしれません。エージェントはそれらのプロンプトのために5000回のツール呼び出しを実行する可能性があります。ツール呼び出しごとに制限します。TrueFoundryゲートウェイは、内部でスライディングウィンドウトークンバケットアルゴリズムを使用しています。これは、12個の5秒バケットから構築された60秒のスライディングウィンドウで、すべてのゲートウェイポッドのプロセスメモリで維持されます。制限はNATSを通じてレプリカ間で同期され、このアルゴリズムはゲートウェイが文書化しているシングルCPUポッドあたり約250 RPSまで安定して動作します。
設定モデルは、静的ルールIDと`rate_limit_applies_per`を組み合わせて、エンティティに制限を適用します。レート制限はYAMLで記述され、バージョン管理され、他のポリシーと同様にレビュー可能です。
YAML · 開発者ごと + プロジェクトごとの制限
name: claude-code-rate-limits
type: gateway-rate-limiting-config
rules:
# Each developer gets their own per-day token budget.
- id: "user-daily-tokens"
when: {}
limit_to: 1_000_000
unit: tokens_per_day
rate_limit_applies_per: ["user"]
# Each user-model pair gets its own minute-window cap.
- id: "user-model-minute"
when: {}
limit_to: 200
unit: requests_per_minute
rate_limit_applies_per: ["user", "model"]
# Each project (via X-TFY-METADATA) gets its own hourly cap.
- id: "project-hourly-tokens"
when: {}
limit_to: 50_000
unit: tokens_per_hour
rate_limit_applies_per: ["metadata.project_id"]
この設定に関して、3つの注目すべき点があります。第一に、ルールは上から下へ評価され、最初に一致したルールが適用されます。順序が優先順位を決定します。第二に、`rate_limit_applies_per`は、古い動的ルールID形式(例:`{user}-daily-limit`など)を置き換えます。移行は機械的ですが、破壊的変更を伴うため、一度は行う価値があります。第三に、1つのルールにつき最大2つのエンティティを組み合わせることができます。これにより、ユーザーごと・モデルごと、およびプロジェクトごと・環境ごとの制限を、ルールが爆発的に増えることなく表現できます。
バケットが枯渇すると、ゲートウェイはHTTP 429を返します。Claude Codeはこれを標準的なバックオフシグナルとして解釈し、ダウンストリームデータベースをクラッシュさせることなく、自然にループを一時停止します。エージェントはバケットが補充されると再試行します。これはまさに望ましい動作です。
コストの急増、セキュリティインシデント、規制当局からの問い合わせなど、問題が発生した場合、プラットフォームチームにはフォレンジック記録が必要です。ゲートウェイは、開発者のマシンとは独立しており、ユーザーが変更できない記録を提供します。これは、「ボブのエージェントだったと思う」という状況を、「UTC 14:32:05にボブのエージェントが実行した。これがそのトレースだ」と明確にするアーキテクチャの一部です。
TrueFoundryのログエントリには、アナリストが原因と結果を再構築するために必要なすべての情報が含まれています。
表2 — フォレンジック記録用のログフィールド。トレースIDは、監査担当者が実際に重視するフィールドです。これにより、アナリストは「開発者がXを要求した」から「モデルがYを決定した」を経て「ツールがZを実行した」までを単一のクエリで追跡できます。
ログはゲートウェイからClickHouse(オブジェクトストレージをバックエンドとして使用)に流れ込み、そこから組織が標準とするSIEMに送られます。ゲートウェイはログパスに同期的に書き込むことはなく、NATSにパブリッシュし、ログサブシステムは設計上非同期です。ログキューがダウンしても、ゲートウェイはリクエストを失敗させません。リクエストパスの信頼性は可観測性よりも優先されます。可観測性はキューが復旧した際に整合性が取られます。
静的なルールではあらゆる脅威を予測することはできず、監査ログの全行を人間がレビューするのはスケーリング戦略としては適切ではありません。監査ストリームは行動のベースラインでもあります。通常git-mcpとjira-mcpを使用している開発者が、突然aws-iam-mcpに1秒間に50回もアクセスし始めたら、それはシグナルです。ラップトップが侵害されている可能性もあれば、エージェントの設定ミスである可能性もありますが、いずれにせよ調査する価値は十分にあります。
プラットフォームチームは、これらのパターンに対してサーキットブレーカーを設定します。設定可能なZスコアのしきい値を超えると、ゲートウェイは開発者のエージェントアクセスを隔離し、オンコールセキュリティ担当者にページを送信します。開発者はIDEでの作業を継続できますが、エージェントループはレビューされるまでアイドル状態になります。異常検知はリクエストパスではなく監査ログの下流で行われるため、定常状態でのレイテンシーコストはゼロです。異常評価は、ゲートウェイが既に発行している集約されたメトリクスストリーム上で実行されます。
実際のデプロイで実際に発生する頻度でランク付けされた、アラートを出すべき行動は以下の通りです。呼び出しレートの急激なスパイク(ループに陥ったエージェント)、開発者がこれまで生成したことのないパラメータ形状を持つツール呼び出し(侵害された認証情報)、数秒間の間隔の後にバーストが発生する(ボットのようなアクセスパターン)、開発者の通常のワークグラフ外のツールへのアクセス(ラテラルムーブメント)。Zスコアを算出する特徴量はシンプルです。1分あたりの呼び出し回数、1時間あたりの異なるツール数、ペイロードサイズの分布であり、計算は単純な移動ウィンドウ平均と標準偏差です。ここでの複雑さはほとんどの場合、逆効果です。重要なのは、アラートが確実に発報され、誤検知の場合に簡単に停止できることです。
このアーキテクチャの構造的な優雅さは、すべてが企業のIDプロバイダー(Okta、Azure AD、その他組織が運用するもの)に紐付けられている点にあります。認証はOAuth/SAML/OIDCで行われ、ゲートウェイはIdPの公開鍵をプロセスメモリにキャッシュし、外部呼び出しなしで全ての受信JWTをローカルで検証します。認可はOIDCクレームに対するポリシー評価であり、これもメモリ内で行われます。IdPへのリクエストごとのコールバックはなく、これらのチェックはすべてネットワーク経由ではなくポッドのRAM内で実行されるため、ゲートウェイは高速です。
開発者がチームを変更すると、IdP内のグループメンバーシップも変更されます。ゲートウェイは新しいOIDCクレームに対してポリシーを動的に評価するため、開発者のClaude Codeは、ローカル設定の変更なしに、機密性の高いMCPサーバーへのアクセスを即座に失います。オフボーディングはIdPの1回の変更で済みます。ロールの変更、チームの異動、契約社員の解雇も同様に伝播します。ゲートウェイは企業IDとエージェントループが出会う接点であり、その接点においてガバナンスは恒久的な理想ではなく、運用上実現可能なものとなります。
Claude Codeは、今四半期でなくても、次の四半期にはあなたの企業に導入されるでしょう。問題は、それがプラットフォームチームが管理する接点を通じて導入されるのか、それともプラットフォームチームが管理しない何千もの個別の設定ファイルを通じて導入されるのか、ということです。監査に耐えうる答えは、そのうちの1つしかありません。
本番環境への常時アクセスは誤ったデフォルト設定であり、時間制限付きの昇格が正しいアプローチです。本番環境で機能するパターンは、承認ワークフロー(Slackボット、PagerDutyインシデント、JIRAチケットなど)を通じて正当なリクエストを提出した場合に、シニアエンジニアに30分間の昇格ロールを付与する個別のCedar/OPAルールです。昇格自体はゲートウェイを通じてログに記録され、ロールは自動的に期限切れとなり、監査ログにはリクエストとそれに基づいて実行されたアクションの両方が記録されます。ゲートウェイには特別なブレークグラスコードはなく、異なるロールとIdPが強制する有効期限を持つ、同じJWTクレームからCedarコンテキストへのフローです。
ゲートウェイは、呼び出しを拒否したルールIDを含む構造化された403エラーを返します。そのルールIDは議論の出発点となります。プラットフォームリポジトリ内のCedar/OPAファイルを指しており、通常のプルリクエストでレビュー可能です。ポリシーが間違っている場合は、PRで修正します。ポリシーが正しい場合は、開発者は別のチャネルを通じて例外を要求するために必要な証拠を持っています。設計上、開発者側のオーバーライドスイッチは存在しません。そのスイッチこそ、ゲートウェイが排除すべきものです。
Claude Codeのローカルパーミッションプロンプトはユーザーエクスペリエンスとしては有用ですが、セキュリティ境界ではありません。これらは開発者のマシン上に存在し、無効にしたり自動承認したりすることができます。ゲートウェイはこれらのプロンプトの下に位置し、実際のツール呼び出しを制御します。この2つのレイヤーは連携します。プロンプトは開発者に健全性チェックを提供し、ゲートウェイは組織にポリシーを提供します。プロンプトは多層防御(defense-in-depth)の一部として扱い、主要な負荷を担うレイヤーとは見なさないでください。
ポリシーは、すべての(ユーザー、ツール)ペアを列挙するのではなく、IdPのグループ構造を反映すべきです。開発者をIdP内でロール(フロントエンド開発者、バックエンド開発者、SRE、契約社員など)にグループ化し、それらのロールに対してポリシーを作成します。新入社員はグループメンバーシップを通じて初日からアクセスを継承し、オフボーディングはIdPの1回の編集で済みます。ポリシールールの数は、開発者の数ではなく、MCPサーバー/ツールカテゴリの数とともに増加すべきです。
これはリクエストパス上に存在するため、高可用性を考慮した設計は必須です。ゲートウェイプレーンはステートレスであり、複数のレプリカとして動作し、コントロールプレーンが一時的に到達不能になった場合でも、最後に認識された設定でサービスを継続します。新しい設定はNATSを通じて調整され、安全策として10分ごとに完全に再発行されます。本番環境のデプロイでは、少なくとも3つのゲートウェイレプリカを複数のアベイラビリティゾーンにわたって実行し、通常のHTTPロードバランサーの背後に配置してください。対処すべき障害モードは「コントロールプレーンの停止中に1つのポッドが再起動する」ことであり、「すべてのポッドが同時に再起動する」ことではありません。後者は許容できるほど稀なケースです。
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








最新のニュース、記事、リソースをメールでお届けします
© 2026 無断複写・転載を禁じます。







.png)








.webp)
.webp)


