













.webp)
July 4, 2026
|
5 min read

Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
CartesiaのSonic-3.5テキスト読み上げモデルとInk-2ストリーミング音声認識モデルは、ネイティブパススルーインターフェースを介してTrueFoundry AI Gatewayと統合されます。リクエストは、元のプロトコルセマンティクスを維持したまま、Cartesiaの/tts/bytes HTTPエンドポイント、/tts/sseサーバー送信イベントストリーム、/tts/websocket双方向WebSocket、およびInkストリーミングWebSocketに流れます。ゲートウェイは、中央の認証情報ストアからCartesia APIキーを挿入し、アクセス制御を実行し、接続を転送する前にOpenTelemetryスパンを発行します。
この記事では、なぜ音声推論プロバイダーが、ゲートウェイがチャット補完プロバイダーに適用するOpenAI互換の変換パターンを使用できないのかを説明します。ゲートウェイプレーンが既存のHonoリクエストパイプライン内でネイティブパススルーをどのように処理するかを解説します。TTSとSTTの両方におけるCartesiaのAPIサーフェスについて説明します。設定の形式とエンドツーエンドのデータフローについて説明します。
ほとんどのTrueFoundry AI Gateway統合は、変換原則に基づいて動作します。リクエストは、/chat/completions、/embeddings、または/responsesでOpenAI互換形式で到着します。ゲートウェイは、モデル識別子をプロバイダーエンドポイントに解決し、アダプターを介してリクエストをそのプロバイダーのネイティブ形式に変換します。AnthropicはMessages APIに変換されます。Google VertexはGenerative Language APIに変換されます。Cohereはネイティブチャットスキーマに変換されます。応答は返送され、逆変換されるため、呼び出し元は、どの物理プロバイダーがリクエストを処理したかに関わらず、統一されたOpenAI形式を確認できます。
このパターンが機能するのは、チャット補完のセマンティクスがプロバイダー間でほぼ同等であるためです。メッセージのリスト、モデル識別子、サンプリングパラメータ、ストリーミングフラグ、ツール呼び出しと終了理由を含む応答があります。違いは存在するものの、限定的であり、アダプター内で調整可能です。
音声推論は、この型には当てはまりません。CartesiaのTTS APIには、OpenAI Audio APIに相当するパラメータがありません。voiceフィールドは、Cartesiaの音声IDまたは音声埋め込みを受け入れます。output_formatブロックは、コンテナ、エンコーディング、サンプルレートを構造化オブジェクトとして指定します。languageフィールドは、42のサポート言語から選択します。__experimental_controlsブロックは、Sonic-3.5の表現制御にマッピングされる速度と感情のパラメータを保持します。WebSocketプロトコルは、多重化されたコンテキスト、flush_id境界、およびアップストリームLLMからのストリーミングテキスト入力のための継続セマンティクスを導入します。これらのいずれも、OpenAIの/v1/audio/speech形式には存在しません。
Ink-2 STTパスも同様です。ストリーミングWebSocketプロトコルは、オーディオフレームをリアルタイムで渡し、モデルがネイティブのターン検出を通じて意味的に意味のあるターン境界を検出すると、中間トランスクリプトと最終トランスクリプトを発行します。OpenAIの/v1/audio/transcriptionsエンドポイントは、公式仕様にストリーミングの対応物がないリクエスト応答ファイルアップロードです。
このサーフェスを変換すると、機能が失われるか、損失のあるマッピングが導入されることになります。したがって、ゲートウェイはCartesiaをネイティブパススルーを介して公開します。呼び出し元は、公式のCartesia Python SDKまたはその他のCartesiaクライアントをその全機能セットで引き続き使用できます。ゲートウェイは、プロトコル変換器としてではなく、認証情報、ポリシー、および可観測性の境界としてパスに存在します。
TrueFoundry AI GatewayはHonoフレームワーク上に構築されています。1 vCPUと1 GB RAMを搭載した単一のゲートウェイポッドは、約3ミリ秒の追加レイテンシで250以上のRPSを処理します。ポッドはステートレスでCPUバウンドであり、水平方向に数万RPSまでスケールします。ゲートウェイプレーンとコントロールプレーンは分離されています。コントロールプレーンはPostgreSQLとClickHouseで構成を管理し、NATSを介して更新を伝播します。ゲートウェイポッドは、その構成をメモリにキャッシュします。
Cartesiaリクエストがゲートウェイポッドに到達すると、チャット補完の場合と同じ転送前パイプラインが実行されます。リクエストで提示されたJWTは、外部認証呼び出しなしでキャッシュされたIdP公開鍵に対して検証されます。認証は、NATSが同期を維持するユーザーとモデルのインメモリマップに対してチェックされます。ルーティングレイヤーは、モデル識別子(sonic-3.5やink-2など)を、そのモデル用に構成されたプロバイダーエンドポイントと、コントロールプレーンに保存されているCartesiaアカウント認証情報に解決します。リクエストボディ、パス、クエリパラメータは書き換えられません。インバウンドリクエストからAuthorizationおよびX-API-Keyヘッダーのみが削除され、セキュアな認証情報ストアからのCartesia APIキーに置き換えられます。転送されるURLは、一致するパスとメソッドが保持されたまま、Cartesiaオリジン(https://api.cartesia.ai/...)になります。ボディは変更されずにストリーミングされます。
WebSocketエンドポイント(wss://api.cartesia.ai/tts/websocketおよびInkストリーミングエンドポイント)の場合、ゲートウェイはHTTPアップグレードハンドシェイクを実行します。アップグレードが成功すると、ゲートウェイは2つのWebSocket接続(1つはクライアントと、もう1つはCartesiaと)を保持し、両方向にフレームをプロキシします。ゲートウェイはフレームペイロードを解釈しないため、Cartesiaが公開する多重化されたコンテキストモデルは保持されます。単一のWebSocketを開き、異なるcontext_id値に対して数十の同時生成を実行するクライアントは、Cartesiaと直接通信する場合と同じ動作をゲートウェイを介して確認できます。
ゲートウェイがチャット補完に使用する非同期トレース公開パスは、Cartesiaトラフィックに対しても実行されます。ゲートウェイは、インバウンドHTTPハンドラー、認証情報解決、およびアウトバウンドプロバイダー呼び出し(またはWebSocketセッション)のスパンを発行します。TTSリクエストの場合、これらのスパンには期間、ステータス、解決されたモデル名、およびトランスクリプトのハッシュが含まれます。STTセッションの場合、スパンは接続のライフタイムとメッセージ数をキャプチャします。スパンは、リクエスト完了後にNATSに非同期で公開されます。OpenTelemetryエクスポーターは非同期パスから読み取り、構成されたバックエンド(gRPCまたはHTTP)にトレースを転送します。エクスポートは追加的であり、ゲートウェイ自身のトレースストレージを変更しません。外部のOTELエンドポイントに到達できない場合でも、ゲートウェイがCartesiaリクエストを失敗させることはありません。
コスト追跡パイプラインもパススルーモードで実行されます。Cartesiaはクレジットに基づいて課金され、これはTTSの合成文字数とSTTの転写秒数に換算されます。ゲートウェイは、リクエストサイズと応答期間のメタデータを記録し、これらをチャット補完コストデータを集約するのと同じNATSイベントバスに公開します。アグリゲーターサービスは、ユーザーごと、チームごと、モデルごとのロールアップを計算し、チャットトラフィックと並んで統合分析ビューに表示されます。
Cartesiaは、状態空間モデルアーキテクチャに基づいて音声モデルを構築しています。TTSファミリーはSonicと名付けられ、現在の本番モデルはSonic-3.5です。STTファミリーはInkと名付けられ、現在の本番モデルはInk-2です。
Sonic-3.5は、90ミリ秒未満の初回オーディオ出力時間と42言語のネイティブサポートを備えたストリーミングTTSモデルです。自然さでNo.1にランクされており、電話番号、ID、メールアドレスなどの英数字を前処理なしで正確に発音し、周囲の文脈からreadやbassのような英語の異形同音異義語を処理します。APIパラメータとSSMLタグを介して、音量、速度、感情のきめ細かな制御を公開しています。このモデルは、異なるユースケースに適した3つのエンドポイント形式で公開されています。
1つ目はPOST /tts/bytesです。これは、応答ボディにオーディオファイル全体を返す同期バッチエンドポイントです。MP3、WAV、またはraw PCM出力形式を受け入れ、完全な出力が完了するまでの全レイテンシが許容されるオーディオアセットの事前生成に適しています。
2つ目はPOST /tts/sseです。これはサーバー送信イベントストリームです。モデルは、生成されるにつれてオーディオチャンクを段階的に発行します。これは、オーディオを段階的に再生し、最初のバイトまでの時間という利点を必要とするが、入力テキストをモデルにストリーミングする必要がないアプリケーションに適しています。
3つ目はWSS /tts/websocketです。これはリアルタイム音声エージェントに推奨されるエンドポイントです。接続は双方向で、context_idフィールドを介した多重化された生成をサポートします。1つの開かれたWebSocketで、数十の同時生成を処理できます。context_idは、既存のコンテキストに追加のテキストセグメントをプッシュして、結合部全体でプロソディを維持する継続生成を可能にします。これは、アップストリームのテキストソースがLLMによってトークンごとにストリーミングされ、TTSがテキスト生成の調子に合わせる必要がある場合に重要です。WebSocketプロトコルは、単一のコンテキスト内で個別のオーディオ境界を作成するflush_idマーカーによる手動フラッシングもサポートしています。
Ink-2は、プロダクション音声エージェント向けにゼロから構築されたストリーミングSTTモデルです。あらゆるストリーミングSTTの中で最も低い単語誤り率と最高のターン検出を誇り、電話番号、日付、メールアドレスなどの構造化データを最初のパスで正確に書き起こします。その決定的な機能は、ネイティブのターン検出です。Ink-2は、別途VADを必要とせずに話者がいつ開始し終了するかを認識し、ターンイベントの完全なライフサイクル(turn.start、turn.update、turn.eager_end、turn.resume、turn.end)を発行するため、エージェントはいつ聞き、考え、応答すべきかを正確に把握できます。セマンティックエンドポインティングは、沈黙ではなく意味によってターンの終了を決定するため、思考途中のポーズがエージェントを時期尚早にトリガーすることはありません。一方、turn.eager_endは、ターンが完了と確認される前にダウンストリームのLLMに先行開始を促します。このエンドポイントは、16 kHzのPCMオーディオフレームを受け入れ、モデルがコミットするにつれて中間および最終の書き起こしを発行するストリーミングWebSocketです。デフォルトのオーディオエンコーディングは、16000 Hzのpcm_s16leです。
Cartesiaは、3分間の非アクティブ状態の後、WebSocket接続を切断します。タイムアウトは、どちらかの方向にフレームが送信されるたびにリセットされます。クライアントは通常、発話間のギャップで接続を維持するために、サイレンスベースのキープアライブを実行します。
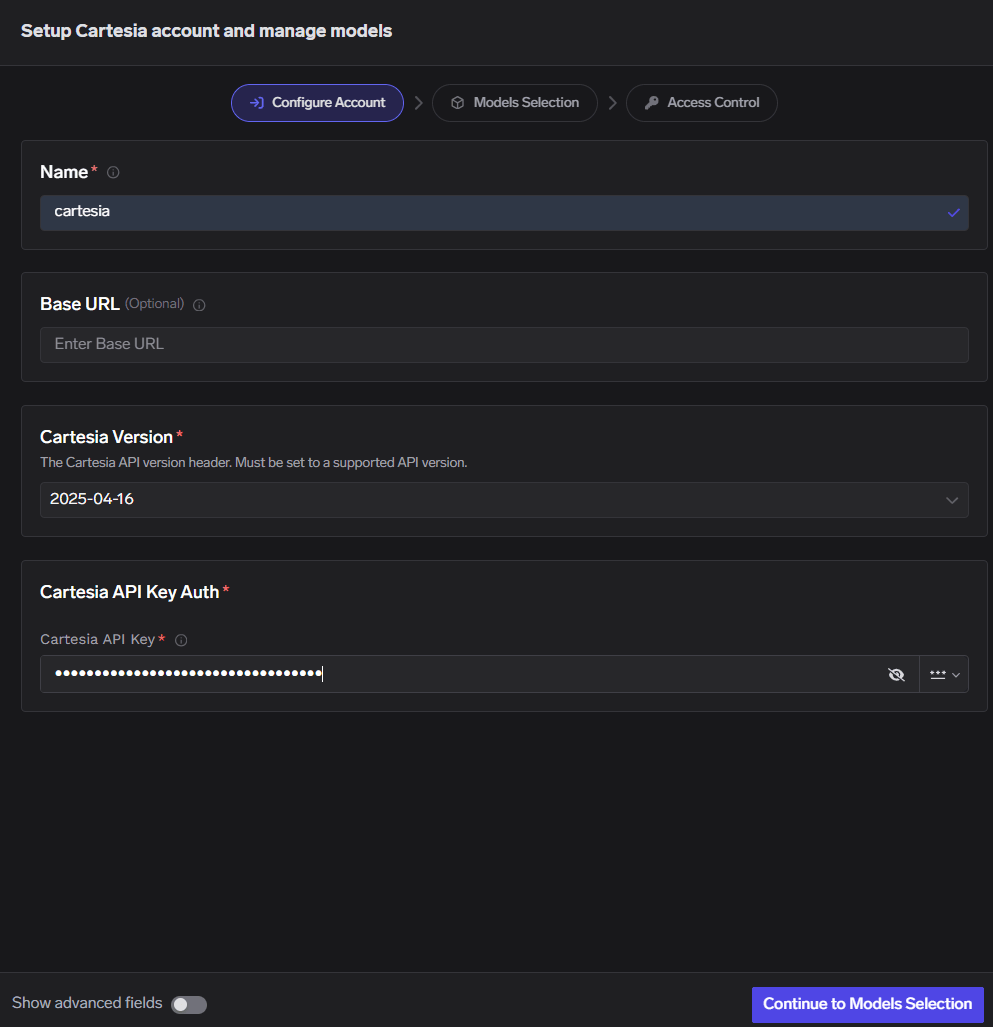
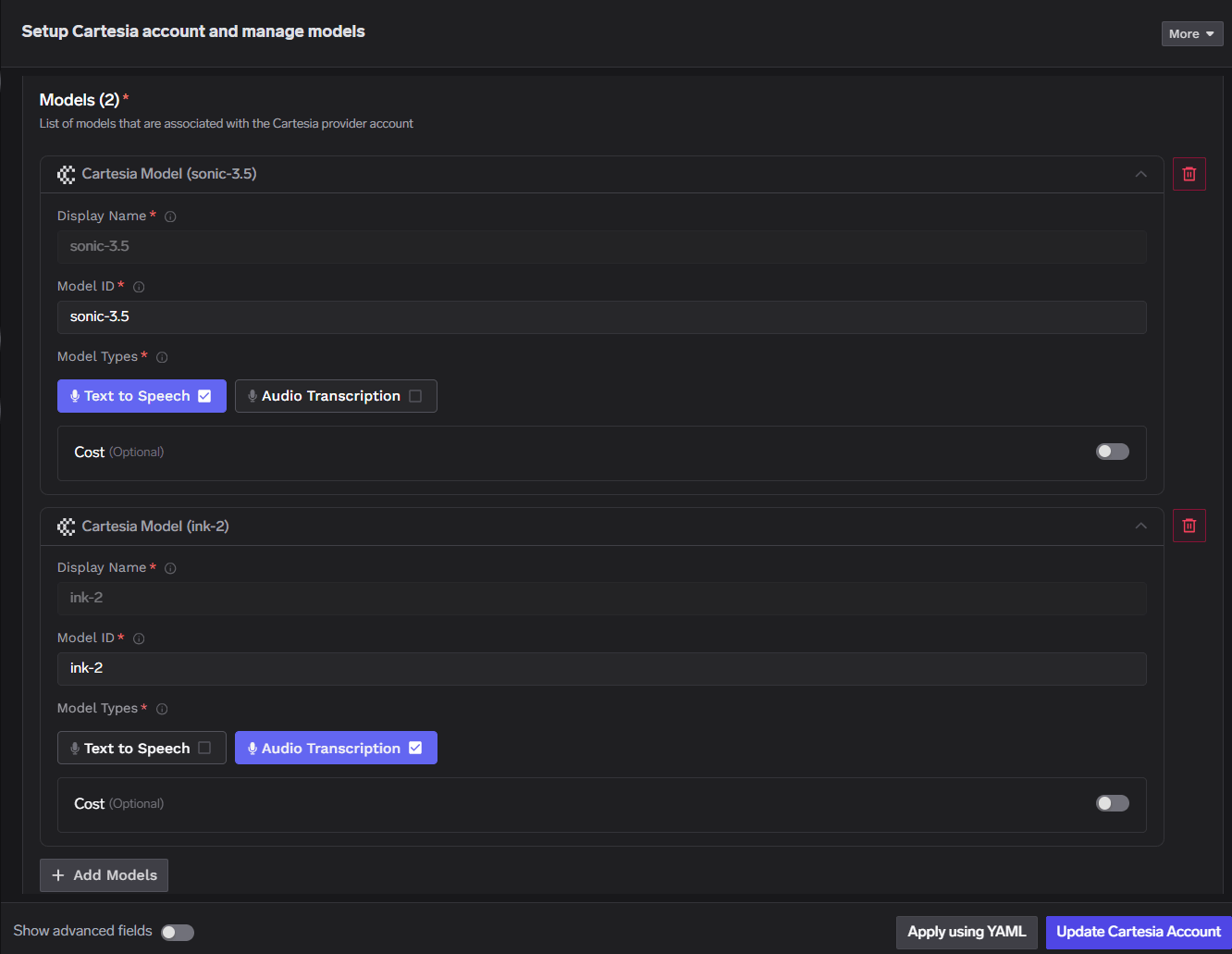
TrueFoundry AI GatewayにCartesiaを追加するには、ダッシュボードで3つのステップが必要です。AI Gatewayに移動し、次に「Models」を選択し、「Cartesia」を選択します。一意のアカウント名とCartesia APIキーを入力して、Cartesiaアカウントを追加します。キーはコントロールプレーンに暗号化されて保存され、ゲートウェイポッドに直接公開されることはありません。オプションで、このアカウントを介してトラフィックをルーティングできるユーザーとチームを制御するコラボレーターを追加します。次に、「Add Model」をクリックし、表示名、モデルID、モデルタイプを指定して、1つ以上のモデルを登録します。Cartesiaの場合、モデルIDと表示名は同一である必要があり、Cartesiaモデル識別子(sonic-3.5、ink-2など)と完全に一致する必要があります。
Cartesiaアカウントの設定インターフェースはシンプルです。
推論は、ゲートウェイURLをベースURLとして置き換えたCartesiaネイティブSDKを使用します。Pythonクライアントは次のようになります。
import os
from cartesia import Cartesia
client = Cartesia(
api_key=os.environ["TFY_API_KEY"],
base_url="https://<your-gateway-host>/cartesia",
)
response = client.tts.bytes(
model_id="sonic-3.5",
transcript="The road goes ever on and on.",
voice={"mode": "id", "id": "6ccbfb76-1fc6-48f7-b71d-91ac6298247b"},
output_format={"container": "wav", "encoding": "pcm_f32le", "sample_rate": 44100},
)
同じSDK呼び出しは、WebSocketエンドポイントとInk-2 STT WebSocketの両方で機能します。TrueFoundryが発行したJWTが、SDK設定のCartesia APIキーを置き換えます。ゲートウェイがURLパスと応答形状を保持するため、SDKはCartesiaと直接通信していると認識します。コスト、アクセス制御、およびトレースはすべて、リクエストパス内で目に見えない形で実行されます。
エンドツーエンドのデータフローはシンプルです。クライアントはCartesia SDKを使用して、ゲートウェイURLに対してHTTPリクエストまたはWebSocketを開きます。ゲートウェイポッドは、キャッシュされたIdP公開鍵に対してJWTを認証し、モデル識別子を設定済みのCartesiaアカウントに解決します。受信認証ヘッダーを削除し、クレデンシャルストアからCartesia APIキーを置き換えます。リクエストを転送するか、WebSocketをhttps://api.cartesia.aiにアップグレードします。WebSocketセッションの場合、どちらかの側が接続を閉じるまで、両方向でフレームをブリッジします。リクエストが完了すると、ゲートウェイはスパンをNATSに公開し、それがOTELエクスポーターとコストアグリゲーターに供給されます。
不要なものが、このシステムの重要な特徴です。Cartesia SDKのフォークはありません。TTSパラメータをOpenAI Audioの形状に平坦化し、その過程で音声IDとストリーミングコンテキストモデルを失うシャドウ変換レイヤーはありません。音声トラフィックとチャットトラフィックで別々のトレースパイプラインはありません。アプリケーションコード全体に分散されたサービスごとのAPIキーはありません。ストリーミングエンドポイントにアクセス制御を適用するために別途デプロイする必要があるクライアント側のWebSocketターミネーターはありません。
これを可能にするアーキテクチャ原則は、プロトコルセマンティクスとガバナンスセマンティクスの分離です。Cartesiaプロトコルは、他のプロバイダーにきれいに一般化できない音声ドメインの意味を伝達します。ガバナンスレイヤー(認証、認可、クレデンシャル注入、可観測性、コスト追跡)はプロバイダーに依存せず、ペイロードを検査することなく、あらゆるHTTPまたはWebSocketオリジンの前で実行できます。ネイティブパススルーは、後者を適用しながら前者を保持します。その結果、Cartesiaの全機能(Sonic-3.5のコンテキスト、継続、感情制御、Ink-2のストリーミング書き起こしフロー)がクライアントに利用可能になり、AI Gatewayの残りの部分がチャットトラフィックに提供する運用保証が、同じゲートウェイポッド、同じコントロールプレーン、同じトレースおよびコストバックエンドで音声トラフィックにも適用されます。
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








最新のニュース、記事、リソースをメールでお届けします
© 2026 無断複写・転載を禁じます。







.png)








.webp)
.webp)


