Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.
Les volumes fournissent un stockage permanent aux conteneurs au sein des pods afin qu'ils puissent lire et écrire des données sur un disque central sur plusieurs pods. Ils sont particulièrement utiles dans le domaine de l'apprentissage automatique lorsque vous devez stocker et accéder à des données, à des modèles et à d'autres artefacts nécessaires aux tâches de formation, de diffusion et d'inférence.
Dans ce blog, nous verrons comment utiliser les volumes et les options disponibles dans chaque cloud.
Quand utiliser les volumes Kubernetes ?
Voici quelques cas d'utilisation où les volumes s'avèrent très utiles :
Partagez les données d'entraînement : Il est possible que plusieurs data scientists s'entraînent sur les mêmes données, ou que nous menions plusieurs expériences en parallèle sur le même ensemble de données. La méthode la plus naïve serait de dupliquer les données pour plusieurs data scientists, mais cela finira par nous coûter beaucoup plus cher. Un moyen plus efficace serait de stocker les données d'entraînement dans un volume et de monter le volume sur les carnets de différents data scientists.
Rangement du modèle : Si nous hébergeons des modèles sous forme d'API en temps réel, il y aura plusieurs répliques du serveur d'API pour gérer le trafic. Ici, chaque réplique doit télécharger le modèle depuis le registre des modèles (par exemple S3) sur le disque local. Si chaque réplica effectue cette opération à plusieurs reprises, le démarrage prendra plus de temps et entraînera également des coûts d'accès S3 plus élevés. À l'aide de volumes, vous pouvez stocker vos modèles entraînés en externe et les monter sur le serveur d'inférence. Il n'est pas nécessaire de télécharger le modèle ; le serveur API peut simplement trouver le modèle sur le disque sur le chemin monté.
Partage d'artefacts : Nous pourrions avoir un cas d'utilisation dans lequel la sortie d'un étage du pipeline doit être consommée par l'étape suivante. Par exemple, après avoir peaufiné un modèle, il se peut que nous devions l'héberger en tant qu'API uniquement à des fins d'expérimentation. Bien que nous puissions écrire le modèle dans S3, puis le télécharger à nouveau depuis S3, le processus de chargement/téléchargement du modèle prendra beaucoup de temps. Au lieu de cela, pour accélérer les expériences, le travail de réglage fin peut simplement écrire le modèle dans un volume, et le service d'inférence peut ensuite monter le volume avec le modèle.
Pointage de contrôle : Lors de la formation des modèles d'apprentissage automatique, il est courant de sauvegarder régulièrement des points de contrôle pour reprendre l'entraînement en cas de panne ou pour affiner les modèles. Les volumes peuvent être utilisés pour stocker ces fichiers de points de contrôle, afin de garantir que la progression de la formation ne soit pas perdue lorsqu'une tâche redémarre après un échec. Cela vous permet également d'organiser des sessions de formation sur place, ce qui vous permet de réduire considérablement les coûts.
Passons maintenant aux cas d'utilisation du ML. Dans la plupart des cas, les ingénieurs ML obtiennent les données dans S3 Bucket GCS Buckets ou Azure Blob Storage. Désormais, s'ils souhaitent entraîner des modèles à partir de ces données, ils doivent télécharger les données sur leur charge de travail de formation (tâche déployée ou ordinateur portable) ou monter le contenu de leur bucket directement sur la charge de travail.
Quand utiliser le stockage en volume par rapport au stockage Blob tel que S3/GCS/Azure Container ?
Il est important de choisir quand choisir un stockage blob tel que S3 par rapport au stockage en volume est important du point de vue des performances, de la fiabilité et des coûts.
Rendement
Dans la plupart des cas, la lecture de données depuis S3 sera plus lente que la lecture de données directement depuis un volume. Donc, si la vitesse de chargement est cruciale pour vous, le volume est le bon choix. Le téléchargement et le chargement du modèle au moment de l'inférence dans plusieurs répliques du service en sont un excellent exemple. Un volume est un meilleur choix car vous n'avez pas à télécharger le modèle à plusieurs reprises et vous pouvez charger le modèle en mémoire à partir du volume beaucoup plus rapidement.
Fiabilité
Les stockages blob tels que S3/GCS/ACS sont généralement plus fiables que les volumes. Vous devriez donc idéalement toujours sauvegarder les données brutes dans l'un des stockages blob et utiliser des volumes uniquement pour les données intermédiaires. Vous devez également enregistrer définitivement une copie des modèles dans S3.
Coût
L'accès à des volumes tels que EFS est un peu moins cher que l'utilisation de S3. Par conséquent, si vous recherchez les mêmes données assez fréquemment, il peut être utile de les stocker dans un volume. Si vous lisez ou écrivez très rarement, S3 devrait être parfait.
Contraintes d'accès
Les données en volumes ne devraient idéalement être accessibles que par les charges de travail d'une même région et d'un même cluster. S3 est conçu pour être accessible dans le monde entier et dans des environnements cloud. Les volumes ne constituent donc pas un excellent choix si vous souhaitez accéder aux données dans une région ou un fournisseur de cloud différent.
Modes de provisionnement des volumes
Pour prendre en charge tous les types de volumes, TrueFoundry propose deux modes de provisionnement de volumes adaptés à différents cas d'utilisation :
Dynamique
Il s'agit de volumes créés dynamiquement et provisionnés lorsque vous déployez un volume sur Truefoundry. Par exemple, EBS, EFS dans AWS et AzureFiles dans Azure peuvent être provisionnés dynamiquement sur Truefoundry.
Statique
Il s'agit de volumes pour lesquels un volume de stockage existe déjà et nous souhaitons intégrer les données de ce volume de stockage à notre service/travail. Les exemples incluent le montage de compartiments S3 et de compartiments GCS sur les charges de travail déployées sur la plate-forme.
Voyons donc comment ces deux solutions fonctionnent et quelles sont les options disponibles dans chaque cloud :
Volumes provisionnés dynamiquement
Les volumes provisionnés dynamiquement nécessitent que vous spécifiiez une classe de stockage. Un volume est provisionné dynamiquement en fonction de la classe et de la taille de stockage fournies par l'utilisateur.
Voyons donc ce qu'est une classe de stockage et les différentes classes de stockage disponibles dans chaque cloud :
Classes de stockage
Les classes de stockage permettent de spécifier le type de stockage qui doit être provisionné pour un volume. Ces classes de stockage diffèrent par leurs caractéristiques, telles que les performances, la durabilité et le coût. Vous pouvez sélectionner la classe de stockage appropriée pour votre volume dans le menu déroulant Classe de stockage lors de sa création.
Les classes de stockage spécifiques disponibles dépendent du fournisseur de cloud que vous utilisez et de ce qui est préconfiguré par l'équipe Infra. Les options suivantes apparaissent généralement dans les classes de stockage en fonction du fournisseur de cloud :
Classes de stockage AWS
TrueFoundry Storage Name
Cloud Provider Storage Name
Storage Class
Description
efs-sc
Elastic File System (EFS)
efs.csi.aws.com
A fully managed, scalable, and highly durable elastic file system that offers high availability, automatic scaling, and cost-effective general file sharing. It's suitable for workloads with varying capacity needs.
Classes de stockage GCP
TrueFoundry Storage Name
Cloud Provider Storage Name
Storage Class
Description
standard-rwx
Google Basic HDD Filestore
filestore.csi.storage.gke.io
A cost-effective and scalable file storage solution ideal for general-purpose file storage and cost-sensitive workloads. It offers lower cost but also lower performance due to its HDD-based nature.
premium-rwx
Google Premium Filestore
filestore.csi.storage.gke.io
Provides higher performance and throughput compared to Basic HDD, making it suitable for I/O-intensive file operations and demanding workloads. It's SSD-based, offering higher performance at a higher cost.
enterprise-rwx
Google Enterprise Filestore
filestore.csi.storage.gke.io
Delivers the highest performance, throughput, advanced features, multi-zone support, and high availability, making it ideal for mission-critical workloads and applications with strict availability requirements. It comes with the highest cost.
Classes de stockage Azure
TrueFoundry Storage Name
Cloud Provider Storage Name
Storage Class
Description
azurefile
Azure File Storage (Standard)
file.csi.azure.com
Uses Azure Standard storage to create file shares for general file sharing across VMs or containers, including Windows apps. It offers cost-effective performance.
azurefile-premium
Azure File Storage (Premium)
file.csi.azure.com
Uses Azure Premium storage for higher performance, making it suitable for I/O-intensive file operations.
azurefile-csi
Azure File Storage (StandardCSI)
file.csi.azure.com
Leverages Azure Standard storage with CSI for dynamic provisioning, potentially offering better performance and CSI features.
azurefile-csi-premium
Azure File Storage (PremiumCSI)
file.csi.azure.com
Combines Azure Premium storage with CSI for dynamic provisioning and high-performance file operations.
azureblob-nfs-premium
Azure Blob Storage (NFS Premium)
blob.csi.azure.com
Uses Azure Premium storage with NFS v3 protocol for accessing large amounts of unstructured data and object storage, catering to demanding workloads with NFS access.
azureblob-fuse-premium
Azure Blob Storage (Fuse Premium)
blob.csi.azure.com
Uses Azure Premium storage with BlobFuse for accessing large amounts of unstructured data and object storage, suitable for workloads that require BlobFuse access.
Volumes provisionnés de manière statique
Les volumes provisionnés de manière statique vous permettent de monter les éléments suivants en tant que volume :
Seau GCS
Seau S3
EFS existant
N'importe quel volume général sur Kubernetes
Pour utiliser des volumes provisionnés statiquement, vous devez créer un « PersistentVolume » qui fait référence à votre stockage (S3/GCS, etc.). Cela vous obligera à installer les pilotes CSI nécessaires sur le cluster et/ou à configurer les comptes de service appropriés pour les autorisations. Dans la section suivante, nous verrons comment créer des volumes provisionnés de manière statique.
Monter un seau GCS en tant que volume
Pour monter un bucket GCS en tant que volume sur Truefoundry, vous devez suivre les étapes suivantes. Vous pouvez vous référer à ceci document pour plus de détails :
Création d'un bucket GCS
Créez un compartiment GCS et assurez-vous de ce qui suit :
Doit être une seule région (plusieurs régions fonctionneront, mais la vitesse sera plus lente et les coûts plus élevés)
La région doit être la même que celle de votre cluster Kubernetes
Créez un compte de service et accordez les autorisations pertinentes
Vous devez exécuter le script suivant. Cela permet d'effectuer les opérations suivantes :
Active le pilote de fusible GCS sur le cluster
Créez une politique IAM pour accéder à votre bucket
Créez un compte de service K8s et ajoutez une politique à ce compte de service
Active la liaison de rôle du compte de service à l'espace de noms K8s souhaité.
Créer un compte de service dans Workspace à partir de l'interface utilisateur Truefoundry
Nous devons maintenant créer un compte de service sur TrueFoundry dans le même espace de travail avec le nom : TARGET_Namespace et le compte de service doit porter le nom GCP_SA_NAME.
Accédez à Espaces de travail -> Choisissez votre espace de travail, cliquez sur les trois points à droite et cliquez sur Modifier :
Ouvrez les options avancées en bas à gauche du formulaire et remplissez le Compte de service rubrique :
Remarque
Le nom du compte de service et l'espace de travail doivent être exactement les mêmes que ceux de l'étape précédente.
Création d'un objet PersistentVolume
Créez un objet de volume persistant en procédant comme suit. (en faisant un kubectl apply)
Pour monter un bucket S3 en tant que volume sur Truefoundry, vous devez suivre les étapes suivantes :
Configuration des politiques IAM et des rôles pertinents
Veuillez suivre ceci document d'AWS pour configurer le point de montage de S3 dans un cluster EKS.
Cela vous guidera pour effectuer les tâches suivantes :
Créez une politique IAM pour autoriser le point de montage à accéder au compartiment S3
Créez un rôle IAM.
Installez le point de montage pour le pilote CSI Amazon S3 et associez le rôle créé ci-dessus.
Création d'un volume persistant sur le cluster Kubernetes
Créez un PV avec les spécifications suivantes (en effectuant un kubectl apply) :
YAML
apiVersion: v1
kind: PersistentVolume
metadata:
name:
spec:
capacity:
storage: 100Gi
csi:
driver: s3.csi.aws.com
volumeHandle: s3-csi-driver-volume # must be unique
volumeAttributes:
bucketName:
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
storageClassName: s3-test # put any value here
mountOptions:
- allow-delete
- region
- allow-other
- uid=1000
volumeMode: Filesystem
Monter un EFS existant en tant que volume
Pour monter un bucket S3 en tant que volume sur TrueFoundry, vous devez suivre les étapes suivantes :
Installez le pilote EFS CSI sur votre cluster
Pour installer le pilote EFS CSI sur votre cluster, accédez à Truefoundry UI -> Clusters-> Applications installées-> Gérer
À partir du Volumessection cliquez sur installer le pilote AWS EFS CSI et cliquez sur Installer.
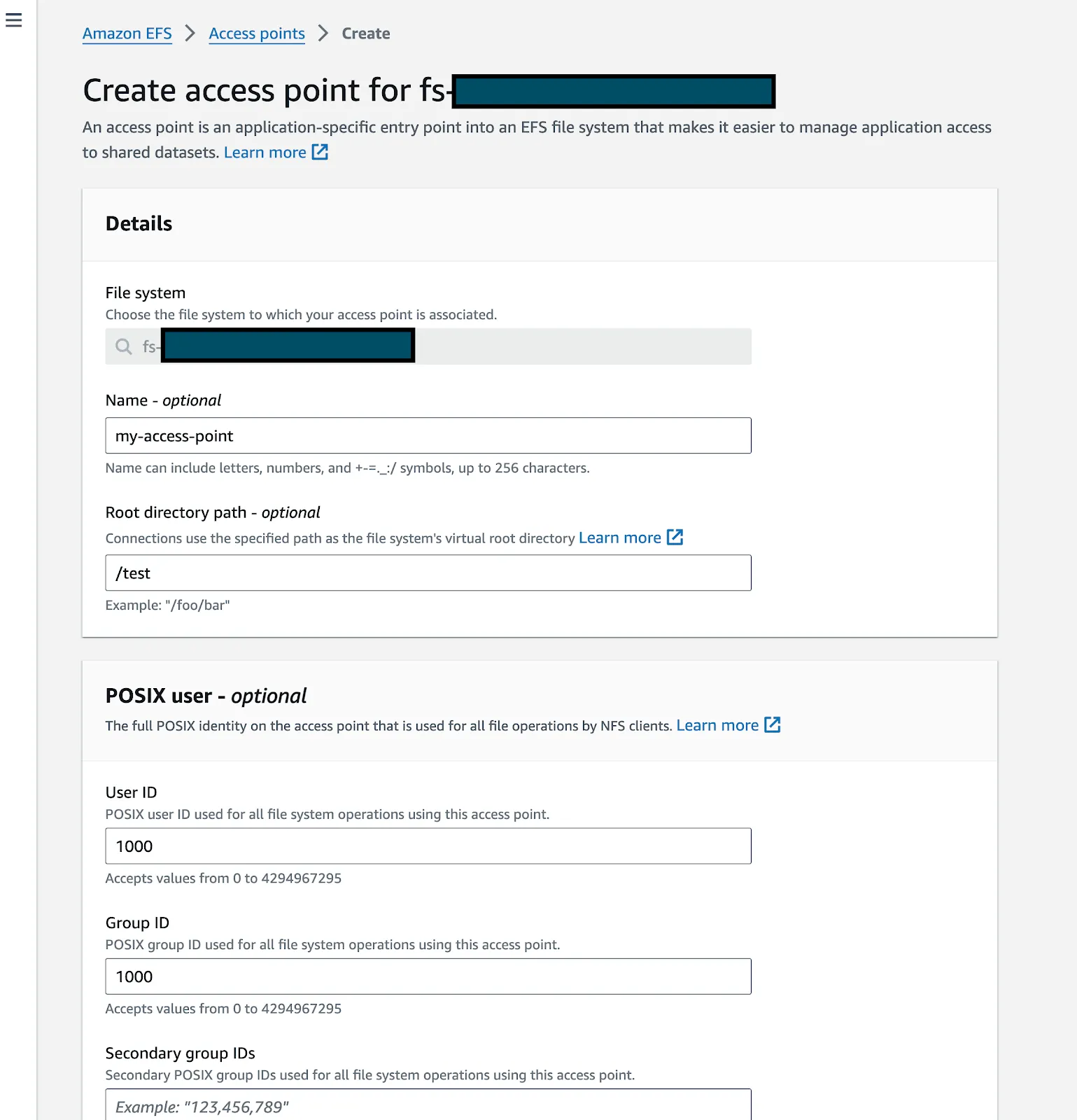
Créez un point d'accès pour votre EFS
Localisez votre EFS dans la console AWS et ouvrez-le. Assurez-vous que l'EFS et le cluster K8S se trouvent dans le même VPC. Cliquez sur « Créer un point d'accès »
Entrez des informations telles que le nom, le chemin du répertoire racine (assurez-vous de remplir la section Autorisations de création du répertoire racine, vous pouvez remplir avec l'UID : 1000 GID : 1000 si vous souhaitez le joindre au bloc-notes)
Cliquez sur Créer.
Création d'un volume persistant sur le cluster
Créez un PV avec les spécifications suivantes (en effectuant un kubectl apply) :
YAML
apiVersion: v1
kind: PersistentVolume
metadata:
name:
spec:
capacity:
storage: 5Gi # this number doesn't matter for EFS, any number will work
csi:
driver: efs.csi.aws.com
volumeHandle: :: # e.g. fs-036e93cbb1fabcdef::fsap-0923ac354cqwerty
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
storageClassName: efs-sc
volumeMode: Filesystem
Création d'un volume sur TrueFoundry
Veuillez suivre ceci section pour créer du volume sur TrueFoundry
Utilisation de Volumes sur Truefoundry
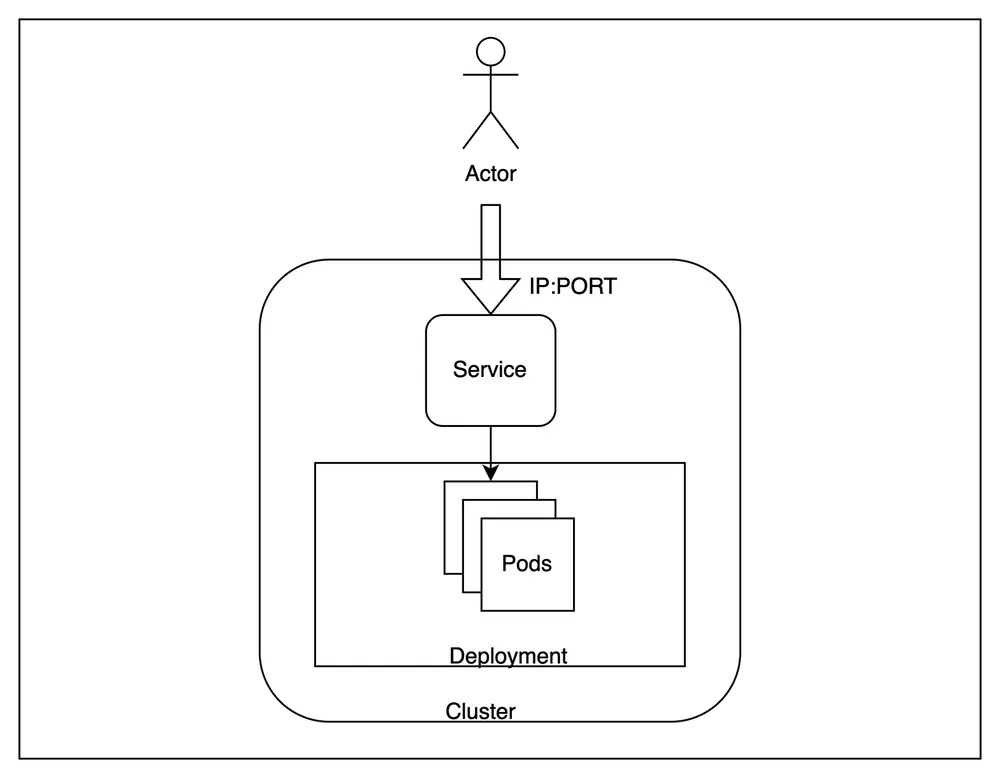
Grâce aux guides ci-dessus, vous pouvez facilement approvisionner des volumes ou utiliser des conteneurs de stockage existants comme volumes. Ces volumes peuvent désormais être montés sur n'importe quelle charge de travail sur Kubernetes. Si vous l'utilisez, vous pouvez facilement monter votre volume sur n'importe quelle charge de travail sur TrueFoundry. Vous pouvez facilement le monter sur un service ou de manière similaire toute charge de travail déployée sur Truefoundry. Vous pouvez également activer un navigateur de fichiers pour parcourir le contenu du volume en quelques clics à l'aide de notre navigateur de volumes.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.
Conçu pour la vitesse : latence d'environ 10 ms, même en cas de charge






































.png)

.webp)
.webp)
.webp)



.webp)
.webp)


