

August 27, 2025
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: April 22, 2026

Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
Les différentes charges de travail nécessitent des spécifications matérielles différentes, telles que le type, la taille et la géolocalisation de la machine. Avec l'essor du ML/LLM, il est devenu crucial de sélectionner le bon matériel. Nous devons faire des choix en fonction de spécifications matérielles telles que le type de système d'exploitation, l'architecture, le processeur, le type de GPU et le stockage. Kubernetes facilite l'orchestration et la distribution des ressources entre des charges de travail similaires, mais le provisionnement dynamique de ces ressources à la demande reste un défi.
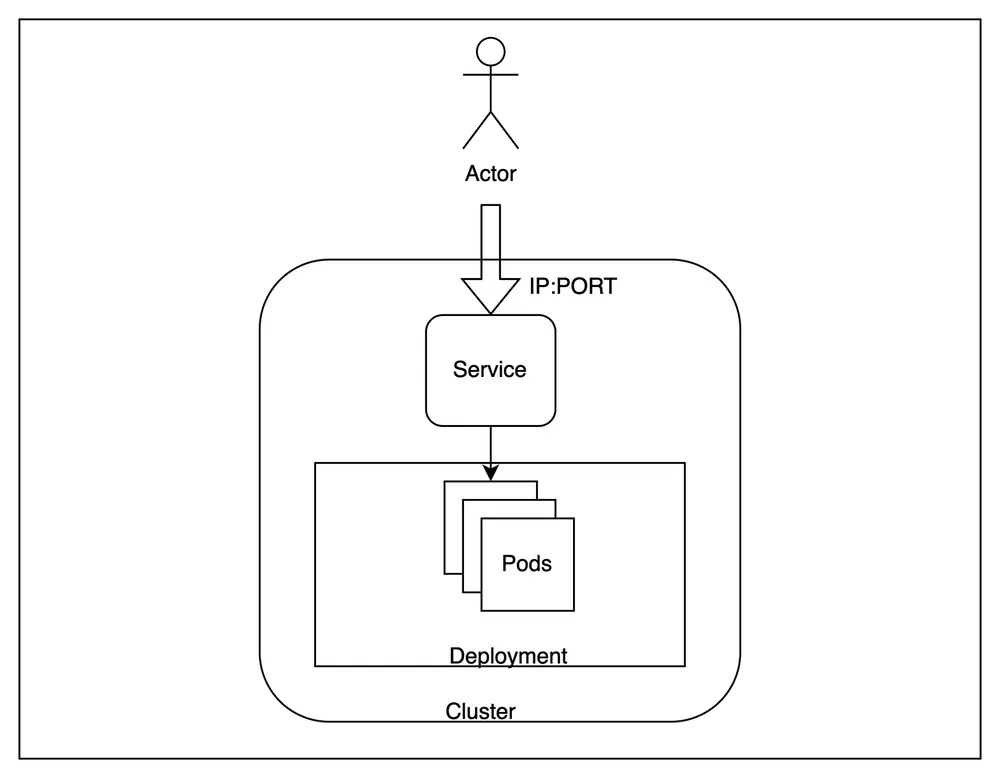
UNE Kubernetes Le cluster (K8s) est un regroupement de nœuds qui exécutent des applications conteneurisées de manière efficace, automatisée, distribuée et évolutive. Chaque nœud d'un cluster Kubernetes possède des attributs spécifiques tels que le type, la taille et l'emplacement de la machine.
Ce blog explore la nécessité des provisionneurs automatiques de nœuds cloud pour gérer automatiquement les diverses exigences en matière de charge de travail au sein des clusters Kubernetes. Nous fournissons également des informations sur les solutions proposées par les principaux fournisseurs de cloud tels qu'AWS, GCP et Azure. Enfin, nous examinons comment TrueFoundry répond à ces défis en tant que plateforme.
Le provisionnement automatique des nœuds automatise le provisionnement du groupe de nœuds approprié en fonction de contraintes de pod non planifiées afin d'optimiser les coûts d'infrastructure. Les provisionneurs automatiques de nœuds d'un cluster Kubernetes sont responsables des actions suivantes :
Kubernetes a des nœuds comme machines de travail avec des configurations matérielles spécifiques telles que le type, la taille et le type de capacité de la machine, et les pools de nœuds font référence aux pools de ces machines de travail courantes. En l'absence d'un provisionneur automatique de nœuds, la seule façon d'allouer une configuration matérielle spécifique à votre charge de travail était de sélectionner un pool de nœuds. Cela oblige l'utilisateur à créer un pool de nœuds avec la configuration requise dans son cloud, puis à ajouter un nœud. affinité pour le pool de nœuds spécifique dans la spécification du pod.
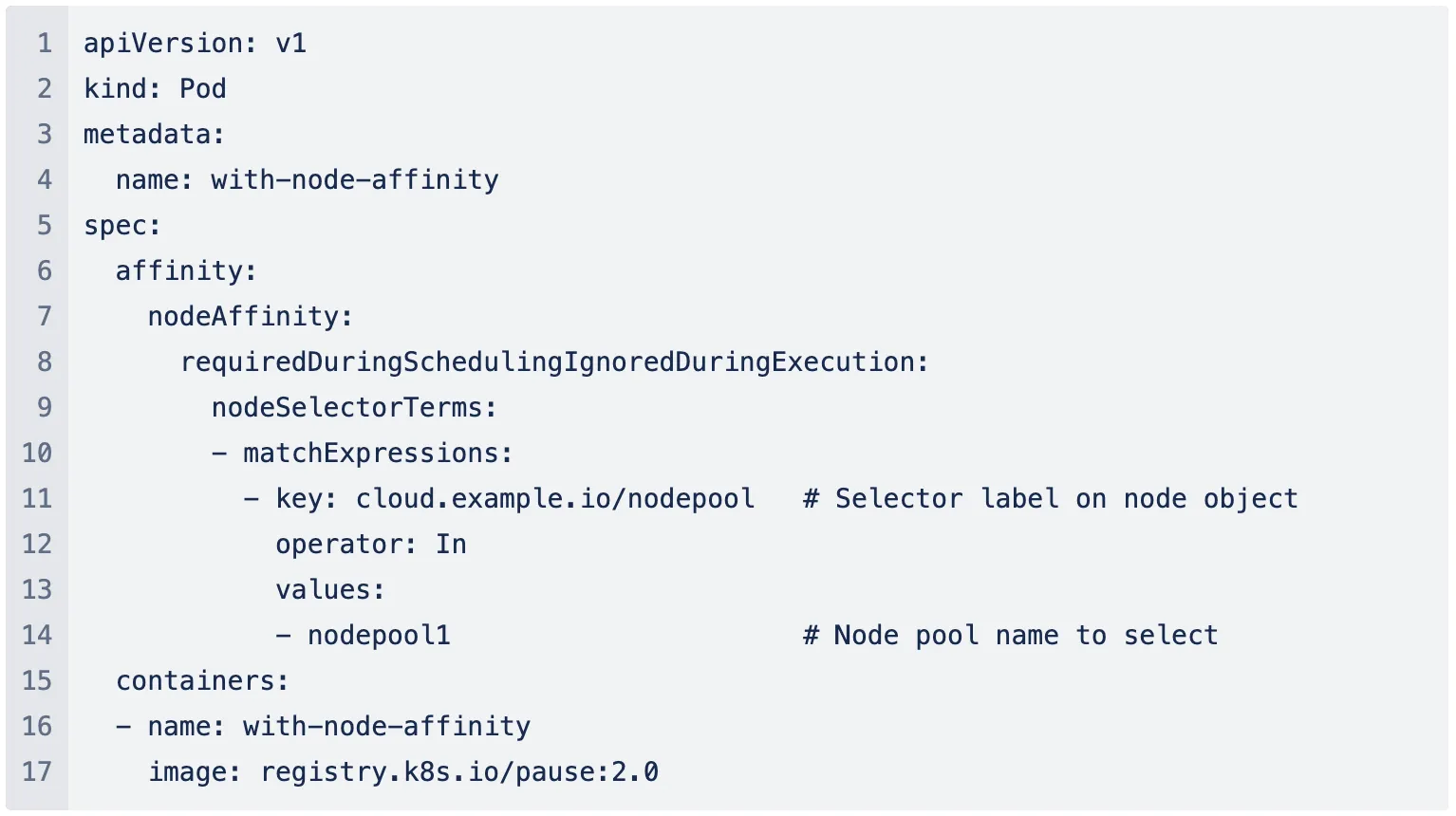
Dans l'ensemble, ce mécanisme comporte les étapes suivantes :
Les combinaisons d'exigences en matière de pool de nœuds peuvent être nombreuses, en particulier pendant la phase d'expérimentation des charges de travail ML/LLM. La coordination entre les équipes DevOps et Platform distinctes peut prendre beaucoup de temps pendant le développement. Par conséquent, un contrôleur qui évalue les exigences de manière dynamique et provisionne automatiquement l'infrastructure devient crucial.
Le provisionnement automatique des nœuds élimine l'étape manuelle de pré-création de pools de nœuds en permettant aux utilisateurs d'ajouter des exigences de haut niveau en tant que contraintes. Il détermine automatiquement le type de machine ou le nœud disponible le mieux adapté à la charge de travail.

Certaines des contraintes couramment utilisées sont les suivantes :
21000T4 et A100à la demande ou placeus-est-1alinux ou vitrinesbras 64 ou amd64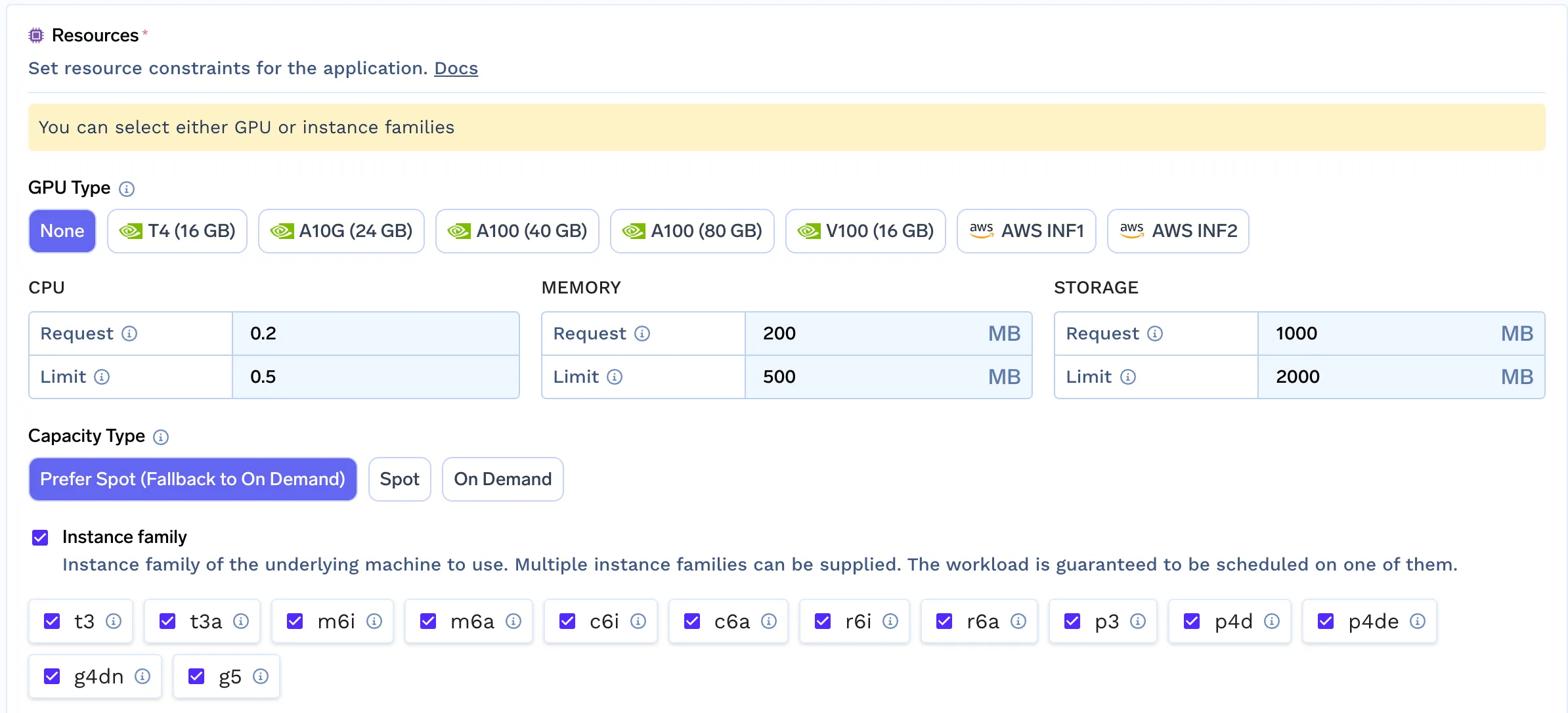
Chaque fournisseur de cloud propose ses mécanismes de provisionnement automatique. AWS nécessite l'installation d'outils tels que Karpenter, tandis que GCP fournit une solution intégrée. Azure a récemment présenté son projet d'approvisionnement automatique, actuellement en mode aperçu.
Charpentier, un projet de gestion du cycle de vie des nœuds open source conçu pour Kubernetes, améliore considérablement l'efficacité et la rentabilité de l'exécution des charges de travail sur des clusters. En tenant compte des contraintes de planification telles que les demandes de ressources, les sélecteurs de nœuds, les affinités, les tolérations et les contraintes d'étalement de la topologie, Karpenter provisionne et désalloue les nœuds de manière intelligente selon les besoins.
Provisionnement automatique des nœuds, intégré à l'autoscaler du cluster, dimensionne les pools de nœuds existants en fonction des spécifications des pods non planifiables. La fonction d'approvisionnement automatique de GCP garantit une utilisation optimale des ressources en tenant compte du processeur, de la mémoire, du stockage éphémère, des requêtes GPU, des affinités de nœuds et des sélecteurs d'étiquettes.
D'Azure Projet de provisionnement automatique des nœuds (NAP), actuellement en mode aperçu, exploite le projet open source Karpenter pour déterminer la configuration de machine virtuelle optimale pour exécuter les charges de travail de manière efficace et rentable. NAP déploie et gère automatiquement Karpenter sur des clusters AKS, offrant ainsi aux utilisateurs une expérience fluide.
💡
Le provisionnement automatique des nœuds (NAP) pour AKS est actuellement en version PREVIEW. Nous sommes très enthousiastes à l'idée de ce nouveau projet et avons hâte de l'utiliser pour nos clients. En savoir plus
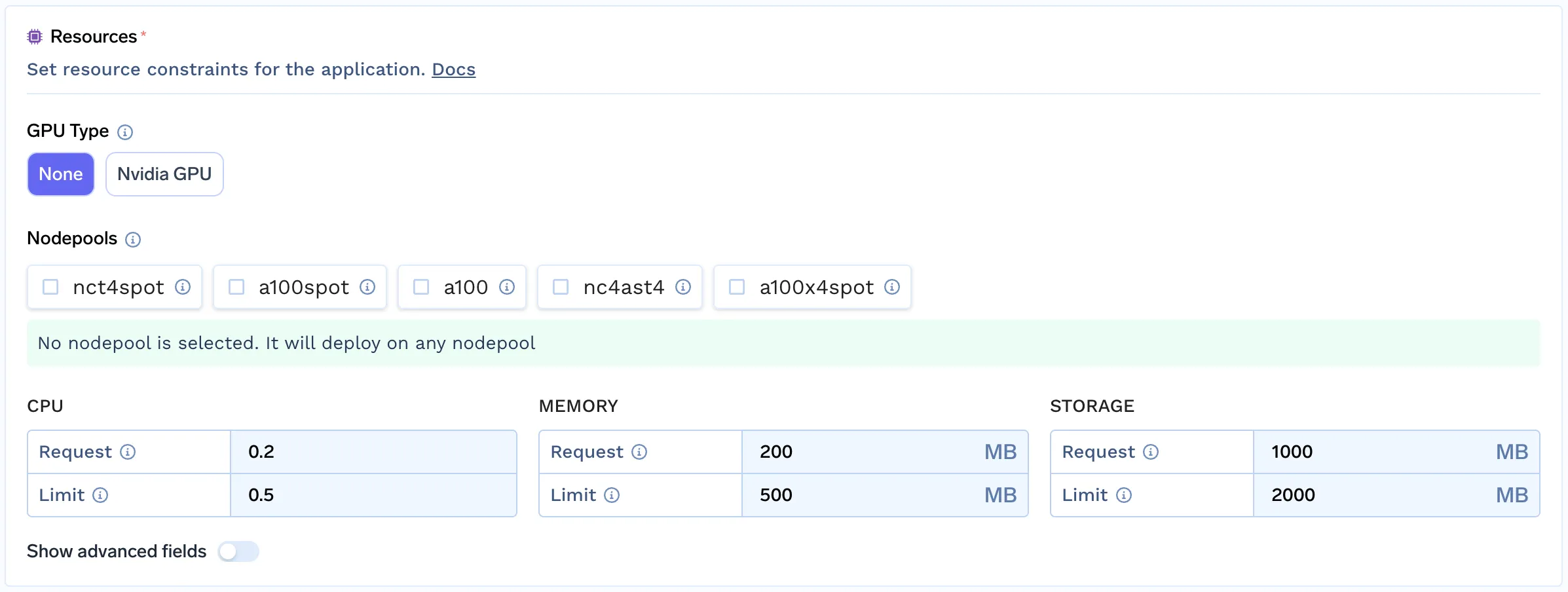
TrueFoundry offre des fonctionnalités de filtrage avancées pour les pools de nœuds, simulant l'expérience de provisionnement automatique des nœuds.
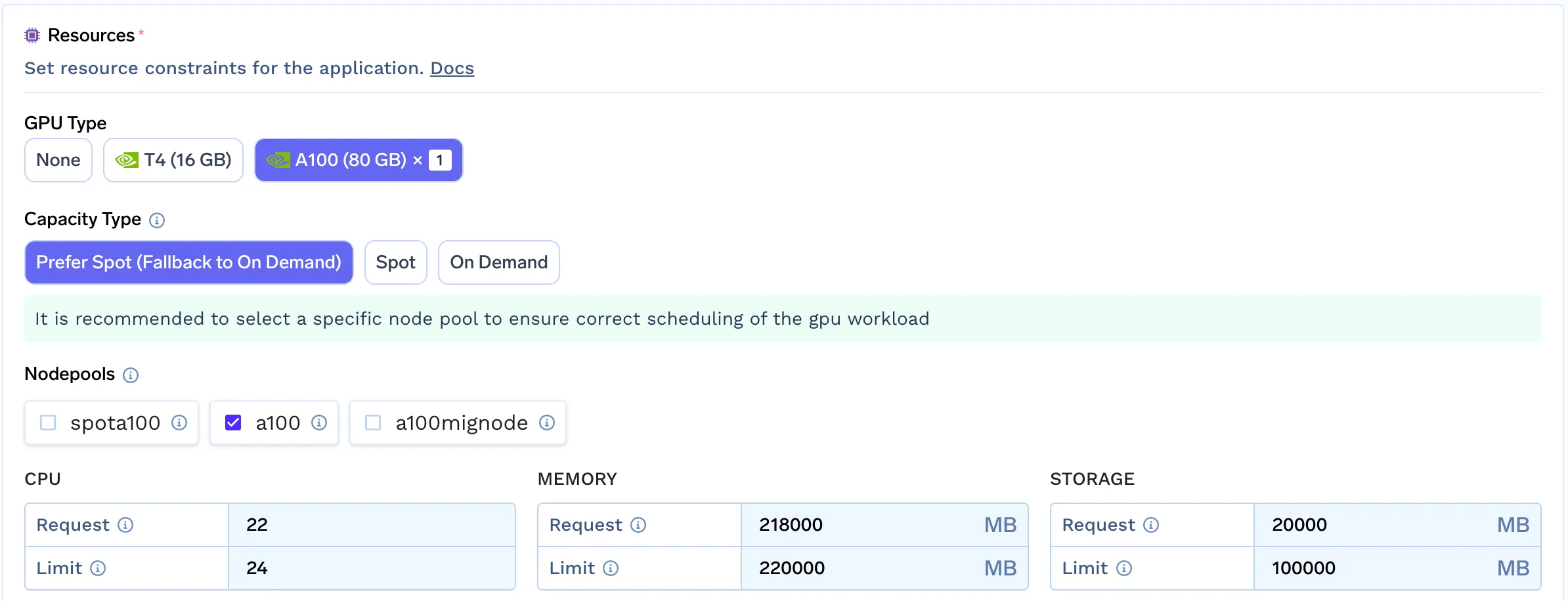
Pour ce faire, nous avons suivi quelques étapes simples :
Cette approche permet aux développeurs/data scientists de sélectionner le pool de nœuds le mieux adapté à leur charge de travail en analysant leurs besoins. Ce mécanisme simple nous permet de fournir la même expérience pour tous les clouds qui ne disposent pas encore de support intégré pour les provisionneurs automatiques.
Alors que les exigences en matière d'infrastructure continuent d'évoluer, les fournisseurs de cloud s'efforcent de rationaliser le processus de sélection de l'infrastructure optimale pour diverses charges de travail. À True Foundry, nous partageons cet engagement en nous efforçant de fournir aux développeurs les outils et les connaissances dont ils ont besoin pour déployer leurs charges de travail de manière fluide.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception








.png)

.webp)
.webp)
.webp)



.webp)
.webp)


