

August 27, 2025
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: April 22, 2026
Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
Dans le dernier numéro, nous avons examiné le flux de travail d'un data scientist et nous avons découvert où Kubernetes peut s'avérer être une base utile sur laquelle créer une plateforme.
Dans ce numéro, examinons un exemple simple pour acquérir de l'expérience pratique dans ce domaine.
Avant de commencer, nous avons besoin d'un terrain de jeu pour effectuer la démo. Pour ce faire, nous allons configurer un cluster Kubernetes sur la machine locale. Bien qu'un cluster doive contenir plusieurs nœuds pour des raisons de tolérance aux pannes et de haute disponibilité, nous allons imiter ce comportement à l'aide d'un outil génial sorte (Kubernetes-dans-Docker).
À la fin de cette section, plusieurs conteneurs seront en cours d'exécution, chaque conteneur agissant comme un nœud de cluster distinct.
Suivez les instructions fournies ici
Testez l'installation en exécutant
$ type --version
version 0.14.0 pour enfants
Nous démarrons maintenant un cluster local en utilisant sorte. Nous allons créer un plan de contrôle et deux nœuds de travail. Il est possible d'avoir plusieurs des deux.
<aside>💡 Kubernetes peut avoir plusieurs plans de contrôle et nœuds de travail. Tous les composants de gestion centralisée des clusters résident sur les nœuds du plan de contrôle tandis que la charge de travail des utilisateurs s'exécute sur les nœuds de travail. En savoir plus ici
</aside>
Tout d'abord, créez un sorte configuration dans un fichier appelé kind-config.yaml. Tu peux le trouver ici. Cela définira la structure de notre cluster -
type : Cluster
Version de l'API : kind.x-k8s.io/v1alpha4
nœuds :
- rôle : plan de contrôle
- rôle : travailleur
- rôle : travailleur
Ici, nous avons défini trois nœuds, l'un jouant le rôle de plan de contrôle et les deux autres en tant que nœuds de travail.
Lancez un cluster à l'aide de cette configuration. Cela peut prendre un certain temps. Assurez-vous que le démon Docker est activé sur votre système avant de l'exécuter -
$ kind créer un cluster --config kind-config.yaml
...
Merci d'avoir fait preuve de gentillesse ! 😊
kubectl pour nous assurer que notre cluster est actif -$ kubectl cluster-info
Le plan de contrôle Kubernetes s'exécute à < https://127.0.0.1:63122 >
CoreDNS fonctionne à < https://127.0.0.1:63122/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy >
...
Cela nous indique que le cluster est effectivement en hausse. Nous pouvons également voir les conteneurs individuels agir comme des nœuds en exécutant docker ps.
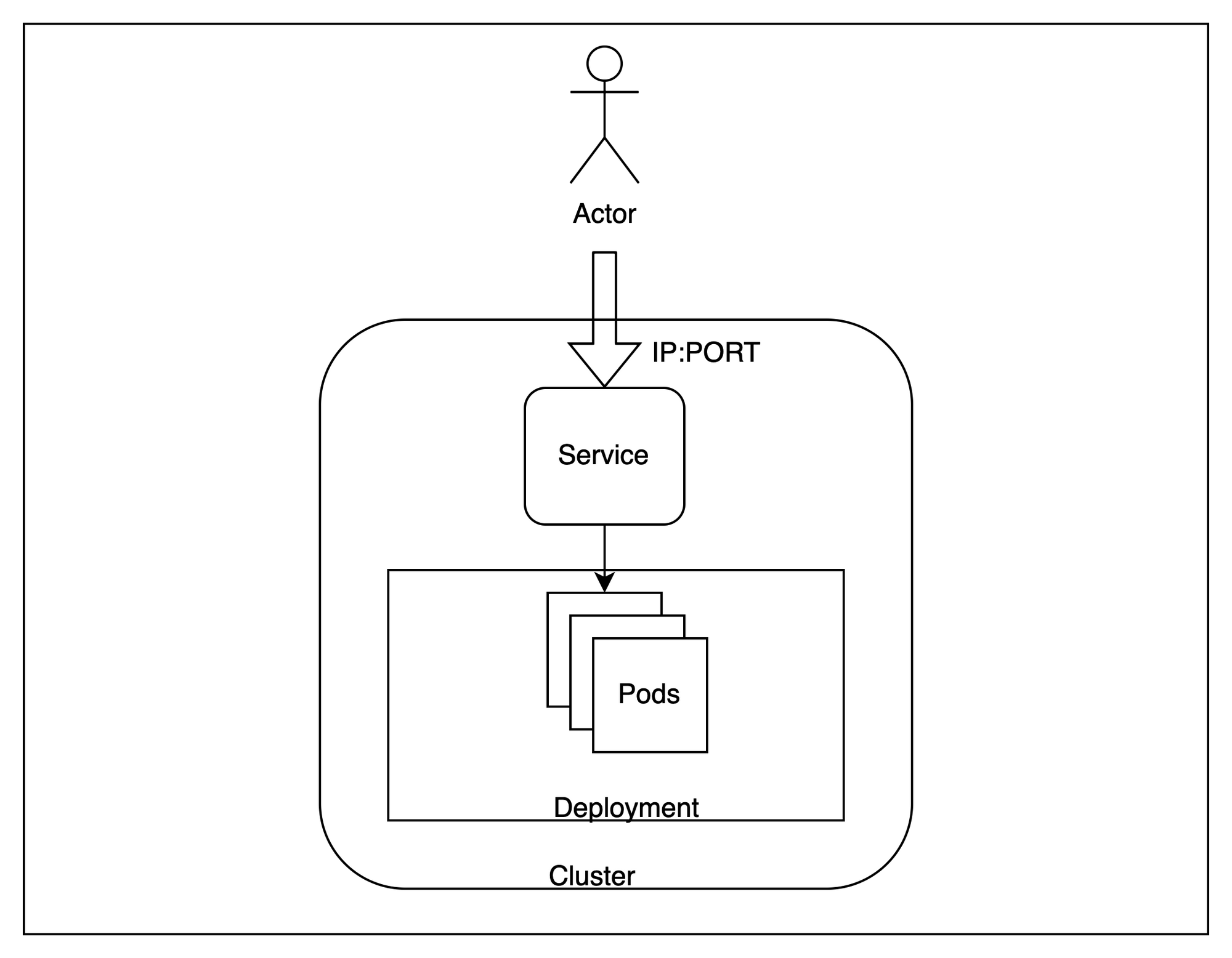
Maintenant que notre cluster est en place, examinons une architecture globale de ce que nous sommes sur le point de fournir.
D'une manière générale, nous hébergerons plusieurs répliques de notre application au sein du cluster et essaierons d'y accéder de l'extérieur en répartissant la charge des requêtes entre les différentes instances.
Pour y parvenir, il existe quelques termes spécifiques à Kubernetes que nous devons connaître :
Nacelle - Les pods sont les plus petites unités informatiques déployables que vous pouvez créer et gérer dans Kubernetes. Dans notre cas, une instance de l'application sera exécutée dans un pod indépendant. Ce sont des ressources éphémères et le plan de contrôle peut les déplacer entre les nœuds si nécessaire.Déploiement - Un déploiement est utile lorsque nous voulons disposer de plusieurs répliques pour une application. Kubernetes essaie de toujours maintenir le nombre de répliques à un niveau égal à celui fourni lors d'un déploiement. Nous allons créer trois répliques identiques pour notre application.Service - Un service est utile pour équilibrer la charge sur un ensemble de pods exécutés sur le cluster. Étant donné que les pods sont essentiellement éphémères et peuvent être remplacés à tout moment, le service fournit une interface stable pour accéder aux pods qui se trouvent derrière lui. Nous utiliserons un service pour tester notre application.Ces trois ressources nous permettront d'héberger un terminal évolutif pour servir notre application.
Une fois le cluster activé, nous pouvons désormais déployer une application et la tester. Nous allons créer une application à l'aide du célèbre ensemble de données du classificateur d'iris.
Le repo est disponible sur https://github.com/shubham-rai-tf/iris-classifier-kubernetes. Il contient déjà le code pour créer et diffuser des prédictions sur /iris/classifier_iris point de terminaison utilisant fastapi.
Nous devons empaqueter ce code dans une image docker pour le préparer kubernetes. UNE Fichier Docker est fourni dans le référentiel pour ce faire - ici.
Ce Fichier Docker spécifie l'image dont nous aurons besoin pour créer un conteneur hébergeant les points finaux de prédiction dans un luvicorne serveur sur le port 5000. Plus de détails sur la syntaxe sont disponibles ici.
Exécutez cette commande pour créer une image locale :
$ docker build. -t - classificateur d'iris : poc
...
$ docker image ls
IDENTIFIANT DE L'IMAGE DE LA BALISE DE RÉFÉRENTIEL (TAILLE CRÉÉE)
iris-classifier poc 549913d5b1f9 il y a 12 secondes 737MB
Nous pouvons voir que l'image a été créée avec succès avec le nom classificateur d'iris et étiquette poc. Nous allons maintenant charger cette image dans le cluster pour l'utiliser à l'intérieur du cluster
<aside>💡 Cette étape est uniquement nécessaire car nous ne disposons pas d'un registre d'images à partir duquel extraire l'image nouvellement créée. En production, l'image doit être hébergée dans un registre privé tel que Dockerhub ou AWS ECR, puis directement intégrée au cluster
</aside>
Exécutez cette commande pour charger l'image créée localement dans le cluster :
$ kind load docker-image iris-classifier:poc
L'image : « iris-classifier:poc » avec l'identifiant « sha 256:549913 d5b1f9456a4beedc73e04c3c0ad70da8691a8745a6b56a4f483c4f0862 » n'est pas encore présente sur le nœud « kind-worker2 », en cours de chargement...
L'image : « iris-classifier:poc » avec l'ID « sha 256:549913 d5b1f9456a4beedc73e04c3c0ad70da8691a8745a6b56a4f483c4f0862 » n'est pas encore présente sur le nœud « kind-control-plane », en cours de chargement...
...
Vous pouvez vérifier que les images ont été chargées en répertoriant les images dans l'un des trois conteneurs :
$ docker exec -it kind-worker crictl images
TAILLE DE L'IDENTIFIANT DE L'IMAGE DE LA BALISE IMAGE
docker.io/library/iris-classifier poc 549913d5b1f94 753 Mo
Kubernetes est essentiellement un système déclaratif. Cela signifie que nous décrivons les contours de ce que nous voulons faire et que les composants du plan de contrôle poussent constamment le système vers cet état.
Pour implémenter l'architecture dont nous avons parlé plus haut, nous allons décrire notre intention sous la forme d'un yaml fichier qui sert de registre d'intention. Dans le langage de Kubernetes, ils sont appelés manifeste.
Tous les manifestes Kubernetes comportent les champs suivants :
Version de l'API - Plusieurs ressources sont regroupées dans les mêmes versions d'API. Cela fournit un moyen standardisé de déprécier ou de promouvoir une ressource dans toutes les versions de Kubernetes.sorte - Identifie le type d'objet exact à créermétadonnées - Contient des champs qui font office de métadonnées pour l'objet créé. Le Version de l'API, sorte et nom des métadonnées les champs identifient ensemble une ressource unique dans un espace de nomsspécifications - Ce champ contient la spécification de l'objet à créer. Chaque type définit sa propre structure pour ce champ avec sa propre implémentation.Nous utiliserons les manifestes présents dans le dépôt dans les fichiers du manifeste annuaire ici.
Il définit deux ressources Kubernetes, Déploiement et Service dans déploiement.yaml et service.yaml respectivement. Passons en revue les deux sections.
Version de l'API : applications/v1
type : Déploiement
spécification :
# nombre de répliques
répliques : 3
modèle :
spécification :
conteneurs :
# nom de l'image
- image : classifieur d'iris : poc
nom : iris-classifier
Le manifeste de déploiement dans déploiement.yaml définit principalement la spécification du pod que nous voulons déployer en termes de nom de l'image et de nombre de répliques. Une fois que nous aurons appliqué cela, Kubernetes prendra constamment des mesures pour maintenir le nombre de répliques à ce que nous spécifions ici.
Version de l'API : v1
type : Service
spécification :
# Type de service
type : ClusterIP
ports :
# Port où le service sera accessible
- port : 8080
# Port du conteneur où le trafic doit être acheminé
Port cible : 5000
protocole : TCP
sélecteur :
appli : Iris-Classifier
Le manifeste de service dans service.yaml définit comment équilibrer la charge entre les répliques créées par le déploiement. Nous avons défini ici comment le port en service doit être mappé au port des conteneurs. Étant donné que notre application fonctionne sur le port 5000, le Port cible est réglé sur 5000. Le service est exposé sur le port 8080. Le trafic TCP envoyé au 8080 sera équilibré en charge sur le port 5000 des conteneurs.
Exécutez la commande suivante pour appliquer les manifestes à Kubernetes :
$ kubectl apply -f manifests/
deployment.apps/iris-classifier a été créé
service/iris-classifier créé
Les deux ressources ont été créées avec succès sur le cluster. Nous pouvons vérifier l'exécution des commandes suivantes :
$ kubectl get service iris-classifier
TYPE DE NOM CLUSTER-IP PORT (S) IP EXTERNE (S) AGE
<none>classificateur iris ClusterIP 10.96.107.238 8080/TCP 37m
$ kubectl get deployment iris classifier
NOM PRÊT À JOUR, ÂGE DISPONIBLE
classificateur d'iris 3/3 3 3 38 mm
$ kubectl get pods
LE STATUT « NOM PRÊT » REDÉMARRE L'ÂGE
iris-classifier-5d97498ff9-77wqw 1/1 Course à pied 0 39 m
iris-classifier-5d97498ff9-8twjm 1/1 Course à pied 0 39 m
iris-classifier-5d97498ff9-znrz8 1/1 Course à pied 0 39 m
Comme nous pouvons le voir, le service est exposé sur le port 8080 et trois pods ont été créés comme nous l'avons spécifié.
Modifier déploiement.yaml pour avoir 2 répliques au lieu de 3 et réappliquer. Kubernetes supprimera l'une des répliques pour qu'elle corresponde à la spécification.
Maintenant que les ressources ont été créées dans le cluster, nous pouvons vérifier notre déploiement en appelant le modèle à l'aide du point de terminaison du service. Puisque nous utilisons une configuration locale, nous devrons transfert de port le service vers un port de la machine locale.
<aside>💡 Dans la configuration d'un fournisseur de cloud, ce service sera lié à un équilibreur de charge externe accessible depuis Internet si nécessaire.
</aside>
Exécutez la commande suivante pour effectuer la redirection de port pour le service :
$ kubectl port-forward services/Iris-Classifier 8080
Transfert depuis 127.0.0. 1:8080 -> 5000
Transfert depuis [::1] :8080 -> 5000
Nous pouvons vérifier en appelant le /bilan de santé point final sur le modèle -
< http://localhost:8080/healthcheck >$ curl « »
« Le classificateur Iris est prêt ! »
Pour effectuer une prédiction de test, nous enverrons un exemple d'entrée pour obtenir une prédiction -
$ curl ''< http://localhost:8080/iris/classify_iris > -X POST \ \
-H 'Type de contenu : application/json' \ \
-d '{"longueur_sépalaise » : 2, « largeur_sépalaire » : 4, « longueur_pétale » : 2, « largeur_pétale » : 4}'
{"class » :"setosa », « probabilité » :0,99}
Nous obtenons une prédiction de classe setosa avec une probabilité de 99 %. En exécutant plusieurs de ces prédictions, nous pouvons vérifier que les demandes sont bien acheminées vers différents pods de manière circulaire.
Supprimons toutes les ressources Kubernetes que nous avions installées en premier -
$ kubectl delete -f manifests/
Cela permettra de nettoyer toutes les ressources Kubernetes que nous avions créées dans les sections précédentes. Maintenant, nous pouvons également supprimer le cluster -
$ kind supprime le cluster
Suppression du « type » de cluster...
Dans ce numéro, nous avons expliqué comment héberger un modèle en tant que service appelable dans Kubernetes. Bien qu'il s'agisse d'un exemple fictif dans lequel nous avons créé une image Docker localement et l'avons exécutée sur un cluster exécuté sur la même machine, une configuration de production typique fonctionne selon des principes similaires. Il est possible de réaliser beaucoup de choses avec ces deux seules ressources.
Dans les prochains numéros, nous explorerons d'autres fonctionnalités plus avancées, telles que la mutualisation et le contrôle d'accès, qui deviennent essentielles à l'approche du deuxième jour des opérations.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception








.png)

.webp)
.webp)
.webp)



.webp)
.webp)


