Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.
9,9
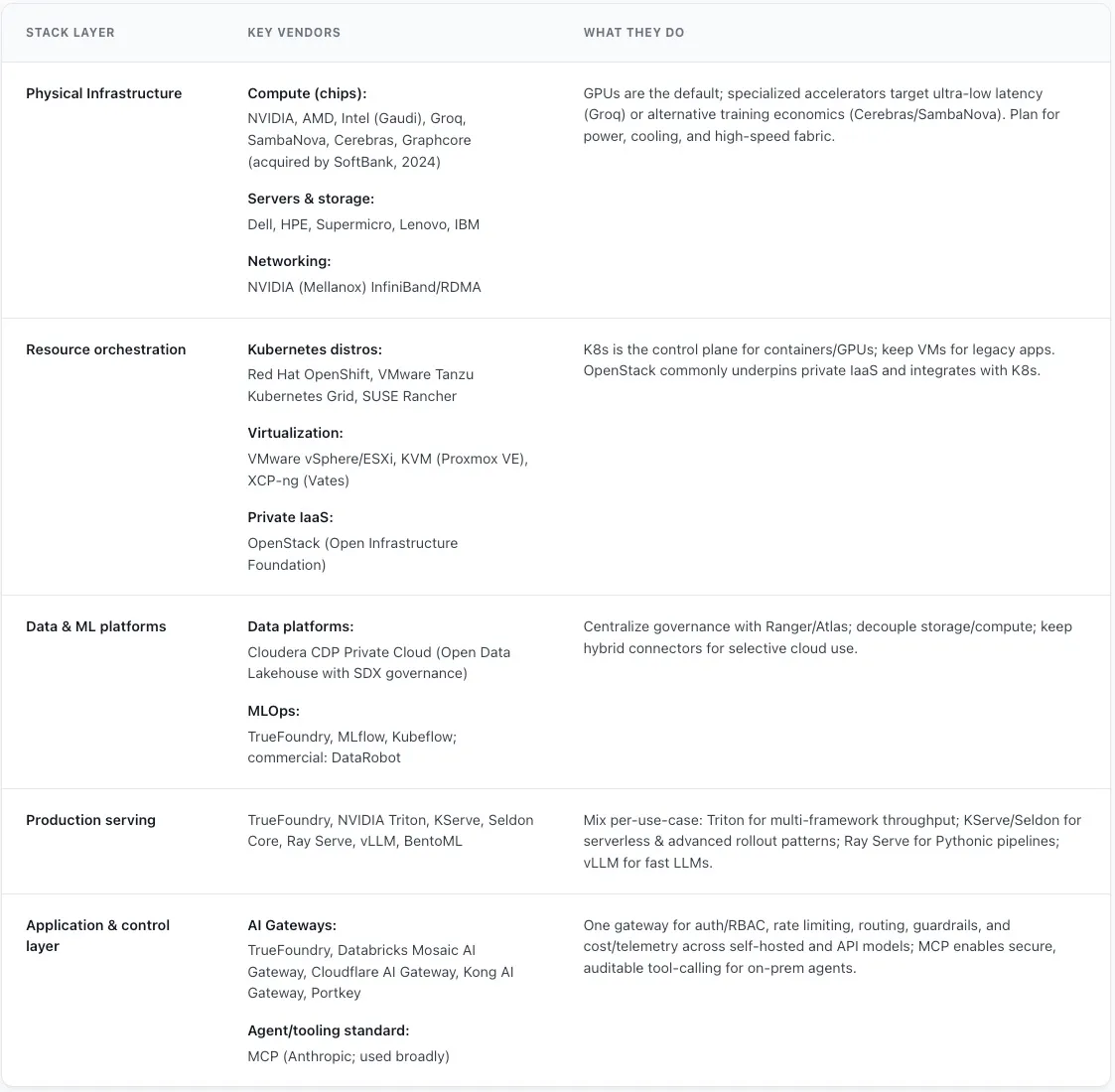
Cartographie du marché de l'IA sur site : des puces aux plans de contrôle
Alors que les entreprises mettent GenAI en production, nombre d'entre elles redécouvrent les avantages des déploiements sur site, qu'il s'agisse de réduire les coûts du cloud, de répondre à des exigences de conformité strictes ou de garantir une latence extrêmement faible. Mais une pile d'IA sur site n'est pas une appliance unique que vous pouvez stocker et oublier. Il s'agit d'un écosystème en couches composé de matériel, d'orchestration, de plateformes de données et de frameworks de service qui doivent tous fonctionner de concert.
Ce guide passe en revue chaque couche de la pile d'IA moderne sur site et présente la proposition de valeur pour chaque composant.
Pourquoi l'IA sur site gagne du terrain
Les entreprises des secteurs de la finance, de la santé, de l'industrie et du secteur public sont confrontées à des réglementations de plus en plus strictes en matière de souveraineté des données, à des factures cloud en hausse et à des SLA de performance que le cloud public ne peut pas toujours respecter. Ensemble, ces couches constituent la base d'un plateforme d'IA sur site que les entreprises peuvent faire évoluer, gérer et opérer indépendamment des contraintes du cloud public.
Contrôle des données et conformité: conservez les données sensibles entièrement derrière votre pare-feu. Lorsque les données sont envoyées vers un cloud public, leur emplacement physique exact et la juridiction légale dont elles relèvent peuvent devenir ambigus, ce qui crée des risques de conformité importants et complique les audits. Une configuration sur site permet à une organisation d'adapter l'ensemble de sa pile d'IA pour se conformer à ces réglementations, en fournissant un cadre défendable qui respecte les normes légales et évite la complexité des problèmes de transfert de données transfrontalier.
Performances et latence: Co-localisez le calcul et le stockage pour une inférence en temps réel. En traitant les données localement, l'IA sur site peut offrir une latence nettement plus faible et, surtout, plus prévisible. Ces performances constantes à haut débit sont essentielles pour les applications qui nécessitent une prise de décision intermodale instantanée, telle que l'analyse d'un flux de données de capteurs tout en le recoupant avec des enregistrements historiques. Cet avantage en termes de performances s'étend à l'intégration avec les systèmes d'entreprise existants. Les solutions sur site, en raison de leur flexibilité et de leur personnalisation, peuvent souvent être intégrées plus facilement et de manière plus fiable aux bases de données existantes, aux systèmes ERP et à d'autres technologies opérationnelles qui peuvent ne pas être compatibles avec les environnements cloud standardisés.
Prévisibilité des coûts: Passez de taux de rémunération variables à l'utilisation à des investissements dans des infrastructures fixes. Les frais cachés liés à la sortie de données, aux appels d'API, à la hiérarchisation du stockage et à la fluctuation des prix de calcul peuvent rapidement éroder les avantages initiaux d'un faible CapEx, entraînant ce que certaines analyses ont qualifié de « pur gaspillage » en termes de dépenses liées au cloud. En revanche, un déploiement sur site, malgré son coût initial élevé, offre des coûts d'exploitation à long terme prévisibles et gérables. Pour les entreprises ayant une utilisation soutenue de l'IA, l'infrastructure sur site s'avère souvent être l'option la plus rentable sur un horizon de trois à cinq ans.
Intégration personnalisée: connectez-vous facilement à des systèmes existants, à des appareils périphériques ou à du matériel propriétaire.
Pourtant, la construction et l'exploitation de cette installation en interne entraînent des dépenses en capital, des besoins en talents spécialisés et des frais de maintenance continus.
Qu'est-ce qu'une pile d'IA moderne sur site ?
Une pile d'IA moderne sur site est un système complexe à plusieurs niveaux dans lequel chaque composant joue un rôle crucial. Il ne s'agit pas d'une entité monolithique mais d'un écosystème interdépendant de matériel et de logiciels conçu pour fournir des capacités d'IA robustes, évolutives et efficaces. Pour comprendre cette pile, il faut procéder à une déconstruction couche par couche, de l'infrastructure physique qui fournit la puissance brute aux plateformes de haut niveau qui permettent le flux de travail de l'IA
À la base, une pile d'IA sur site combine :
Infrastructure physique (calcul, stockage, mise en réseau)
Orchestration des ressources (virtualisation, conteneurs, Kubernetes)
Plateformes de données et de machine learning (lacs de données, outils MLOps)
Au service de la production (cadres d'inférence, mise à l'échelle, gouvernance)
Chaque couche doit être conçue pour optimiser l'utilisation, garantir la fiabilité et permettre une évolutivité fluide, sans vous enfermer dans un seul fournisseur.
Infrastructure matérielle et physique
C'est le fondement de l'ensemble de la pile d'IA, la manifestation physique de la puissance de calcul. Il comprend les moteurs de calcul qui effectuent les calculs, les systèmes de stockage qui contiennent les vastes ensembles de données et la structure réseau qui connecte tout. Les performances et les limites de cette couche dictent le potentiel de toutes les couches suivantes.
Moteurs de calcul
GPU: Conçus à l'origine pour le rendu graphique 3D, les GPU sont devenus le cheval de bataille de la révolution de l'IA en raison de leur architecture massivement parallèle. NVIDIA a établi une position dominante sur ce marché avec ses GPU pour centres de données, tels que les A100, H100 et la prochaine série B200. Ces puces, équipées de milliers de cœurs spécialisés (par exemple, des cœurs Tensor), peuvent fournir des performances d'entraînement à l'IA jusqu'à 20 fois plus rapides que les processeurs traditionnels. Ils constituent la norme de facto actuelle pour créer des clusters de formation à l'IA sur site performants.
processeurs: Alors que les GPU gèrent la lourde charge du traitement parallèle, les processeurs restent des composants essentiels du serveur d'IA. Ils gèrent les opérations globales du système, gèrent les tâches de traitement séquentielles et orchestrent le flux de données à destination et en provenance des GPU. La dernière génération de processeurs multicœurs d'Intel et d'AMD fournit la puissance de calcul polyvalente nécessaire pour prendre en charge les accélérateurs spécialisés
ASIC/TPU: La tendance émergente et perturbatrice en matière de calcul basé sur l'IA est l'essor des circuits intégrés spécifiques aux applications (ASIC). Il s'agit de puces conçues de A à Z dans un seul but : exécuter des charges de travail basées sur l'IA. Les unités de traitement tensoriel (TPU) de Google en sont un excellent exemple, optimisées pour les opérations matricielles au cœur des réseaux de neurones. Sur le marché du on-premise, une nouvelle catégorie de startups conteste le monopole des GPU avec des ASIC spécialisés. Des entreprises comme Croissance développent des puces pour l'inférence à très faible latence, tandis que Systèmes SambaNova et Cérébrales créent de nouvelles architectures (unités de flux de données reconfigurables et moteurs Wafer-Scale, respectivement) qui promettent un coût total de possession et une efficacité énergétique supérieurs pour la formation et l'inférence à grande échelle. Ces accélérateurs spécialisés représentent l'avenir du matériel d'IA, car ils permettent de dépasser les limites de puissance et de coût des GPU à usage général.
Serveurs et solutions de stockage d'entreprise
Serveurs hautes performances: Les principaux fournisseurs de matériel d'entreprise tels que Hewlett Packard Enterprise (HPE) avec ses gammes ProLiant et Apollo, Dell Technologies avec ses serveurs PowerEdge, Supermicro, et IBM avec ses systèmes d'alimentation, fournissez le châssis de serveur pour l'IA sur site. Il ne s'agit pas de serveurs standard ; ils sont spécifiquement conçus pour accueillir plusieurs GPU haute puissance, fournir d'énormes quantités de mémoire haute vitesse (RAM) et intégrer des solutions de refroidissement avancées pour gérer la puissance thermique des accélérateurs.
Stockage hautes performances: L'IA est alimentée par les données, et la couche de stockage doit fournir un accès rapide et simultané à des ensembles de données volumineux sans créer de goulot d'étranglement. Cela nécessite d'aller au-delà du stockage traditionnel. Des solutions de stockage hautes performances et à faible latence telles que SSD NVMe (Non-Volatile Memory Express) et systèmes de fichiers distribués sont essentiels. Les données elles-mêmes sont généralement organisées en lacs de données pour stocker de grandes quantités de données brutes non structurées (images, texte, journaux) et entrepôts de données pour des données structurées prêtes à être analysées. Un composant émergent essentiel, en particulier pour l'IA générative, est le base de données vectorielles, qui est optimisé pour stocker et interroger les intégrations vectorielles de grande dimension qui représentent des données non structurées.
Réseau haut débit
InfiniBand et RDMA les structures fournissent jusqu'à 400 Gbit/s de débit à faible latence, ce qui garantit que les GPU restent alimentés en données pendant l'entraînement distribué ou l'inférence parallèle. La couche réseau est le « système nerveux » du centre de données IA, responsable du transfert fluide des données entre les systèmes de stockage et les nœuds de calcul. Pour l'IA à grande échelle, en particulier la formation distribuée où un seul modèle est entraîné sur des centaines ou des milliers de GPU, le réseau Ethernet standard est insuffisant et peut devenir un obstacle majeur aux performances. Pour éviter que les puissants GPU ne restent inactifs en attendant les données, les clusters d'IA sur site s'appuient sur des structures réseau à bande passante élevée et à faible latence. Les technologies comme InfiniBand et RDMA (Remote Direct Memory Access) sont essentielles. InfiniBand, par exemple, peut prendre en charge un débit allant jusqu'à 400 gigabits par seconde, garantissant ainsi que les données peuvent être déplacées entre les serveurs et le stockage à la vitesse requise pour que les moteurs de calcul soient pleinement utilisés. Cette interconnexion haut débit est un composant non négociable de toute infrastructure d'IA sérieuse sur site.
La couche d'orchestration et de gestion
Située au-dessus du matériel physique, la couche d'orchestration et de gestion comprend le logiciel qui extrait, partitionne et gère les ressources sous-jacentes. Cette couche transforme un ensemble rigide de serveurs physiques en une plate-forme flexible, évolutive et efficace pour le développement et l'exécution d'applications d'IA.
Le rôle de la virtualisation et de la conteneurisation
Les technologies de base pour la gestion des ressources sont la virtualisation et la conteneurisation. Ils permettent de partitionner et d'isoler efficacement les charges de travail.
Machines virtuelles (VM): La virtualisation est au cœur des datacenters depuis des décennies. Un hyperviseur crée plusieurs machines virtuelles sur un seul serveur physique, chacune dotée de son propre système d'exploitation complet. Bien que robustes et bien comprises, les machines virtuelles ont une plus grande empreinte de ressources et des temps de démarrage plus lents que les conteneurs. Ils restent toutefois pertinents, en particulier pour moderniser les applications existantes parallèlement aux nouvelles charges de travail liées à l'IA. Les plateformes telles qu'IBM Fusion et Vates VMS sont spécialement conçues pour fournir une plate-forme unifiée sur site capable de gérer à la fois des machines virtuelles et des conteneurs, souvent avec des fonctionnalités telles que le GPU direct.
Conteneurs (par exemple, Docker) : La conteneurisation est l'approche moderne et légère de l'isolation des charges de travail. Un conteneur regroupe une application et toutes ses dépendances (bibliothèques, fichiers de configuration) dans une seule unité portable qui partage le noyau du système d'exploitation hôte. Cela se traduit par un encombrement beaucoup plus réduit, des temps de démarrage plus rapides et une meilleure efficacité des ressources que les machines virtuelles. Pour l'IA, cela signifie qu'un modèle et son environnement spécifique peuvent être encapsulés dans un image de conteneur immuable. Cette image peut ensuite être déployée de manière cohérente sur l'ordinateur portable d'un développeur, un serveur de test et le cluster de production, éliminant ainsi le problème « cela fonctionnait sur ma machine » et garantissant la reproductibilité.
Kubernetes : le système d'exploitation du centre de données basé sur l'IA
Alors que Docker fournit le format de conteneur, Kubernetes assure la gestion à grande échelle. Kubernetes est une plateforme open source qui automatise le déploiement, la mise à l'échelle, la mise en réseau et la gestion d'applications conteneurisées sur un cluster de machines. Il est devenu la norme incontestée en matière d'orchestration de conteneurs et constitue le moteur de la plupart des applications cloud natives modernes, que ce soit dans le cloud public ou sur site.
Pour l'IA sur site, Kubernetes est le lien essentiel entre la couche applicative et le matériel. Distributions Kubernetes destinées aux entreprises, telles que Red Hat OpenShift sont spécialement conçus pour les déploiements sur site et dans le cloud hybride, fournissant la sécurité, la gestion et le support dont les entreprises ont besoin.
Les avantages de l'utilisation de Kubernetes pour les charges de travail d'IA sont considérables :
Mise à l'échelle et équilibrage de charge automatisés : Kubernetes peut automatiquement augmenter ou diminuer le nombre de répliques de conteneurs en fonction de la demande de calcul et répartir les demandes d'inférence entre elles, garantissant ainsi une disponibilité et des performances élevées.
Gestion et planification des ressources : Kubernetes possède des fonctionnalités de planification prenant en compte les GPU, ce qui lui permet de placer intelligemment les charges de travail d'IA sur des nœuds disposant du matériel d'accélération nécessaire, maximisant ainsi l'utilisation de ces ressources coûteuses.
Résilience et auto-guérison : En cas de défaillance d'un conteneur ou d'un nœud, Kubernetes peut le redémarrer automatiquement ou le replanifier sur un nœud sain, offrant ainsi la résilience nécessaire aux tâches de formation de modèles de longue durée et aux services d'inférence critiques.
Kubernetes fournit essentiellement le système d'exploitation dynamique, automatisé et résilient pour le centre de données IA sur site.
Activation des données et du ML
Plateformes de données et gouvernance
Il s'agit de la couche logicielle la plus élevée de la pile, contenant les outils et plateformes spécialisés que les data scientists et les ingénieurs en apprentissage automatique utilisent pour exécuter le cycle de vie de bout en bout de l'IA. Cette couche exploite le matériel et l'orchestration sous-jacents pour gérer les données et créer, former, déployer et surveiller des modèles d'IA.
La fabrique de données (plateformes de données)
Avant de créer un modèle, les données doivent être gérées. Les plateformes de données fournissent un environnement unifié pour l'ensemble du cycle de vie des données, de l'ingestion et du traitement au stockage et à la gouvernance.
Plateforme de données Cloudera (CDP) : Acteur dominant dans le paysage des données hybrides et sur site, Cloudera a évolué depuis ses racines dans l'écosystème Hadoop pour devenir une plateforme de données d'entreprise complète. Le Cloud privé CDP l'offre est spécialement conçue pour fonctionner sur site, généralement au-dessus d'un cluster Kubernetes tel que Red Hat OpenShift. Il fournit une Lakehouse de données ouvertes architecture capable de gérer à la fois des données structurées et non structurées à l'échelle du pétaoctet. Essentiellement pour l'IA d'entreprise, il intègre une sécurité robuste et centralisée via Ranger Apache et un cadre de gouvernance et de métadonnées unifié appelé Expérience de données partagée (SDX), en veillant à ce que des politiques de sécurité cohérentes soient appliquées à toutes les données et analyses dans l'environnement hybride.
Databricks et connectivité hybride : Bien que Databricks soit avant tout une plateforme native du cloud, son importance dans le domaine de l'IA signifie que de nombreuses organisations élaborent des solutions pour connecter leurs sources de données sur site, telles qu'un cluster Cloudera, à leur environnement Databricks. Cette réalité souligne la nature hybride de l'IA d'entreprise moderne, où la gravité des données nécessite souvent de conserver de grands ensembles de données sur site tout en tirant parti d'outils basés sur le cloud pour certaines tâches d'analyse ou de collaboration.
MLOps et expérimentation
Les MLOps (Machine Learning Operations) sont un ensemble de pratiques qui vise à déployer et à maintenir des modèles d'apprentissage automatique en production de manière fiable et efficace. Les plateformes MLOps sont les outils qui permettent ces pratiques, en automatisant l'ensemble du cycle de vie du machine learning et en comblant le fossé entre la science des données (création de modèles) et les opérations informatiques (leur exécution en production).
Les principales fonctions d'une plateforme MLOps incluent : le suivi des expériences (enregistrement de tous les paramètres, métriques et artefacts), la gestion des versions et le registre des modèles, la création de pipelines CI/CD (intégration continue/déploiement continu) automatisés pour les modèles, la gestion du déploiement des modèles et la surveillance des performances des modèles pour des problèmes tels que la dérive des données.
Le marché des MLOps sur site propose un mélange de puissantes plateformes open source et commerciales :
Code source ouvert :Débit ML est une plateforme MLOps open source de premier plan, largement adoptée pour sa flexibilité, son approche indépendante du framework et ses fonctionnalités complètes de suivi des expériences et de gestion des modèles. Il permet aux équipes de créer des flux de travail MLOps robustes sans dépendre d'un fournisseur.
Plateformes commerciales : Des plateformes gérées de bout en bout telles que Robot de données, Iguazio (acquis par McKinsey), proposent des solutions complètes qui couvrent l'intégralité du cycle de vie, souvent en mettant l'accent sur la facilité d'utilisation, l'automatisation et un support de niveau entreprise.
Augmentez le choix de plateformes grâce à la passerelle IA RBAC, aux garde-fous et aux budgets de TrueFoundry pour garantir une application fluide des politiques entre les équipes et les modèles
Servir et développer l'IA dans la production
Une fois qu'un modèle est entraîné et validé, il doit être déployé dans un environnement de production où il peut recevoir des données d'entrée et renvoyer des prédictions, un processus appelé inférence. La diffusion de modèles est une tâche spécialisée qui nécessite un logiciel optimisé pour un débit élevé et une faible latence.
Serveur d'inférence NVIDIA Triton : Un serveur d'inférence open source performant de NVIDIA. Ses principaux atouts sont sa capacité à exécuter des modèles à partir de presque tous les frameworks (TensorFlow, PyTorch, ONNX, etc.) et sa capacité à exécuter des modèles simultanément, ce qui permet à plusieurs modèles ou à plusieurs instances du même modèle de fonctionner sur un seul GPU, maximisant ainsi l'utilisation du matériel.
Kserve : Une norme pour le service de modèles sur Kubernetes. KServe fournit une plateforme évolutive et extensible pour le déploiement de modèles. Ses fonctionnalités remarquables incluent des fonctionnalités d'inférence sans serveur (avec une mise à l'échelle automatique qui permet de réduire les pods à zéro lorsqu'ils ne sont pas utilisés, économisant ainsi des ressources) et un « InferenceGraph » qui prend en charge des stratégies de déploiement avancées telles que les déploiements Canary, les tests A/B et les ensembles de modèles.
Noyau Seldon : Une autre puissante plateforme de service de modèles open source pour Kubernetes. Seldon Core est également connu pour sa prise en charge robuste des modèles de déploiement avancés, notamment les tests A/B, les déploiements Canary et les bandits multi-armés (MAB), ce qui en fait un choix idéal pour les organisations qui doivent tester et optimiser rigoureusement les modèles en production.
Autres cadres : L'écosystème comprend également d'autres outils open source puissants tels que botte de foin, qui est un cadre pour la construction de pipelines agentic et RAG complexes, et Ray, un moteur de calcul distribué souvent utilisé comme colonne vertébrale pour la formation et la gestion d'applications d'IA à grande échelle.
TrueFoundry fonctionne comme un passerelle/commande planez au-dessus de ces serveurs, afin que vous puissiez effectuer des combinaisons (Triton pour les modèles CV, vLLM pour les LLM, KServe pour les périphériques sans serveur) tout en conservant une interface, une politique et une couche de télémétrie cohérentes.
La couche d'application et de contrôle : AI Gateway et MCP
Les couches décrites jusqu'à présent constituent la base de la création et de l'exécution de modèles d'IA. Cependant, pour rendre ces modèles accessibles de manière sûre et efficace aux applications des utilisateurs finaux et pour permettre des flux de travail complexes et agentiques, une dernière couche logicielle est requise : la couche d'application et de contrôle. Cette couche agit comme le système nerveux central pour toutes les interactions de l'IA, assurant la gouvernance, la sécurité et une interface standardisée pour la communication. Il comprend deux composants émergents essentiels : l'AI Gateway et le Model Context Protocol (MCP).
La passerelle IA : un plan de contrôle centralisé
Une passerelle IA est un intergiciel spécialisé qui sert de point de contrôle unique et centralisé pour tout le trafic lié à l'IA entre les applications et les modèles d'IA sous-jacents. Déployé dans un environnement sur site, souvent sur Kubernetes, il fournit un ensemble essentiel de fonctions pour gérer l'IA à l'échelle de l'entreprise.
Accès unifié et routage intelligent : La passerelle offre un point de terminaison d'API unique et cohérent pour les développeurs, éliminant ainsi la complexité liée à l'interaction avec plusieurs modèles différents (par exemple, une combinaison de modèles open source affinés et de modèles commerciaux spécialisés). Il peut effectuer un routage basé sur le contexte, en dirigeant les demandes vers le modèle le plus approprié en fonction de facteurs tels que le coût, les exigences de performance ou le cas d'utilisation spécifique, optimisant à la fois l'efficacité et les résultats.
Sécurité et gouvernance robustes : Pour l'IA sur site, la sécurité est primordiale. L'AI Gateway agit en tant que point d'application des politiques, s'intégrant à l'architecture de sécurité de l'entreprise pour gérer l'authentification, l'autorisation et le contrôle d'accès basé sur les rôles (RBAC). Il inspecte à la fois les demandes entrantes et les réponses sortantes en temps réel pour empêcher les attaques par injection rapide et les fuites de données d'informations sensibles telles que les informations personnelles identifiables (PII), garantissant ainsi la conformité aux réglementations telles que le RGPD et la HIPAA.
Observabilité complète et contrôle des coûts : La passerelle fournit un tableau de bord unifié pour surveiller toutes les interactions de l'IA, en suivant les indicateurs clés tels que la latence, les taux d'erreur et l'utilisation des jetons. Cette observabilité centralisée est cruciale pour le dépannage et l'optimisation des performances. En outre, il permet un contrôle granulaire des coûts en imposant des limites tarifaires et des budgets d'utilisation basés sur des jetons, en évitant les coûts exorbitants et en permettant des rétrofacturations précises aux différentes unités commerciales.
Le protocole MCP (Model Context Protocol) : le langage universel pour les agents d'IA
Alors que l'AI Gateway gère le flux des demandes, le Model Context Protocol (MCP) est un standard ouvert qui révolutionne que ces demandes peuvent suffire. Le MCP fournit aux modèles d'IA un moyen standardisé de découvrir et d'interagir avec des outils, des données et des services externes, les transformant ainsi de « cerveaux » isolés en agents intégrés performants.
Une interface standardisée pour les outils : Au lieu de créer un code personnalisé fragile pour chaque intégration, MCP permet aux systèmes d'entreprise (tels que les bases de données, les CRM ou les API internes) d'annoncer leurs capacités via un « serveur MCP » léger. L'application d'IA, agissant en tant qu' « hôte MCP », peut ensuite interroger ces serveurs pour comprendre quels outils sont disponibles et comment les utiliser, créant ainsi un écosystème prêt à l'emploi pour les agents d'IA.
Activation de l'IA agentique sur site : L'un des principaux avantages du MCP est qu'il s'agit d'un protocole ouvert et auditable qui peut être entièrement déployé dans le pare-feu d'une organisation. Cela permet aux entreprises de créer des agents d'IA puissants et autonomes capables d'interagir en toute sécurité avec des systèmes internes propriétaires sans exposer les données sensibles à des services externes.
Empêcher le verrouillage des fournisseurs : Étant donné que MCP est une norme indépendante du modèle prise en charge par des acteurs majeurs tels qu'Anthropic, OpenAI et Microsoft, elle dissocie le modèle d'IA des intégrations d'outils. Cela donne aux entreprises la flexibilité nécessaire pour échanger le LLM sous-jacent, par exemple en passant d'une API commerciale à un modèle affiné et auto-hébergé, sans avoir à reconstruire l'ensemble de la pile d'intégration, préservant ainsi la souveraineté technologique.
Ensemble, AI Gateway et MCP forment une puissante couche de contrôle et d'application qui rend l'IA sur site non seulement possible, mais également sécurisée, gérable et véritablement intégrée au tissu de l'entreprise.
La passerelle MCP de TrueFoundry combine les deux : gouvernance et observabilité pour chaque demande, ainsi que des appels d'outils sécurisés et audités via MCP afin que les agents puissent agir sur vos systèmes internes sans que les données ne quittent votre réseau.
Cartographie des fournisseurs sur l'ensemble de la pile d'IA sur site
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.
Conçu pour la vitesse : latence d'environ 10 ms, même en cas de charge

































.png)

.webp)
.webp)
.webp)



.webp)
.webp)


