

August 27, 2025
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: June 4, 2026

Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
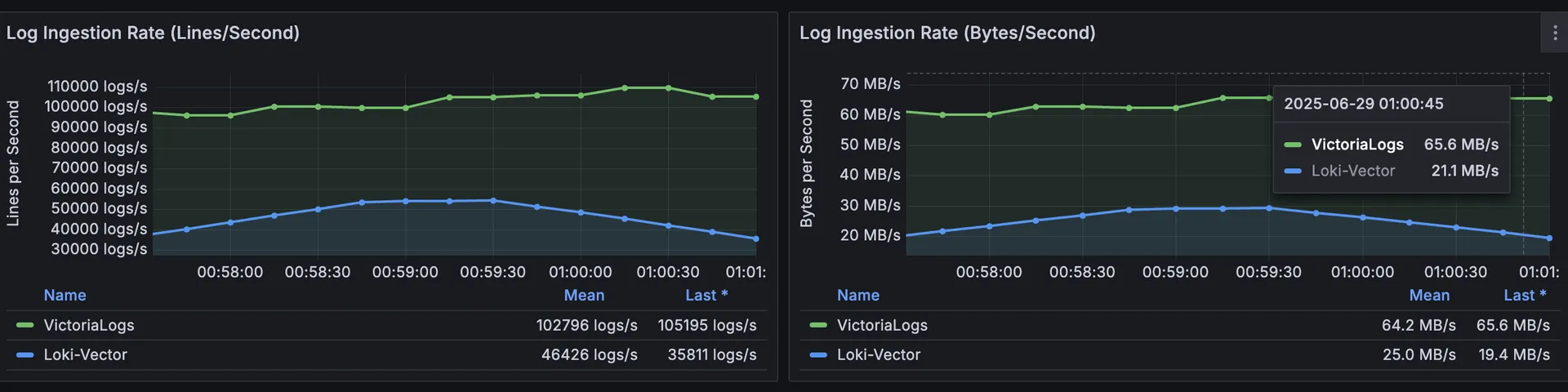
TL ; SEC — Après des tests côte à côte sur une charge de travail de 500 Go/7 jours, VictoriaLogs a réduit les latences des requêtes en 94 %, espace de stockage réduit de ≈ 40 %, et a utilisé < 50 % du processeur et de la RAM que nous avions précédemment alloués à Loki. Ce post explique pourquoi nous avons échangé.
Truefoundry aide les développeurs à exécuter des charges de travail ML mutualisées sur Kubernetes.
Les développeurs ont besoin de :
Loki nous a bien servis au début, mais à mesure que le volume augmentait, nous avons constaté des latences de recherche supérieures à 30 s et une amplification d'E/S élevée. Cela a déclenché une évaluation de VictoriaLogs.
Loki est le système d'agrégation de journaux de Grafana‑Labs qui stocke les journaux dans des blocs compressés accompagnés d'un index construit à partir de étiquettes (paires clé-valeur). Les requêtes sont exprimées en LogQL et s'appuient largement sur des filtres d'étiquettes suivis d'un filtrage en ligne.
Logs de Victoria est une base de données de journaux créée par l'équipe VictoriaMetrics. Il utilise des colonnes Style LSM stockage avec index par champ, recherche accélérée par SIMD et LogSQL de type SQL syntaxe.

[JOURNAL STATIQUE UNIQUE] ID=ABC123 XYZ dans un espace de noms rempli de journaux lourds pendant 7 jours.Finalité: Nombre total de lignes de journal provenant de app="servicefoundry-server »
Finalité: recherchez une ligne de journal statique unique dans véritable fonderie espace de noms
Finalité: Recherche d'un modèle de redémarrage connu : 3 000 dans un petit sous-ensemble de journaux (ciblant un seul fragment)
L'identité des ensembles de résultats a été vérifiée.
Finalité: recherche d'un journal inexistant, déclenchant une recherche complète des données
L'identité des ensembles de résultats a été vérifiée.
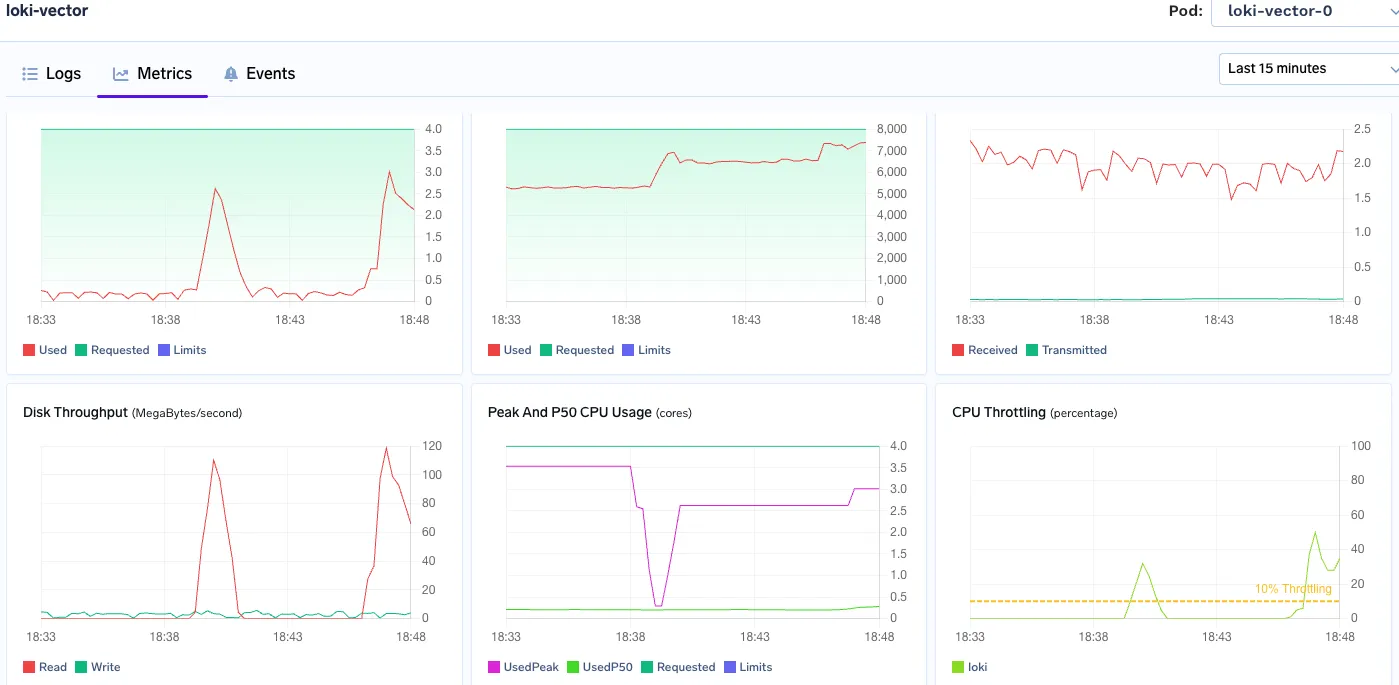
Sur 500 Go de données de traitement, Loki s'est comporté étrangement. Les ressources ont été bloquées et la réponse à la requête s'est arrêtée.
Notre évaluation s'est concentrée sur trois dimensions qui sont importantes au quotidien pour les ingénieurs de plateformes :
Pourquoi cet écart ? VictoriaLogs gère un index par jeton, de sorte que même les scans de type regex sont assistés par indexation. Loki, en revanche, filtre ligne par ligne après une requête d'étiquette, qui se transforme en un scan par force brute lorsque le jeu d'étiquettes est large.
Nous avons également testé l'ingestion sous contrainte avec 120 répliques de notre fougette générateur.
Les résultats ont été révélateurs :
Loki:
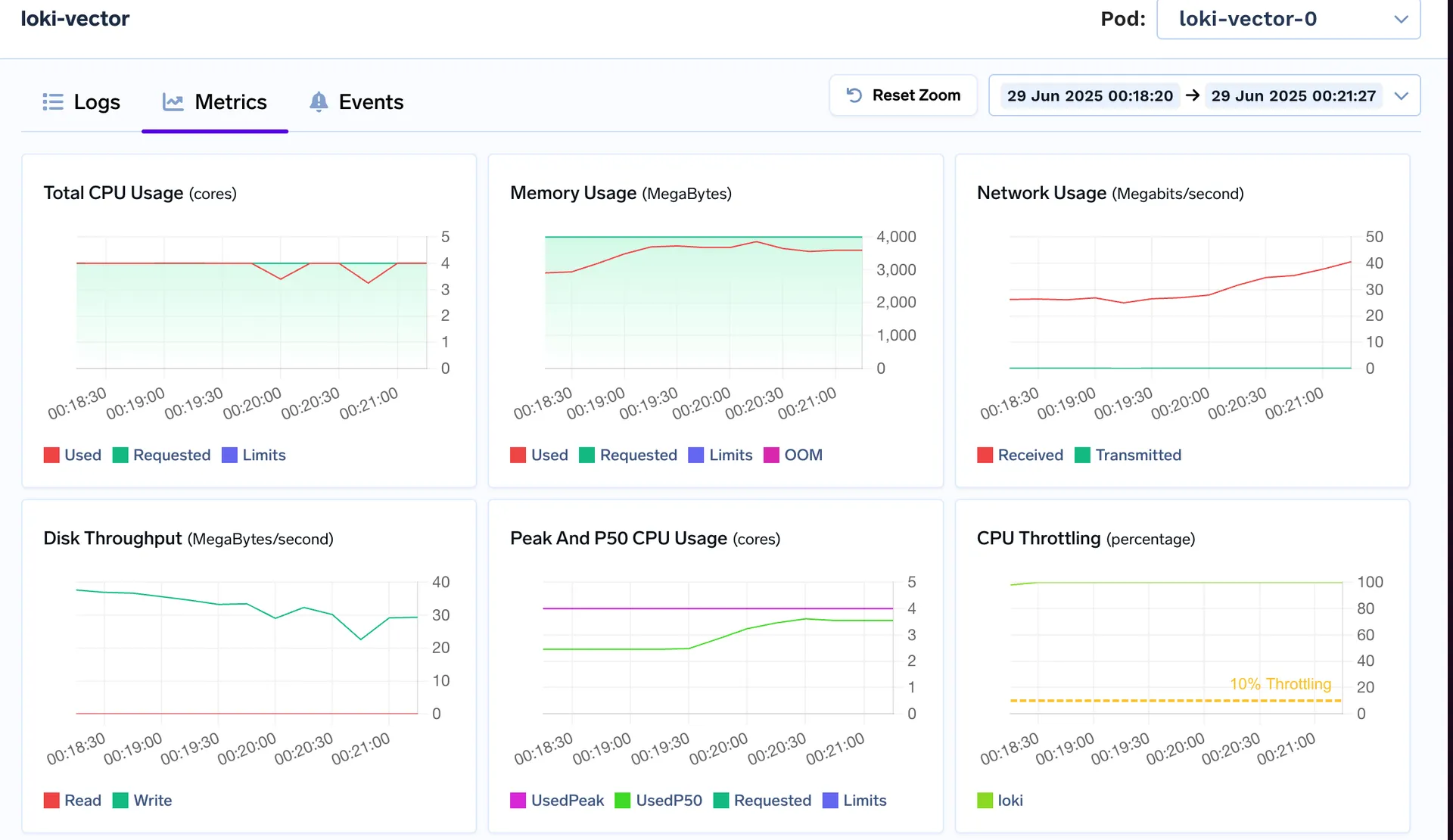
Loki passe à 3 à 4 processeurs virtuels, approche de sa limite de 8 Go et montre des signes de ralentissement pour la même charge de travail
Logs Victoria :
👉 Principaux plats à emporter: VictoriaLogs livré Vitesse d'ingestion 3 fois plus élevée tout en consommant 72 % de processeur en moins et 87 % de mémoire en moins comparé à Loki.
VictoriaLogs reste confortablement en dessous de ses limites de 4 vCPU/8 GiB, même en cas de rafale d'ingestion
Mémoire utilisée : utilisation constante de 6 à 7 Go de RAM
Puissance maximale du processeur : 3 vCPU
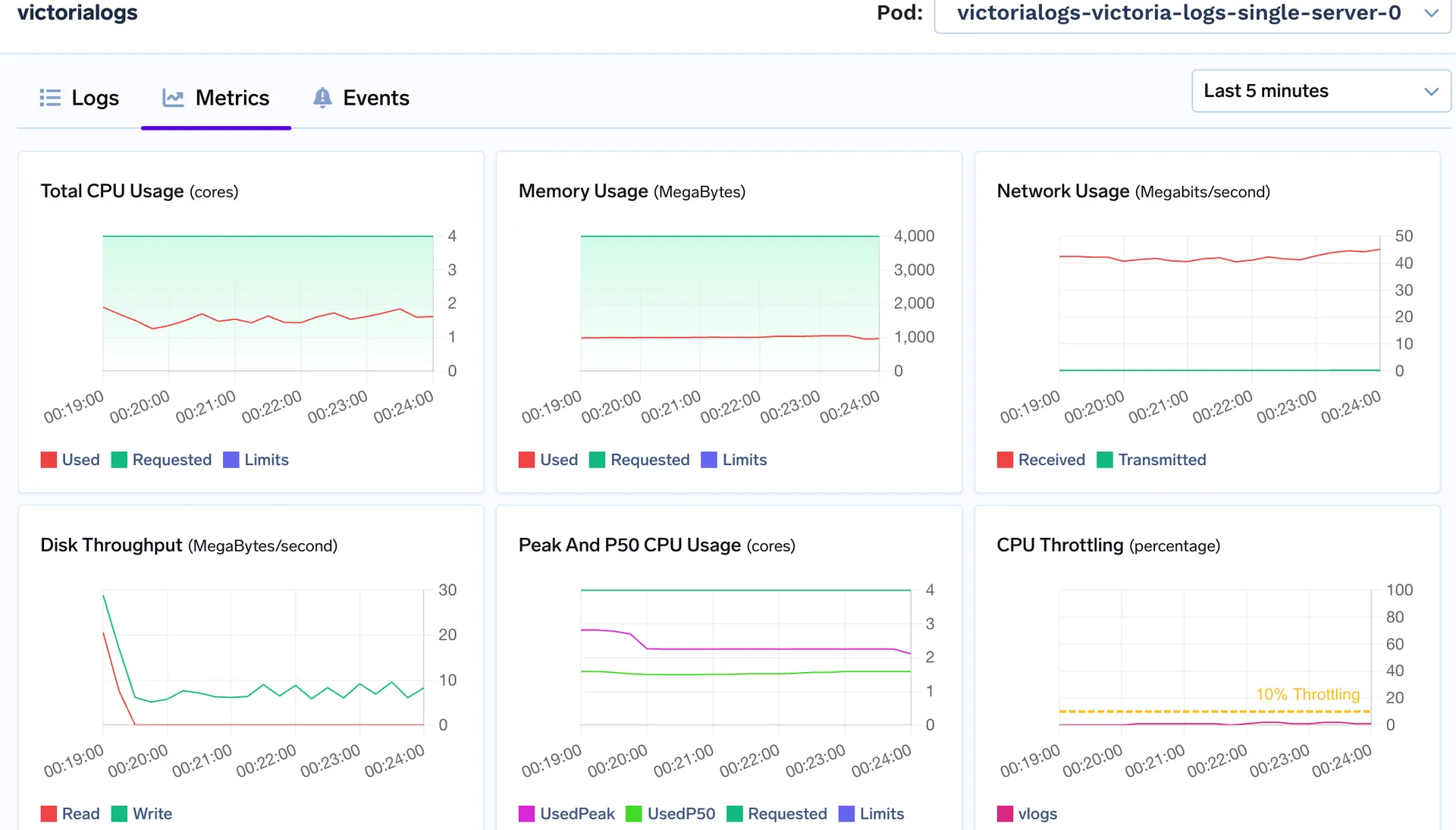
Logs de Victoria
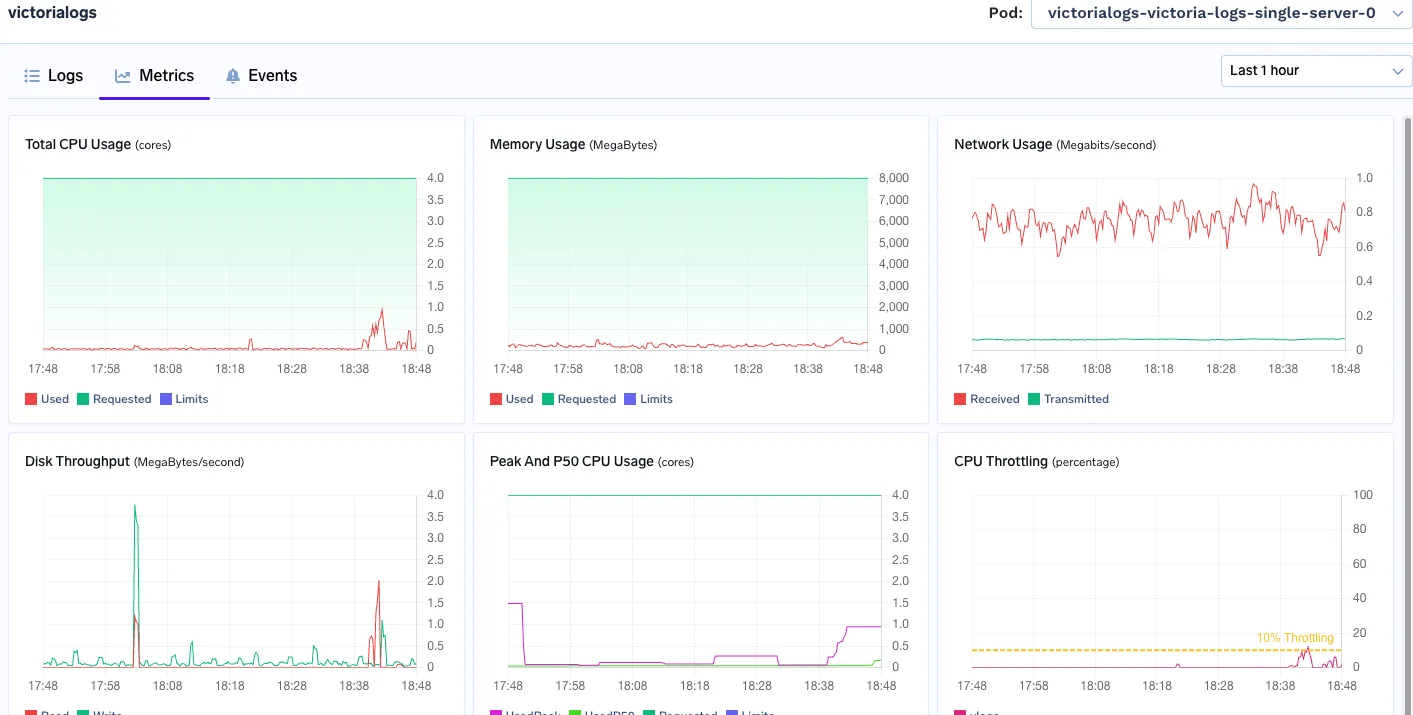
Mémoire utilisée : 800 Mo - 900 Mo
Utilisation maximale du processeur : 1.1 vCPU
Les requêtes étaient similaires, avec des limites aléatoires et une plage de temps aléatoire, pour garantir des rafales de cache.
Victoria Logs
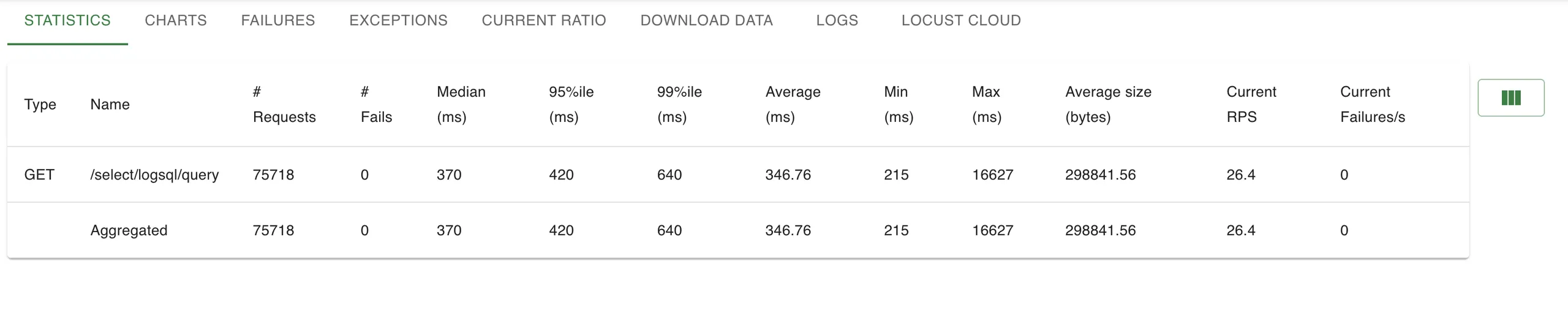
Loki

📌 Malgré la manipulation RPS 36 % plus élevé, VictoriaLogs a enregistré un p inférieur de 95 % et des latences inférieures, ce qui prouve que son modèle d'indexation résiste à la pression avec 3,6 fois plus rapide Fichier Pp 99%
Ce test a renforcé notre décision : VictoriaLogs n'est pas seulement plus rapide en théorie, il s'adapte mieux au stress des charges de travail similaires à celles liées à la production.
Conclusion : pour un cas d'utilisation centré sur la recherche et riche en journaux, VictoriaLogs nous permet de répondre aux questions en quelques secondes au lieu de quelques minutes tout en réduisant les coûts d'infrastructure.
Pour les profils de charge de travail nécessitant une recherche de texte ad hoc, VictoriaLogs a fourni ordre de grandeur des requêtes plus rapides et des économies de coûts matériels. Loki reste un excellent choix lorsque l'intégration étroite de Grafana et les requêtes privilégiant les étiquettes dominent, mais VictoriaLogs est désormais notre solution par défaut pour les clusters centrés sur les développeurs à forte ingestion.
La principale différence entre Victorialogs et Loki réside dans l'indexation avancée par jeton et le stockage en colonnes de VictoriaLogs. Cela permet des performances de requête beaucoup plus rapides et une utilisation des ressources nettement inférieure par rapport à l'indexation basée sur les étiquettes de Loki, ce qui entraîne souvent un ralentissement des recherches complètes et une augmentation des frais opérationnels liés à la gestion des journaux.
Oui, lors de notre analyse comparative rigoureuse, VictoriaLogs a démontré une vitesse supérieure à celle de Loki. Pour les comparaisons entre Victorialogs et Loki, VictoriaLogs a réduit les latences des requêtes de 94 % et a obtenu des temps de recherche 12 fois plus rapides pour les requêtes complexes. Il a également obtenu des performances d'ingestion 3 fois plus élevées, ce qui le rend nettement plus efficace.
Lorsque vous évaluez Victorialogs par rapport à Loki, il est utile de connaître les détails de configuration. VictoriaLogs utilise généralement le port 8428 pour son API HTTP par défaut et ses points de terminaison de scraping. Ce port permet d'accéder à la base de données des journaux et d'interagir avec celle-ci. Bien que notre blog soit axé sur les performances, il est essentiel de comprendre les principes de base du déploiement, tels que le port par défaut, pour la configuration du système.
Dans les benchmarks comparant Victorialogs à Loki, VictoriaLogs a enregistré des performances supérieures. Il a permis de réduire de 94 % les latences des requêtes, de réduire l'utilisation du stockage d'environ 40 % et de consommer moins de 50 % du processeur et de la RAM alloués. VictoriaLogs a également présenté un débit d'ingestion 3 fois plus élevé, ce qui le rend très efficace.
Lors de notre comparaison entre Victorialogs et Loki, VictoriaLogs s'est révélé supérieur. Il a réduit les latences des requêtes de 94 %, réduit le stockage de 40 % et a utilisé plus de 50 % de CPU/RAM en moins. TrueFoundry aux États-Unis a choisi VictoriaLogs pour ses performances et son efficacité accrues en matière de gestion des charges de travail de machine learning.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception







.png)

.webp)
.webp)
.webp)



.webp)
.webp)


