

July 20, 2023
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: April 22, 2026

Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
Supposons qu'il existe un équipe A chargé de développer l'application RAG pour cas d'utilisation 1, alors il y a équipe B qui développe une application RAG pour cas d'utilisation 2, et puis il y a équipe C, qui ne fait que planifier le prochain cas d'utilisation de son application RAG. Avez-vous souhaité qu'il soit facile de créer des pipelines RAG pour plusieurs équipes ? Chaque équipe n'a pas besoin de partir de zéro, mais d'une manière modulaire permettant à chaque équipe d'utiliser les mêmes fonctionnalités de base et de développer efficacement ses propres applications en plus de celles-ci, sans aucune interférence ?
Ne t'inquiète pas ! C'est pourquoi nous avons créé Cognita. Bien que RAG soit indéniablement impressionnant, le processus de création d'une application fonctionnelle avec celui-ci peut être intimidant. Il y a beaucoup à comprendre en ce qui concerne les pratiques de mise en œuvre et de développement, allant de la sélection des modèles d'IA appropriés pour un cas d'utilisation spécifique à l'organisation efficace des données pour obtenir les informations souhaitées. Alors que des outils tels que Chaîne Lang et Indice de lama existent pour simplifier le processus de conception des prototypes, il n'existe pas encore de modèle RAG open source accessible et prêt à l'emploi qui intègre les meilleures pratiques et offre un support modulaire, permettant à quiconque de l'utiliser rapidement et facilement.
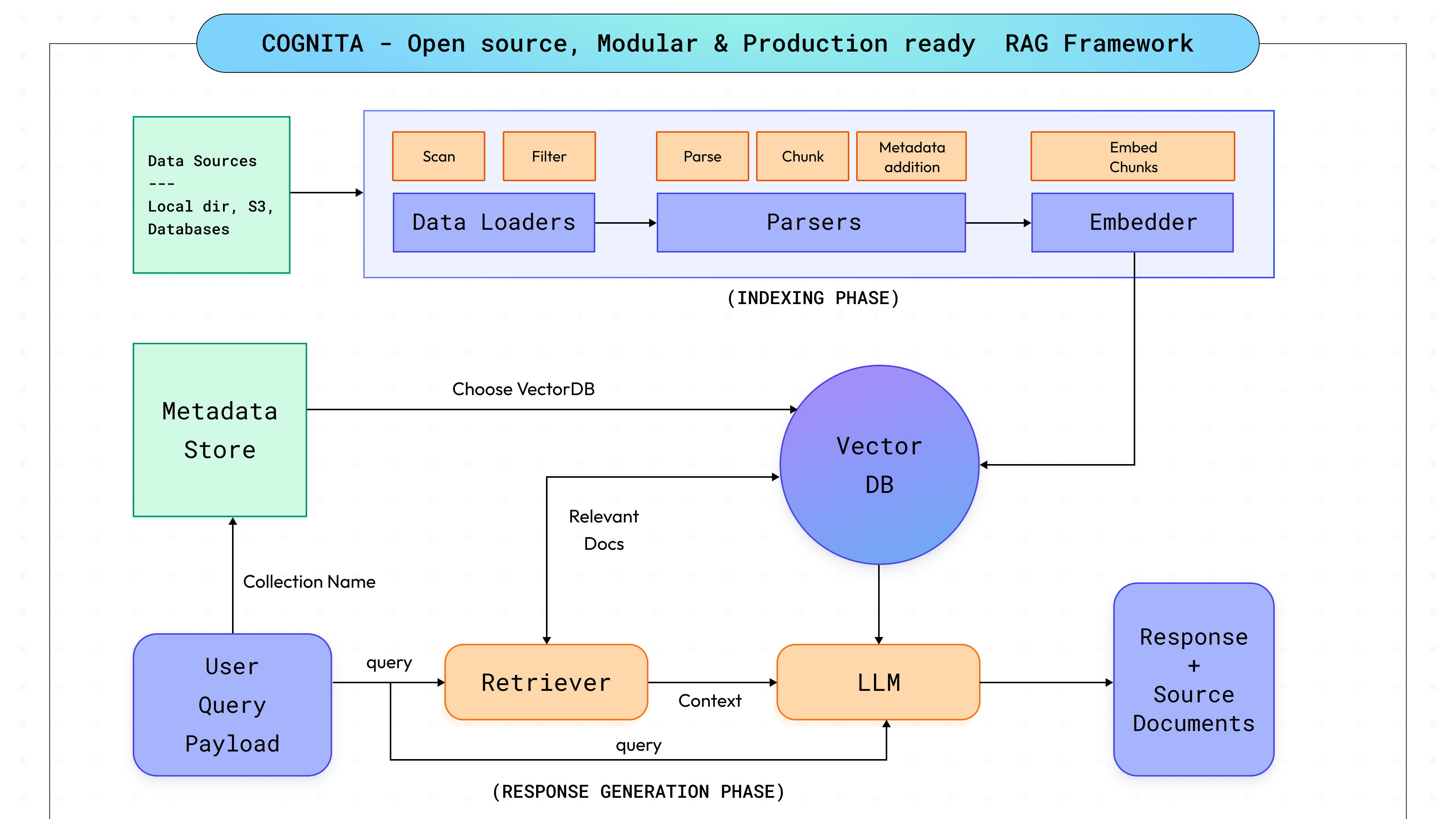
En explorant le fonctionnement interne de Cognita, notre objectif était de trouver un équilibre entre personnalisation complète et adaptabilité tout en garantissant la facilité d'utilisation dès le départ. Compte tenu du rythme rapide des avancées en matière de RAG et d'IA, il était impératif pour nous de concevoir Cognita en tenant compte de l'évolutivité, afin de permettre une intégration fluide des nouvelles avancées et des divers cas d'utilisation. Cela nous a amenés à décomposer le processus RAG en étapes modulaires distinctes (comme le montre le schéma ci-dessus, qui sera discuté dans les sections suivantes), facilitant ainsi la maintenance du système, l'ajout de nouvelles fonctionnalités telles que l'interopérabilité avec d'autres bibliothèques d'IA et permettant aux utilisateurs d'adapter la plateforme à leurs besoins spécifiques. Notre objectif reste de fournir aux utilisateurs un outil robuste qui non seulement répond à leurs besoins actuels, mais qui évolue également en même temps que la technologie, y compris des changements architecturaux plus généraux tels que MCP contre RAG, garantissant une valeur à long terme.
Cognita est conçu autour de sept modules différents, chacun étant personnalisable et contrôlable pour répondre à différents besoins :
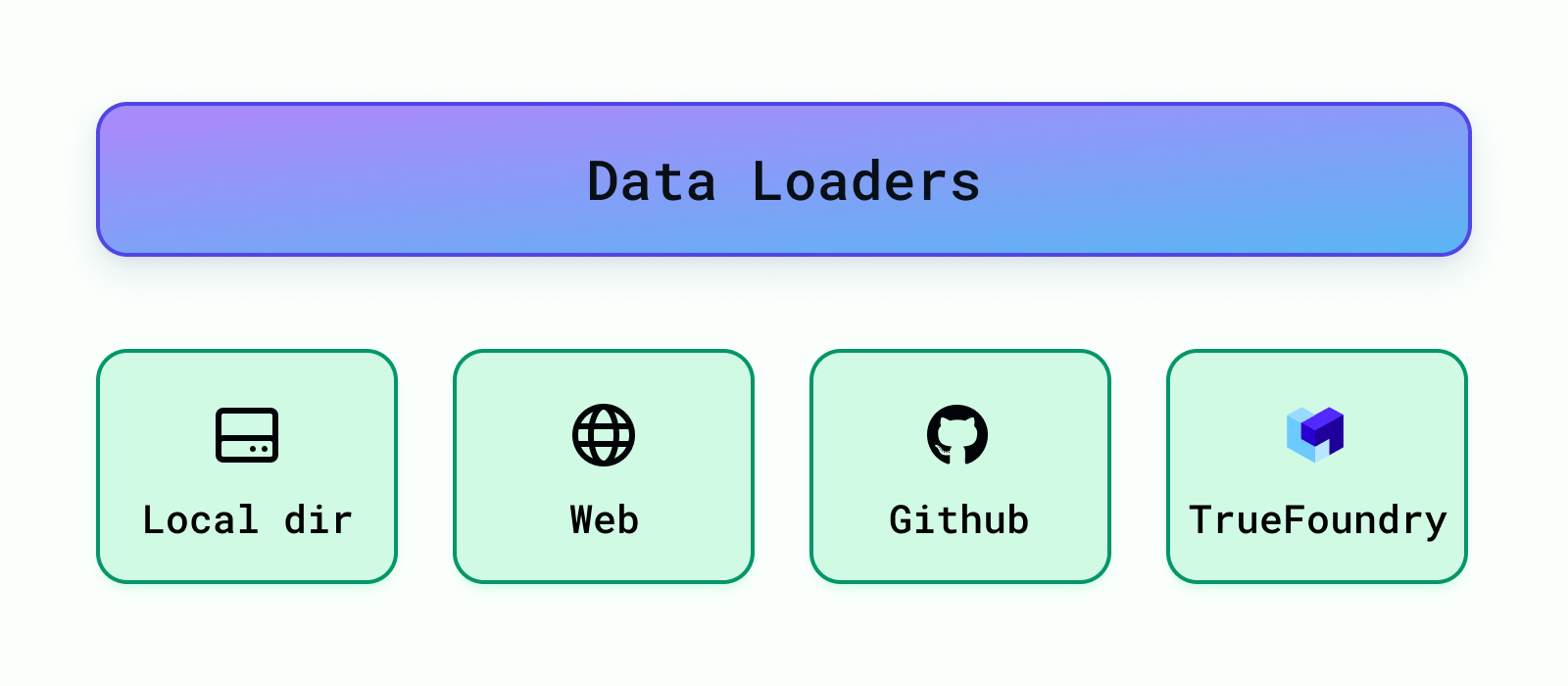
Ceux-ci chargent les données à partir de différentes sources telles que les répertoires locaux, les compartiments S3, les bases de données, Véritable fonderie artefacts, etc. Cognita prend actuellement en charge le chargement de données depuis le répertoire local, l'URL Web, le référentiel Github et les artefacts Truefoundry. D'autres chargeurs de données peuvent être facilement ajoutés sous backend/modules/chargeurs de données/ . Une fois qu'un chargeur de données est ajouté, vous devez l'enregistrer afin qu'il puisse être utilisé par l'application RAG sous backend/modules/dataloaders/__init__.py Pour enregistrer un chargeur de données, ajoutez les éléments suivants :
Au cours de cette étape, nous traitons différents types de données, tels que des fichiers texte classiques, des PDF et même des fichiers Markdown. L'objectif est de transformer tous ces différents types en un format commun afin que nous puissions les utiliser plus facilement par la suite. Cette partie, appelée analyse syntaxique, est généralement la plus longue et est difficile à implémenter lorsque nous configurons un système comme celui-ci. Mais l'utilisation de Cognita peut être utile, car elle gère déjà pour nous le dur labeur que représente la gestion des pipelines de données.
Après cela, nous avons divisé les données analysées en morceaux uniformes. Mais pourquoi en avons-nous besoin ? Le texte que nous obtenons des fichiers peut être de différentes longueurs. Si nous utilisons directement ces longs textes, nous finirons par ajouter un tas d'informations inutiles. De plus, étant donné que tous les LLM ne peuvent traiter qu'une certaine quantité de texte à la fois, nous ne serons pas en mesure d'inclure tout le contexte important nécessaire à la question. Nous allons donc plutôt décomposer le texte en parties plus petites pour chaque section. Intuitivement, les petits morceaux contiendront des concepts pertinents et seront moins bruyants que les gros morceaux.
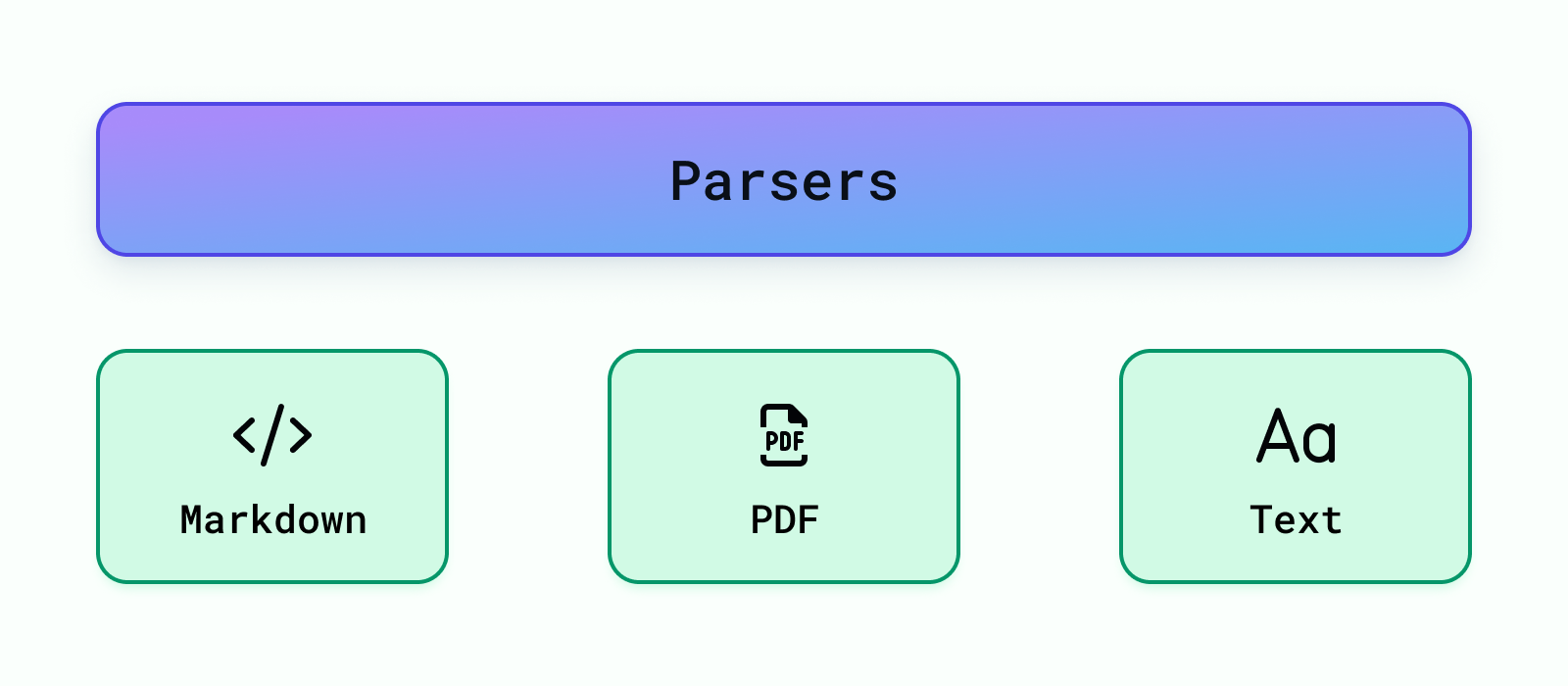
Actuellement, nous prenons en charge l'analyse de Markdown, PDF et Texte fichiers. D'autres analyseurs de données peuvent être facilement ajoutés sous backend/modules/analyseurs/ . Une fois qu'un analyseur est ajouté, vous devez l'enregistrer afin qu'il puisse être utilisé par l'application RAG sous backend/modules/parsers/__init__.py Pour enregistrer un analyseur, ajoutez ce qui suit :
Une fois que nous avons divisé les données en plus petits morceaux, nous voulons trouver les éléments les plus importants pour une question spécifique. Un moyen rapide et efficace d'y parvenir consiste à utiliser un modèle pré-entraîné (modèle d'intégration) pour convertir nos données et la question en codes spéciaux appelés intégrations. Ensuite, nous comparons les intégrations de chaque bloc de données à celui de la question. En mesurant similitude en cosinus entre ces intégrations, nous pouvons déterminer quels morceaux sont les plus étroitement liés à la question, ce qui nous aide à trouver les meilleurs à utiliser.
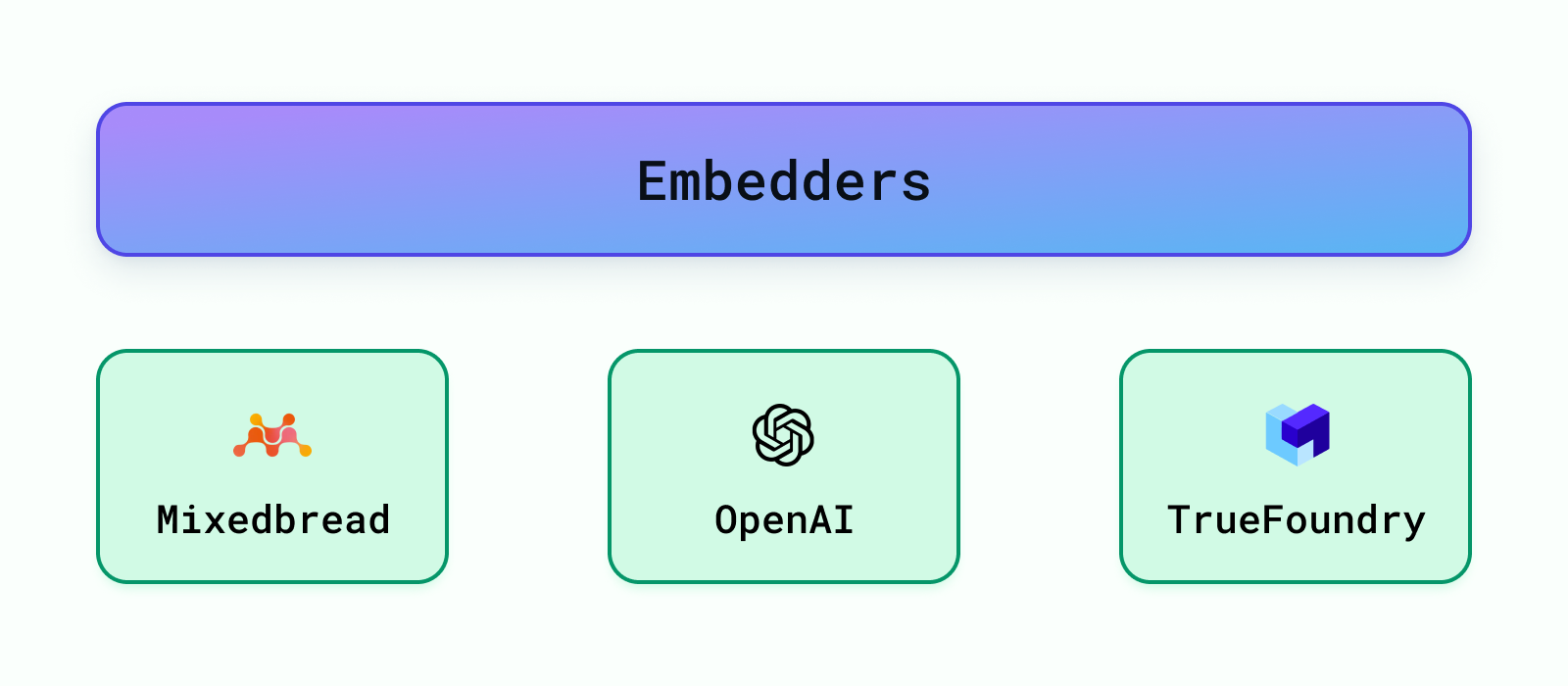
Il existe de nombreux modèles pré-entraînés disponibles pour intégrer les données, tels que les modèles d'OpenAI, de Cohere, etc. Les modèles les plus populaires peuvent être découverts via Le benchmark d'intégration de texte massif de HuggingFace (MTEB) classement. Nous fournissons un support pour OpenAI Embeddings, TrueFoundry Embeddings et également les versions actuelles SOTA intégrations (en avril 2024) de pain mixé-ai.
D'autres intégrateurs peuvent être facilement ajoutés sous backend/modules/embedder/ . Une fois qu'un intégrateur est ajouté, vous devez l'enregistrer afin qu'il puisse être utilisé par l'application RAG sous backend/modules/embedders/__init__.py Pour enregistrer un analyseur, ajoutez ce qui suit :
Remarque : N'oubliez pas que les intégrations ne sont pas la seule méthode pour trouver des morceaux importants. Nous pourrions également utiliser un LLM pour cette tâche ! Cependant, les LLM sont beaucoup plus volumineux que les modèles d'intégration et ont une limite quant à la quantité de texte qu'ils peuvent gérer à la fois. C'est pourquoi il est plus intelligent d'utiliser les intégrations pour sélectionner en premier les k meilleurs morceaux. Ensuite, nous pouvons utiliser les LLM sur ces quelques segments afin de déterminer les meilleurs à utiliser comme contexte pour répondre à notre question.
Une fois que l'étape d'intégration trouve des correspondances potentielles, ce qui peut être beaucoup, une étape de reclassement est appliquée. Reclassement pour s'assurer que les meilleurs résultats sont au sommet. Par conséquent, nous pouvons choisir les x meilleurs documents, ce qui rend notre contexte plus concis et les requêtes rapides plus courtes. Nous fournissons le soutien pour SOTA reclassement (en avril 2024) de pain mixé-ai qui est mis en œuvre dans backend/modules/reanker/
Une fois que nous avons créé des vecteurs pour les textes, nous les stockons dans ce que l'on appelle une base de données vectorielles. Cette base de données garde une trace de ces vecteurs afin que nous puissions les retrouver rapidement ultérieurement en utilisant différentes méthodes. Les bases de données classiques organisent les données dans des tableaux, tels que des lignes et des colonnes, mais les bases de données vectorielles sont spéciales car elles stockent et trouvent des données en fonction de ces vecteurs. C'est très utile pour des choses comme reconnaître des images, comprendre un langage ou recommander des choses. Par exemple, dans un système de recommandation, chaque article que vous souhaitez recommander (comme un film ou un produit) est transformé en vecteur, avec différentes parties du vecteur représentant différentes caractéristiques de l'article, comme son genre ou son prix. De même, dans le domaine du langage, chaque mot ou document est transformé en vecteur, certaines parties du vecteur représentant les caractéristiques du mot ou du document, comme la fréquence à laquelle le mot est utilisé ou sa signification. Ces bases de données vectorielles sont conçues pour les gérer efficacement. En utilisant différentes méthodes pour mesurer la proximité des vecteurs les uns par rapport aux autres, par exemple leur similitude ou leur distance, nous trouvons les vecteurs les plus proches de la requête utilisateur donnée. Les méthodes les plus courantes pour mesurer cela sont la distance euclidienne, la similarité des cosinus et le produit scalaire.
Il existe plusieurs bases de données vectorielles disponibles sur le marché, telles que Qdrant, SingleStore, Weaviate, etc. Nous prenons actuellement en charge Qdrant et Boutique unique. La classe de base de données du vecteur Qdrant est définie sous /backend/modules/vector_db/qdrant.py, tandis que la classe de base de données vectorielle SingleStore est définie sous /backend/modules/vector_db/singlestore.py
D'autres dbs vectoriels peuvent également être ajoutés dans le vecteur_db dossier et peut être enregistré sous /backend/modules/vector_db/__init__.py
Pour ajouter un support de base de données vectorielle dans Cognita, l'utilisateur doit procéder comme suit :
Vecteur de base DB (depuis backend.modules.vector_db.base, importez BaseVectorDB) et initialisez-le avec Configuration vectorielle DBConfig (depuis backend.types import VectorDBConfig)créer_collection: Pour initialiser la collection/le projet/la table dans la base de données vectorielle.documents bouleversés: Pour insérer les documents dans la base de données.obtenir_collections: Obtenez toutes les collections présentes dans la base de données.supprimer_collection: Pour supprimer la collection de la base de données.get_vector_store: Pour obtenir la boutique vectorielle de la collection donnée.obtenir_vector_client: Pour obtenir le client vectoriel pour la collection donnée, le cas échéant.liste_point_de_données_vecteurs: Pour répertorier les vecteurs déjà présents dans la base de données qui sont similaires aux documents en cours d'insertion.supprime_données_point_vecteurs: Pour supprimer les vecteurs de la base de données, utilisé pour supprimer les anciens vecteurs du document mis à jour.Nous montrons maintenant comment ajouter une nouvelle base de données vectorielle au système RAG. Nous prenons l'exemple des deux Qdrant et Boutique unique vecteur dbs.
Qdrant est une base de données vectorielle open source et un moteur de recherche vectorielle écrits en Rust. Il fournit un vecteur rapide et évolutif recherche de similarité service avec une API pratique. Pour ajouter la base de données vectorielles Qdrant au système RAG, procédez comme suit :
Dans le fichier .env, vous pouvez ajouter les éléments suivants
VECTOR_DB_CONFIG = '{"url » : "<url_here>«, « provider » : « qdrant"}' # URL Qdrant pour l'instance déployéeVECTOR_DB_CONFIG=' {"provider » :"qdrant », « local » :"true "} '# Pour une instance Qdrant locale basée sur un fichier sans docker
Vecteur QDRANTDB dans backend/modules/vector_db/qdrant.py qui hérite de Vecteur de base DB et initialisez-le avec Configuration vectorielle DBConfigcréer_collection méthode pour créer une collection dans Qdrantdocuments bouleversés méthode pour insérer les documents dans la base de donnéesobtenir_collections méthode pour obtenir toutes les collections présentes dans la base de donnéessupprimer_collection méthode pour supprimer la collection de la base de donnéesget_vector_store méthode pour obtenir le magasin vectoriel pour la collection donnéeobtenir_vector_client méthode pour obtenir le client vectoriel pour la collection donnée, le cas échéantliste_point_de_données_vecteurs méthode pour répertorier les vecteurs déjà présents dans la base de données qui sont similaires aux documents en cours d'insertionsupprime_données_point_vecteurs méthode pour supprimer les vecteurs de la base de données, utilisée pour supprimer les anciens vecteurs du document mis à jourSingleStore propose de puissantes fonctionnalités de base de données vectorielles parfaitement adaptées aux applications basées sur l'IA, aux chatbots, à la reconnaissance d'images, etc., vous évitant ainsi d'avoir à gérer une base de données vectorielle spécialisée uniquement pour vos charges de travail vectorielles. Contrairement aux bases de données vectorielles traditionnelles, SingleStore stocke les données vectorielles dans des tables relationnelles avec d'autres types de données. La co-localisation de données vectorielles avec des données associées vous permet d'interroger facilement des métadonnées étendues et d'autres attributs de vos données vectorielles avec toute la puissance de SQL.
SingleStore propose un niveau gratuit permettant aux développeurs de démarrer avec leur base de données vectorielles. Vous pouvez créer un compte gratuitement ici. Lors de votre inscription, rendez-vous sur Nuage -> espace de travail -> Créer un utilisateur. Utilisez les informations d'identification pour vous connecter à l'instance SingleStore.
Dans le fichier .env, vous pouvez ajouter les éléments suivants
VECTOR_DB_CONFIG = '{"url » : "<url_here>«, « provider » : « singlestore"}' # url : mysql ://{utilisateur} : {mot de passe} @ {hôte} : {port}/{db}
Pour ajouter la base de données vectorielles SingleStore au système RAG, procédez comme suit :
Vector DB à magasin unique dans backend/modules/vector_db/singlestore.py qui hérite de Vecteur de base DB et initialisez-le avec Configuration vectorielle DBConfigcréer_collection méthode pour créer une collection dans SingleStoredocuments bouleversés méthode pour insérer les documents dans la base de donnéesobtenir_collections méthode pour obtenir toutes les collections présentes dans la base de donnéessupprimer_collection méthode pour supprimer la collection de la base de donnéesget_vector_store méthode pour obtenir le magasin vectoriel pour la collection donnéeobtenir_vector_client méthode pour obtenir le client vectoriel pour la collection donnée, le cas échéantliste_point_de_données_vecteurs méthode pour répertorier les vecteurs déjà présents dans la base de données qui sont similaires aux documents en cours d'insertionsupprime_données_point_vecteurs méthode pour supprimer les vecteurs de la base de données, utilisée pour supprimer les anciens vecteurs du document mis à jourIl contient les configurations nécessaires qui définissent de manière unique un projet ou une application RAG. Une application RAG peut contenir un ensemble de documents provenant d'une ou de plusieurs sources de données combinées, que nous appelons collection. Les documents provenant de ces sources de données sont indexés dans la base de données vectorielle à l'aide de méthodes de chargement, d'analyse et d'intégration des données. Pour chaque cas d'utilisation de RAG, le magasin de métadonnées contient :
Nous définissons actuellement deux manières de stocker ces données, l'une localement et autres utilisations Truefoudry. Ces magasins sont définis comme suit : backend/modules/metada_store/
Une fois les données indexées et stockées dans la base de données vectorielles, il est maintenant temps de combiner toutes les parties pour utiliser notre application. C'est exactement ce que font les contrôleurs de requêtes ! Ils nous aident à trouver la réponse à la requête de l'utilisateur correspondante. Les étapes typiques d'un contrôleur de requêtes sont les suivantes :
nom de la collection pertinent base de données vectorielle est corrigé avec sa configuration, comme l'intégrateur utilisé, le type de base de données vectorielle, etc.requête, les documents pertinents sont récupérés à l'aide du retriever à partir de Vector DB.contexte et avec la requête a.k.a question est donné au LLM pour générer la réponse. Cette étape peut également impliquer un réglage rapide.Remarque : Dans le cas des agents, les étapes intermédiaires peuvent également être diffusées en continu. C'est à l'application concernée de décider.
Les méthodes des contrôleurs de requêtes peuvent être directement exposées en tant qu'API, en ajoutant des décorateurs http aux fonctions respectives.
Pour ajouter votre propre contrôleur de requêtes, procédez comme suit :
application-2. Par conséquent, nous allons écrire notre contrôleur sous /backend/modules/query_controller/app-2/controller.pycontrôleur de requêtes décorateur à votre classe et transmettez le nom de votre contrôleur personnalisé en argumentposte, obtenir, supprimer pour transformer vos méthodes en APIbackend/modules/query_controllers/__init__.pyUn exemple de contrôleur de requêtes est écrit sous la forme suivante : /backend/modules/query_controller/example/controller.py Veuillez vous référer pour une meilleure compréhension
Un processus Cognita typique comprend deux phases :
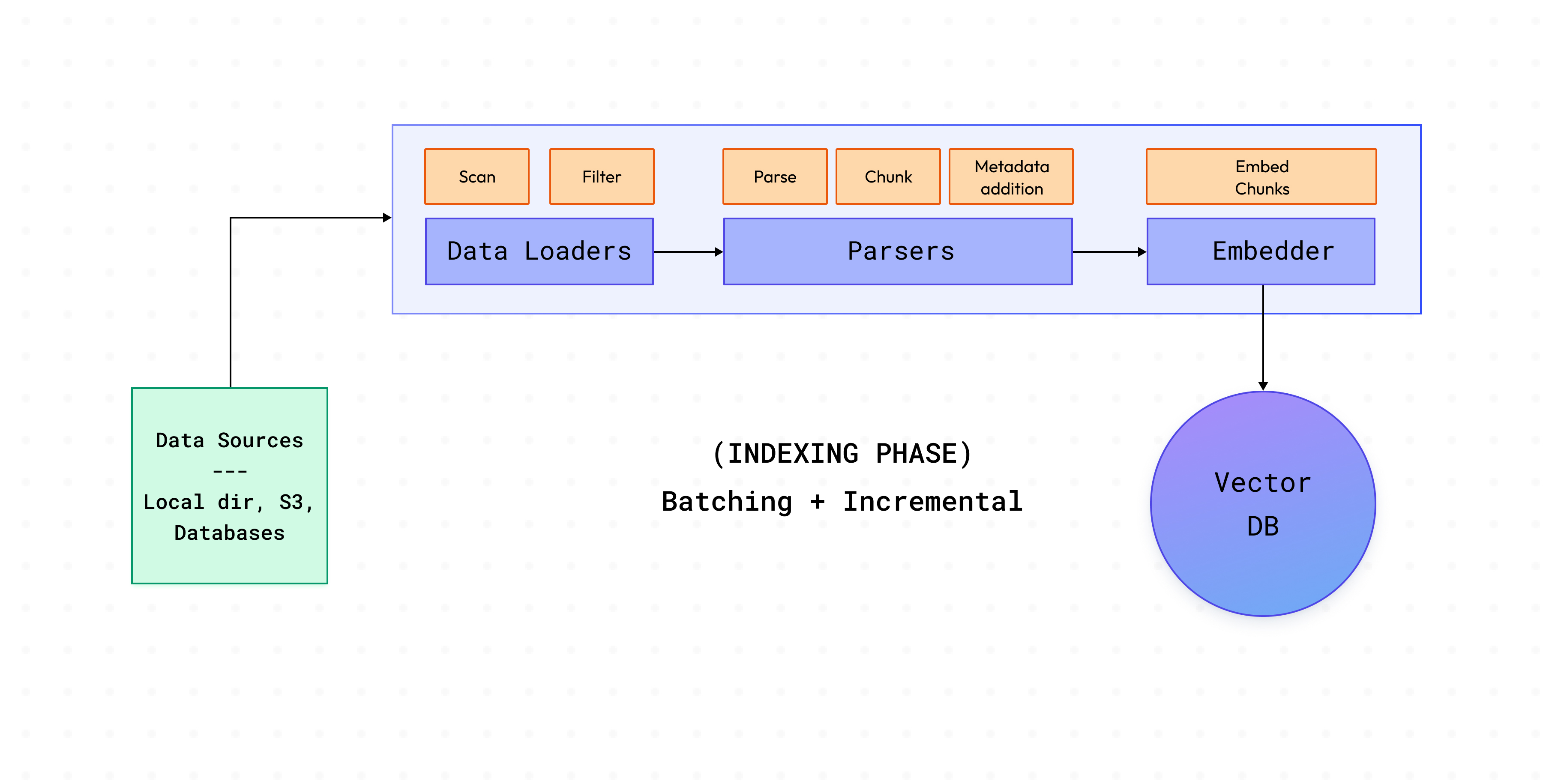
Cette phase implique le chargement de données à partir de sources, l'analyse des documents présents dans ces sources et leur indexation dans la base de données vectorielle. Pour traiter de grandes quantités de documents rencontrés en production, Cognita va encore plus loin.
INCRÉMENTIEL indexation, il existe également un autre mode pris en charge dans Cognita, à savoir COMPLET indexation. COMPLET l'indexation réingère les données dans la base de données vectorielles indépendamment des données vectorielles présentes pour la collection donnée.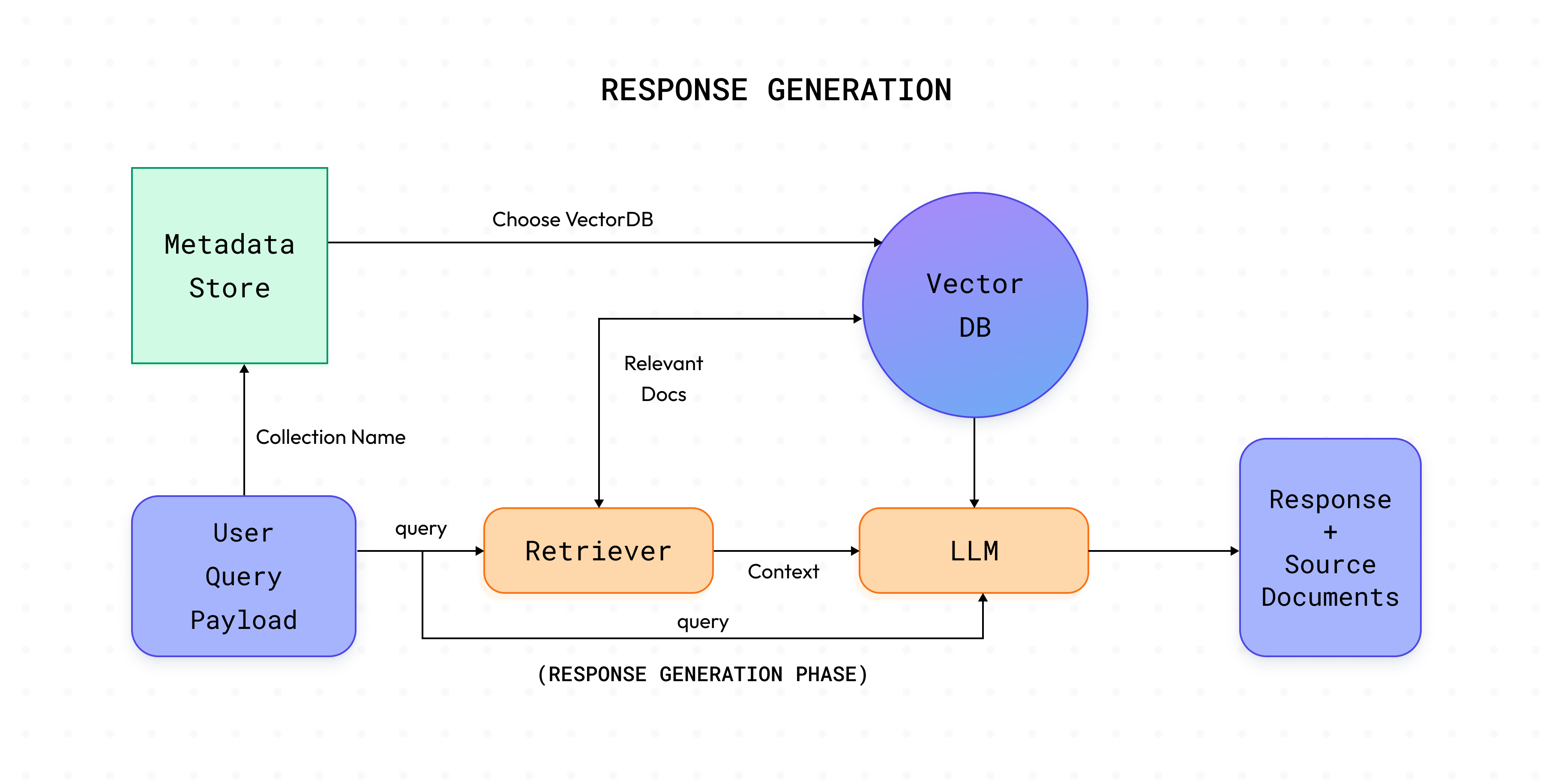
La phase de génération de réponse lance un appel au /réponse point de terminaison de votre définition Contrôleur de requêtes et génère la réponse à la requête demandée.
Les étapes suivantes vous montreront comment utiliser l'interface utilisateur de Cognita pour interroger des documents :
1. Créer une source de données
Sources de données onglet 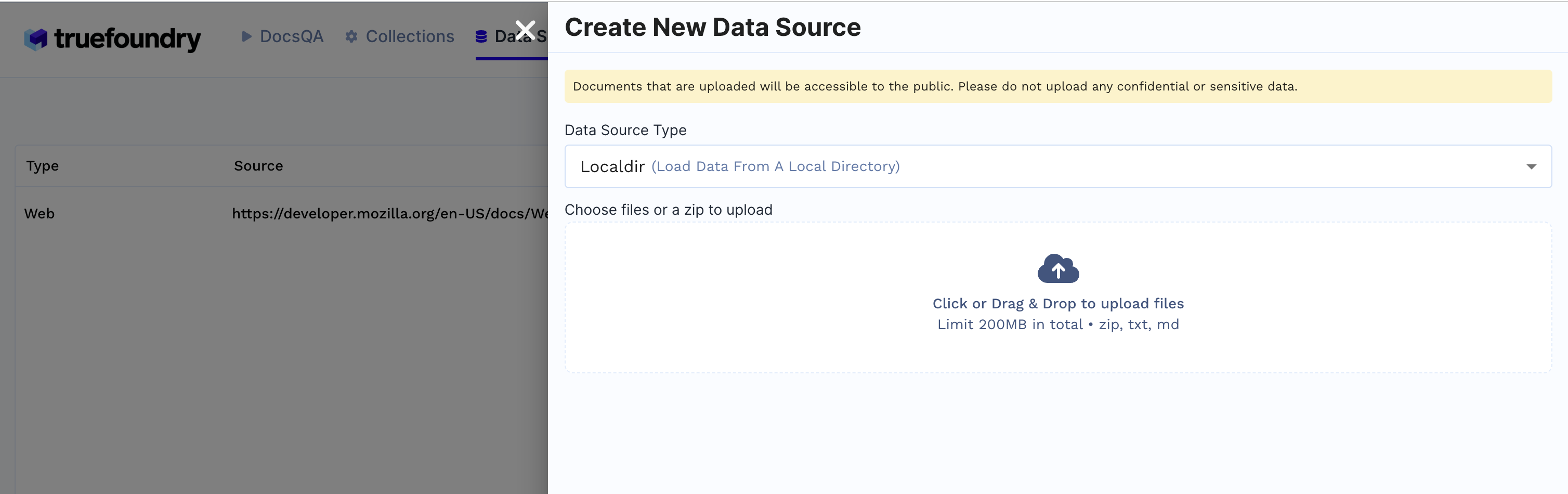
+ Nouvelle source de donnéesLocaldir est sélectionné, téléchargez des fichiers depuis votre machine et cliquez sur Soumettre.
2. Créer une collection
Collections onglet+ Nouvelle collection 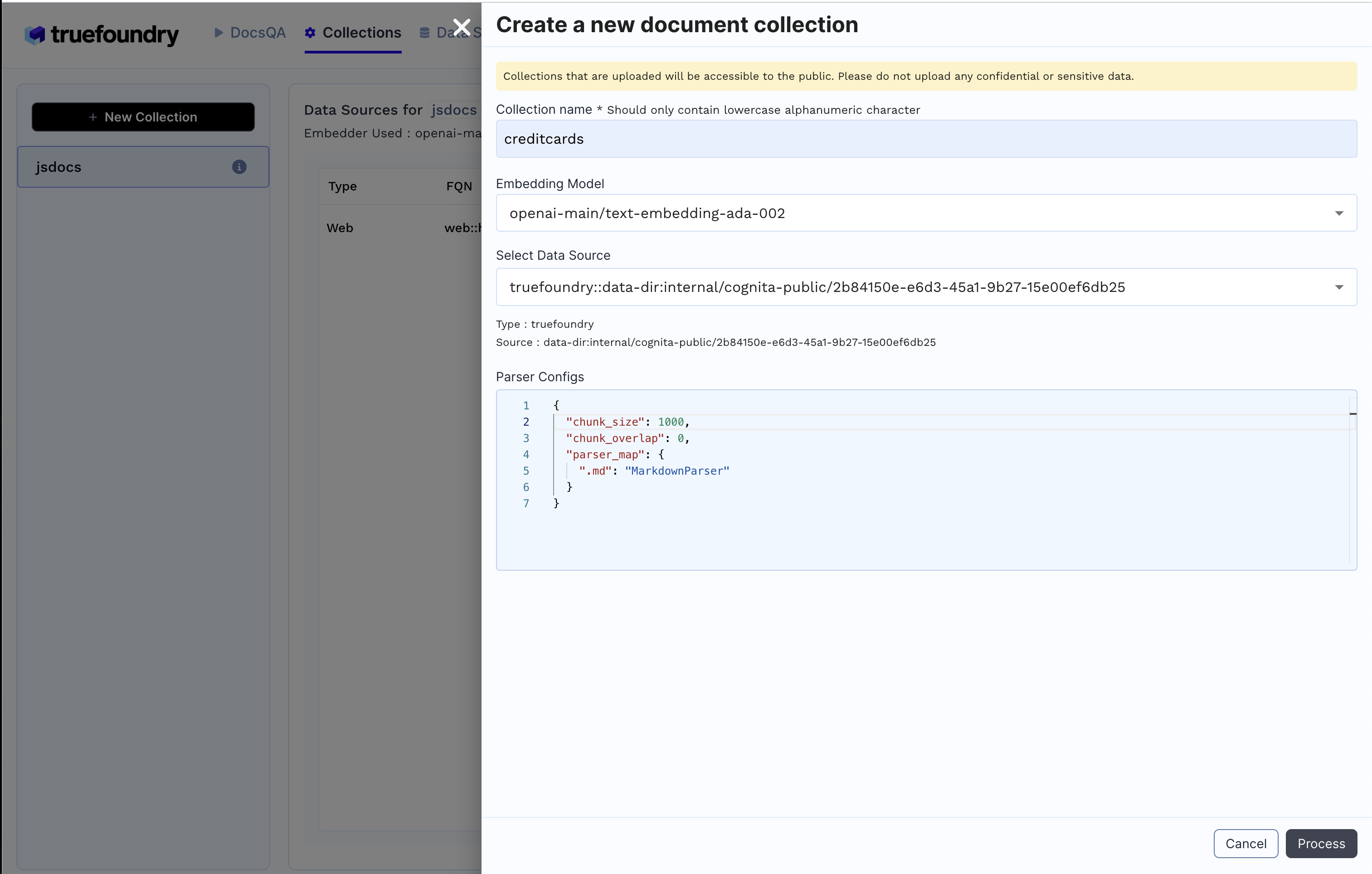
Procédé pour créer la collection et indexer les données. 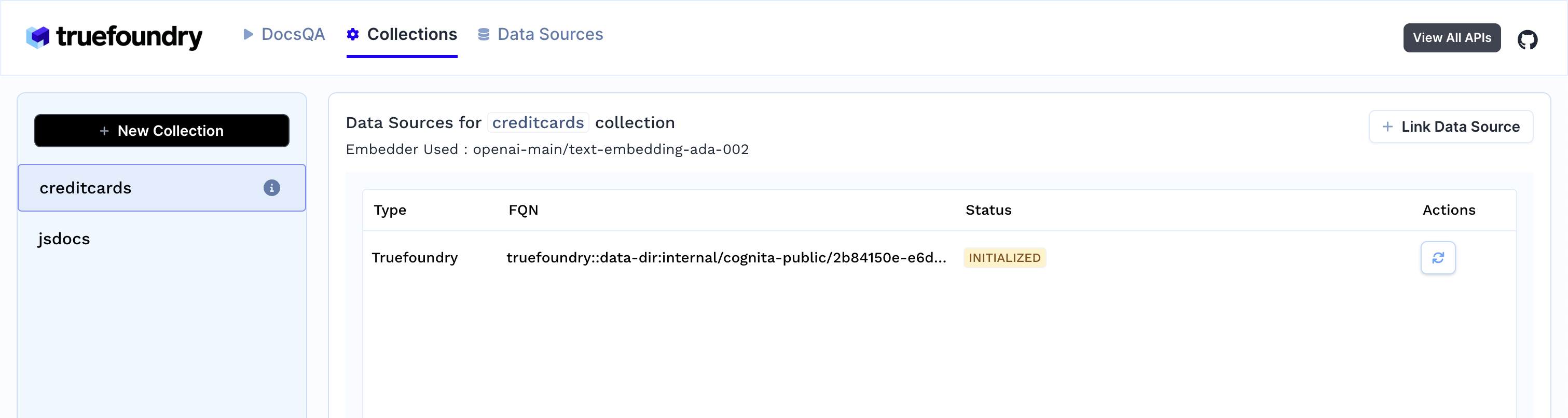
3. Dès que vous créez la collection, l'ingestion des données commence. Vous pouvez consulter son statut en sélectionnant votre collection dans l'onglet Collections. Vous pouvez également ajouter des sources de données supplémentaires ultérieurement et les indexer dans la collection.
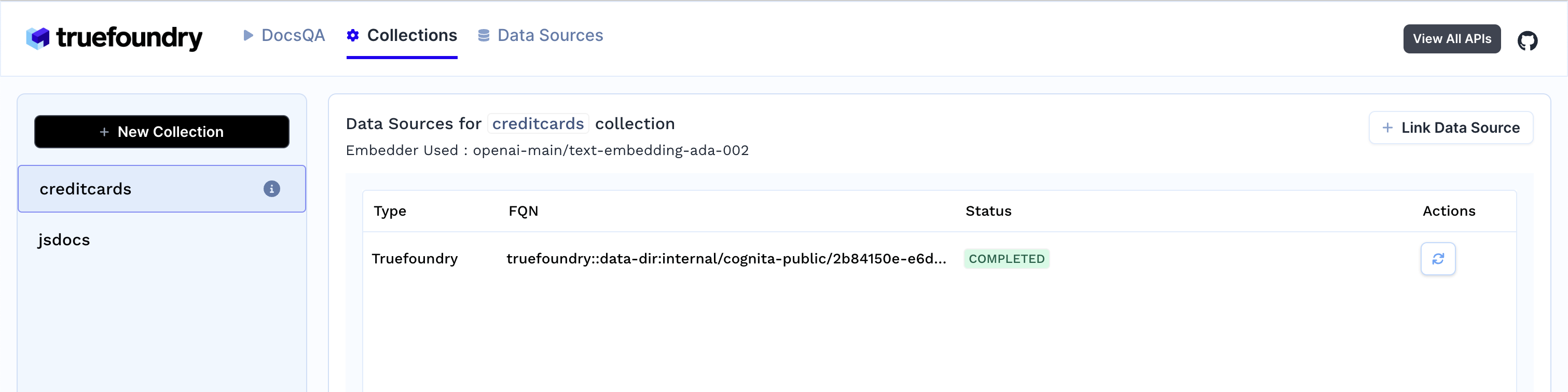
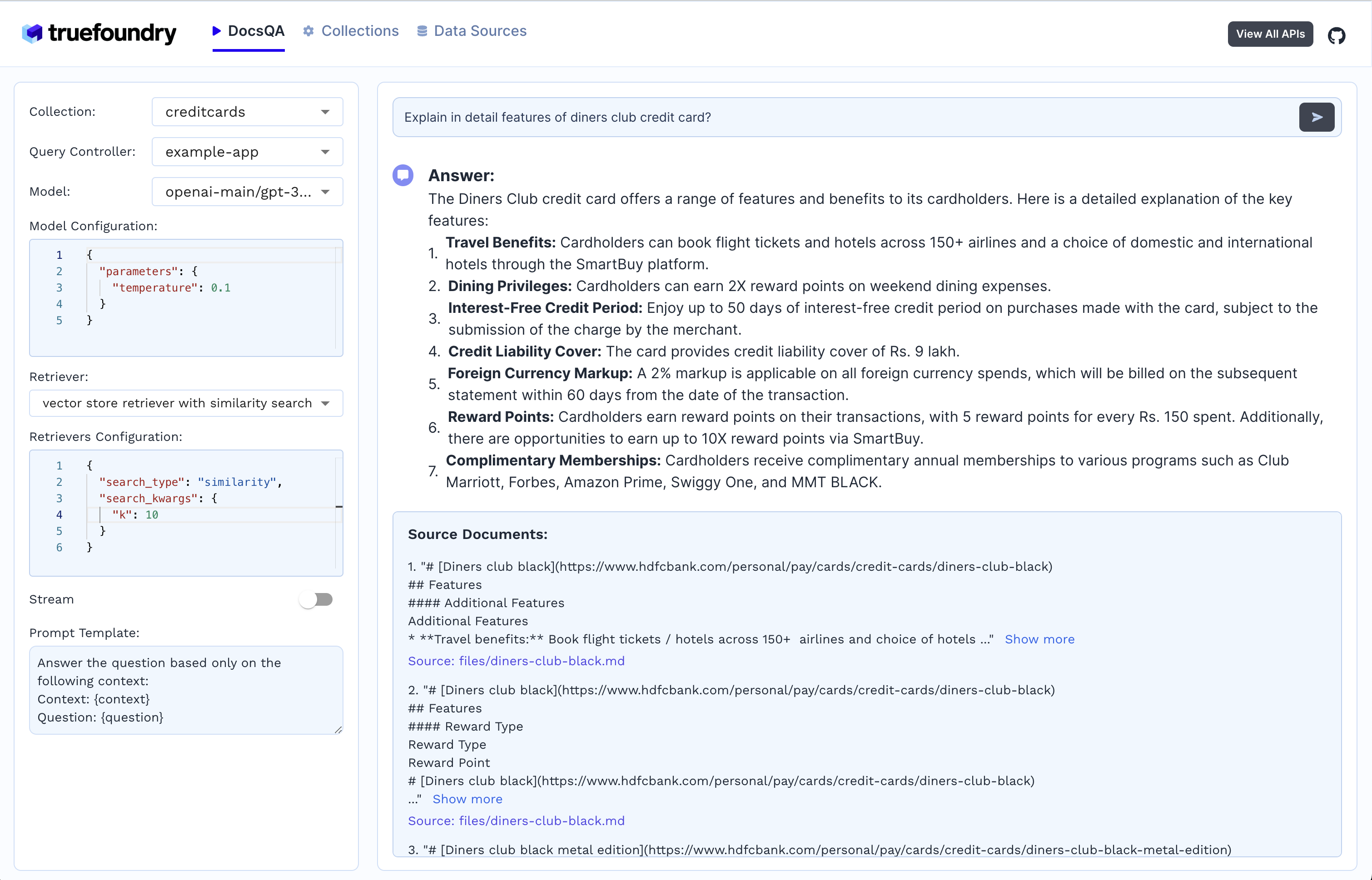
4. Génération de réponses
Réservez un pDémo personnalisée ou inscrivez-vous dès aujourd'hui pour commencer à créer vos cas d'utilisation RAG.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception












.png)

.webp)
.webp)
.webp)



.webp)
.webp)


