Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.
9,9
AI Gateway : le panneau de commande central de l'infrastructure d'IA générative d'aujourd'hui
Lors de notre récent webinaire sur AI Gateway, nous avons commencé en vérifiant où en est le public dans son parcours vers l'IA générative (GenAI).
Il est intéressant de noter que plus de 50 % ont indiqué que GenAI était déjà en production et que 15 % d'entre eux étaient en train de l'étendre à plusieurs équipes, ce qui témoigne clairement d'une forte adoption par les entreprises et d'une maturité croissante dans le déploiement des applications GenAI.
L'évolution de la passerelle LLM en tant que plan de contrôle central
Nous nous sommes concentrés sur l'évolution de la passerelle IA au cours des 6 à 9 derniers mois, passant d'une couche de routage de modèle de base à un plan de contrôle central essentiel au sein de la pile d'IA générative moderne.
Au départ, les LLM étaient principalement utilisés pour générer des réponses en un tour à des invites, considérées principalement comme des prédicteurs avancés du mot suivant.
État actuel des agents: À l'horizon 2025, les agents alimentés par LLM sont devenus autonomes et orientés vers des objectifs, capables d'invoquer de multiples outils et systèmes en coulisse. Par exemple, un agent de réinitialisation de mot de passe peut authentifier un utilisateur, appeler des API pour réinitialiser les mots de passe et envoyer des e-mails de confirmation, le tout sans intervention humaine.
Complexité organisationnelle: Les entreprises gèrent souvent des dizaines d'agents complexes de ce type répartis sur plusieurs équipes, en utilisant différents modèles provenant de différents fournisseurs, frameworks et infrastructures (y compris des hyperscalers et des clouds hybrides).
Défis sans centralisation : Cette décentralisation entraîne d'importants problèmes de gouvernance, notamment des incohérences dans les API des modèles, la déployabilité, l'auditabilité, la gestion des coûts et les stratégies de basculement.
La passerelle LLM est devenue indispensable en tant que passerelle centrale consolidant ces diverses ressources et besoins opérationnels, permettant la gouvernance, l'observabilité, le contrôle des coûts et la fiabilité à grande échelle.
Les défis auxquels sont confrontées les entreprises utilisant plusieurs fournisseurs de LLM
Formats d'API incohérents: Malgré les affirmations générales concernant la compatibilité de l'API OpenAI, la syntaxe des paramètres des fournisseurs diffère (par exemple, les jetons maximaux, les plages de température, les séquences d'arrêt), ce qui complique la commutation et l'interopérabilité.
Pannes fréquentes: Les fournisseurs de modèles sont eux-mêmes des startups, dont les interruptions fréquentes entraînent des défaillances des applications ; les applications doivent donc être indépendantes du modèle et capables de basculer facilement.
Variance de latence élevée: la latence entre les fournisseurs fluctue considérablement, ce qui rend les performances des applications imprévisibles. La latence a un impact aussi important sur l'expérience utilisateur que les temps d'arrêt complets.
Limites de taux complexes: Les limites tarifaires multiples par fournisseur nécessitent une limitation et un contrôle des coûts entre les unités commerciales et les centres de coûts. L'application centralisée est difficile mais essentielle.
Demandes en matière d'infrastructure hybride: De nombreuses entreprises doivent gérer les limites de débit et les rotations clés entre les fournisseurs de cloud et l'infrastructure GPU sur site.
Requêtes répétées coûteuses: Les applications d'IA générative reçoivent souvent de nombreuses requêtes identiques ou sémantiquement similaires (par exemple, des messages d'accueil), ce qui augmente la coût de l'IA générative inutilement, à moins que cela ne soit atténué par mise en cache sémantique.
Garde-corps et conformité: Les entreprises ont besoin d'un filtrage rapide des entrées (par exemple, aucune fuite d'informations personnelles) et d'une validation des sorties (filtrage des blasphèmes) au niveau de plusieurs équipes et modèles, ce qui nécessite une application centralisée.
Exigences en matière de gouvernance et d'audit: les demandes peuvent concerner plusieurs fournisseurs et sources de données au sein d'une seule action d'interface utilisateur. Les entreprises exigent donc une observabilité centralisée, une journalisation des audits, une explicabilité et une traçabilité pour répondre aux besoins de conformité.
Ces défis justifient le rôle de la passerelle LLM en tant que plan de contrôle central dans les écosystèmes d'IA génératifs des entreprises.
Principales fonctions et avantages d'une passerelle IA
Une passerelle d'IA joue un rôle clé pour relever ces défis en offrant une gamme de fonctionnalités techniques conçues pour rationaliser l'accès, la gouvernance et la fiabilité des modèles.
Principales fonctionnalités de la passerelle :
Couche API unifiée: fournit une interface API unique et cohérente qui supprime les détails et les mécanismes d'authentification spécifiques au fournisseur. Cela garantit :
Aucune dépendance vis-à-vis d'un fournisseur.
Changement de fournisseur fluide sans modification de code.
Utilisation simplifiée du SDK pour les développeurs.
Gestion centralisée des clés: gère diverses méthodes d'authentification (rôles AWS IAM, clés d'API OpenAI, identités GCP) via un système unifié. Les avantages incluent :
Émission de clés API au niveau de l'utilisateur pour la traçabilité.
Comptes de service ou clés virtuelles pour les applications.
Rotation et gestion faciles des touches.
Évite le partage général des clés d'API et permet des contrôles d'autorisation plus précis.
Réessais et rappels: gère les pannes des fournisseurs avec élégance grâce à des politiques de basculement automatisées. La fonction de repli configurable d'un modèle à l'autre garantit un service ininterrompu sans impact sur le code de l'application.
Limitation des tarifs et contrôle des coûts: permet d'appliquer avec précision les politiques d'utilisation des API par utilisateur, par application ou par unité commerciale. Les exemples incluent :
Limites d'appels quotidiennes pour les développeurs.
Niveaux d'utilisateurs premium avec quotas différenciés.
Protection contre les agents en fuite qui invoquent des boucles infinies, évitant ainsi des pics de facturation inattendus.
Équilibrer la charge: automatise le routage des demandes vers le modèle le plus rapide ou le plus fiable en temps réel, en effectuant un équilibrage de charge et des contrôles de santé basés sur la latence.
Déploiement de nouveaux modèles avec Canary: Facilite le déploiement progressif et contrôlé des nouvelles versions de modèles, ce qui permet de réaliser des tests et de comparer les performances avant la migration complète.
Différents types d'équilibrage de charge
Rambardes centrales : met en œuvre des filtres d'invite et de réponse à l'échelle de l'entreprise, tels que :
Suppression des PII avant l'envoi de données vers l'extérieur.
Détection et suppression de blasphèmes ou de contenus préjudiciables dans les réponses.
Possibilité de bloquer ou de modifier les invites de manière centralisée.
Intégration transparente afin que les développeurs d'applications n'aient pas à gérer ces règles individuellement.
Mise en cache sémantique: gère un cache de paires de réponses rapides sémantiquement similaires afin de réduire les appels de modèles, la latence et les coûts liés aux requêtes répétitives.
Principaux avantages
Une gouvernance centrale solide pour les entreprises.
Possibilité immédiate d'échanger des modèles et des fournisseurs sans interruption.
Accès auditable et observable à toutes les interactions des modèles avec des métriques granulaires.
Réduction des efforts d'ingénierie liés à la gestion de la complexité multimodèle.
Expérience utilisateur améliorée grâce à l'optimisation du basculement et de la latence.
Key Metrics for Evaluating Gateway
Criteria
What should you evaluate ?
Priority
TrueFoundry
Latency
Adds <10ms p95 overhead for time-to-first-token?
Must Have
✅ Supported
Data Residency
Keeps logs within your region (EU/US)?
Depends on use case
✅ Supported
Latency-Based Routing
Automatically reroutes based on real-time latency/failures?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Evaluating an AI Gateway?
A practical guide used by platform & infra teams
Vision d'avenir : intégration avec les serveurs MCP avec AI Gateway
À l'avenir, la passerelle LLM s'étendra au-delà des modèles pour gérer des outils et des agents complets via les protocoles MCP et A2A -
Qu'est-ce qu'un serveur MCP ?
Un serveur MCP expose les API des produits (par exemple, les canaux Slack, les messages, les utilisateurs) sous une forme que les agents basés sur LLM peuvent découvrir et utiliser.
Exemple : un serveur Slack MCP expose des API pour lire les chaînes, les messages et envoyer des messages, toutes compréhensibles par un agent LLM.
Interaction de l'agent avec les serveurs MCP :
Les agents interrogent le serveur MCP pour identifier les outils disponibles.
Sur la base d'une demande en langage naturel, l'agent planifie et appelle de manière autonome la séquence d'outils appropriée (par exemple, récupération de messages, synthèse, création de tâches Jira).
Intégration de la passerelle avec MCP :
La passerelle servira de point d'accès unifié pour les modèles LLM et les serveurs MCP au sein d'une organisation.
Les utilisateurs pourront émettre des commandes en langage naturel (par exemple, « Créer des tâches dans Jira en fonction de mes messages Slack ») via des outils intégrés sans codage.
L'authentification sera gérée de manière fluide, fédérée par le biais de fournisseurs d'identité existants tels qu'Okta ou Azure AD.
Cette intégration permet aux utilisateurs non techniques d'automatiser facilement les processus métier.
Point d'accès unifié pour les modèles LLM et les serveurs MCP au sein d'une organisation
Analysez et triez les alertes en combinant les données de l'API Datadog et GitHub.
Planification de flux de travail récurrents à l'aide de plusieurs outils logiciels d'entreprise.
Audit et gouvernance centralisés de toutes les activités des agents et des appels d'outils.
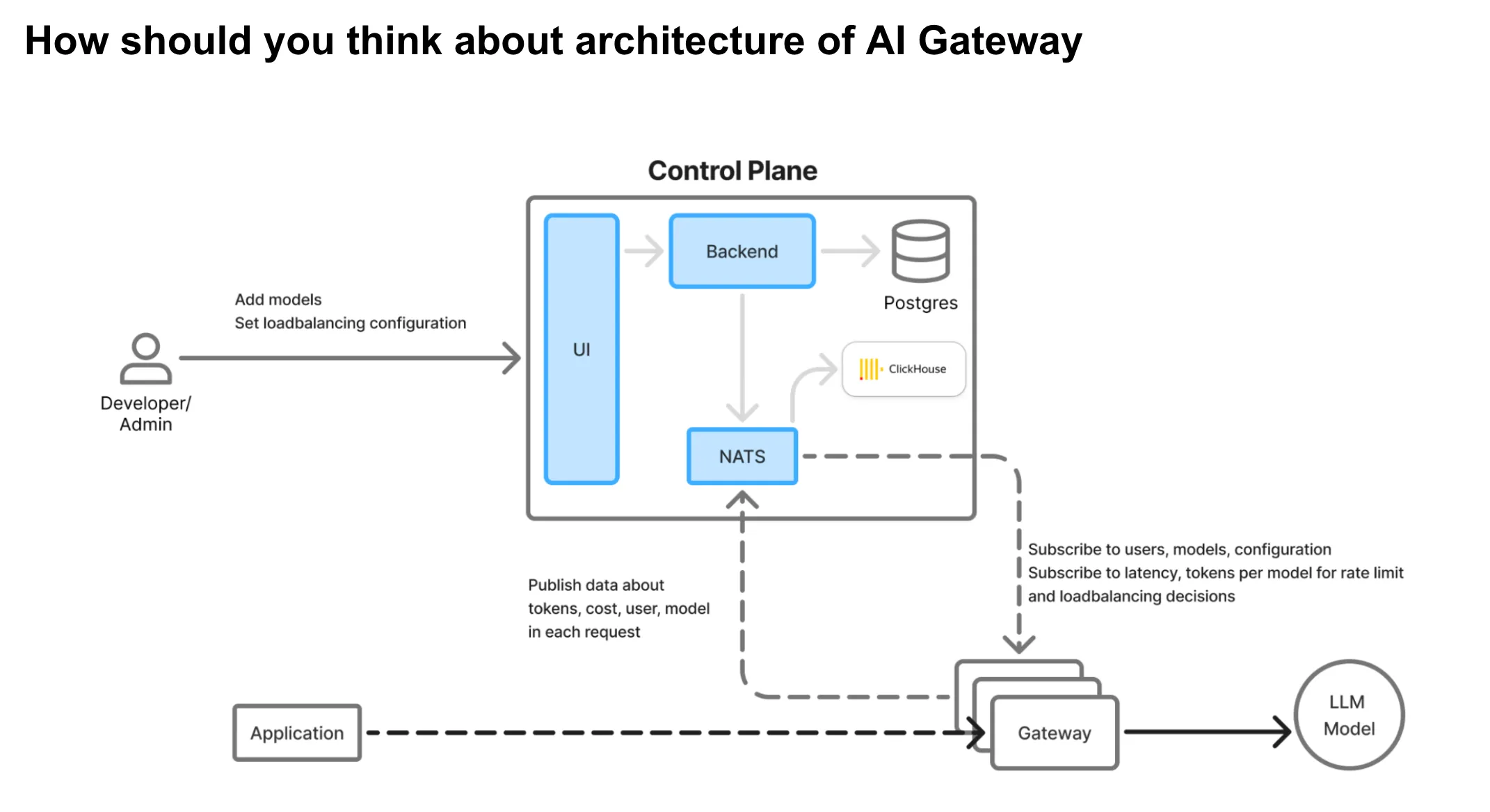
Architecture AI Gateway
L'AI Gateway fonctionne comme la couche proxy essentielle entre les applications et les fournisseurs de modèles linguistiques (LLM). Parce que la porte d'entrée se trouve sur le chemin critique du trafic de production, il doit être conçu en tenant compte des principes fondamentaux suivants :
Principales priorités architecturales :
Haute disponibilité : La passerelle ne doit pas devenir un point de défaillance unique. Même en cas de problèmes de dépendance (tels que des pannes de base de données ou de files d'attente), il devrait continuer à gérer le trafic avec élégance.
Faible latence : Comme elle est intégrée à chaque demande d'inférence, la passerelle doit ajouter frais généraux minimaux pour garantir une expérience utilisateur agréable.
Débit et évolutivité élevés : Le système doit évoluer de manière linéaire en fonction de la charge et être capable de gérer des milliers de demandes simultanées avec une utilisation efficace des ressources.
Aucune dépendance externe dans le Hot Path : Toutes les opérations liées au réseau ou au disque doivent être déchargées vers des systèmes asynchrones afin d'éviter tout goulot d'étranglement des performances.
Prise de décision en mémoire : Contrôles critiques tels que limitation de débit, équilibrage de charge, authentification, et autorisation doivent tous être exécutés en mémoire pour une vitesse et une fiabilité maximales.
Séparation du plan de contrôle et du plan proxy : Les modifications de configuration et la gestion du système doivent être dissociées du routage du trafic réel, afin de permettre des déploiements mondiaux avec une isolation régionale des pannes.
La passerelle IA de TrueFoundry incarne tous les principes de conception ci-dessus, spécialement conçue pour offrir une faible latence, une fiabilité élevée et une évolutivité sans faille.
Architecture de passerelle IA de TrueFoundry
Construit sur Hono Framework : La passerelle tire parti Hono, un framework minimaliste et ultrarapide optimisé pour les environnements périphériques. Cela garantit une charge d'exécution minimale et une gestion des demandes extrêmement rapide.
Aucun appel externe sur le chemin de la demande : Une fois qu'une demande atteint la passerelle, elle ne déclenche aucun appel externe (sauf si la mise en cache sémantique est activée). Toute la logique opérationnelle est gérée en interne, ce qui réduit les risques et renforce la fiabilité.
Application en mémoire : Toutes les décisions d'authentification, d'autorisation, de limitation de débit et d'équilibrage de charge sont prises à l'aide de configurations en mémoire, garantissant des temps de réponse inférieurs à la milliseconde.
Journalisation asynchrone : Les journaux et les métriques de demande sont envoyés vers une file de messages de manière asynchrone, ce qui garantit que l'observabilité des données ne bloque ni ne ralentit le chemin de la demande.
Comportement infaillible : Même si la file d'attente de journalisation externe est en panne, la passerelle n'échouera à aucune demande. Cela garantit la disponibilité et la résilience en cas de défaillance partielle du système.
Évolutif horizontalement : La passerelle est liée au processeur et sans état, ce qui facilite son évolutivité. Il fonctionne efficacement dans des conditions de simultanéité élevée et de faible utilisation de la mémoire.
Passerelle IA de True Foundry
Support multi-fournisseurs : ajoutez et gérez facilement des modèles depuis AWS, GCP, OpenAI, Anthropic, DeepInfra et des options personnalisées/auto-hébergées.
Terrain de jeu unifié : testez et exécutez des instructions sur n'importe quel modèle via une seule interface. Les clés d'API et les noms de modèles sont configurables sans qu'il soit nécessaire de modifier le code.
Gestion rapide avec garde-corps : affiche la rédaction en temps réel des données sensibles lors de la soumission rapide, intégrée au serveur de garde-corps centralisé.
Métriques détaillées et observabilité :
Suivi en direct de qui appelle quel modèle.
Statistiques de latence détaillées, y compris le « délai jusqu'au premier jeton » et la « latence entre jetons » (essentiel pour la surveillance des performances LLM).
Statistiques relatives à la limitation du débit, à la solution de repli et aux déclencheurs de mesures de protection.
Journaux d'audit de toutes les paires demande-réponse, exportables à des fins de conformité.
Paramètres d'administration configurables : définissez des limites de débit par développeur ou par équipe, définissez des politiques de secours, un routage basé sur la latence et gérez les garde-corps de manière centralisée.
Feuille de route d'intégration des serveurs MCP : aperçu des fonctionnalités à venir prenant en charge tous les serveurs MCP internes pour des outils tels que Gmail, Slack, Confluence, Jira, GitHub et des API personnalisées.
Questions-réponses en direct : aborder la question de l'évolutivité, de l'intégration et des questions techniques
La session se termine par une séance de questions-réponses portant sur les sujets suivants :
Évolutivité de la passerelle: Conçu pour être évolutif horizontalement ; les tests de performances montrent qu'un processeur peut gérer 350 requêtes par seconde (RPS), ce qui nécessite des déploiements évolutifs pour des débits plus élevés.
Latence et stabilité : Gateway fournit des mécanismes de rappel et de nouvelle tentative pour une fiabilité accrue et change automatiquement de modèle lorsque les fournisseurs sont confrontés à des pannes.
Limites de taille d'entrée du modèle : les modèles ne peuvent pas gérer des entrées extrêmement volumineuses (par exemple, 500 Mo) ; il est recommandé d'utiliser des systèmes RAG (Retrieval-Augmented Generation).
Intégrations de frameworks : compatible avec les principaux frameworks de création d'agents tels que LangChain, LangGraph en utilisant des API standard compatibles avec OpenAI sans avoir besoin de SDK spéciaux.
Prise en charge des langages de programmation : Gateway est conçu à l'aide de frameworks légers et performants (Hono, similaires à ceux utilisés dans les applications Cloudflare) et est indépendant du langage pour les clients API (Python, JavaScript, Go, etc.).
Adaptation rapide aux nouveaux modèles d'API : mises à jour continues pour prendre en charge les paramètres spécifiques aux fournisseurs et les entrées multimodales avec une documentation rigoureuse.
Outils de gouvernance et d'audit : possibilité d'exporter des données détaillées sur la latence, l'utilisation et les coûts pour des audits adaptés aux besoins de gouvernance.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.
Conçu pour la vitesse : latence d'environ 10 ms, même en cas de charge




































.png)

.webp)
.webp)
.webp)



.webp)
.webp)


