

July 20, 2023
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: April 22, 2026

Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
L'essor des grands modèles linguistiques (LLM) a transformé les capacités de l'IA, mais la mise au point de ces modèles massifs reste un défi coûteux et gourmand en ressources. Découvrez LoRa (Low-Rank Adaptation), une technique révolutionnaire qui permet d'affiner efficacement les modèles pré-entraînés en réduisant considérablement le nombre de paramètres pouvant être entraînés. Au lieu de mettre à jour l'ensemble du modèle, LoRa injecte des modules légers et faciles à apprendre, ce qui rend le réglage plus rapide, moins coûteux et plus accessible. Que vous créiez des LLM spécifiques à un domaine ou que vous optimisiez des déploiements en périphérie, LoRa est devenue une méthode incontournable dans les flux de travail ML modernes. Dans ce guide, nous allons expliquer ce qu'est la LoRa, comment elle fonctionne et pourquoi elle change la donne.
LoRa, abréviation de Low-Rank Adaptation, est une technique de réglage fin efficace en termes de paramètres conçue pour adapter de grands modèles pré-entraînés sans mettre à jour leurs matrices complètes. Au lieu de modifier les paramètres d'origine du modèle, qui peuvent se chiffrer en milliards, LoRa introduit de petites matrices de décomposition en rangs pouvant être entraînées dans les couches existantes. Ces modules apprennent la tâche de réglage alors que le modèle de base reste figé.
L'idée de base de LoRa trouve ses racines dans l'algèbre linéaire. Au lieu d'apprendre directement une matrice de mise à jour de poids importante ΔW, LoRa l'approxime comme le produit de deux matrices plus petites :
ΔW≈ A⋅B
où Ard×R et Brr×k, avec rmin (d, k). Cette factorisation de bas rang réduit considérablement le nombre de paramètres à entraîner, souvent de plusieurs ordres de grandeur.
En pratique, les modules LoRa sont insérés dans des couches spécifiques d'un modèle de transformateur (généralement des couches d'attention et d'anticipation). Pendant l'entraînement, seuls les paramètres LoRa sont mis à jour, tandis que les poids du modèle d'origine restent figés. Cela rend LoRa non seulement efficace en termes de calcul et d'utilisation de la mémoire, mais également modulaire : vous pouvez entraîner différents adaptateurs LoRa pour différentes tâches et les échanger selon les besoins.
Initialement introduit pour les tâches de PNL, le LoRa a depuis été adopté dans les modèles de vision, la reconnaissance vocale et les architectures multimodales, démontrant ainsi sa polyvalence dans tous les domaines.
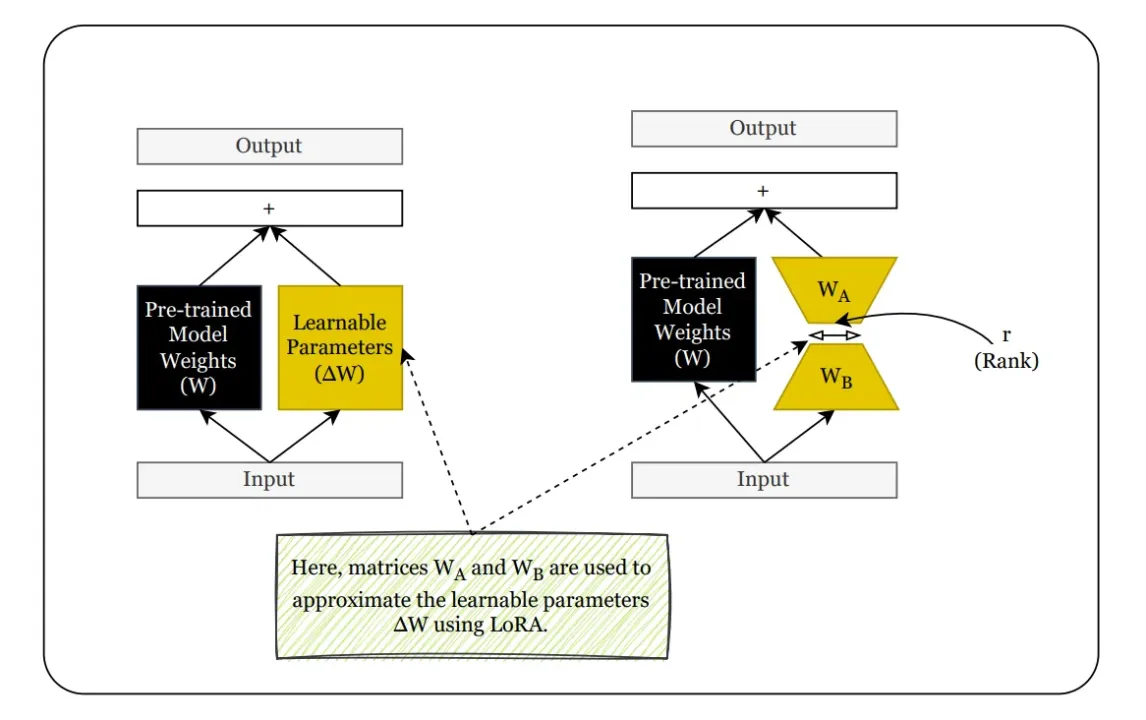
Le réglage précis de LoRa est une méthode qui permet d'adapter de grands modèles pré-entraînés, tels que BERT, GPT ou LLAMA, en n'entraînant qu'un petit nombre de paramètres supplémentaires, plutôt que de mettre à jour l'ensemble du modèle. Il s'appuie sur le principe fondamental de LoRa (Low-Rank Adaptation) pour rendre les réglages plus efficaces sur le plan informatique, plus respectueux de la mémoire et prêts au déploiement, en particulier dans les environnements où la reconversion complète des modèles n'est pas pratique. Parmi les modernes outils de réglage fin, LoRa se distingue par sa capacité à adapter efficacement de grands modèles sans mettre à jour tous les paramètres.
Lors du réglage fin traditionnel, toutes les pondérations des modèles sont mises à jour, ce qui nécessite une mémoire GPU, un temps de calcul et un stockage importants. Cela devient difficile lorsque vous travaillez avec des modèles de plusieurs milliards de paramètres. LoRa résout ce problème en gelant les poids des modèles pré-entraînés et en insérant des adaptateurs légers pouvant être entraînés dans des couches spécifiques, généralement les couches de requête et de projection de valeurs dans les architectures basées sur des transformateurs.
Pendant le réglage de LoRa :
En raison de cette structure, le réglage fin de LoRa est particulièrement intéressant pour :
Une fois entraînés, ces adaptateurs LoRa peuvent être enregistrés séparément et fusionnés à nouveau dans le modèle de base à des fins d'inférence, ou rester modulaires et échangés dynamiquement en fonction du cas d'utilisation.
Le réglage précis de LoRa ne compromet pas non plus les performances. Dans de nombreux benchmarks, les modèles affinés à l'aide de LoRa obtiennent des résultats comparables, voire supérieurs, à ceux du réglage fin complet, tout en économisant nettement plus de ressources.
Le réglage précis de LoRa permet de personnaliser et d'adapter de grands modèles avec un minimum de calcul, une flexibilité maximale et sans compromis sur la précision.
L'excellence technique de LoRa (Low-Rank Adaptation) réside dans son utilisation de l'algèbre linéaire pour réduire le nombre de paramètres pouvant être entraînés lors du réglage fin, sans sacrifier la capacité du modèle ou les performances en aval. Pour comprendre comment cela fonctionne, analysons les mécanismes sous-jacents.
Le problème des mises à jour des classements complets
Lors du réglage fin standard, un modèle pré-entraîné apprend une nouvelle tâche en ajustant ses matrices de poids WWW. Ces matrices, en particulier dans les modèles de grands transformateurs, sont massives (par exemple, des centaines de millions de paramètres par couche). Leur mise à jour directe entraîne une utilisation importante de la mémoire, de longs temps d'entraînement et des difficultés d'adaptation ou de déploiement multitâches.
The LoRa Insight : décomposition de bas rang
LoRa propose que le changement de poids requis pour adapter un modèle à une nouvelle tâche n'a pas besoin d'être de grande dimension. Ces mises à jour peuvent plutôt être approximées à l'aide de matrices de rang inférieur.
Plutôt que d'apprendre une matrice de mise à jour complète ΔW, LoRa introduit deux matrices plus petites :
ΔW=A⋅B
où, rmin (d, k)
Ces matrices sont initialisées avec de petites valeurs aléatoires et sont les seuls paramètres mis à jour lors de l'entraînement. La matrice WWW d'origine reste figée.
Intégration dans les couches de transformation
La LoRa est généralement appliquée aux projections d'attention dans les architectures de transformateurs, en particulier aux matrices de projection de requête (Q) et de valeur (V). Lors du réglage, la sortie adaptée devient :
W (x) +α⋅A⋅B (x)
où α est un facteur d'échelle (souvent défini de manière empirique) et A⋅B (x) représente l'adaptation de bas rang apprise appliquée à l'entrée.
Efficacité et rétropropagation
Comme seules les matrices de rang inférieur peuvent être entraînées, le nombre de paramètres pouvant être entraînés est réduit de plusieurs ordres de grandeur. Cela permet de réduire :
La rétropropagation se produit uniquement via les modules LoRa, ce qui permet de réduire les dégradés et de concentrer les mises à jour.
En appliquant des principes mathématiques à l'architecture des modèles, LoRa propose une solution hautement efficace, modulaire et élégante pour l'adaptation de grands modèles, ce qui la rend idéale pour les flux de travail modernes de réglage fin du LLM.
La LoRa est devenue l'une des techniques les plus efficaces dans le domaine du réglage fin efficace des paramètres (PEFT), et pour cause. Il offre de nombreux avantages pratiques qui le rendent particulièrement intéressant dans les scénarios impliquant de grands modèles de langage (LLM), un apprentissage multitâche ou un déploiement en périphérie. Explorons les principaux avantages de l'utilisation de LoRa pour le réglage fin.
Réduction significative des paramètres pouvant être entraînés
L'un des principaux avantages de LoRa est sa capacité à réduire le nombre de paramètres pouvant être entraînés jusqu'à 10 000 fois, en fonction de la taille du modèle et de la configuration des rangs. En n'apprenant qu'un petit ensemble de paramètres d'adaptateur, LoRa minimise la consommation de mémoire et les frais de calcul, ce qui permet d'affiner les GPU grand public, voire les processeurs dans certains cas.
Préservation des connaissances préformées
Étant donné que LoRa bloque le modèle de base, cela évite un « oubli catastrophique », où un ajustement complet peut remplacer les connaissances générales utiles. Cela rend LoRa particulièrement utile pour adapter de grands modèles à des domaines de niche (par exemple, juridique, médical, financier) tout en préservant leur compréhension de la langue d'origine.
Modularité et réutilisabilité
Avec LoRa, différents adaptateurs peuvent être entraînés pour différentes tâches et stockés séparément. Cela permet de :
Cette modularité est idéale pour les plateformes multi-locataires ou les cas d'utilisation où le changement de contexte est fréquent.
Évolutivité et déploiement améliorés
Les adaptateurs LoRa sont de petite taille et ne nécessitent aucune modification architecturale du modèle de base. Cela facilite la connexion aux pipelines de déploiement de modèles existants. Ils sont également adaptés aux environnements informatiques de pointe où la taille du modèle et la mémoire sont limitées.
Performance concurrentielle
Malgré sa légèreté, LoRa atteint ou dépasse souvent les performances de réglage complètes sur les tâches en aval, en particulier lorsqu'il est associé à des modèles de base modernes et à des données de qualité.
LoRa offre un compromis convaincant : des performances quasi complètes pour un coût et une complexité moindres. Il démocratise le réglage fin, rendant la personnalisation avancée du LLM accessible à un plus large éventail d'équipes et de développeurs.
Dans cette section, nous verrons comment affiner de grands modèles de langage à l'aide de LoRa avec la bibliothèque PEFT de Hugging Face. Cette approche vous permet d'injecter des adaptateurs entraînables dans des modèles pré-entraînés avec un minimum de modifications de code, ce qui rend LoRa à la fois accessible et prêt pour la production.
1. Installez les bibliothèques requises
Installez les bibliothèques principales dont vous aurez besoin pour le chargement des modèles, la tokenisation, la formation et l'injection LoRa.
ensembles de données Pip Install Transformers Left Accelerate
2. Chargez le modèle de base et le tokenizer
Ici, nous chargeons un modèle de langage causal (par exemple, LLama 2) et son tokenizer à l'aide de la bibliothèque Transformers de Hugging Face. Il s'agit de notre modèle de base congelé.
à partir de transformateurs, importation de modèles automobiles pour Causallm, AutoTokenizer
model = AutomodelForCausAllm.from_pretrained (« Meta-Llama/Llama-2-7b-HF »)
tokenizer = AutoTokenizer.from_pretrained (« Meta-LLama/LLAMA-2-7B-HF »)
3. Injectez des adaptateurs LoRa dans le modèle
Nous définissons une configuration LoRa en spécifiant :
Cela enveloppe le modèle de base et ajoute des couches LoRa pouvant être entraînées.
depuis peft import get_peft_model, LoraConfig, TaskType
lora_config = LoraConfig (
task_type=TaskType.causal_lm,
r=8,
lora_alpha=32,
lora_drop out=0,05,
modules_cibles = ["q_proj », « v_proj »]
)
modèle = get_peft_model (modèle, lora_config)
4. Tokenisez votre ensemble de données pour la formation
Nous chargeons un exemple de jeu de données (par exemple, le format Alpaca) et le prétraitons en joignant les instructions et les entrées dans un format de texte plat, puis en le tokenisant avec remplissage et troncature.
à partir de jeux de données import load_dataset
ensemble de données = load_dataset (« yashishdua/alpaga nettoyé »)
def tokenize (exemple) :
tokenizer de retour (exemple ["instruction"] + exemple ["input"], truncation=True, padding="max_length », max_length=512)
tokenized_dataset = dataset.map (tokenize)
5. Ajustez le modèle avec le Trainer de Hugging Face
Cela configure la boucle d'entraînement à l'aide de Trainer, en spécifiant la taille du lot, le nombre d'époques, la journalisation et la stratégie de sauvegarde.
depuis Transformers import Trainer, TrainingArguments
entraîneur = Entraîneur (
modèle=modèle,
args=Arguments d'entraînement (
dir_sortie = ». /lora-pert-point de contrôle «,
taille du lot par train_appareil = 2,
num_train_epochs=3,
étapes_journalisées=10,
save_strategy="epoch »
),
train_dataset=tokenized_dataset [« train »],
tokenizer=tokenizer
)
entraîneur.train ()
6. Enregistrez le poids de l'adaptateur LoRa
Après la formation, nous n'enregistrons que les couches adaptatrices LoRa (et non le modèle de base complet) pour que les choses restent légères et modulaires.
modèle.save_pretrained (». /lora-pert-point de contrôle «)
7. Chargez les poids de l'adaptateur à des fins d'inférence
Pour exécuter l'inférence, rechargez le modèle de base et connectez l'adaptateur LoRa enregistré à l'aide de PEFTModel. Cela permet de recréer efficacement la version affinée.
à partir de PEFT import PEFTModel
base_model = AutomodelForCausAllM.from_pretrained (« Meta-LLama/LLAMA-2-7B-HF »)
model = PeftModel.from_pretrained (base_model), ». /lora-pert-point de contrôle «)
modèle.eval ()
Vous pouvez utiliser ce code comme point de départ pour affiner tout modèle de transformateur pris en charge à l'aide de LoRa. Il vous suffit de brancher votre jeu de données préféré, de modifier la configuration LoRa ou les hyperparamètres d'entraînement, puis d'exécuter le script tel quel. Il est conçu pour être modulaire. Vous pouvez donc l'étendre à des fins d'évaluation, de journalisation ou de déploiement selon vos besoins. Parfait pour des expérimentations rapides ou des ajustements de production légers.
Alors que LoRa est largement adoptée, ses applications réelles se développent rapidement dans tous les secteurs et dans tous les cas d'utilisation. Qu'il s'agisse de réduire les coûts d'infrastructure ou de permettre la personnalisation à grande échelle, LoRa a prouvé sa valeur dans les environnements de recherche et de production. Vous trouverez ci-dessous quelques scénarios notables dans lesquels LoRa a eu un impact mesurable.
Ajustement spécifique à un domaine dans l'IA médicale et juridique
Les organisations qui travaillent avec des données sensibles ou spécialisées, telles que les prestataires de soins de santé ou les startups du secteur des technologies juridiques, doivent souvent adapter de grands modèles linguistiques à leur domaine. L'utilisation d'un réglage complet nécessiterait des calculs massifs et soulèverait des problèmes de confidentialité. Avec LoRa, les équipes peuvent affiner des modèles pré-entraînés sur des corpus spécifiques à un domaine (par exemple, la terminologie médicale ou les contrats juridiques) tout en gelant les poids de base. Il en résulte des modèles légers et optimisés pour les tâches qui restent sécurisés et faciles à déployer en interne.
Réglage multitâche à grande échelle
Les grandes plateformes d'IA doivent souvent prendre en charge de multiples tâches en aval, telles que la synthèse, la classification et la génération de dialogues. Au lieu de conserver des copies séparées du modèle complet pour chaque tâche, LoRa leur permet de former et de stocker des adaptateurs légers pour chaque cas d'utilisation. Ces adaptateurs peuvent être chargés dynamiquement en fonction des besoins des utilisateurs, ce qui permet de proposer facilement des modèles personnalisés ou multifonctionnels à partir d'une seule base partagée.
IA intégrée à l'appareil et en périphérie
Les environnements aux ressources limitées, tels que les appareils mobiles, les passerelles IoT ou les plateformes d'inférence de périphérie, bénéficient de manière significative de la LoRa. En n'entraînant que quelques millions de paramètres au lieu de milliards, LoRa permet une adaptation rapide sans épuiser les budgets de mémoire ou de calcul. Certaines équipes ont utilisé LoRa pour affiner des modèles, comme Whisper ou DisTiLbert pour les assistants vocaux ou les scanners de documents fonctionnant entièrement sur l'appareil.
Écosystème communautaire et open source
Les projets open source tels qu'Alpaca, Dolly et Vicuna se sont tous appuyés sur LoRa pour affiner les modèles de base ouverts (par exemple, LLama) pour les tâches de suivi des instructions ou de dialogue, démontrant ainsi que même des développeurs individuels ou de petites équipes peuvent créer des modèles puissants sans avoir accès à du matériel coûteux.
Dans tous ces cas d'utilisation, LoRa tient toujours ses promesses : des ajustements rentables sans sacrifier les performances, tout en offrant la flexibilité nécessaire pour s'adapter à tous les domaines, tâches et environnements.

La véritable puissance de LoRa va bien au-delà du simple réglage fin. Lorsqu'il est correctement dimensionné, il permet une gamme de configurations avancées idéales pour le déploiement en production, les systèmes multidomaines et les flux de travail de recherche. Vous trouverez ci-dessous certaines des méthodes les plus efficaces et les plus importantes sur le plan technique pour étendre LoRa dans des systèmes du monde réel.
Fusion des adaptateurs LoRa dans le modèle de base
Par défaut, les adaptateurs LoRa restent séparés du modèle de base, agissant comme des couches résiduelles appliquées lors de l'inférence. Cependant, dans les environnements sensibles à la latence ou pour un déploiement sur des environnements d'exécution optimisés pour l'inférence (par exemple, vLLM, ONNX, TensorRT), il est avantageux de fusionner les poids LoRa de bas rang avec les poids du modèle d'origine après l'entraînement. Cela élimine le besoin d'une logique d'adaptateur et réduit la complexité de l'inférence, ce qui permet de :
Le processus de fusion est généralement effectué via une opération linéaire :
W fusionné = W+α⋅A⋅B
Application du module sélectif
Il n'est pas nécessaire d'appliquer LoRa sur toutes les couches du transformateur. Dans de nombreux cas, le réglage précis de parties spécifiques de l'architecture, telles que les matrices de projection de requête (Q) et de valeur (V) dans les couches d'attention, permet d'obtenir des performances comparables avec moins de paramètres.
Les utilisateurs avancés peuvent cibler :
Cette approche vous permet de mieux contrôler le comportement du modèle, de budgétiser les paramètres et d'améliorer l'interprétabilité au niveau de la couche.
LoRa avec quantification : QLoRa
QLoRa est une extension puissante qui combine LoRa avec une quantification 4 bits ou 8 bits, permettant d'affiner des modèles comportant des milliards de paramètres sur un seul GPU. Il fonctionne de la manière suivante :
QLoRa permet de peaufiner des modèles tels que LLama-65b sur du matériel grand public sans sacrifier la précision.
Inférence et routage multi-adaptateurs
Dans les scénarios de production nécessitant plusieurs tâches ou plusieurs locataires, LoRa permet de créer plusieurs adaptateurs, chacun étant adapté à un cas d'utilisation ou à un client différent. Il peut s'agir de :
Cela permet à un modèle de base unique de desservir de nombreux domaines tout en maintenant une faible utilisation de la mémoire et une latence gérable. La logique de sélection des adaptateurs peut être intégrée à des couches d'orchestration externes ou à des analyseurs rapides.
Composants modulaires de l'agent et du RAG
Dans les systèmes plus complexes tels que la génération augmentée par extraction (RAG) ou les architectures multi-agents, différents sous-modules peuvent effectuer la récupération de documents, la sélection d'outils, la synthèse ou le dialogue. LoRa permet un réglage précis au niveau des composants, chaque sous-modèle pouvant être entraîné indépendamment avec son propre adaptateur.
Cela est particulièrement efficace dans les scénarios où :
LoRa garantit l'isolation, la maintenabilité et l'adaptabilité au sein de tels systèmes modulaires.
Bien que la LoRa apporte des avantages significatifs en termes d'efficacité et de modularité, elle n'est pas sans défis. Il est essentiel de comprendre ces limites lors de la conception de flux de travail robustes et précis ou de l'adaptation de LoRa à de multiples cas d'utilisation.
Capacité limitée pour une adaptation extrême
Étant donné que LoRa ne met à jour qu'un petit sous-ensemble de paramètres (via des matrices de bas rang), il peut être difficile lorsque la tâche nécessite des modifications importantes du comportement du modèle. Pour les tâches qui impliquent un raisonnement dans des domaines très différents de ceux de la distribution pré-entraînée, un ajustement complet ou des couches supplémentaires peuvent encore être nécessaires.
Compromis en matière de configuration de l'adaptateur
Le choix de la bonne configuration LoRa, telle que le rang (r), le facteur d'échelle alpha et les modules cibles, nécessite des expériences. Un rang trop bas risque de ne pas être adapté, tandis qu'un rang trop élevé peut entraîner un surajustement ou une réduction des économies de paramètres. De plus, cibler les mauvais modules (par exemple, utiliser LoRa sur toutes les couches sans discernement) peut entraîner une complexité et des coûts inutiles sans gains de performances.
Compatibilité avec la quantification et le service
Bien que des outils tels que QLoRa prennent en charge le réglage précis quantifié, toutes les plateformes d'inférence ne gèrent pas correctement les adaptateurs LoRa ou les pondérations fusionnées. Certains frameworks de service (en particulier les environnements d'exécution Edge ou C++ de bas niveau) peuvent nécessiter la fusion d'adaptateurs ou la réexportation dans un format compatible, ce qui ajoute des étapes au pipeline de déploiement.
Débogage et évaluation
Le débogage des modèles optimisés pour LoRa peut s'avérer plus complexe que prévu. Le modèle de base étant figé, il peut être difficile d'interpréter si les défaillances sont dues à un sous-entraînement des modules LoRa ou à des limites inhérentes au backbone gelé. Une évaluation correcte de plusieurs tâches et ensembles de données est importante pour comprendre quand LoRa est l'outil adapté à la tâche.
Malgré ces défis, la LoRa reste une approche extrêmement efficace et flexible lorsqu'elle est utilisée de manière réfléchie, en particulier dans les environnements où l'efficacité, l'évolutivité et la modularité sont des priorités clés.
LoRa a redéfini la façon dont nous affinons les grands modèles de langage, ce qui permet d'adapter efficacement des modèles puissants, sans avoir besoin d'une informatique approfondie ou d'une reconversion complète. Son approche de bas niveau apporte modularité, évolutivité et rentabilité aux flux de travail de machine learning modernes. Dans ce guide, nous avons exploré les fondements de LoRa, des cas d'utilisation concrets, des techniques avancées et une mise en œuvre pratique à l'aide du PEFT de Hugging Face. Alors que les LLM continuent de croître en taille et en adoption, LoRa offre une voie pratique vers la personnalisation et les performances. Pour les équipes qui souhaitent évoluer de manière intelligente, LoRa est bien plus qu'efficace, c'est un avantage stratégique dans la création de systèmes d'IA adaptables.
Le réglage fin LoRa est une méthode efficace pour adapter de grands modèles pré-entraînés sans mettre à jour tous les paramètres. Il gèle les poids du modèle de base et n'entraîne que de petits modules adaptateurs légers. Cette technique réduit considérablement les ressources de calcul et la mémoire, rendant l'adaptation des modèles plus rapide, moins coûteuse et plus accessible pour des tâches et des déploiements spécifiques.
Le réglage fin LoRa réduit considérablement les données requises par rapport au réglage fin complet du modèle. Bien qu'il n'existe pas de montant fixe, LoRa s'appuie sur une base pré-entraînée, ce qui signifie que vous pouvez obtenir de bons résultats avec des ensembles de données plus petits et spécifiques à des tâches. Cela rend l'adaptation de grands modèles plus efficace et plus accessible pour des cas d'utilisation spécialisés, optimisant ainsi l'utilisation des ressources.
Le principal avantage du réglage LoRa est son efficacité remarquable. Il réduit considérablement les paramètres pouvant être entraînés, ce qui rend le processus plus rapide, plus rentable et moins gourmand en mémoire. Cela permet d'adapter de grands modèles de langage à diverses tâches avec un minimum de ressources informatiques, garantissant ainsi des solutions d'IA accessibles et performantes pour les entreprises américaines.
Le réglage précis de LoRa fige les poids importants du modèle d'origine et insère de petites matrices adaptatrices faciles à entraîner dans des couches spécifiques. Seuls ces paramètres d'adaptateur léger sont mis à jour pendant l'entraînement, et non l'ensemble du modèle. Ce processus rend le réglage de LoRa nettement plus efficace, réduit les ressources de calcul et accélère l'adaptation des modèles pour les équipes américaines.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception











.png)

.webp)
.webp)
.webp)



.webp)
.webp)


