




July 20, 2023
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: April 22, 2026

Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
Déployer des modèles de langage large (LLM) open source à grande échelle tout en garantissant la fiabilité, une faible latence et une rentabilité peut être une entreprise difficile. En m'appuyant sur notre vaste expérience dans la construction d'une infrastructure LLM et dans son déploiement réussi pour nos clients, j'ai compilé une liste des principaux défis fréquemment rencontrés par les individus au cours de ce processus.
Il existe plusieurs options permettant aux serveurs modèles d'héberger LLM et divers paramètres de configuration à régler pour obtenir les meilleures performances en fonction de votre cas d'utilisation. TGI, VLLM, Ouvrez LLM sont quelques-uns des frameworks les plus courants pour héberger ces LLM. Vous trouverez une analyse détaillée dans ce bloguer. Pour choisir le bon framework pour votre hébergement, il est important de comparer les performances de ces frameworks pour votre cas d'utilisation et de choisir celui qui convient le mieux à votre cas d'utilisation. De plus, ces frameworks ont leurs seuls paramètres ajustables qui peuvent vous aider à extraire les meilleurs résultats d'analyse comparative.
Les GPU sont chers et difficiles à trouver. Il existe différents fournisseurs de cloud GPU, allant des principaux clouds tels qu'AWS, GCP et Azure aux fournisseurs de cloud à petite échelle tels que Runpod, Fluidstack, Paperspace et Coreweave. Les prix et les offres de chacun de ces fournisseurs varient considérablement. La fiabilité reste également une préoccupation pour certains des nouveaux fournisseurs de cloud GPU.
En pratique, c'est plus difficile qu'il n'y paraît. D'après notre expérience en matière d'exécution de LLM en production, vous devriez être prêt à faire face à d'étranges bogues ponctuels sur les serveurs modèles, qui peuvent interrompre votre processus et entraîner l'expiration de toutes les demandes. Il est très important de disposer de gestionnaires de processus et de sondes de préparation/de vivacité appropriés afin que les serveurs modèles puissent se rétablir après des pannes ou que le trafic puisse passer facilement d'une instance défectueuse à une instance saine.
Lors de l'analyse comparative, il est très important de trouver le compromis entre la latence et le débit. À mesure que nous augmentons le nombre de requêtes simultanées adressées au modèle, la latence augmente légèrement jusqu'à un certain point, après quoi la latence se détériore considérablement. Trouver le juste équilibre entre latence, débit et coût peut prendre beaucoup de temps et être source d'erreurs. Nous avons quelques blogs décrivant de tels points de référence pour Appel 7B et Clama13B.
Les modèles LLM sont de taille énorme, allant de 10 à 100 Go. Le téléchargement du modèle une fois que le serveur de modèles est prêt, puis son chargement du disque vers la mémoire peuvent prendre beaucoup de temps. Il est essentiel que vous mettiez le modèle en cache sur le disque afin que nous ne retéléchargions pas le modèle au cas où le processus redémarrerait. De plus, pour réduire les coûts liés au réseau, il est préférable de télécharger le modèle une seule fois et de partager le disque entre plusieurs répliques au lieu de télécharger le modèle à plusieurs reprises sur Internet.
La mise à l'échelle automatique est délicate dans le cas d'un hébergement LLM en raison du temps de démarrage élevé d'une autre réplique. Si la charge est très élevée, nous devons généralement provisionner l'infrastructure en fonction des pics de répliques. Toutefois, si le pic est attendu à certaines heures de la journée, la mise à l'échelle automatique basée sur le temps fonctionne bien.
Nous avons commencé par l'approche ci-dessus, mais nous avons rapidement migré vers l'architecture ci-dessous, ce qui nous permet d'héberger des LLM avec des coûts très bas et une grande fiabilité.
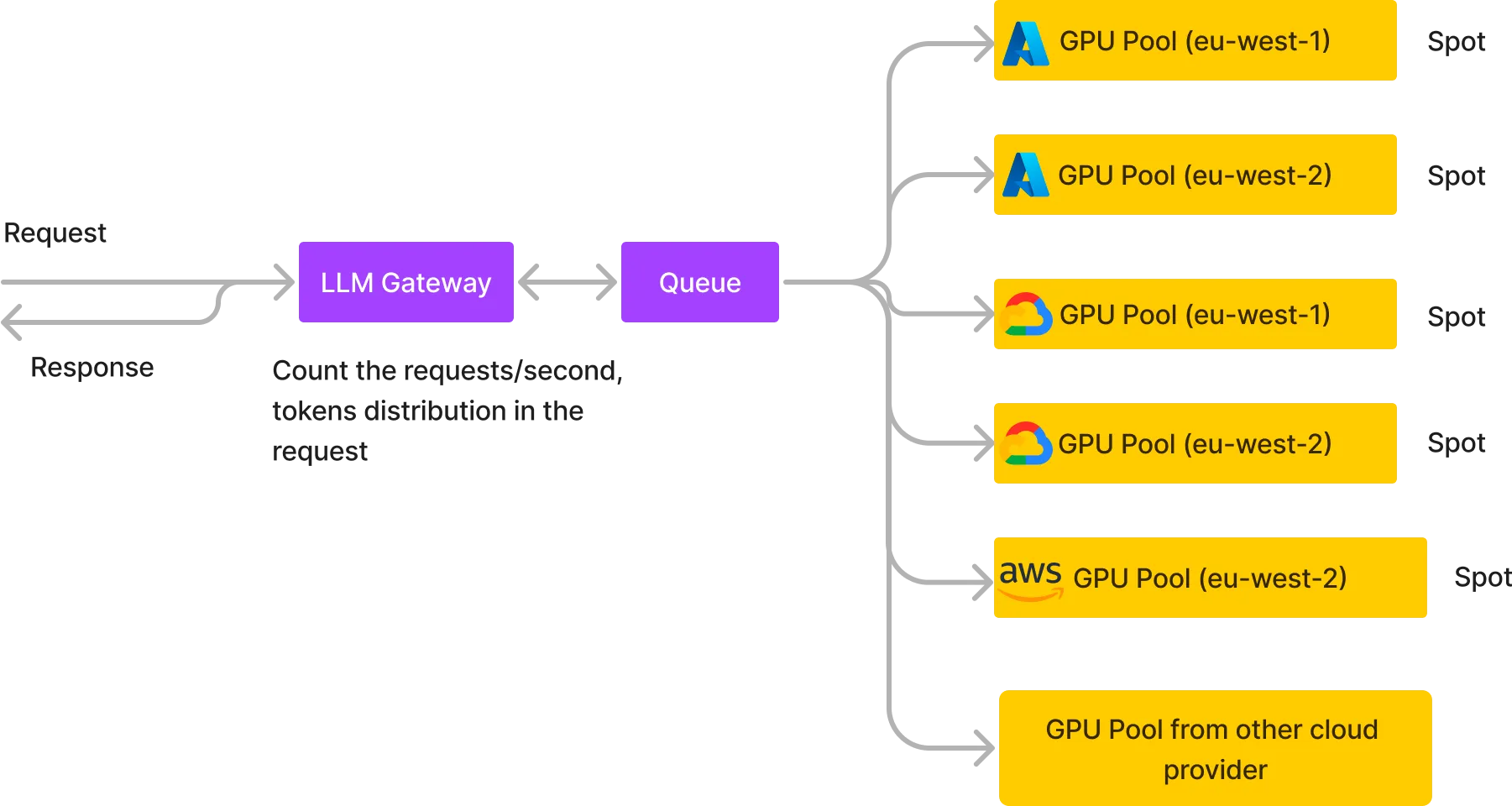
Nous créons essentiellement plusieurs pools de GPU sur différents fournisseurs de cloud dans différentes régions et nous utilisons généralement des instances ponctuelles s'il s'agit de l'un des nœuds AWS, GCP ou Azure ou à la demande des plus petits fournisseurs de cloud. Nous plaçons également une file d'attente au milieu qui reçoit toutes les requêtes et les différents pools de GPU consomment de la file d'attente et renvoient la réponse à la file d'attente d'où la réponse HTTP est renvoyée à l'utilisateur. Quelques avantages de cette architecture :
Prenons le scénario de l'hébergement d'un LLM avec 10 demandes par seconde en période de pointe et 7 demandes par seconde en moyenne. Disons que nous découvrons, à l'aide d'une analyse comparative, qu'une machine GPU A100 de 80 Go peut faire 0,5 RPS. Considérons également que le trafic est plus intense pendant 12 heures par jour (environ 9 à 10 RPS) et faible pendant les 12 heures restantes par jour (7 à 8 RPS).
Sur la base des données ci-dessus, nous pouvons déterminer le nombre de machines GPU nécessaires pendant la période de pointe de 12 heures et pendant la période hors pointe de 12 heures :
Période de pointe de 12 heures : 20 PROCESSEURS GRAPHIQUES
Période de 12 heures en dehors des heures de pointe : 15 PROCESSEURS GRAPHIQUES
Nous comparerons le coût de fonctionnement du LLM à l'aide de Sagemaker, de l'hébergement naïf sur des machines à la demande dans AWS, GCP et Azure et de l'utilisation de notre propre architecture avec mise à l'échelle automatique.
Coût de l'hébergement sur Sagemaker (région us-east-1) :
Coût de 8 machines A100 de 80 Go (ml.p4de.24xlarge) -> 47,11$ de l'heure
Nous aurons besoin de 2 machines en dehors des heures de pointe et de 3 machines pendant les heures de pointe.
Coût mensuel total : 85 000$
Coût de l'hébergement direct sur les nœuds AWS :
Coût de 8 machines A100 de 80 Go (p4de.24xlarge) -> 40,966$ de l'heure
Nous aurons besoin de 2 machines en dehors des heures de pointe et de 3 machines pendant les heures de pointe :
Coût mensuel total : 73 000$
Coût de l'hébergement sur Truefoundry
En utilisant les instances spot et d'autres fournisseurs de GPU, nous sommes en mesure de réduire le prix moyen des GPU à 2,5 dollars de l'heure. En supposant 15 GPU en dehors des heures de pointe et 20 GPU en heures de pointe, le coût total sera de :
2,5$ * (15*12 + 20*12) * 30 (jours par mois) = 31 000$
Comme nous pouvons le constater, nous sommes en mesure d'héberger le même LLM à près de 30 % du prix du Sagemaker avec une grande fiabilité. Cependant, il faudra déployer des efforts pour construire et maintenir cette architecture. True Foundry peut vous aider à l'héberger pour vous ou à l'héberger sur votre propre compte cloud en toute simplicité, tout en réduisant les coûts.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception








.png)

.webp)
.webp)
.webp)



.webp)
.webp)


