




October 5, 2023
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: June 24, 2026

Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
OpenAI et Langchain ont rendu très facile la création d'une démo permettant de répondre à des questions sur vos documents. Il existe de nombreux articles sur Internet expliquant comment procéder. Nous avons également un bloc-notes de travail au cas où vous voudriez jouer avec un système de bout en bout :
Dans cet article, nous verrons comment produire un robot de réponse aux questions sur vos documents. Nous le déploierons également dans votre environnement cloud et permettrons également l'utilisation de LLM open source au lieu d'OpenAI si la confidentialité et la sécurité des données constituent l'une des exigences fondamentales.
Le flux de travail clé pour créer le système d'assurance qualité à l'aide de RAG (Génération augmentée par récupération) est le suivant :
Flux d'indexation des documents :
Obtenir la réponse à la requête de l'utilisateur :
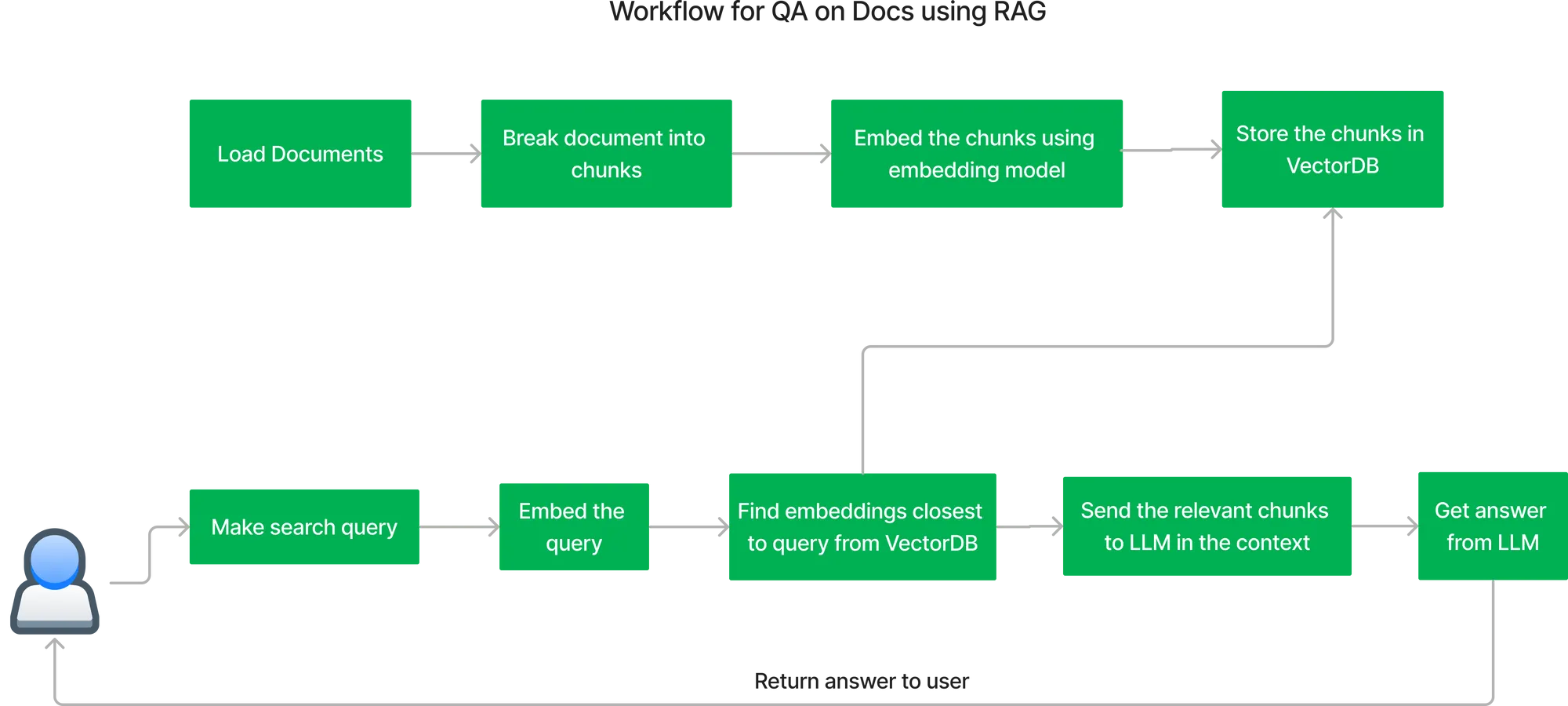
Pour déployer l'ensemble du flux décrit ci-dessus, nous devons déployer un certain nombre de composants ensemble. Voici le schéma d'architecture du déploiement de RAG sur votre propre cloud.
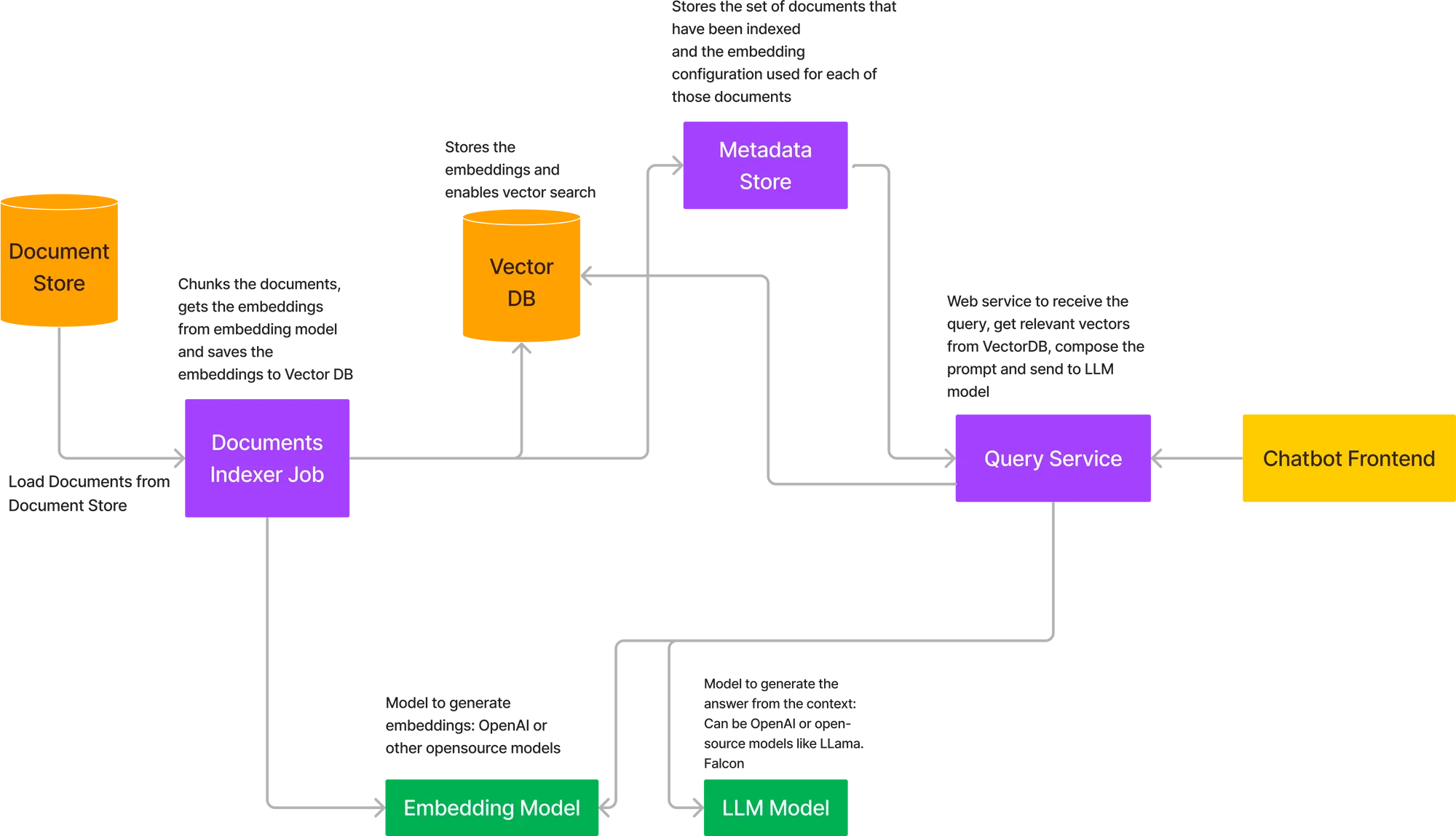
Les principaux composants de l'architecture ci-dessus sont les suivants :
C'est ici que les documents seront stockés. Dans de nombreux cas, il s'agira d'AWS S3, de Google Storage Buckets ou d'Azure Blob Storage. Dans certains cas, ces données peuvent également provenir d'API s'il s'agit de quelque chose comme Confluence Docs.
Cela sera modélisé de la même manière qu'un travail de formation en machine learning, qui obtient les documents en entrée, les divise en morceaux, appelle le modèle d'intégration pour intégrer les morceaux et stocke les vecteurs dans la base de données. Le modèle d'intégration peut être chargé dans la tâche elle-même ou appelé API. La route de l'API est préférée car le modèle d'intégration peut alors être étendu indépendamment en cas de grand nombre de documents. Les tâches peuvent être déclenchées ad hoc ou selon un calendrier s'il y a un flux de documents entrant. Une fois la tâche terminée, celle-ci doit également enregistrer le statut Réussite dans un magasin de métadonnées, ainsi que les paramètres d'intégration.
Si nous utilisons OpenAI ou un modèle hébergé en externe, nous n'avons pas besoin d'héberger un modèle dans ce cas. Cependant, si nous utilisons un modèle open source, nous devrons l'héberger dans notre environnement cloud, puis obtenir les intégrations à l'aide de l'API.
Si nous utilisons OpenAI ou des API de modèles hébergés comme Cohere et Anthropic, nous n'avons rien à déployer, sinon nous devons déployer des LLM open source.
Il peut s'agir d'un service FastAPI qui fournit l'API pour répertorier toutes les collections de documents indexés et permet à l'utilisateur d'interroger les collections de documents. Il y aura également une API pour déclencher une nouvelle tâche d'indexation pour une nouvelle collection de documents.
Nous pouvons utiliser une solution hébergée ici comme PineCone ou héberger l'un des VectorDB open source comme Qdrant ou Milvus.
Cela est nécessaire pour stocker les liens vers les documents qui ont été indexés et quelle a été la configuration utilisée pour intégrer les morceaux dans ces documents. Cela permet à l'utilisateur de sélectionner l'ensemble de documents à interroger et peut prendre en charge plusieurs ensembles de documents au sein d'une organisation.
Véritable fonderie est une plateforme sur Kubernetes qui permet de déployer très facilement des tâches et des services de formation ML au coût le plus optimal. Grâce à Truefoundry, nous pouvons déployer tous les composants de l'architecture ci-dessus, sur votre propre compte cloud. Le déploiement final sur votre cloud ressemblera à ceci :
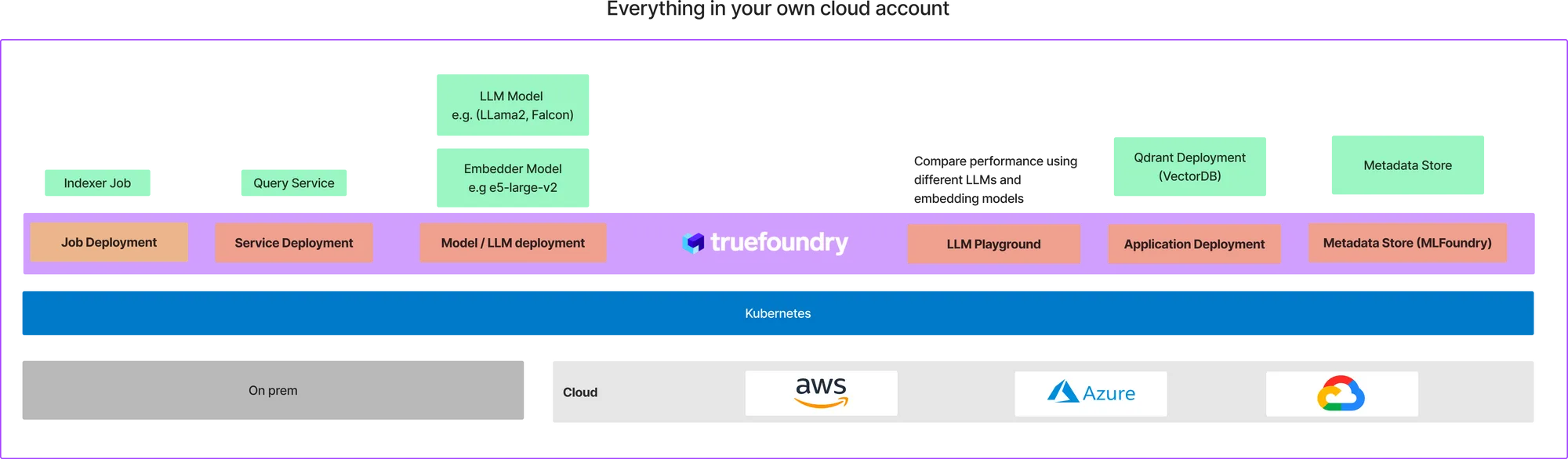
Cela peut sembler fastidieux, nous avons déjà créé un modèle pour vous aider à démarrer en moins de 10 minutes. Nous supposons que vous êtes déjà intégré à TrueFoundry. Si vous n'êtes pas déjà inscrit, suivez ce lien guide pour vous intégrer. TrueFoundry fonctionne sur les trois principaux fournisseurs de cloud : AWS, Azure et GCP. Vous devriez donc pouvoir le configurer sur n'importe lequel de ces fournisseurs de cloud.
Nous avons créé pour vous un exemple de robot d'assurance qualité avec le code d'une tâche d'indexation, d'un service de requêtes et d'une interface de discussion utilisant streamlit dans ce dépôt Github :
Vous pouvez le déployer sur TrueFoundry dans votre propre cloud en 15 minutes. Cela permettra une configuration au niveau de la production et vous donnera également une flexibilité totale pour modifier le code selon vos propres cas d'utilisation.
Nous déploierons l'ensemble de l'architecture sur un cluster Kubernetes. Vous pouvez trouver l'intégralité du code et les instructions de déploiement sur ce dépôt github.
TrueFoundry fournit une abstraction facile à utiliser sur Kubernetes pour déployer différents types d'applications sur Kubernetes. Nous allons passer en revue les différentes étapes du déploiement de RAG sur votre cloud.
Truefoundry est livré avec un magasin de métadonnées sous la forme de dépôts ML. Vous pouvez stocker des artefacts, des métadonnées et bibliothèque de tuyaux mlfoundry fournit des méthodes pour charger et télécharger les artefacts. Chaque dépôt ML est soutenu par le stockage blob cloud (AWS S3, GCS ou Azure Blob Storage). Nous allons d'abord commencer par créer un dépôt ML, puis télécharger nos documents pour les indexer en tant qu'artefact. Pour créer un dépôt ML, suivez le guide ci-dessous : https://docs.truefoundry.com/docs/creating-ml-repo-via-ui
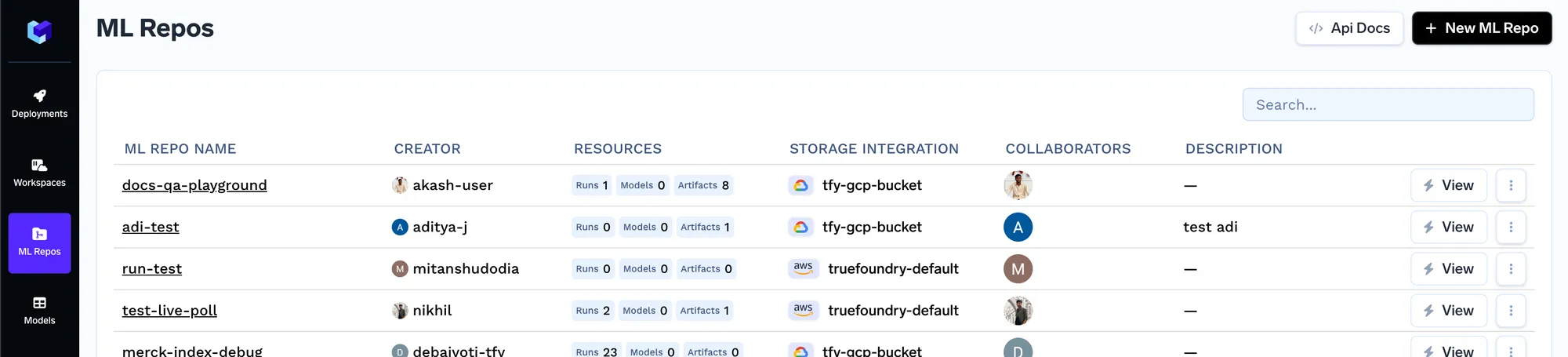
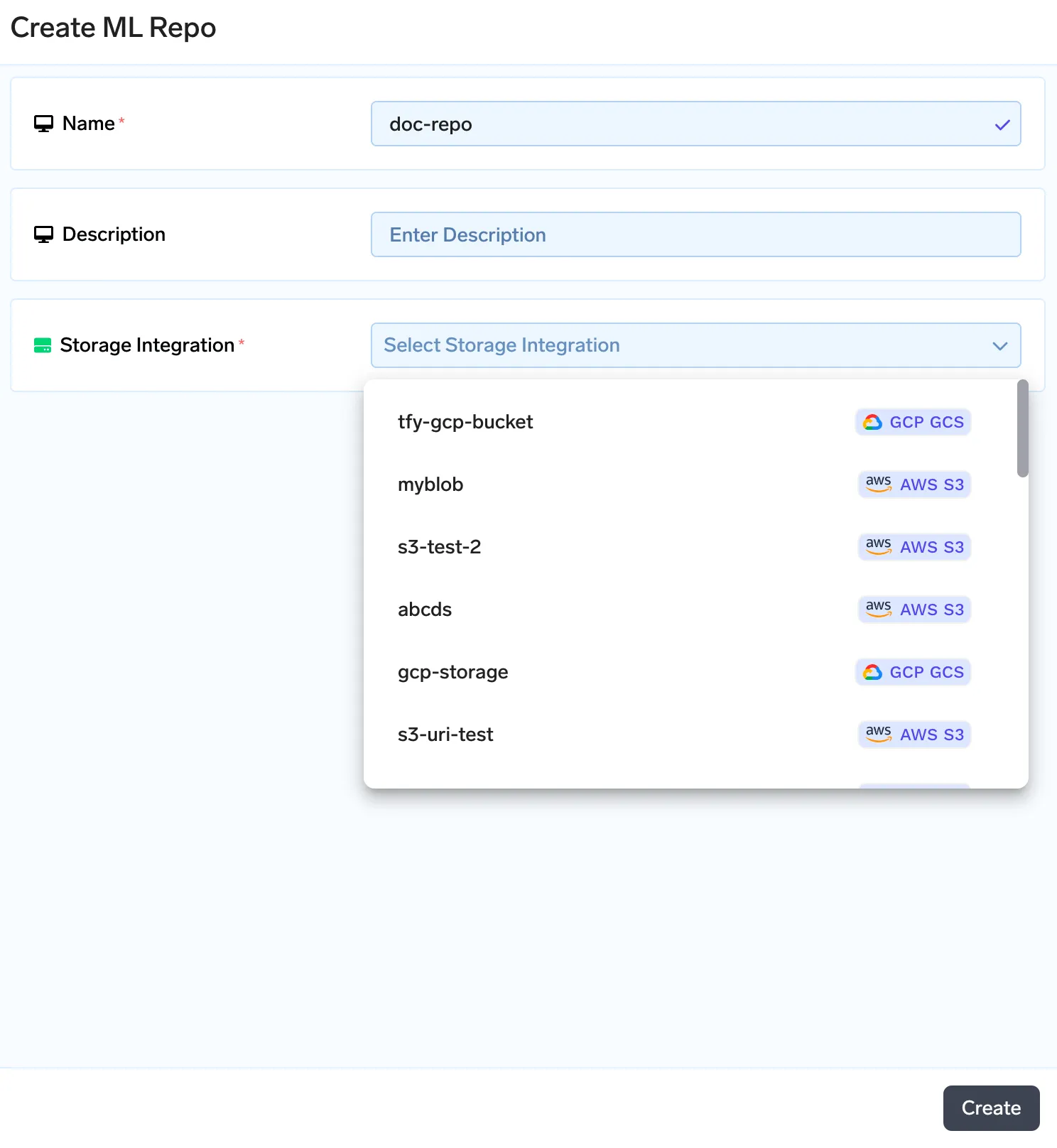
Une fois que nous aurons créé un artefact, nous en créerons une nouvelle version. Ainsi, chaque fois que l'ensemble de documents change, vous pouvez télécharger le nouvel ensemble de documents en tant que nouvelle version. Vous pouvez télécharger vos documents sur l'écran ci-dessous.
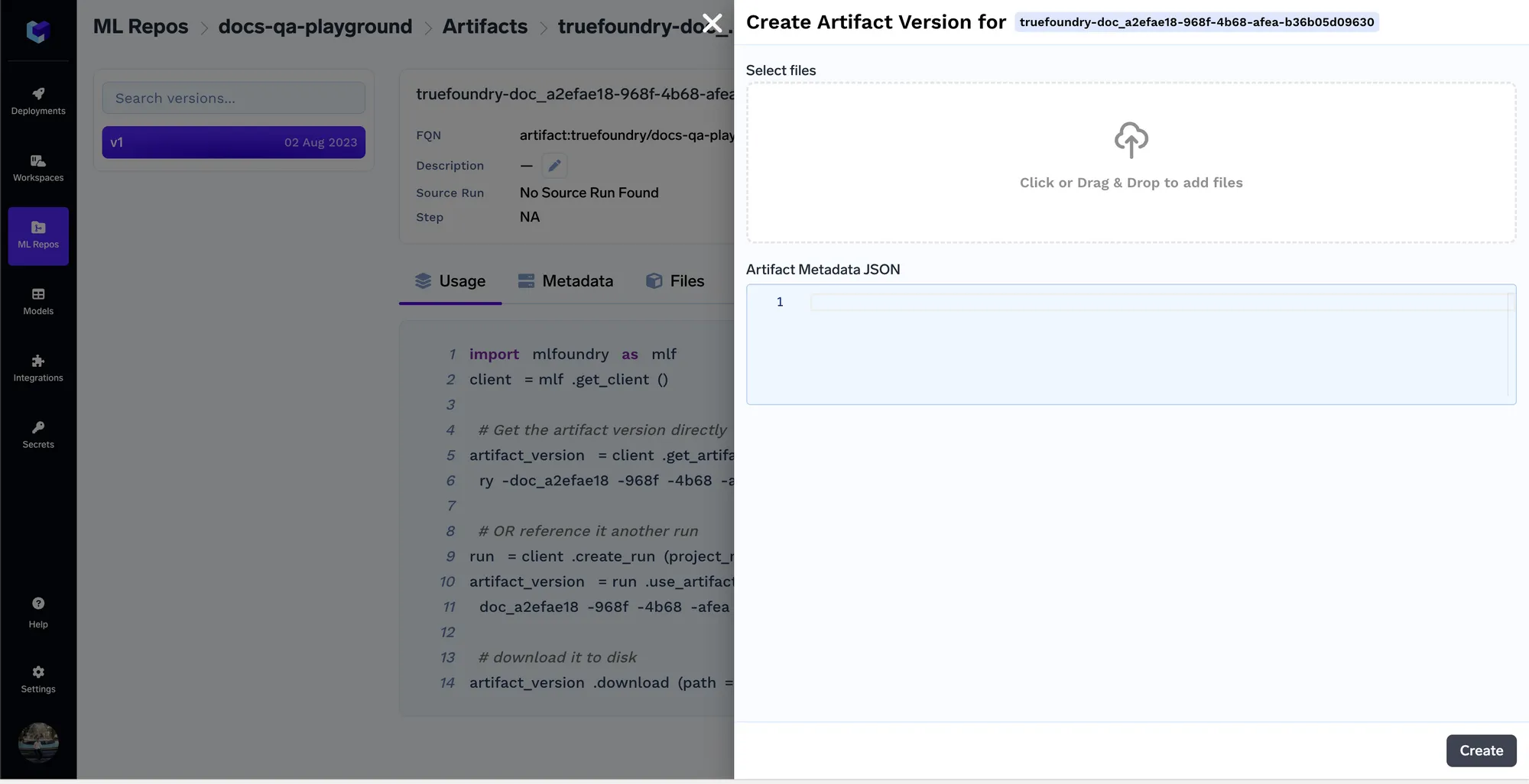
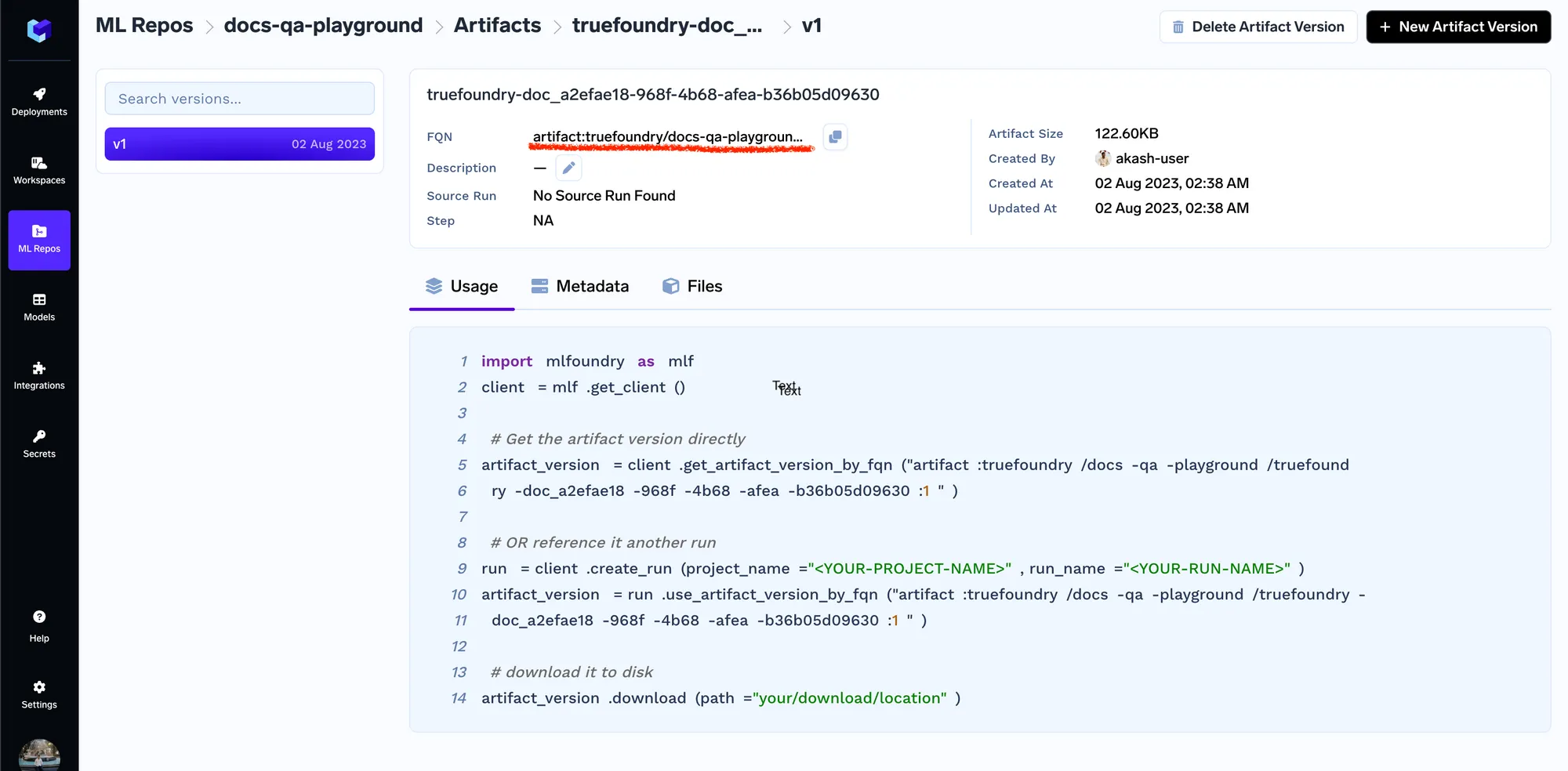
Une fois les documents téléchargés, nous obtiendrons la version de l'artefact fqn à l'aide de laquelle nous pourrons ensuite référencer/télécharger l'artefact en code n'importe où.
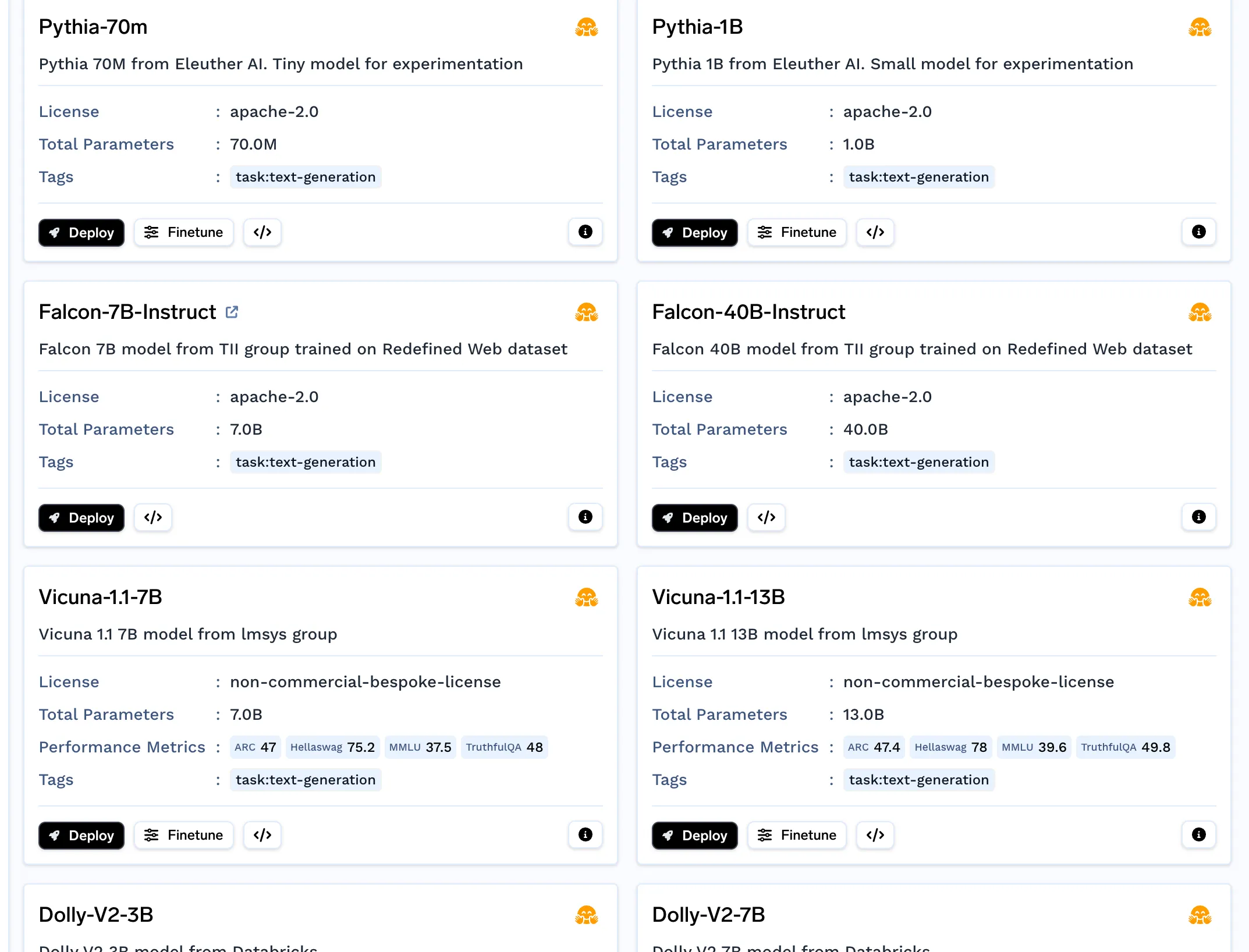
Nous aurons besoin du modèle d'intégration pour intégrer les morceaux. Vous pouvez ignorer cette étape si vous utilisez OpenAI Embeddings. Vous pouvez déployer n'importe quel modèle d'intégration du catalogue de modèles. En général, nous avons constaté que e5-large-v2 fonctionnait assez bien.
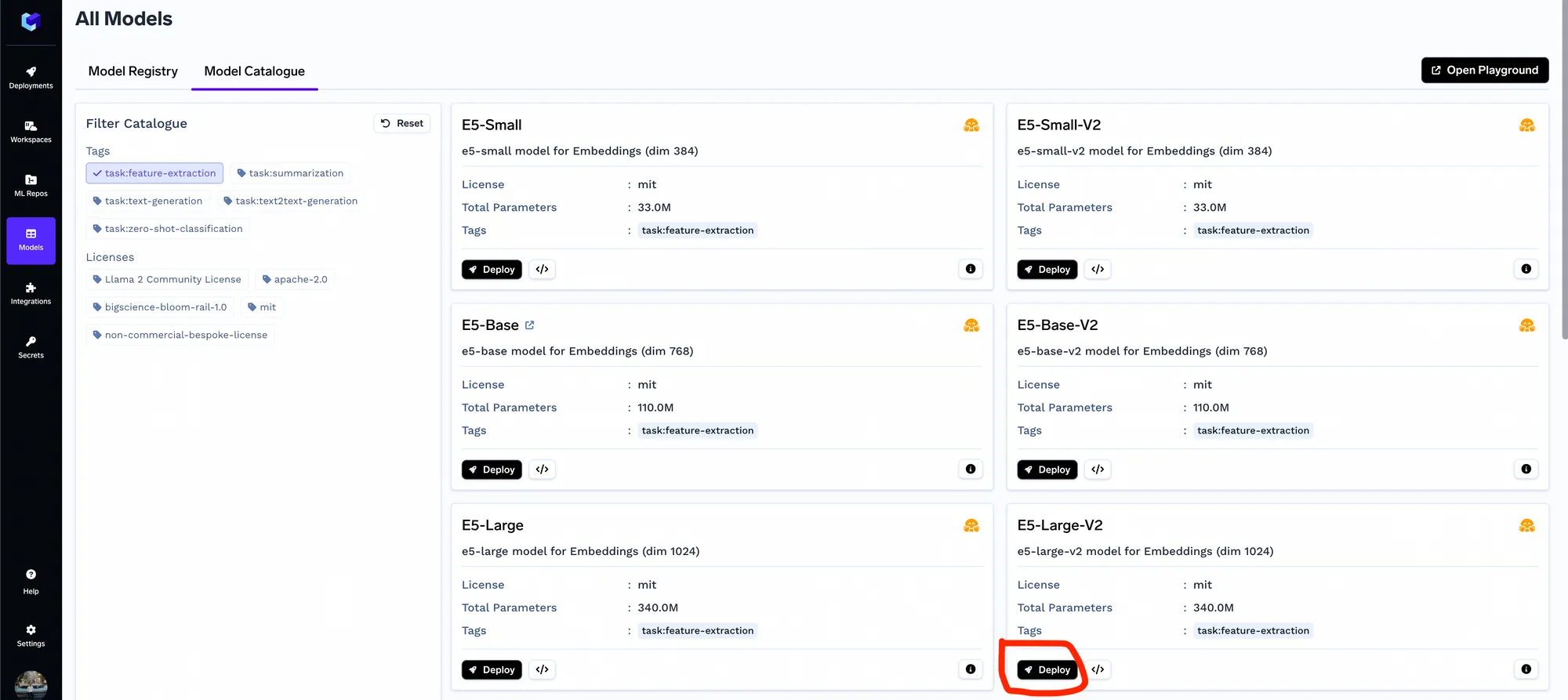
Une fois le modèle d'intégration déployé, vous pouvez vérifier les API à l'aide du terrain de jeu OpenAPI sur le tableau de bord Truefoundry.
Nous allons déployer le Qdrant VectorDB.
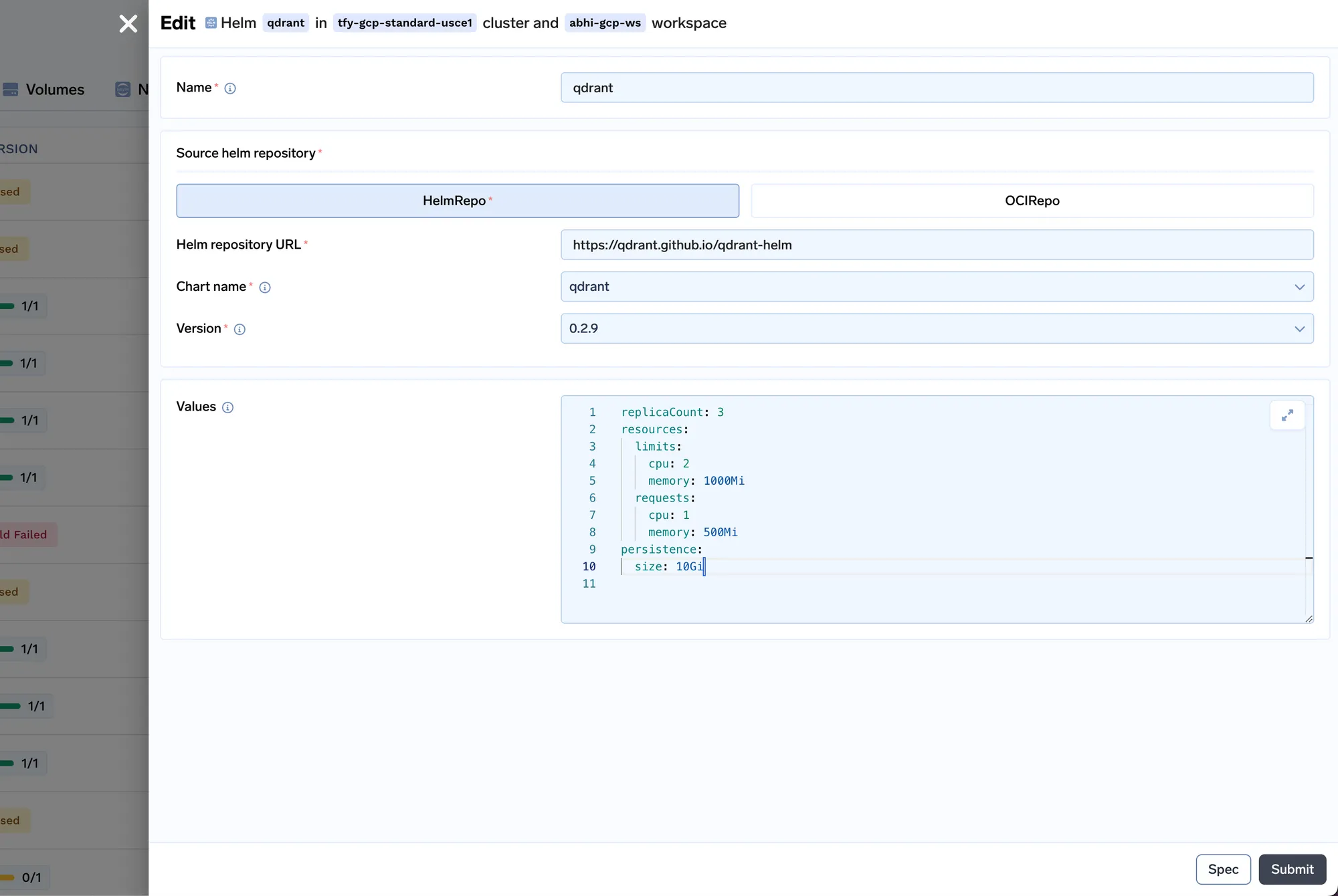
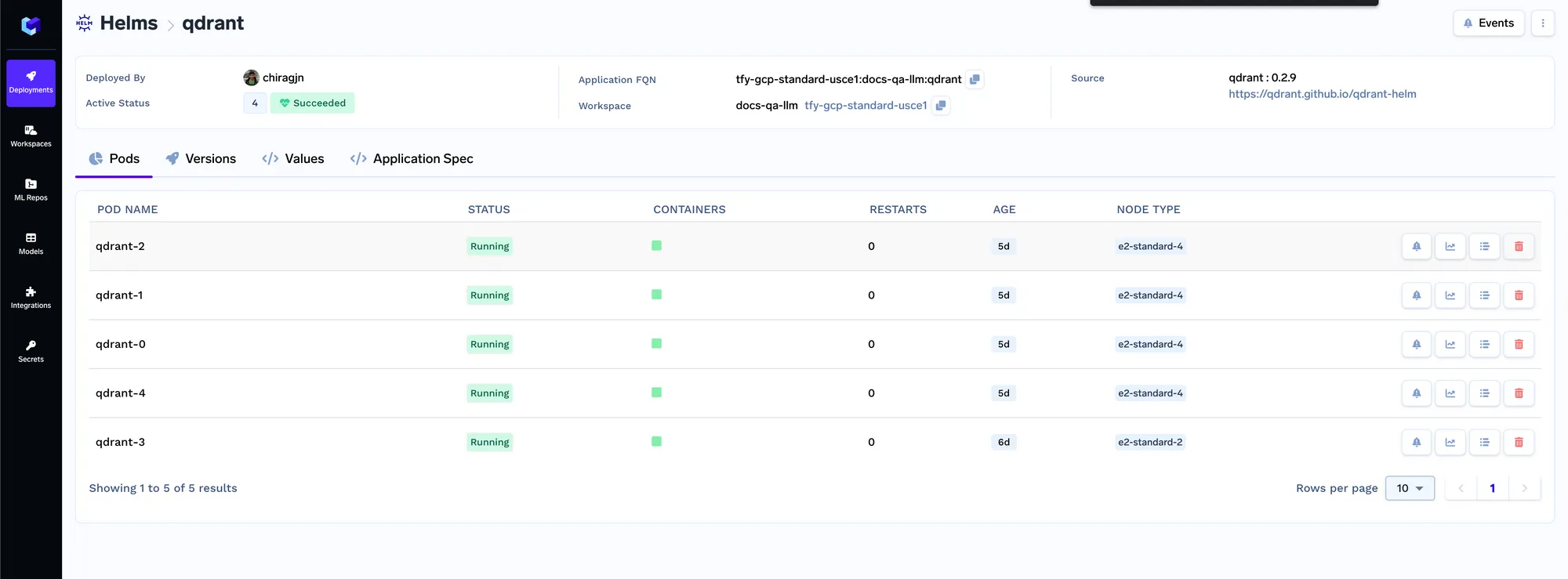
Nous allons maintenant déployer le job d'indexeur. Job in Truefoundry nous permet d'exécuter un script une fois ou dans les délais prévus, puis le calcul s'arrête une fois le travail terminé. Le code de tâche de l'indexeur se trouve ici : https://github.com/truefoundry/docs-qa-playground/tree/main/backend/train. La tâche d'indexation prend en charge le chargement de données à partir de fichiers locaux ou d'un artefact mlfoundry. Il affiche également automatiquement un formulaire dans lequel vous pouvez fournir des arguments pour déclencher la tâche. <artifact_fqn>Vous pouvez saisir le ventilateur d'artefact que nous avons copié à l'étape 1 et le coller dans le champ URI source sous la forme mlfoundry ://. Le nom du dépôt peut être n'importe quelle chaîne aléatoire qui vous aide à identifier cette tâche d'indexation. Vous devez également saisir le nom du dépôt ML que nous avons créé à l'étape 1.
Une fois que la tâche commence à s'exécuter, vous pouvez suivre toutes les exécutions et leurs journaux :
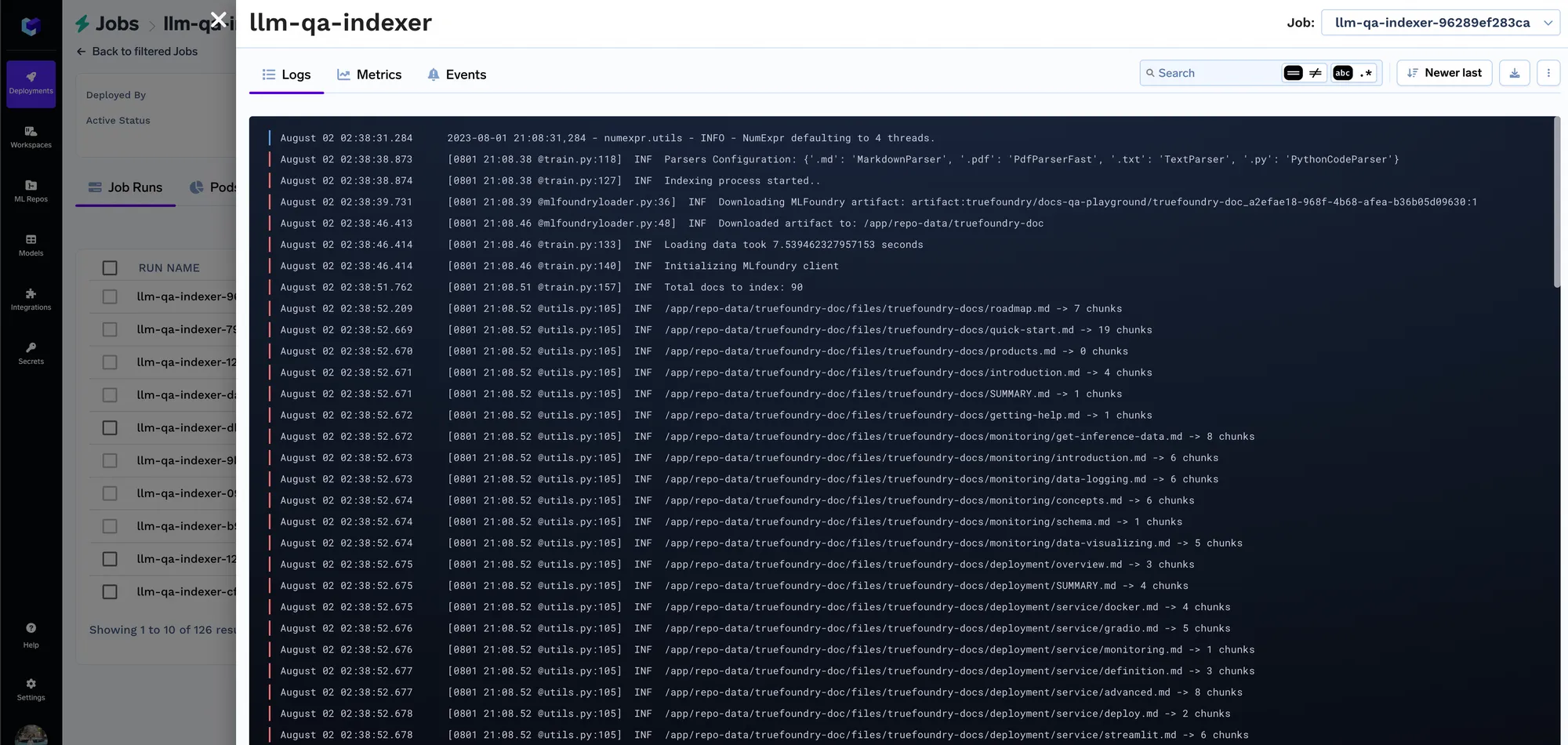
Chaque fois que la tâche est exécutée, nous créons une exécution dans le référentiel ML qui stocke tous les paramètres d'intégration et les paramètres de la tâche d'indexation. Ces paramètres sont ensuite utilisés par le service de requêtes pour déterminer les paramètres d'intégration à utiliser pour intégrer la requête. Vous pouvez suivre les détails de toutes les tâches d'indexation dans l'onglet Exécutions.
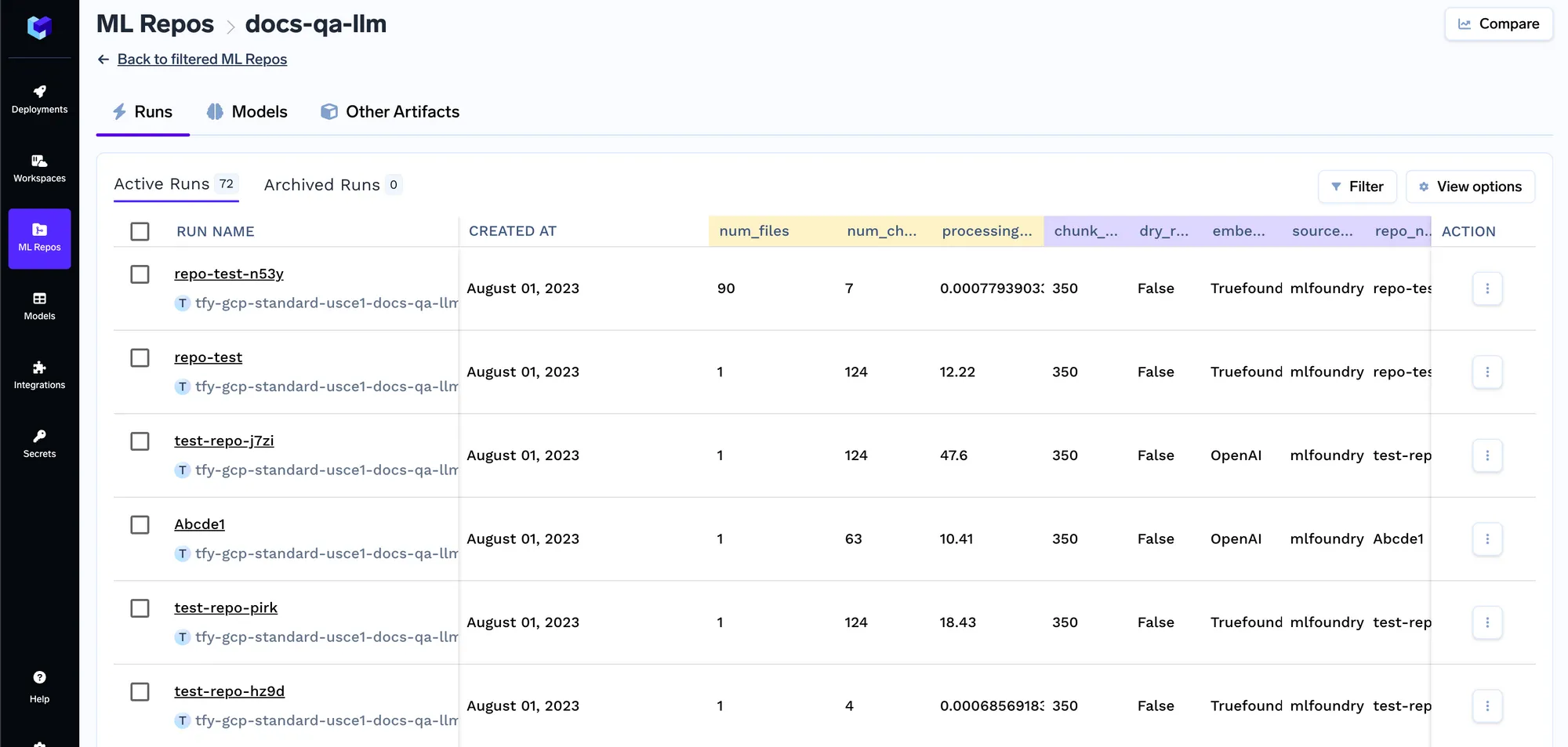
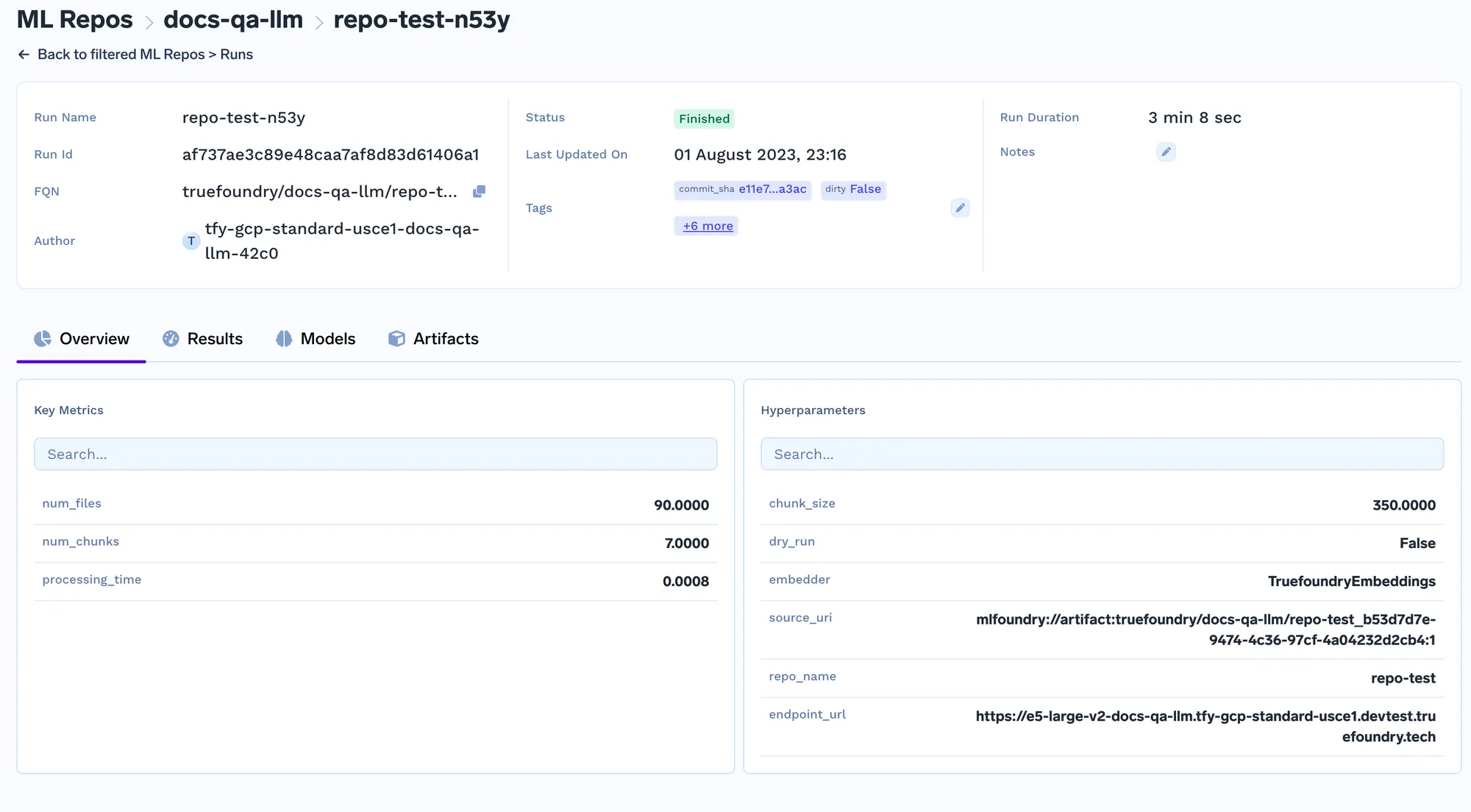
Le service de requête est un serveur fastapi doté d'une API pour obtenir la requête et obtenir la réponse du LLM. Une fois que vous l'avez déployé, vous pouvez effectuer des requêtes à l'aide de l'interface utilisateur Swagger sur fastapi.
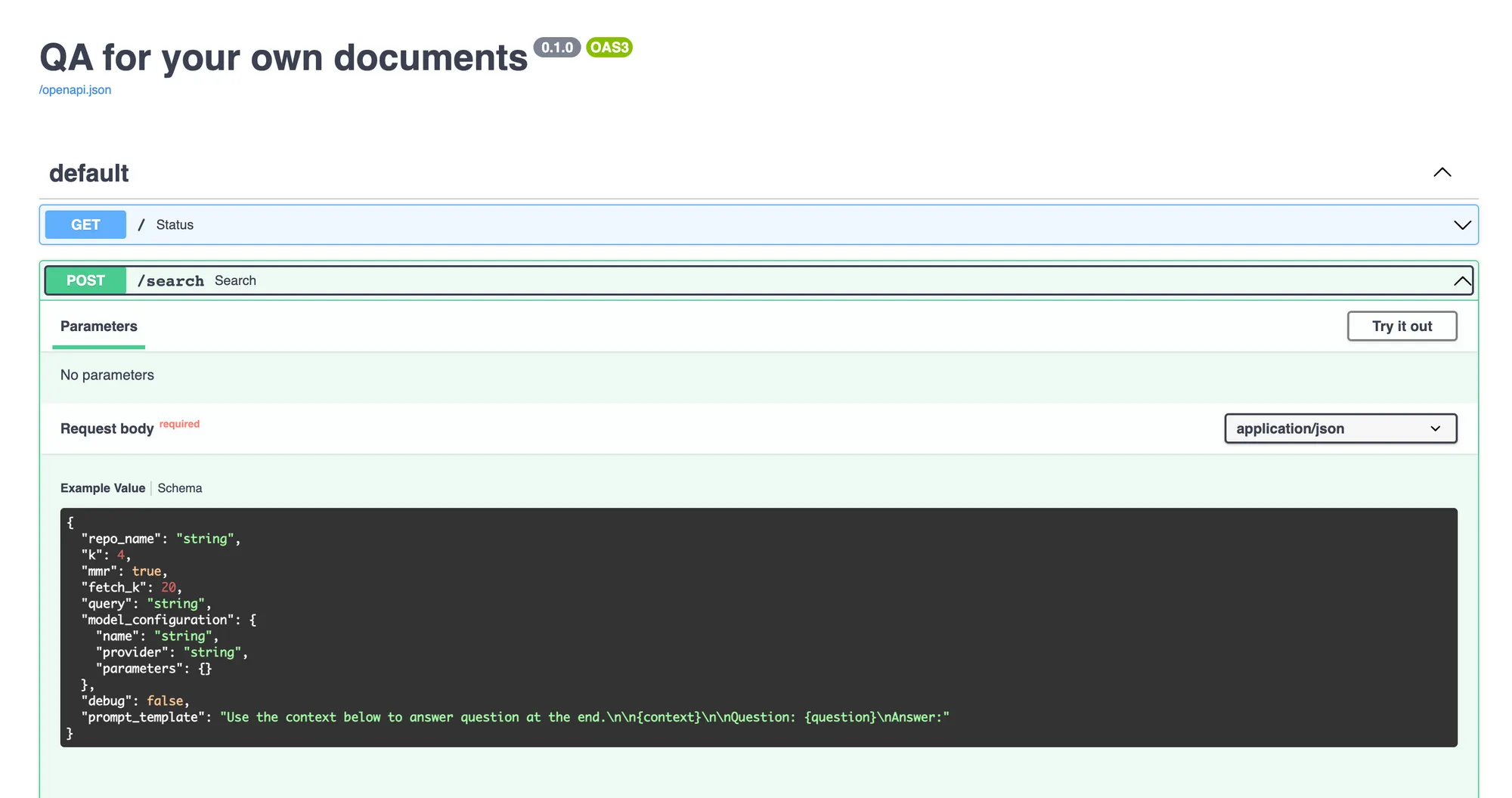
Cela est nécessaire si vous envisagez d'utiliser un LLM open source et non OpenAI. Vous pouvez déployer le LLM à partir du catalogue de modèles.
Nous proposons également une application simplifiée qui peut être liée à votre backend d'indexation, à votre service de requêtes et à votre magasin de métadonnées pour répertorier tous les référentiels indexés et les interroger. Un exemple de démonstration est disponible sur https://www.truefoundry.com/docs/introduction. Vous pouvez trouver le code dans le dépôt github ici. Pour que cette interface fonctionne, vous devrez la lier à votre service de requêtes et à votre tâche à l'aide de variables d'environnement :
Nous disposons désormais d'un système de bout en bout doté d'une interface qui peut s'adapter à autant de cas d'utilisation et d'ensembles de documents différents au sein de l'organisation. Il y a quelques éléments que nous souhaitons intégrer à l'avenir :
Cette architecture permet également de disposer d'un service central d'indexation des documents dans une organisation qui s'appuie sur une bibliothèque centrale de chargeurs de données et d'analyseurs.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception








.png)

.webp)
.webp)
.webp)



.webp)
.webp)


