Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.
9,9
Réduisez vos coûts d'infrastructure pour les modèles ML/LLM
Les charges de travail d'apprentissage automatique (ML) et de grands modèles de langage (LLM) sont notoirement coûteuses à exécuter dans le cloud. En effet, ils nécessitent des quantités importantes de puissance informatique, de mémoire et de stockage. Il existe toutefois des moyens de réduire les coûts liés au cloud pour les charges de travail ML/LLM sans sacrifier l'évolutivité ou la fiabilité.
Principes clés pour réduire les coûts
Meilleure visibilité pour les ingénieurs et les développeurs DevOps : Il est difficile d'obtenir une visibilité sur les coûts du cloud, en particulier lorsque plusieurs composants sont déployés sur plusieurs clouds. TrueFoundry fournit une visibilité sur les coûts du cloud au niveau du cluster, de l'espace de travail et du déploiement, permettant aux équipes DevOps et aux développeurs d'identifier et d'optimiser les opportunités de réduction des coûts tout au long du cycle de vie ML/LLM.
Facilité d'ajustement des ressources : TrueFoundry permet aux équipes DevOps et aux développeurs de prendre des mesures en fonction de la visibilité qu'ils ont acquise sur les coûts.
Les équipes DevOps peut définir des contraintes de ressources au niveau du projet, en veillant à ce que les charges de travail de chaque équipe aient accès aux ressources dont elles ont besoin sans dépasser le budget.
Développeurs peuvent également ajuster facilement les ressources à tout moment, en fonction des informations qu'elles obtiennent. En outre, TrueFoundry facilite la mise à l'échelle des applications et des IDE à zéro dans les environnements hors production, éliminant ainsi le coût des ressources inutilisées et rendant les cycles d'itération permettant de réduire les coûts plus efficaces.
Optimisation de l'infrastructure en termes de coûts : L'architecture basée sur Kubernetes et les optimisations de l'infrastructure de TrueFoundry sont conçues pour réduire les coûts du cloud.
Dans l'ensemble, les fonctionnalités économiques de TrueFoundry fournissent aux équipes DevOps et aux développeurs les fonctionnalités de visibilité, de contrôle et d'optimisation dont ils ont besoin pour réduire les coûts du cloud tout au long du cycle de vie ML/LLM.
Transition entre AMI et Docker : Notre plateforme a permis à de nombreuses entreprises de migrer d'AMI vers Docker, où elles ont déjà réalisé des économies de coûts de 30 à 40 %.
TrueFoundry : votre plateforme axée sur le coût
Truefoundry est un « le coût d'abord » plateforme, construite autour de Kubernetes, conçue avec une architecture qui donne la priorité à l'efficacité, à l'évolutivité et à la réduction des coûts.
Explorons comment l'architecture unique de TrueFoundry vous permet de réaliser des économies tout en optimisant la fiabilité et l'évolutivité. Voici la structure hiérarchique de la plateforme :
Clusters : Connectez tous vos clusters, qu'il s'agisse d'AWS EKS, d'Azure AKS, de GCP GKE ou d'un cluster sur site, à la plateforme. Cela vous permet d'intégrer facilement tous vos clusters en un seul endroit. Ces clusters constituent la base du déploiement d'un large éventail de services, de modèles et de tâches.
Espaces de travail : Au sein des clusters, nous introduisons des espaces de travail, offrant une approche rationalisée pour ajouter le contrôle d'accès et l'isolation afin de garantir que chaque projet ou environnement dispose de ses propres ressources dédiées et est protégé contre tout accès non autorisé. Considérez-les comme des groupes de déploiements.
Déploiements : Au sein de ces espaces de travail, nous effectuons des déploiements et nous vous aidons à déployer différents types de choses. Avec TrueFoundry, vous pouvez couvrir sans effort tous les aspects de votre cycle de vie de développement de machine learning.
Environnements de développement interactifs : Déployez Jupyter Notebook et VS Code pour des expériences collaboratives.
Emplois de formation et de mise au point : Entraînez efficacement les modèles ML ou affinez les modèles LLM en les déployant en tant que tâche.
LLMs pré-formés : Déployez rapidement des modèles de langage étendus pré-entraînés pour des cas d'utilisation spécifiques à l'aide de notre catalogue de modèles.
Services et applications : Déployez une variété de services et d'applications, notamment des modèles, des applications Web, etc.
Catalogue d'applications : Déployez facilement des logiciels populaires tels que Label Studio, Redis, Qdrant, etc.
Économies de coûts au niveau du cluster
Infrastructure basée sur Kuberenetes
Kubernetes contribue à la réduction des coûts en utilisant l'emballage en bacs pour optimiser l'utilisation des ressources, en plaçant efficacement les conteneurs et, en fin de compte, en réduisant les coûts d'infrastructure.
Pour en savoir plus sur la façon dont TrueFoundry exploite Kuberenetes, lisez ici.
💡
Migration d'EC2 vers Kubernetes : De nombreuses entreprises sont passées avec succès des machines EC2 à Kubernetes après leur intégration à notre plateforme, ce qui a permis de réaliser des économies grâce à une meilleure allocation des ressources
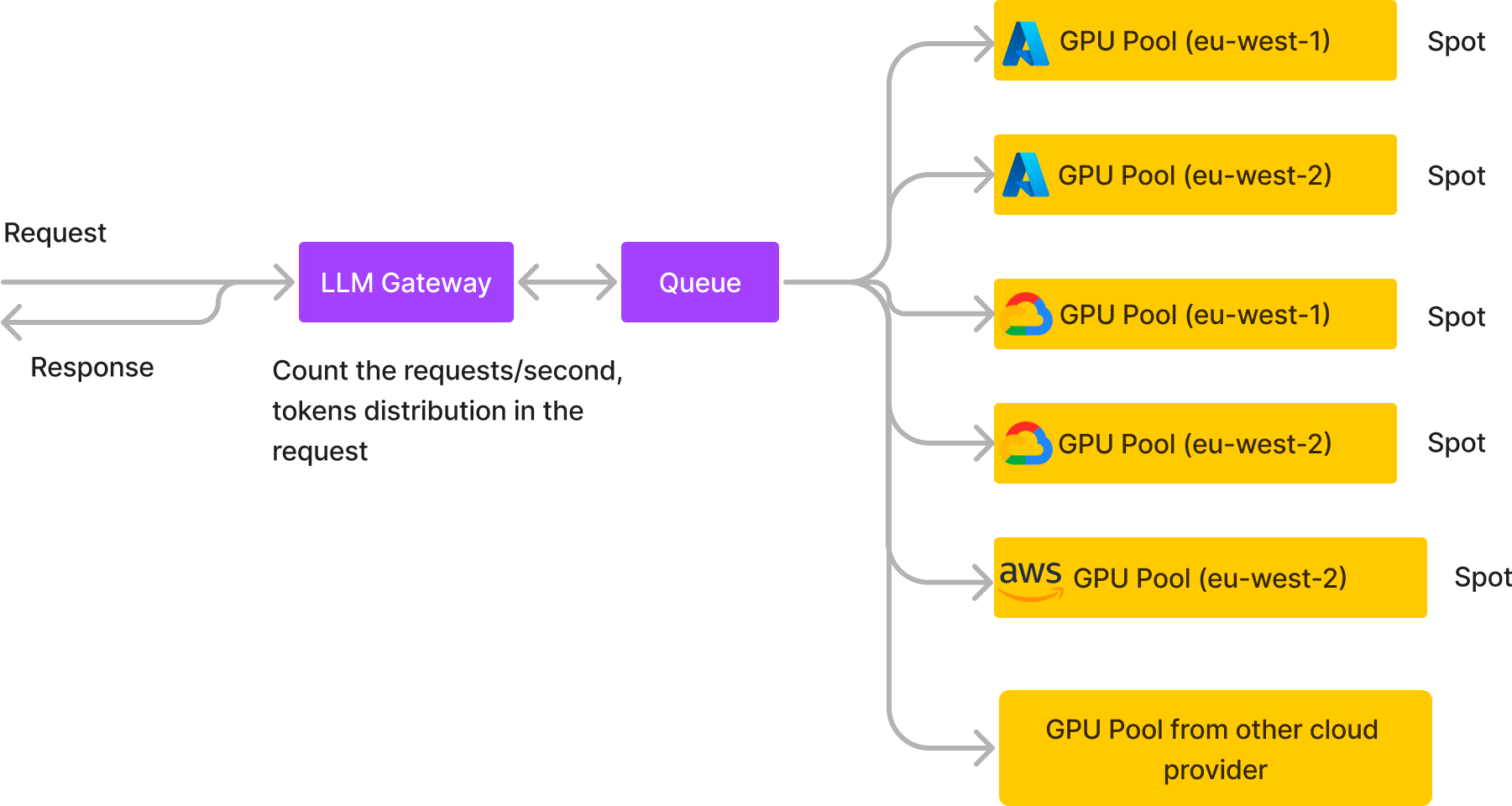
Prise en charge de plusieurs clouds
L'architecture multicloud de TrueFoundry facilite la connexion à différents fournisseurs de cloud.
Flexibilité pour passer d'un cloud à l'autre: En ayant la possibilité de passer facilement d'un fournisseur de cloud à un autre, vous pouvez bénéficier des meilleurs prix et des meilleures fonctionnalités de différents fournisseurs.
Répartissez les charges de travail entre les clouds et les régions: en répartissant vos charges de travail entre plusieurs fournisseurs de cloud et régions. Cela peut contribuer à réduire les coûts en répartissant vos charges de travail entre différents niveaux de tarification et différentes régions. Il contribue également à améliorer les performances et la fiabilité en réduisant votre dépendance à l'égard d'un seul fournisseur de cloud.
Quota de disponibilité élevé des instances: En utilisant plusieurs fournisseurs de cloud, vous pouvez accéder à davantage de ressources. Cela peut vous aider à économiser de l'argent et à éviter toute limitation des ressources dont vous avez besoin.
Adaptation des LLM à de multiples clouds et régions
💡
Un fournisseur de chatbot d'intelligence artificielle conversationnel de niveau intermédiaire avec un trafic utilisateur élevé (plus de 20 RPS et plus de 2 millions de requêtes par jour) fonctionne entièrement sur des instances GPU ponctuelles distribuées sur cinq clusters répartis dans différents clouds et régions à l'aide de notre service asynchrone. Cela réduit leurs coûts d'infrastructure de 60 % tout en améliorant la fiabilité et le débit.
Visibilité améliorée
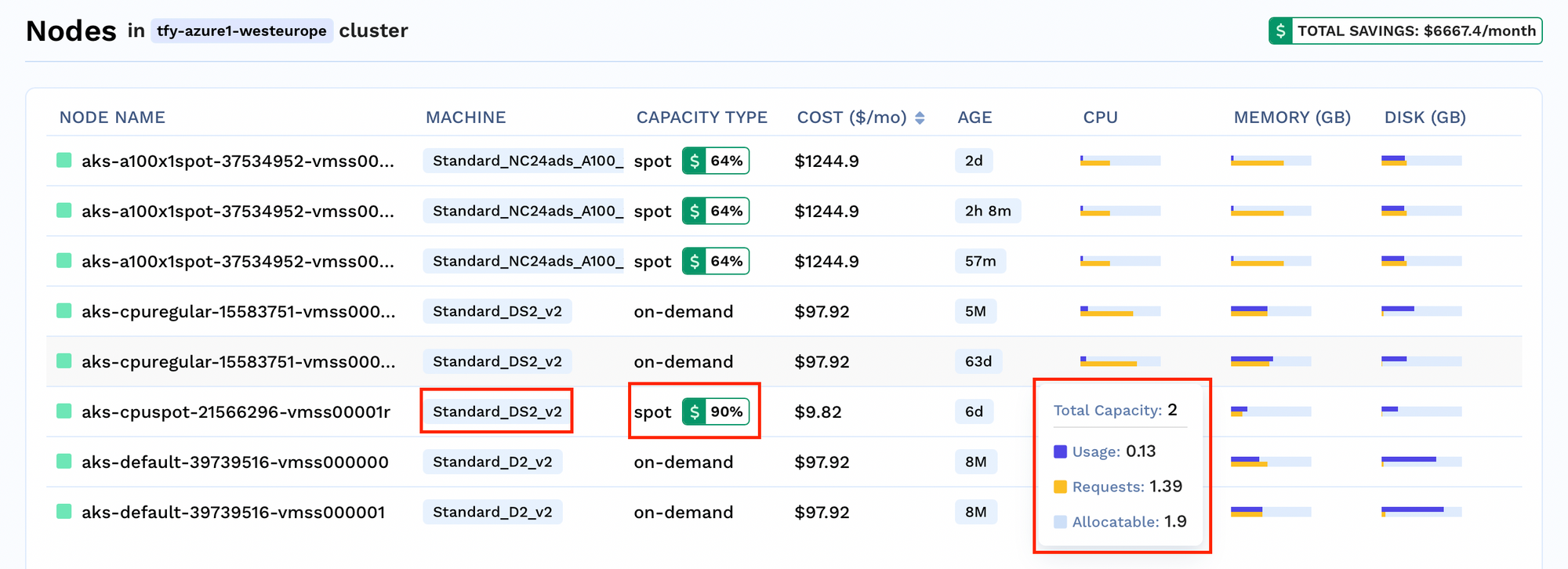
Pour chaque cluster, vous pouvez afficher le nombre de nœuds en cours d'exécution dans le cluster. Vous pouvez également obtenir des informations sur les détails spécifiques aux nœuds, tels que
Analyse des économies: Consultez le pourcentage des coûts économisés pour chaque nœud
Informations sur l'allocation des ressources : Consultez l'utilisation actuelle, la demande de ressources et la limite pour prendre une décision éclairée.
Informations sur les types de capacité: Découvrez quels types de nœuds s'exécutent dans votre cluster, qu'il s'agisse de nœuds ponctuels ou à la demande.
Économies de coûts au niveau de l'espace de travail
Limites de ressources
TrueFoundry vous permet de créer plusieurs espaces de travail au sein d'un cluster. Cette segmentation vous permet d'organiser vos déploiements pour différentes équipes ou différents environnements.
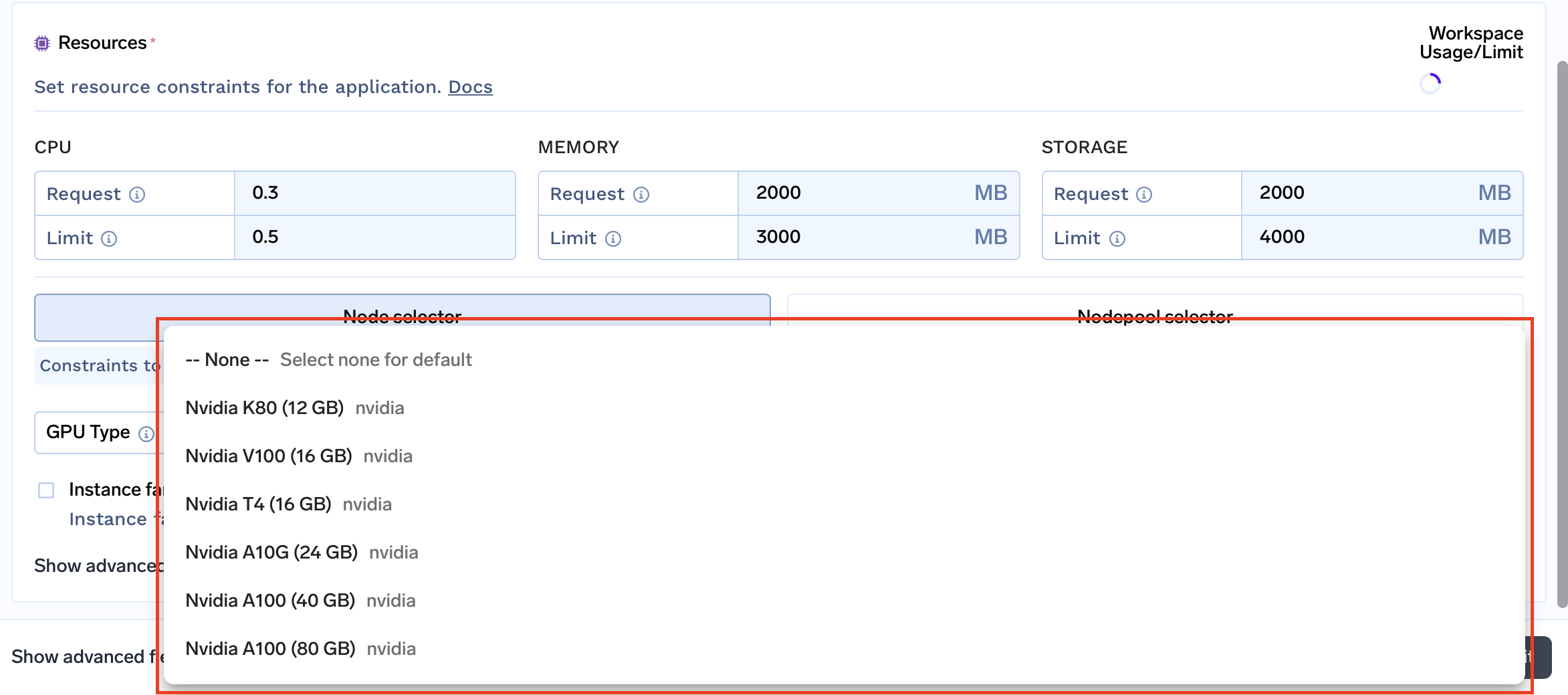
Contraintes liées aux ressources: Personnalisez les contraintes de ressources pour chaque espace de travail, y compris le processeur, la mémoire, le stockage et même les familles d'instances. Cela vous permet d'allouer les ressources pour répondre aux exigences spécifiques de votre projet ou de votre environnement.
Familles d'instances prises en charge: Adaptez votre espace de travail à des exigences de performances et à un budget spécifiques en sélectionnant les familles d'instances qu'il prendra en charge.
Par exemple, si un projet ne nécessite pas de calcul haute performance, vous pouvez désactiver les instances plus importantes dans son espace de travail. Cela aidera à empêcher les développeurs de surapprovisionner les ressources, ce qui peut permettre d'économiser de l'argent.
Pools de nœuds pris en charge: Les pools de nœuds sont des groupes de nœuds qui fournissent les ressources de calcul nécessaires à vos charges de travail. Vous pouvez choisir les pools de nœuds les mieux adaptés à vos charges de travail et à votre budget.
Par exemple, vous pouvez créer un pool de nœuds avec des GPU A100. Ensuite, vous ne pouvez activer ce pool de nœuds spécifique que pour les espaces de travail de projet nécessitant un accès à ce type de GPU.
Suivez le coût au niveau de l'espace de
Nous vous donnons également la visibilité nécessaire pour suivre le coût de votre espace de travail en fonction de votre utilisation passée. Cela vous permettra d'identifier les projets ou les environnements qui utilisent le plus de ressources et les domaines dans lesquels vous pouvez réaliser des économies.
Économies de coûts au niveau du déploiement
Nous proposons des fonctionnalités avancées au niveau de l'application pour vous aider à réaliser d'importantes économies :
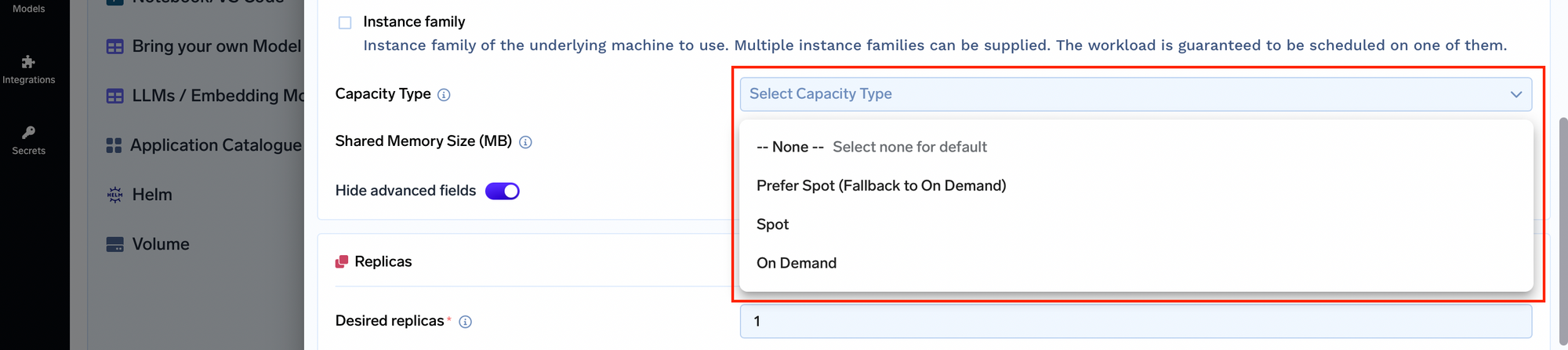
Instances Spot avec retour à la demande: Les applications ont généralement du mal à trouver un équilibre entre coût et fiabilité. TrueFoundry vous permet de sélectionner le type de capacité pour vos nœuds, y compris des instances ponctuelles avec recours à des ressources à la demande. Cela garantit que vos applications restent disponibles même si une instance ponctuelle est expulsée, offrant ainsi un équilibre optimal entre coût et disponibilité.
Interruption des services: Suspendez les services lorsqu'ils ne sont pas utilisés pour réduire les coûts. Suspendez ou reprenez facilement les services depuis la page des déploiements.
Optimisation des ressources: Assurez-vous que vos ressources sont allouées de manière optimale et que vos services fonctionnent à la bonne capacité.
Surveillance des ressources: Suivez l'utilisation des ressources de votre service en temps réel, y compris l'allocation des processeurs et des GPU. Recevez des alertes en cas de surprovisionnement ou de sous-approvisionnement et recevez des recommandations en matière de ressources.
Ajustement dynamique des ressources: Ajustez les niveaux de ressources à la volée pour les réduire à une ressource CPU inférieure et redéployez votre service en conséquence.
Mise à l'échelle automatique basée sur le temps: Planifiez des ajustements de ressources en fonction du temps afin de réduire les coûts dans les environnements hors production pendant les périodes de faible utilisation.
💡
Nombre de nos clients économisent plus de 60 % sur les coûts liés au cloud de leur environnement de développement en planifiant des arrêts en dehors des heures de travail, réduisant ainsi l'utilisation de calcul de 128 heures par semaine.
Économies de coûts au niveau des éditeurs de code
Nous proposons certaines fonctionnalités pour les éditeurs de code, vous permettant de réaliser d'importantes économies au niveau du bloc-notes et du VSCode :
Volumes partagés: Utilisez des volumes en fonction des besoins pour partager des données volumineuses entre des ordinateurs portables et des instances VSCode et faciliter la collaboration. Les volumes partagés réduisent la redondance et améliorent l'efficacité, en particulier lorsque plusieurs utilisateurs ont besoin d'accéder à des données importantes via des ordinateurs portables et des instances VSCode.
Utilisation adaptative des ressources : Basculez facilement entre le processeur et le processeur graphique sur la même machine pour optimiser l'allocation des ressources. Vous n'êtes pas obligé de maintenir une ressource GPU en permanence, mais uniquement en cas de besoin.
💡
Une société d'IA générative opérant dans le segment de la génération vidéo, qui gère des centaines d'instances ponctuelles de Jupyter Notebooks pour des charges de travail hors production, a économisé environ 50 à 60 % sur les coûts du cloud en activant les GPU uniquement en cas de besoin.
Pause manuelle : Suspendez facilement les instances Notebooks/VSCode lorsqu'elles ne sont pas utilisées. Le code et les données sont conservés, ce qui garantit un redémarrage fluide en cas de besoin.
Pause automatique: Configurez vos instances Notebooks/VSCode pour qu'elles s'interrompent automatiquement après une certaine période d'inactivité afin d'économiser des ressources précieuses.
💡
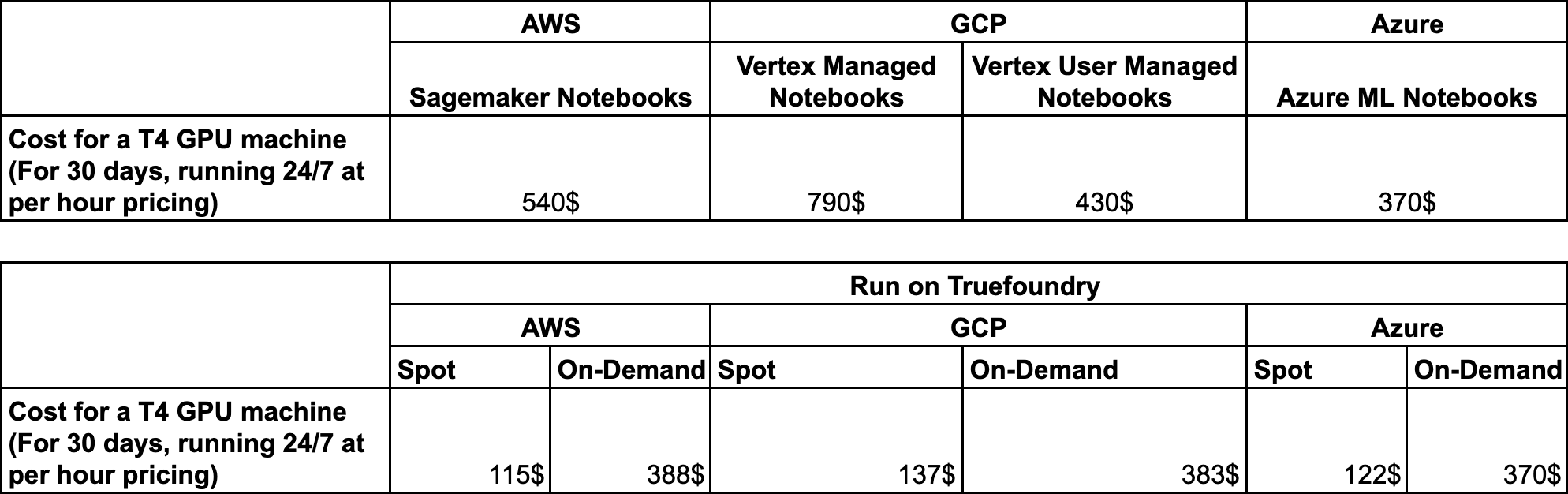
Analyse comparative des coûts Nous avons effectué une analyse comparative sur AWS, GCP et Azure afin de comparer les économies réalisées grâce à l'exécution de Notebooks et de VSCode à la demande ou à l'utilisation du cloud correspondant.
Analyse comparative des coûts pour les ordinateurs portables Jupiter
Économies de coûts liées au déploiement et à la mise au point de grands modèles de langage (LLM) :
Notre catalogue de modèles fournit un guichet unique pratique pour le déploiement et la mise au point de LLM pré-entraînés bien connus. Nous avons pris les mesures suivantes pour nous assurer que le déploiement et la mise au point de ces LLM soient aussi rentables que possible :
Configuration optimisée du service de modèles: Sur la base de l'analyse comparative de différents modèles de serveurs et d'allocations de ressources, nous vous proposons des configurations préremplies qui offrent la meilleure latence et le meilleur débit. Cela simplifie le processus de déploiement des LLM et vous aide à rendre vos déploiements économes en ressources et rentables.
Configuration de réglage fin efficace: Nous proposons des méthodes efficaces de réglage, telles que LoRa et Q-LoRa, qui contribuent à réduire l'utilisation des ressources et vous permettent d'atteindre vos objectifs à moindre coût.
Déploiements évolutifs avec support asynchrone : Déployez des LLM à grande échelle avec un support asynchrone pour utiliser vos quotas de GPU dans les trois clouds et obtenir de manière fiable les GPU dont vous avez besoin pour affiner et déployer. Cette fiabilité accrue vous permet d'utiliser des instances ponctuelles, ce qui vous permet d'économiser de l'argent.
Analyse comparative Nous avons effectué une analyse comparative des coûts afin de comparer les dépenses liées au déploiement de LLM sur AWS EKS par rapport à SageMaker. Vous pouvez en savoir plus sur le blog ci-dessous.
Plusieurs entreprises du Fortune 100 et entreprises de taille moyenne ont réalisé des économies importantes en utilisant notre plateforme. Certains ont même remplacé leurs plateformes internes SageMaker ou cloud par notre système, économisant ainsi 30 à 40 %.
Nous avons également évalué les performances de nombreux LLM open source courants dans cette série d'articles du point de vue de la latence, du coût et des demandes par seconde. Vous pouvez les consulter sur Blogs TrueFoundry
Vous pouvez également visionner cette vidéo pour obtenir une démonstration en direct de toutes les fonctionnalités que nous avons abordées dans ce blog :
True Foundry est un PaaS de déploiement de machine learning sur Kubernetes destiné à accélérer les flux de travail des développeurs tout en leur offrant une flexibilité totale dans les tests et le déploiement de modèles, tout en garantissant une sécurité et un contrôle complets à l'équipe Infra. Grâce à notre plateforme, nous permettons aux équipes de machine learning de déployer et surveiller des modèles en 15 minutes avec une fiabilité à 100 %, une évolutivité et la possibilité de revenir en arrière en quelques secondes, ce qui leur permet de réduire les coûts et de mettre les modèles en production plus rapidement, ce qui permet de réaliser une véritable valeur commerciale.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.
Conçu pour la vitesse : latence d'environ 10 ms, même en cas de charge



















































.png)

.webp)
.webp)
.webp)



.webp)
.webp)


