
.webp)
July 2, 2026
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: June 25, 2026

¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
CI/CD se ha convertido discretamente en una de las mayores líneas de costo de LLM en las organizaciones de ingeniería modernas. Un solo agente de revisión de seguridad que se activa en cada solicitud de extracción puede superar el gasto de toda la carga de trabajo de IA orientada al cliente del equipo de ingeniería por un factor de tres. La factura del proveedor te indica el total. No te dice qué tubería, qué repositorio o qué paso del agente lo causó. Sin esa atribución, la única respuesta posible es una prohibición general, y la pérdida de productividad supera el exceso original.
La pasarela de IA de TrueFoundry cierra esa brecha con tres primitivas: etiquetado de metadatos obligatorio en cada solicitud, presupuestos jerárquicos por centro de costos con umbrales suaves, restringidos y estrictos, y un pronóstico P95 continuo que revela los excesos antes de que lleguen a la factura. Las configuraciones de esta publicación son reales, se pueden copiar y pegar, y se basan en las oficiales de TrueFoundry Limitación de presupuesto y Limitación de tasa esquemas.
Las aplicaciones LLM de producción se ejecutan con tráfico de usuarios, el cual está limitado por el número de usuarios y la frecuencia de las solicitudes. Las tuberías de CI/CD se ejecutan con tráfico de máquinas: agentes automatizados, trabajos programados, regresiones periódicas, revisiones de cada PR. La forma del costo es fundamentalmente diferente. Un equipo de 50 ingenieros, cada uno abriendo 15 solicitudes de extracción por semana, genera 750 invocaciones de LLM impulsadas por PR por semana antes de que alguien toque una característica orientada al usuario. Cada invocación puede encadenar cuatro o cinco pasos de agente. Cada paso puede realizar múltiples llamadas a modelos con contextos de miles de tokens. El multiplicador de rendimiento entre la IA orientada al usuario y la IA de CI/CD es habitualmente de 10x a 100x.
La primera vez que la dirección de ingeniería se da cuenta es cuando finanzas reenvía una factura con un número que no coincide con el modelo mental de nadie. La historia se repite en cada organización que implementa CI/CD agéntico sin observabilidad: Octubre es una factura pequeña, noviembre es mediana, diciembre es el mes que provoca una reunión ejecutiva. El patrón es lo suficientemente consistente como para que los equipos de plataforma deban tratarlo como la expectativa operativa, no como una sorpresa.
La factura del proveedor —Anthropic, OpenAI, Bedrock o cualquier otro— detalla por modelo y tipo de token. No puede detallar por repositorio, por tubería o por paso de agente, porque el proveedor no sabe lo que significan esos conceptos dentro de tu organización de ingeniería. Esa información reside en los metadatos de tu solicitud, que el proveedor nunca ve. Desde la perspectiva del proveedor, los 847 millones de tokens de entrada de Sonnet del mes pasado parecen idénticos; desde tu perspectiva, el 80% de ellos provino de una tubería descontrolada que habrías limitado en la primera semana si lo hubieras sabido.
La falta de coincidencia entre lo que recibe finanzas y lo que ingeniería necesita depurar es la razón estructural por la que los proyectos de gobernanza de costos se estancan. Finanzas recibe una factura. Ingeniería recibe la misma factura sin desglose. Sin un libro mayor por carga de trabajo, la respuesta se reduce a "dejen de gastar en IA durante dos semanas mientras resolvemos esto", lo que anula la ganancia de productividad que la IA estaba generando.
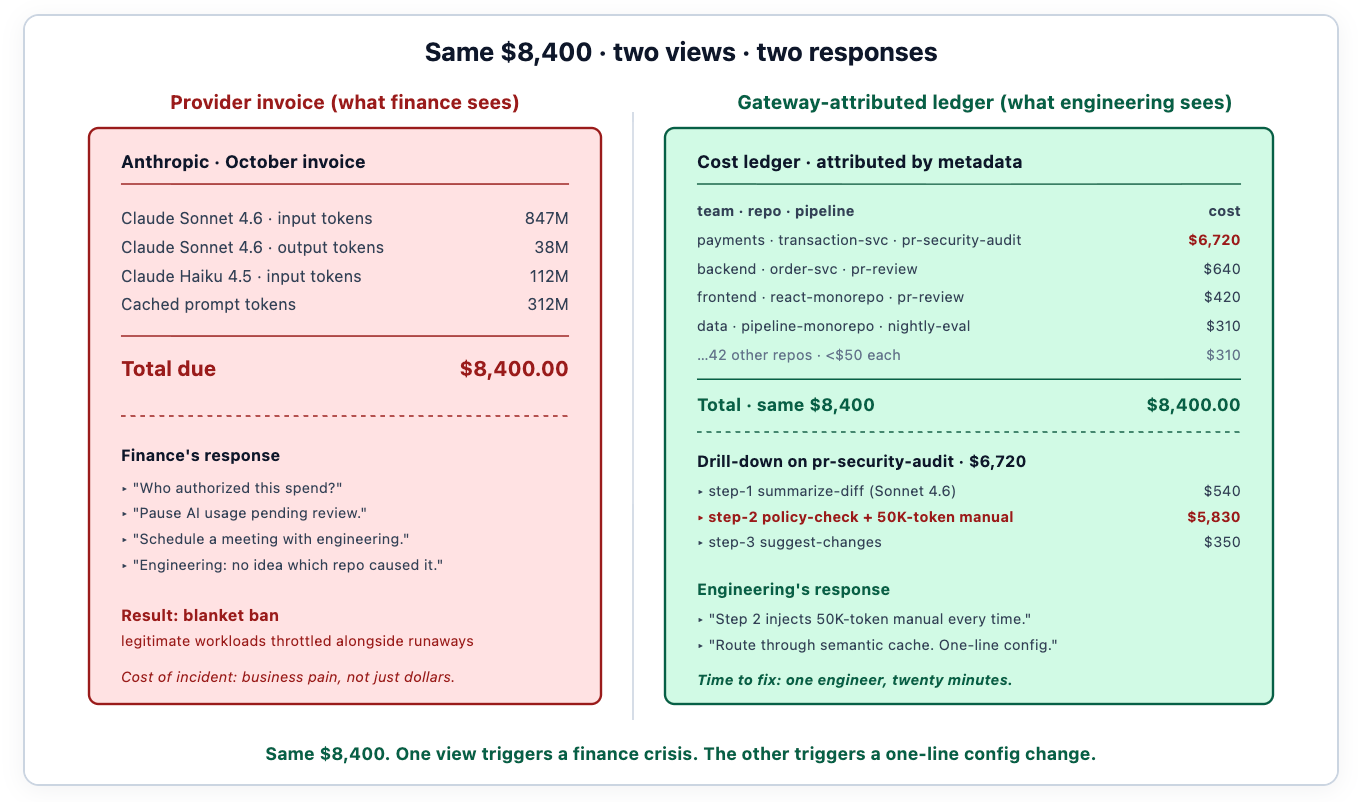
La misma cifra monetaria produce respuestas opuestas dependiendo de si el equipo tiene atribución. Sin ella, la respuesta es estructural: prohibir el gasto, escalar a la dirección, programar una reunión que será incómoda para todos. Con ella, la respuesta es un ingeniero leyendo el libro mayor de costos, identificando que el paso 2 de una tubería específica está inyectando un manual de políticas de 50,000 tokens en cada prompt, y escribiendo un cambio de configuración de una línea para enrutar el paso 2 a través de la caché semántica. Misma factura. Resultado diferente.
La base de la atribución de costos es el etiquetado obligatorio en la pasarela. Las tuberías de CI/CD tienen que inyectar identidad en cada solicitud, identificando el equipo, el repositorio, la tubería, el paso del agente y el centro de costos responsable. Según TrueFoundry's documentación de los encabezados de solicitud, esa identidad viaja en un único encabezado — x-tfy-metadata — cuyo valor es un objeto JSON serializado con claves y valores de tipo cadena, limitado a 128 caracteres por valor. Los campos dentro del JSON son convenciones elegidas por el equipo de la plataforma; no son encabezados HTTP por derecho propio.
Una solicitud correctamente formada desde una tubería de CI/CD se ve así en la red:
POST /api/llm/api/inference/openai/chat/completions HTTP/1.1
Host: gateway.truefoundry.ai
Authorization: Bearer {TFY_API_KEY}
Content-Type: application/json
x-tfy-metadata: {"team":"payments-platform","repo":"transaction-service","pipeline":"pr-security-audit","agent_step":"step-2-policy-check","cost_center":"eng-backend","run_id":"gh-run-882134"}La documentación de la pasarela enumera exactamente nueve encabezados de solicitud personalizados aceptados: Authorization, x-tfy-metadata, x-tfy-provider-name, x-tfy-strict-openai, x-tfy-retry-config, x-tfy-request-timeout, x-tfy-ttft-timeout-ms, x-tfy-logging-config, y x-tfy-mcp-headers. La identidad personalizada —equipo, repositorio, pipeline, centro de costos, ID de ejecución, o cualquier otra cosa que defina el equipo de la plataforma— reside estrictamente dentro del valor JSON de x-tfy-metadata, no como encabezados separados. Este es el único contrato que reconoce la pasarela. Los equipos que inventan encabezados adicionales x-tfy-* descubren que son ignorados silenciosamente: los metadatos nunca llegan a las capas de seguimiento de costos o de políticas, los paneles pierden la atribución y los registros de auditoría solo contienen el token de portador. Un solo encabezado, con JSON dentro, es la regla.
La visibilidad sin aplicación es un panel que nadie utiliza. La pasarela asigna presupuestos jerárquicos, aplicados matemáticamente, a cada centro de costos que produce el etiquetado. El equipo de la plataforma de pagos recibe, por ejemplo, 500 $ por semana para flujos de trabajo agénticos de CI/CD; ese presupuesto se aplica en la pasarela, en la ruta de la solicitud, con tres umbrales que activan diferentes respuestas.
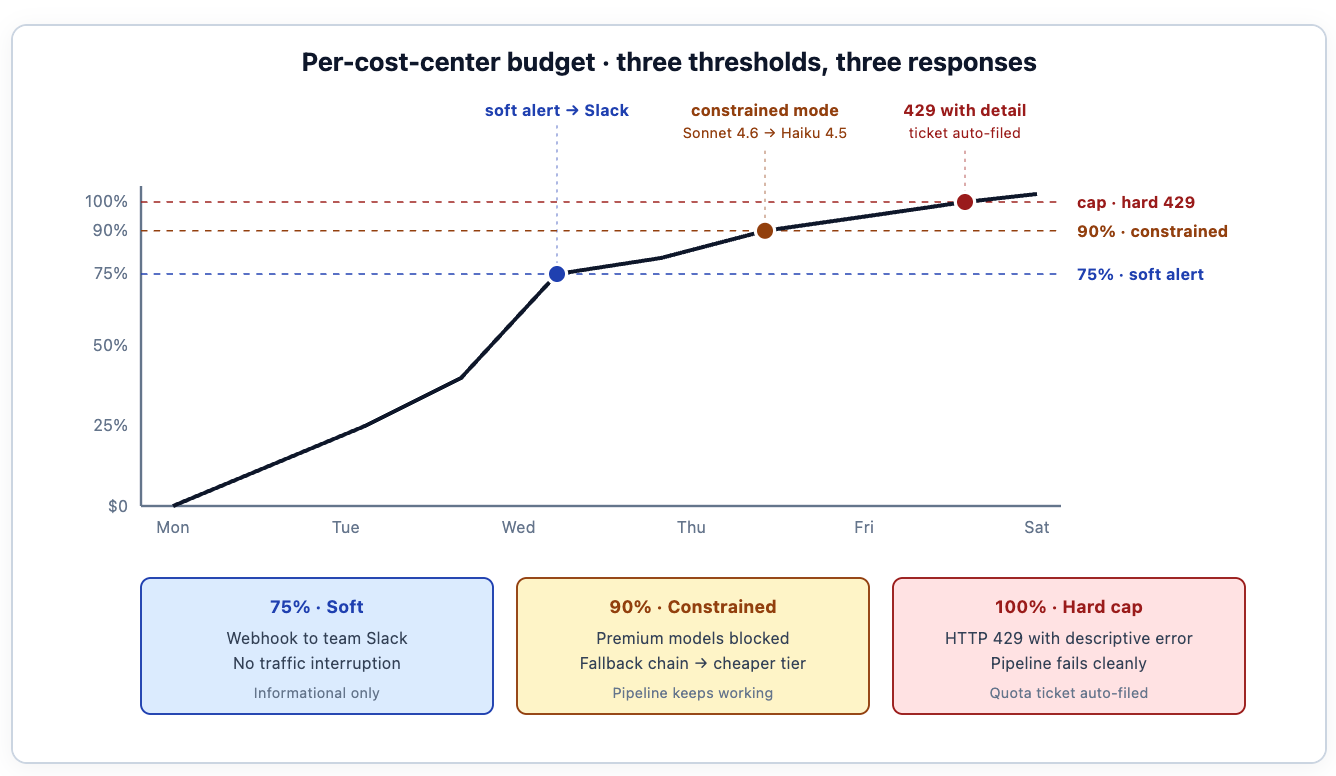
75% del límite — alerta suave. Un webhook publica en el canal de Slack del equipo: "Ya has consumido tres cuartas partes del presupuesto de IA de esta semana." Sin interrupción del tráfico. El propietario de la carga de trabajo ve la alerta durante el horario laboral normal y puede decidir si ajustar el comportamiento del agente, solicitar un aumento de cuota o no hacer nada porque el gasto es legítimo.
90% — modo restringido. Los modelos premium (Sonnet 4.6, Opus 4.7, GPT-4o) se bloquean; la pasarela enruta de forma transparente las solicitudes a alternativas más económicas (Haiku 4.5, GPT-4o-mini) mediante una configuración de respaldo de modelo virtual, de modo que los pipelines sigan funcionando mientras los costos se estabilizan. La cadena de respaldo se define en una configuración de enrutamiento separada: la configuración del presupuesto activa la restricción, la configuración de enrutamiento ejecuta el intercambio. La aplicación ve un encabezado que indica qué modelo atendió realmente la solicitud, y la calidad puede variar para cargas de trabajo específicas.
100% — límite estricto. La pasarela rechaza más solicitudes con HTTP 429. A continuación se muestra la estructura que los equipos de plataforma suelen diseñar para el cuerpo del error: la respuesta predeterminada de la pasarela es concisa, y el equipo la enriquece a través de su capa de envoltura con el contexto del centro de costos, el puntero al panel y el flujo de solicitud de cuota:
{
"error": "Budget Exceeded",
"detail": "Cost center 'eng-backend' has exhausted its weekly $500 AI budget.",
"context": {
"spent_to_date": "$501.23",
"cap": "$500.00",
"resets_at": "2026-05-19T00:00:00Z",
"top_consumer": "pipeline=pr-security-audit · 87% of spend"
},
"mitigation": "Review pipeline logs for runaway loops, or request a quota increase at /governance/quota."
}El cuerpo del error forma parte del diseño. Un pipeline que alcanza su presupuesto debe saber qué hacer a continuación —leer los registros, presentar una solicitud de cuota— sin que el desarrollador tenga que perseguir al equipo de la plataforma para obtener contexto. Los ejecutores de CI interpretan el 429 como una señal de retroceso estándar; la compilación falla limpiamente con un mensaje accionable en lugar de colapsar de formas confusas. El mismo patrón 429 se combina con las capas de límite de tasa y detección de fugas, de modo que una carga de trabajo que excede múltiples controles recibe una ruta de fallo coherente en lugar de una cascada de errores no relacionados.
Los datos etiquetados que fluyen a Grafana permiten al equipo de la plataforma construir paneles que responden a preguntas de propiedad en lugar de generar más ruido agregado. En lugar de mirar un pico y preguntar "¿quién hizo esto?", el panel ya te dice que a las 02:00 UTC el equipo de frontend desplegó un nuevo agente en react-monorepo que alucinó una dependencia faltante y entró en un bucle de resolución de 400 pasos. Los campos de metadatos aparecen como etiquetas de Prometheus; las consultas PromQL estándar producen desgloses por equipo, por repositorio, por pipeline; los paneles estándar de Grafana los visualizan.
Ese tipo de contexto operativo convierte el costo de un problema financiero en un problema de ingeniería. Una vez que el equipo ve que cambiar el paso inicial de resumen de código de Sonnet 4.6 a Haiku 4.5 reduce el costo de ese paso en un 80% sin afectar la calidad de la revisión de PR, realizan el cambio. La discusión sobre los límites presupuestarios no necesita tener lugar en un comité directivo; los datos son el argumento, y el cambio es la respuesta.
Un panel útil tiene tres vistas: un costo agregado por centro de costos a lo largo del tiempo, un desglose por pipeline y paso, y una vista de anomalías que detecta automáticamente los valores atípicos de costos. Las dos primeras son las vistas operativas; la tercera es la vista de alerta temprana que encuentra los desvíos antes de que lo haga el límite presupuestario. Los rastros de OpenTelemetry emitidos por la pasarela incluyen el modelo, los recuentos de tokens, los campos de metadatos y el monto en dólares por llamada; las herramientas existentes de Grafana se encargan del resto.
Los datos de etiquetado agregados también hacen que la previsión sea manejable. Las cargas de trabajo agénticas son intermitentes —los trabajos pesados y periódicos de CI dominan la factura—, razón por la cual los promedios móviles simples subestiman sistemáticamente el gasto. Un equipo que promedió $40/día durante tres semanas y $400 en una sola ejecución de tren de lanzamiento de un miércoles tiene un promedio móvil de $51/día; su gasto real a fin de mes, si lanzan dos trenes de lanzamiento más, supera los $2,000.
La pasarela ejecuta una previsión móvil P95 de 7 días por repositorio y por centro de costos. P95 captura el riesgo de picos que un promedio suaviza, proyectando el gasto de fin de mes con suficiente antelación para ajustar presupuestos, aumentar cuotas o eliminar un pipeline problemático antes de que finanzas vea la sorpresa. "Sorpresa" es la palabra clave: esta es una previsión diseñada para no producirlas. Cuando la previsión indica que un equipo está en camino de exceder su presupuesto mensual en un 30%, el equipo tiene dos o tres semanas de margen para actuar antes de que se active el límite estricto.
La previsión aparece en el mismo panel de Grafana que el gasto en tiempo real, con la proyección dibujada junto a la curva histórica. Los equipos de plataforma que revisan la previsión semanalmente detectan el patrón que produce la crisis presupuestaria del próximo trimestre; los equipos que no revisan la previsión se enteran del problema de la misma manera que siempre lo hicieron: por finanzas.
Lo que sigue es un ejemplo ilustrativo compuesto extraído de patrones que este equipo ha observado en implementaciones reales de clientes; los números están estilizados para aclarar la mecánica, pero tanto el modo de fallo como la solución son comunes.
Una organización de 50 ingenieros construyó un agente de revisión de código Claude de tres pasos que se ejecutaba en cada solicitud de extracción: (1) resumir el diff, (2) revisar el diff contra las políticas de seguridad a través de un servidor de documentación MCP, (3) sugerir cambios de código. Arquitectura sensata, flujo de trabajo útil, sin señales de alarma obvias. El agente entró en producción a principios de septiembre.
Con aproximadamente 15 PRs por ingeniero por semana, teniendo en cuenta los reintentos y el costo de la ventana de contexto de inyectar archivos completos en las indicaciones, el agente promedió alrededor de 400,000 tokens de entrada por PR. Factura del primer mes para la automatización de CI/CD: $8,400. La factura llegó el 5 de octubre. El mensaje de Slack de finanzas llegó el 6 de octubre. La conversación que produjo esta publicación llegó el 7 de octubre.
La atribución reveló la causa real a los pocos minutos de que el equipo iniciara sesión en el panel de costos. El paso 2 estaba inyectando un manual de seguridad de 50,000 tokens en cada indicación, en cada PR, independientemente de si el diff realmente tocaba código relevante para la política. El modelo leía todo el manual para evaluar si aplicarlo; la respuesta era "no, esto es un cambio de CSS" el 80% de las veces; el costo se pagaba cada vez. Enrutando el paso 2 a través de la pasarela de semantic cache — indexado por la extensión de archivo y la firma de contenido del diff — redujo la sobrecarga de tokens en un 92%. Misma cobertura. Mismas sugerencias. Factura mensual por debajo de los $800.
Sin atribución, la respuesta habría sido una prohibición general de Sonnet para los flujos de trabajo de CI. Ingeniería habría absorbido el golpe a la productividad; finanzas habría absorbido la victoria política; nadie habría sabido cuál era el problema real. Con atribución, la respuesta fue un cambio de configuración de una sola línea. Esa es la diferencia que marcan los datos.
Dos configuraciones de políticas de TrueFoundry soportan el peso de todo el patrón: una configuración de presupuesto que aplica límites de dólares con modos de auditoría y alertas, y una configuración de límite de tasa que aplica cuotas de tokens y solicitudes. Ambos son esquemas reales; cópielos directamente en la pasarela de IA Policies pestaña. La referencia del esquema se encuentra en la documentación oficial de Limitación de presupuesto y Limitación de tasa. Dos puntos semánticos a interiorizar antes de implementarlos:
Primero, sobre el orden de las reglas y el seguimiento por capas: según la documentación de presupuesto de TrueFoundry, cuando una solicitud coincide con varias reglas, el costo se registra en cada una de las reglas coincidentes, pero solo la primera regla coincidente controla la decisión de permitir/bloquear. El orden de las reglas en el YAML determina la prioridad; no existe un campo de prioridad separado. En la configuración siguiente, una solicitud de plataforma de pagos coincide tanto con la regla específica payments-platform-weekly (primera coincidencia, controla la decisión de bloqueo) como con la regla general per-user-daily-default (también registra el costo, útil para la visibilidad por desarrollador). Esto es intencional: el panel muestra tanto el uso a nivel de centro de costos como a nivel de usuario en la misma solicitud.
Segundo, sobre la nomenclatura de cuentas de proveedor: los identificadores de modelo como anthropic-main/claude-opus-4-7 siguen el formato <provider-account-name>/<model-id>, where the provider account name is whatever the workspace administrator named the Anthropic account in AI Gateway → Models. The model-id portion is fixed by Anthropic. Verify the provider account name in your specific TrueFoundry instance before copy-pasting.
Budget config — dollar enforcement per cost center, with audit mode for safe rollout:
name: cicd-budget-config
type: gateway-budget-config
rules:
# Priority 1 (first in list = first match): payments-platform — higher cap
- id: 'payments-platform-weekly'
when:
metadata:
cost_center: 'eng-backend-payments'
limit_to: 800
unit: cost_per_week
audit_mode: false # enforce: block on exceed
alerts:
thresholds: [75, 90, 100]
notification_target:
- type: slack-bot
notification_channel: 'eng-alerts-channel'
channels: ['#eng-backend-ai']
# Priority 2: data team — lighter cap, longer period
- id: 'data-team-monthly'
when:
metadata:
cost_center: 'eng-data'
limit_to: 2000
unit: cost_per_month
audit_mode: false
alerts:
thresholds: [75, 90, 100]
notification_target:
- type: email
notification_channel: 'data-alerts'
to_emails: ['data-platform-lead@example.com']
# Priority 3: intern sandbox — hard cap, no exceptions
- id: 'intern-sandbox-weekly'
when:
metadata:
cost_center: 'intern-sandbox'
limit_to: 50
unit: cost_per_week
audit_mode: false
alerts:
thresholds: [100]
notification_target:
- type: slack-bot
notification_channel: 'platform-alerts'
channels: ['#platform-budgets']
# Default per-user safety net — $20/day per individual developer.
# Tracks against every request (layered), controls block only for requests
# that don't match a higher-priority rule above.
- id: 'per-user-daily-default'
when: {}
limit_to: 20
unit: cost_per_day
budget_applies_per: ['user']
audit_mode: true # audit-only during initial rollout
alerts:
thresholds: [90, 100]
notification_target:
- type: slack-bot
notification_channel: 'platform-alerts'
channels: ['#platform-budgets']Rate-limit config — request and token quotas, the second line of defense:
name: cicd-ratelimiting-config
type: gateway-rate-limiting-config
rules:
# Per-pipeline token ceiling: prevents runaway agents.
# metadata.pipeline accesses the 'pipeline' field inside x-tfy-metadata JSON.
- id: 'pipeline-hourly-token-cap'
when: {}
limit_to: 500000
unit: tokens_per_hour
rate_limit_applies_per: ['metadata.pipeline']
# Per-user request floor: stops developer mistakes from going viral
- id: 'per-user-daily-requests'
when: {}
limit_to: 5000
unit: requests_per_day
rate_limit_applies_per: ['user']
# Premium-model brake: caps Opus consumption per cost center.
# Replace 'anthropic-main' below with your workspace's Anthropic
# provider-account name (see AI Gateway → Models in the dashboard).
- id: 'opus-per-cost-center-daily'
when:
models: ['anthropic-main/claude-opus-4-7']
limit_to: 200000
unit: tokens_per_day
rate_limit_applies_per: ['metadata.cost_center']Both configurations are version-controlled, reviewed in pull requests, and applied through the same GitOps flow the platform team uses for the rest of the gateway. The schemas above match the official docs exactly — every field, every value, every rate_limit_applies_per entry is documented and supported. Workload teams propose changes to their own cost-center entries through pull requests; the platform team approves; the gateway picks up the change on its next reconciliation loop.
The audit_mode: true setting on the default per-user rule is the safety primitive worth highlighting. During rollout, audit mode lets the rule track real spend and fire alerts without blocking any traffic. After a week or two of observation, the team flips audit_mode to false to enforce. This is the lowest-risk path to a production-grade budget enforcement system: observe first, enforce second, and never enforce a number you haven't yet seen real traffic produce.
The single-organization case where every cost center belongs to one company is the easy one. Many production AI deployments are multi-tenant: a B2B SaaS product offers AI features to its own customers, and the AI bill needs to be allocated per tenant before the company knows which customers are profitable and which are subsidized. The cost-attribution layer is what makes this question answerable.
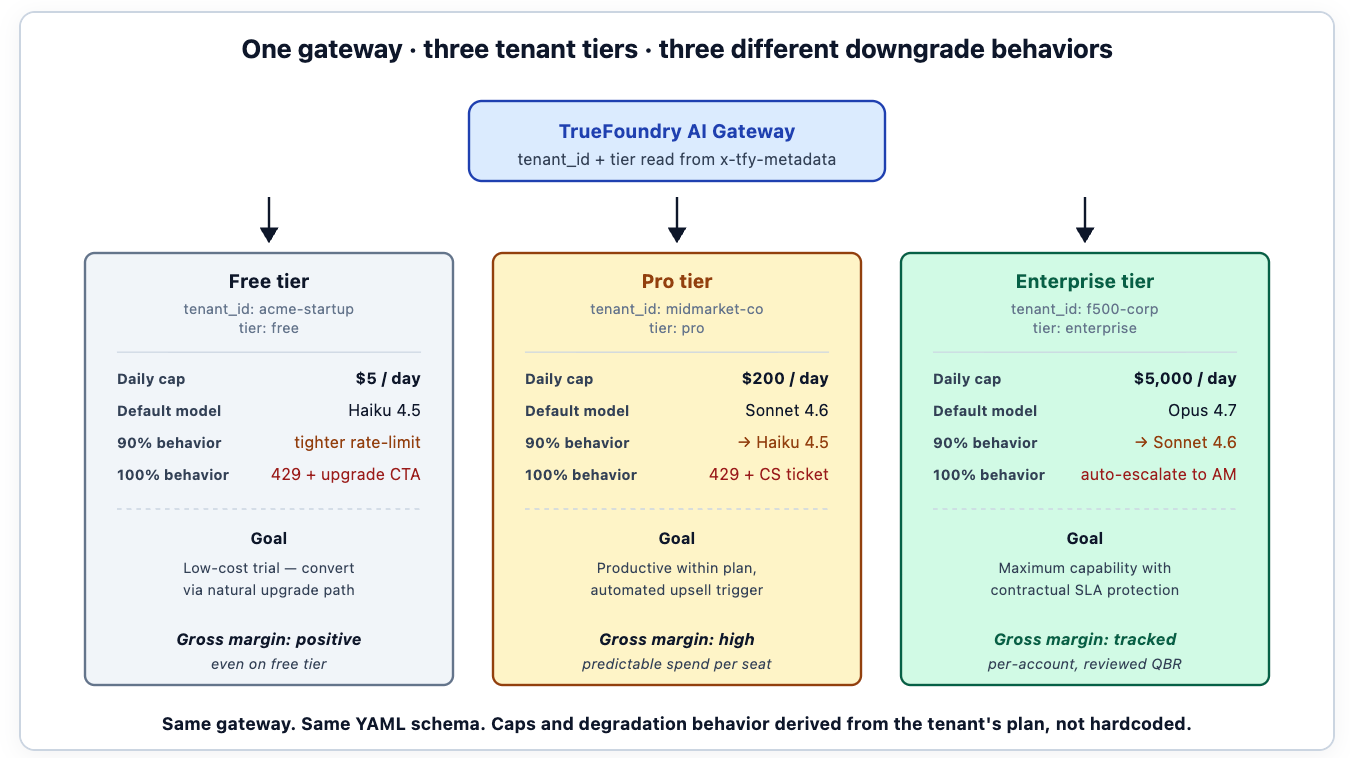
The pattern that works adds tenant_id as another field on the metadata envelope. The bucket key for budgeting becomes the combination of tenant_id and workload; the dashboard supports a per-tenant view alongside the per-cost-center view; the FinOps report joins gateway data to the company's billing system to produce gross margin per tenant. A tenant whose AI consumption exceeds their plan tier shows up in the dashboard before customer success has to chase the conversation.
Tier-aware budget caps are the second pattern. The free-tier tenant gets a tighter cap than the enterprise-tier tenant; the caps are derived from the tenant's plan rather than hardcoded. When a tenant upgrades, the cap updates without code changes — the plan is metadata on the tenant identity, the cap is a function of the plan. Teams that hardcode caps end up rewriting them every time pricing changes; teams that derive them from tenant data inherit the right behavior automatically.
The third pattern: degraded-but-working modes per tier. The enterprise-tier tenant's constrained mode might keep them on a frontier model with stricter rate limiting; the free-tier tenant's constrained mode might route them to a self-hosted small model. Same gateway, different downgrade chains, expressed as configuration. The B2B SaaS company's pricing structure shows up directly in the gateway configuration — which is the right place for it.
Four configuration mistakes appear regularly in teams' first attempts at cost attribution. Each produces a different failure mode worth knowing.
Optional tagging. The team configures the gateway to log untagged requests but pass them through, intending to enforce later. "Later" doesn't arrive, and the dashboard accumulates an "unknown" bucket that grows month over month. By the time enforcement is enabled, half the traffic is in the unknown bucket and breaking it is politically expensive. The fix is to enforce rejection from week 2, when the visible traffic is still small.
Inventing extra headers. Teams sometimes try to spread identity across multiple headers — separate headers for team, repo, cost center, and so on. The gateway recognizes exactly nine custom headers, listed earlier in this post; the rest are silently ignored. All custom identity belongs inside the JSON value of x-tfy-metadata. One header. JSON inside. The contract is documented and the gateway enforces it.
Cost centers that span teams. A cost center like shared-infra looks like a clean abstraction but produces no engineering ownership when it overruns — there is no team to call. Cost centers should map to a team's responsibility surface; shared work belongs in a "platform" cost center owned by the platform team, not in a vague shared bucket.
Hard caps without descriptive errors. A 429 with body {"error": "rate_limited"} tells the developer nothing actionable. A 429 with the cost center, the cap, the top consumer, and a link to the quota request flow tells them exactly what to do. The error-body schema is one of the most-tuned parts of the configuration in any mature deployment.
Cost attribution is one of the safer rollouts in the AI platform space because the failure mode of "miscalibrated budget" is bounded (some pipelines hit constrained mode unexpectedly) and the failure mode of "no attribution" is catastrophic (the runaway bill). The right sequence is observe-first, enforce-second.

Week 1 — Tagging in audit mode. Update the CI templates to inject x-tfy-metadata on every request. Configure the gateway to log untagged requests as warnings but pass them through. The dashboard at the end of the week tells the team the natural shape of their spend: which pipelines dominate, which cost centers are the heavy users, which models the workloads actually prefer. This is the data that informs the budget calibration.
Week 2 — Reject untagged requests. Flip the gateway to return 400 for untagged requests. The CI templates updated in week 1 are the only legitimate clients; any 400 response indicates either an un-updated template or an out-of-band caller that needs to be addressed. By the end of week 2 every request in production is tagged.
Weeks 3-4 — Configure budgets in audit mode. Deploy the budget config with audit_mode: true across all rules. Set the soft thresholds (75%) against the observed P95 of legitimate spend plus margin. Alerts fire to team Slack channels; no enforcement actions trigger yet. The team observes which thresholds are reasonable and which need tuning. Some workloads will appear to be on a runaway trajectory; one or two will actually be, and the team can intervene before enforcement kicks in.
Week 5 — Enable enforcement. Flip audit_mode to false on the budget rules. Turn on the 90% downgrade chain (paired virtual-model fallback config) and the 100% hard cap. The downgrade chain is the more contentious change with workload owners — some teams strongly prefer "fail fast" over "degraded but working" for their pipelines. Make the chain per-cost-center configurable from the start, so each team can choose its preferred behavior.
Week 6+ — Forecasting and review cadence. Enable the 7-day P95 forecast. Set up a weekly platform-team review of the forecast against the budgets. New cost centers default into reasonable starting caps based on observed early usage; quota changes flow through pull requests against the configuration. The system runs as infrastructure, not as a project.
The cost-attribution layer needs a clear ownership boundary because the data it produces lands in multiple stakeholders' worlds at once. The right split is: platform team owns the layer, workload teams own their budgets, finance owns the strategic view, engineering leadership owns the policy.
The platform team operates the gateway, the tagging discipline, the budget engine, and the forecast. They review and approve quota requests, they tune the downgrade chains based on quality feedback from workload owners, and they triage the alerts that fire during off-hours. Their job is to make the system run; they do not decide how much each workload should cost.
The workload teams own their own cost-center entry in the configuration. They propose budget changes through pull requests; they tune their pipelines when they hit soft alerts; they choose between degraded-but-working and fail-fast behavior for their hard-cap response. The platform team approves; the workload team executes.
Finance and engineering leadership consume the aggregate views. Monthly close calls cite specific cost centers and specific pipelines rather than aggregate numbers. Quarterly planning uses the forecast to project AI infrastructure spend; budget cycles become predictable instead of reactive. This is the property that makes AI spend a budgeted line item rather than a recurring surprise.
Mandatory tagging is not a substitute for prompt engineering. A workload that injects a 50,000-token manual into every prompt will see the tag tell them exactly which workload is expensive; it will not tell them how to fix it. The fix — a smaller manual, a cache, a more focused retrieval, a model better-suited to the task — is the engineering work that follows the attribution. The dashboard is the diagnosis; the fix is the treatment.
Hierarchical budgets are not a guarantee of cost control. A team that gets its budget raised every time it hits the cap eventually arrives at "the cap doesn't exist." The discipline is in the budget-review cadence, not in the technical mechanism. Platform teams that approve every quota request lose the leverage the budget was meant to provide.
And cost attribution at the gateway is not the right answer for every organization. Teams whose total AI spend is small enough that the engineering investment exceeds the savings should pick a different problem to solve first; teams whose existing FinOps tooling already produces per-workload attribution from cloud-provider data don't need a parallel system at the gateway. The pattern fits organizations whose AI spend has grown faster than their visibility into it — typically anywhere above $5K/month of provider spend, where the cost of one runaway incident exceeds the cost of building the layer. Below that threshold, the math of even an off-the-shelf gateway like TrueFoundry's doesn't always pencil out; the team is better off keeping the spend in one or two well-monitored applications and applying the layer when growth makes it warranted.
Both, concurrently. Dollars align with finance and operational planning. Tokens are the engineering metric that lets the team debug prompt efficiency — a workload whose token consumption doubles while its dollar cost stays flat (because the model got cheaper) is worth investigating from an engineering standpoint even if finance doesn't notice. The gateway tracks both; finance owns the dollar dashboards, engineering owns the token dashboards, and the gateway is the source of truth for both.
The pipeline receives a 429 with the descriptive error body shown above and a link to the budget dashboard. CI runners interpret 429 as a standard backoff signal; the build fails cleanly with an actionable message rather than crashing in confusing ways. Quota increases are filed as standard tickets against the platform team through the link in the error body. The pipeline's last successful step is preserved; resuming after the quota increase doesn't redo work already paid for.
In practice, no. TrueFoundry ships SDK wrappers that inject the metadata envelope automatically from environment variables CI runners already set, so individual developers never edit headers. The one-time cost is updating the team's pipeline templates; the recurring cost is zero. The recurring benefit is every dashboard that follows.
Use a stable workflow_id field inside the x-tfy-metadata JSON — the same value for every request belonging to the same logical workflow. The gateway groups requests by workflow_id for per-workflow budget enforcement. A workflow with a $5 cap can span hundreds of requests; the gateway tracks running total against the workflow's identifier rather than the individual request.
It matches the provider's invoice within roughly 1% for input and output token costs; the small variance comes from rounding and from provider-side surcharges (volume discounts, region differentials) that the gateway cannot see at request time. For most planning purposes the gateway's numbers are tight enough; for accounting-grade reconciliation the provider's invoice remains the source of truth, with the gateway providing the per-workload breakdown. TrueFoundry's cost-tracking documentation describes both public-pricing (provider-published rates) and private-pricing (custom contracts) modes.
Budgets are scoped per cost center; one team's runaway only consumes their own budget. The hard cap stops the runaway before it can affect other teams. The model-level cap rule in the rate-limit config (the opus-per-cost-center-daily example) is a backstop for the case where multiple teams misbehave simultaneously or where attribution itself is wrong; it operates above the per-cost-center layer.
Cross-team work is uncommon but real. The cleanest pattern is to define a "shared-initiative" cost center owned by the platform team, with explicit charge-back rules documented in the gateway README. Tagging stays single-valued — the request belongs to exactly one cost center at runtime — but the platform team can journal the spend out to participating teams at the end of each billing period via the exported cost data described in the cost-tracking documentation.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada
© 2026 Todos los derechos reservados.






.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




