

October 5, 2023
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: June 12, 2026

¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
A medida que la adopción del aprendizaje automático continúa acelerándose en todos los sectores, la necesidad de canalizaciones de aprendizaje automático sólidas, escalables y automatizadas nunca ha sido mayor. En 2026, las plataformas MLOps se han convertido en la base de la operacionalización de la IA, desde la capacitación y el despliegue de modelos hasta la supervisión y la gobernanza.
Estas plataformas optimizan el ciclo de vida de principio a fin, lo que ayuda a los equipos a gestionar la complejidad, garantizar la reproducibilidad y acelerar la generación de valor. Tanto si se trata de una empresa emergente que está escalando su primer modelo como de una empresa que implementa cientos, elegir la plataforma mLOps adecuada es fundamental.
En esta guía, exploramos qué es MLOps, por qué es importante y las mejores herramientas de MLOps que darán forma al panorama en 2026.

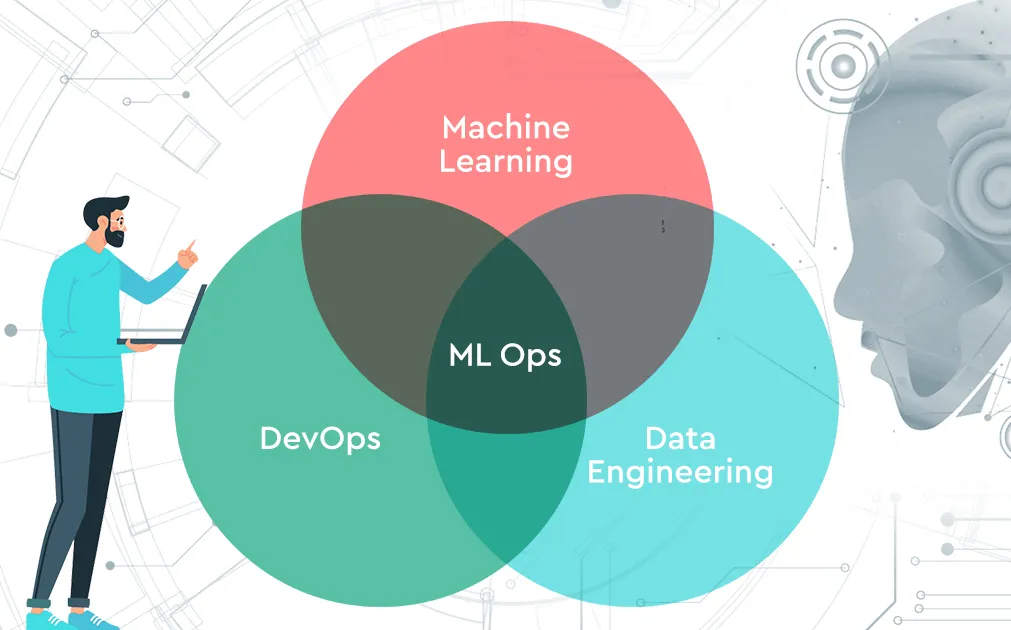
Las MLOps (operaciones de aprendizaje automático) son una disciplina que fusiona los principios de aprendizaje automático, DevOps e ingeniería de datos para permitir el desarrollo, la implementación, la supervisión y el mantenimiento de sistemas de aprendizaje automático confiables a escala. Garantiza que los modelos creados en entornos experimentales puedan pasar de manera segura y eficiente a la producción, donde deben funcionar de manera constante, adaptarse a los cambios y seguir siendo responsables.
Los flujos de trabajo de DevOps tradicionales se centran en el control de versiones, las canalizaciones de CI/CD, las pruebas automatizadas y la confiabilidad del sistema. mLOps los hereda, pero los amplía para abordar los desafíos únicos del aprendizaje automático: administrar datos en constante evolución, volver a capacitar los modelos para que tengan en cuenta las desviaciones, evaluar los resultados no deterministas y mantener la reproducibilidad en todas las iteraciones de los modelos.
A medida que el aprendizaje automático pasa de la experimentación a la implementación a escala empresarial. Las herramientas de MLOps se han vuelto esenciales para garantizar la coherencia, la confiabilidad y la velocidad a lo largo del ciclo de vida del modelo. Sin una solución mLOps centralizada, los equipos suelen terminar con herramientas fragmentadas, procesos manuales y flujos de trabajo inconsistentes que ralentizan la innovación e introducen riesgos operativos.
Plataformas MLOps resuelva estos desafíos al proporcionar una interfaz unificada para administrar las canalizaciones de datos, los flujos de trabajo de capacitación, el seguimiento de modelos, la implementación y la supervisión, todo en un solo lugar. Esta consolidación permite una colaboración más estrecha entre los científicos de datos, los ingenieros de aprendizaje automático y los equipos de DevOps, lo que reduce la fricción de transferencia y mejora la reproducibilidad en todos los entornos.
Al seleccionar las herramientas de MLOps en 2026, es importante evaluar no solo las características, sino también qué tan bien la plataforma admite su flujo de trabajo de aprendizaje automático, se adapta a su infraestructura y se alinea con los objetivos operativos de su equipo. A continuación, se muestran algunos criterios esenciales que debes tener en cuenta:
Una plataforma mLOps ideal debe cubrir todo el ciclo de vida del aprendizaje automático, desde el control de versiones de datos y la capacitación hasta la implementación y la supervisión. Las cadenas de herramientas fragmentadas pueden generar ineficiencias e inconsistencias entre los equipos. Las plataformas que unifican estas etapas en un único flujo de trabajo ayudan a mejorar la reproducibilidad, reducir las transferencias y acelerar la iteración.
A medida que las cargas de trabajo de ML escalan, también debe hacerlo la plataforma. Una buena solución de MLOps debería ser compatible con todo, desde la experimentación local hasta el entrenamiento distribuido en varias GPU o nodos. También debe ofrecer flexibilidad en la implementación y ser compatible con entornos nativos de la nube, locales e híbridos sin tener que limitarse a un paquete específico.
La usabilidad a menudo se pasa por alto, pero es fundamental. Una plataforma sólida ofrece interfaces limpias, tanto de interfaz de usuario como de CLI, junto con SDK completos que se integran con marcos populares como PyTorch, TensorFlow y Hugging Face. Una plataforma que sea intuitiva tanto para los científicos de datos como para los ingenieros de aprendizaje automático promueve una mejor colaboración y una incorporación más rápida.
Los MLOps no existen de forma aislada. Tu plataforma debe integrarse perfectamente con los sistemas de almacenamiento existentes (como S3 o GCS), las herramientas de CI/CD (como GitHub Actions o Jenkins), las plataformas de observabilidad (como Prometheus o Grafana) y los registros de modelos. Una integración sólida garantiza un flujo fluido de datos y modelos en toda tu canalización.
Para las organizaciones que trabajan en entornos regulados, las funciones de gobierno son imprescindibles. La plataforma debe admitir el control de acceso basado en roles (RBAC), los registros de auditoría y el seguimiento del linaje. El cumplimiento de estándares como el SOC 2, la HIPAA o el RGPD ayuda a garantizar la privacidad de los datos, la confianza y la viabilidad a largo plazo en los entornos empresariales.
El panorama de los MLOps en 2026 está repleto de plataformas que se adaptan a diferentes necesidades, desde el seguimiento ligero de experimentos hasta la implementación y el monitoreo de modelos de nivel empresarial. A continuación, se muestran las 25 mejores herramientas de mLOps que ayudan a los equipos a optimizar sus flujos de trabajo de aprendizaje automático, optimizar la infraestructura y poner en funcionamiento los modelos a escala. Cada plataforma tiene sus puntos fuertes en función de la tecnología, la madurez del equipo y los objetivos empresariales.
TrueFoundry es un plataforma moderna de MLOps y LLMops diseñado para equipos que desean implementar, escalar y monitorear modelos de aprendizaje automático e IA generativa en producción. Elimina la complejidad de la infraestructura y, al mismo tiempo, ofrece un control total, lo que permite a los equipos pasar de la experimentación a la implementación en cuestión de minutos.
A diferencia de los sistemas antiguos, TrueFoundry está optimizado para el rendimiento, la productividad de los desarrolladores y los flujos de trabajo centrados en GenAI, que incluyen soporte para agentes, canalizaciones de RAG y rastreo avanzado. Su seguridad de nivel empresarial y su diseño modular la convierten en una de las mejores herramientas de MLOps, adecuada para organizaciones de todos los tamaños.
Características principales:
Ideal para:
Equipos impulsados por la IA que crean productos respaldados por la LLM, especialmente cuando el rendimiento, la seguridad y la observabilidad son fundamentales. Excelente opción para equipos o empresas que cambian rápidamente y que necesitan una implementación escalable de GenAI. Aquí están algunas de las mejores herramientas de pasarela de LLM.
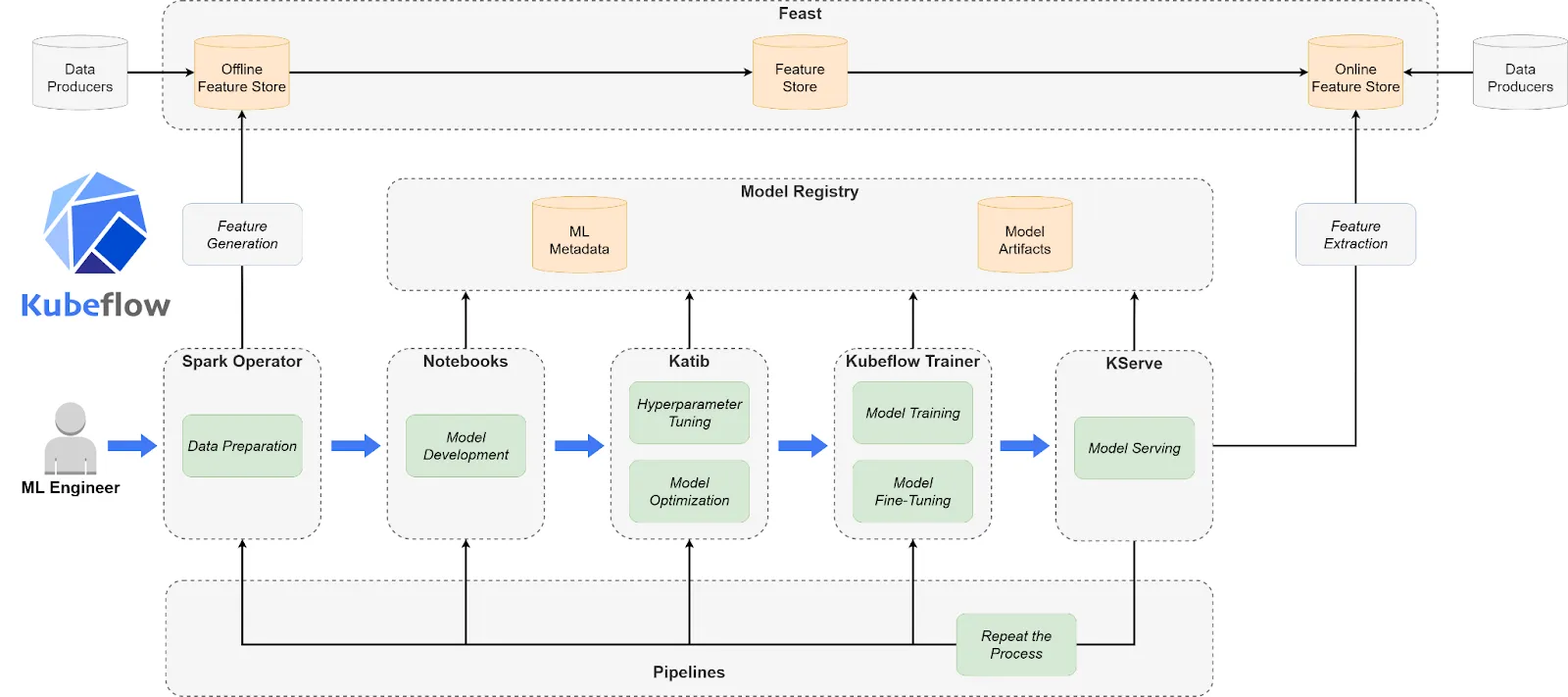
Kubeflow es una herramienta nativa de Kubernetes, de código abierto y una de las mejores herramientas de MLOps para crear y administrar flujos de trabajo de aprendizaje automático portátiles y componibles. Proporciona la flexibilidad necesaria para organizar el entrenamiento, el ajuste y la prestación utilizando abstracciones conocidas de Kubernetes. Aunque es potente, Kubeflow requiere un conocimiento profundo de la infraestructura y no es ideal para equipos sin soporte dedicado de DevOps. Destaca cuando se necesitan canalizaciones de aprendizaje automático personalizadas, escalables y seguras.
Características principales:
Ideal para:
Equipos con una sólida experiencia en Kubernetes que buscan personalizar y controlar por completo sus flujos de trabajo de mLOps, especialmente en entornos de nube regulados o híbridos.
MLFlow es una plataforma mLOps ligera y de código abierto creada por Databricks, que se centra en gestionar la experimentación de ML y el control de versiones de modelos. Sus componentes modulares permiten a los equipos integrar el seguimiento, el registro y la implementación en sus flujos de trabajo existentes.
Esta herramienta mLOps es ideal para equipos u organizaciones más pequeños que desean flexibilidad sin la sobrecarga de una infraestructura a gran escala o Kubernetes.
Características principales:
Ideal para:
Los equipos de aprendizaje automático buscan herramientas ligeras y personalizables para rastrear experimentos, compartir modelos y administrar versiones sin depender de una plataforma a gran escala.
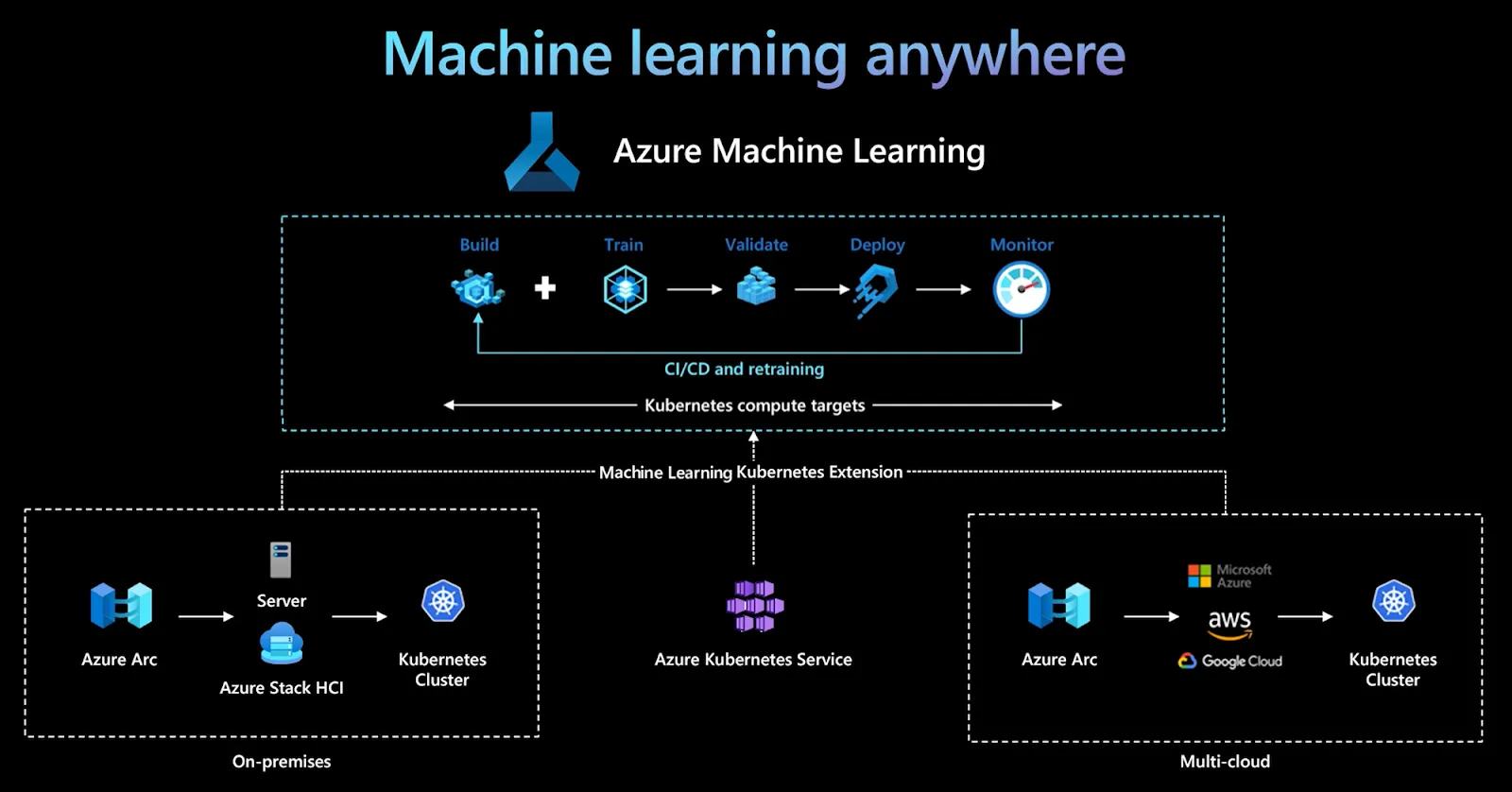
Azure Machine Learning es la plataforma mLOps totalmente administrada de Microsoft, diseñada para crear, entrenar, implementar y monitorear modelos de aprendizaje automático a escala empresarial. Se integra perfectamente con el ecosistema de Azure y ofrece un potente conjunto de herramientas para la administración de modelos, el AutoML y la IA responsable. Azure ML es ideal para las organizaciones que ya han invertido en la nube de Microsoft y buscan seguridad, escalabilidad y cumplimiento.
Características principales:
Ideal para:
Empresas que operan en Microsoft Azure necesitan una plataforma mLOps altamente segura, escalable y totalmente integrada con el cumplimiento empresarial incorporado.
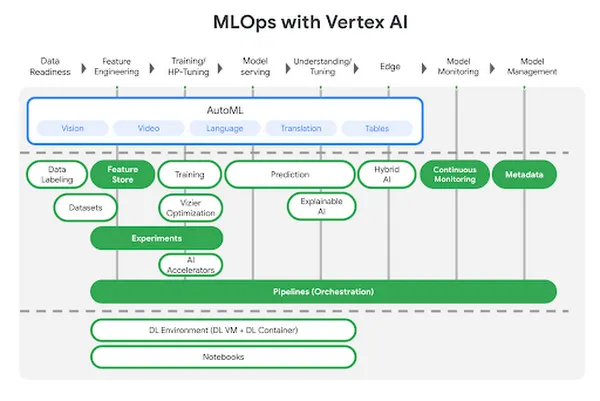
Vertex AI es la plataforma unificada de Google Cloud para el desarrollo de aprendizaje automático, que combina AutoML y el entrenamiento de modelos personalizados en una sola interfaz. Abstrae la infraestructura y, al mismo tiempo, ofrece servicios avanzados, como almacenes de funciones, canalizaciones y seguimiento de experimentos.
Diseñada para la escalabilidad y la integración con el ecosistema de Google, esta herramienta MLOps está optimizada para la implementación de aprendizaje automático a nivel de producción y los flujos de trabajo basados en datos.
Características principales:
Ideal para:
Equipos que crean y escalan el aprendizaje automático en Google Cloud y desean una plataforma mLOps gestionada y escalable con una integración total de datos e implementación.
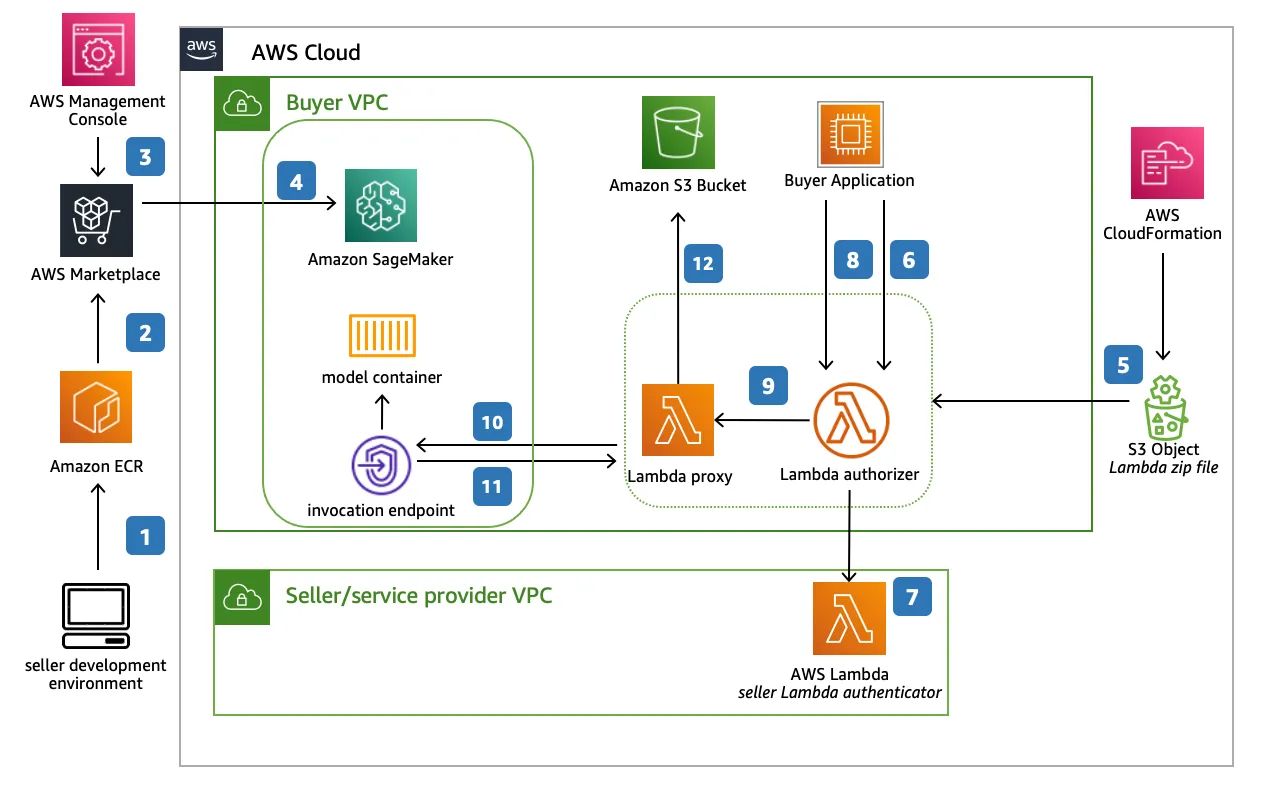
Amazon SageMaker es la plataforma MLOps insignia de AWS que ofrece de todo, desde el preprocesamiento de datos hasta la implementación de modelos en tiempo real. Conocida por su amplia funcionalidad, SageMaker admite el desarrollo de modelos personalizados, AutoML, el alojamiento de modelos y las herramientas de supervisión avanzadas. Está estrechamente integrado con el ecosistema de AWS, lo que lo convierte en la opción ideal para las empresas nativas de la nube.
Características principales:
Ideal para:
Organizaciones que ya utilizan AWS para la infraestructura y necesitan una plataforma MLOps sólida y escalable con una integración profunda y soporte durante todo el ciclo de vida.
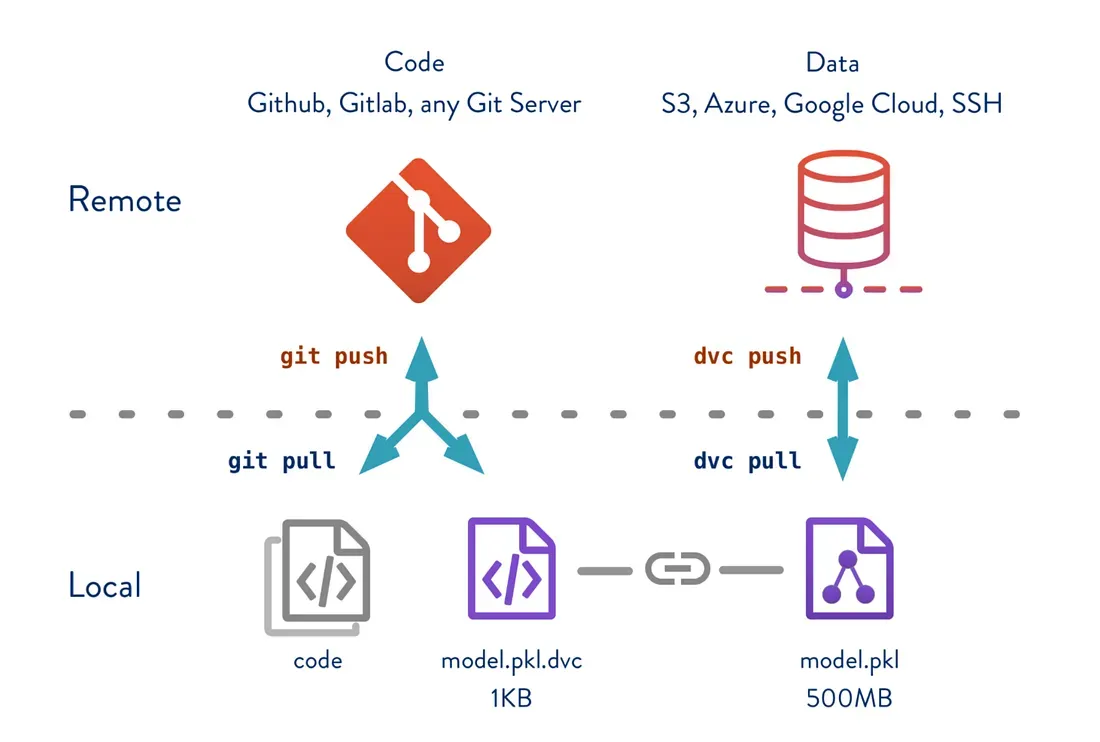
DVC es una herramienta de código abierto que lleva el control de versiones a los proyectos de aprendizaje automático mediante el seguimiento de conjuntos de datos, modelos y experimentos, de forma similar a la forma en que Git administra el código. No pretende ser una plataforma de MLOps completa, sino que se centra en la reproducibilidad, la colaboración y el seguimiento de modelos a través de flujos de trabajo compatibles con Git. El DVC se integra perfectamente en las canalizaciones existentes y brinda a los profesionales del aprendizaje automático más control sobre la gestión de los experimentos.
Características principales:
Ideal para:
Equipos que buscan capacidades de MLOps ligeras que prioricen el código y que se centren en la reproducibilidad, los flujos de trabajo basados en GIT y la gestión de experimentos, especialmente en proyectos de aprendizaje automático iterativos y de investigación.
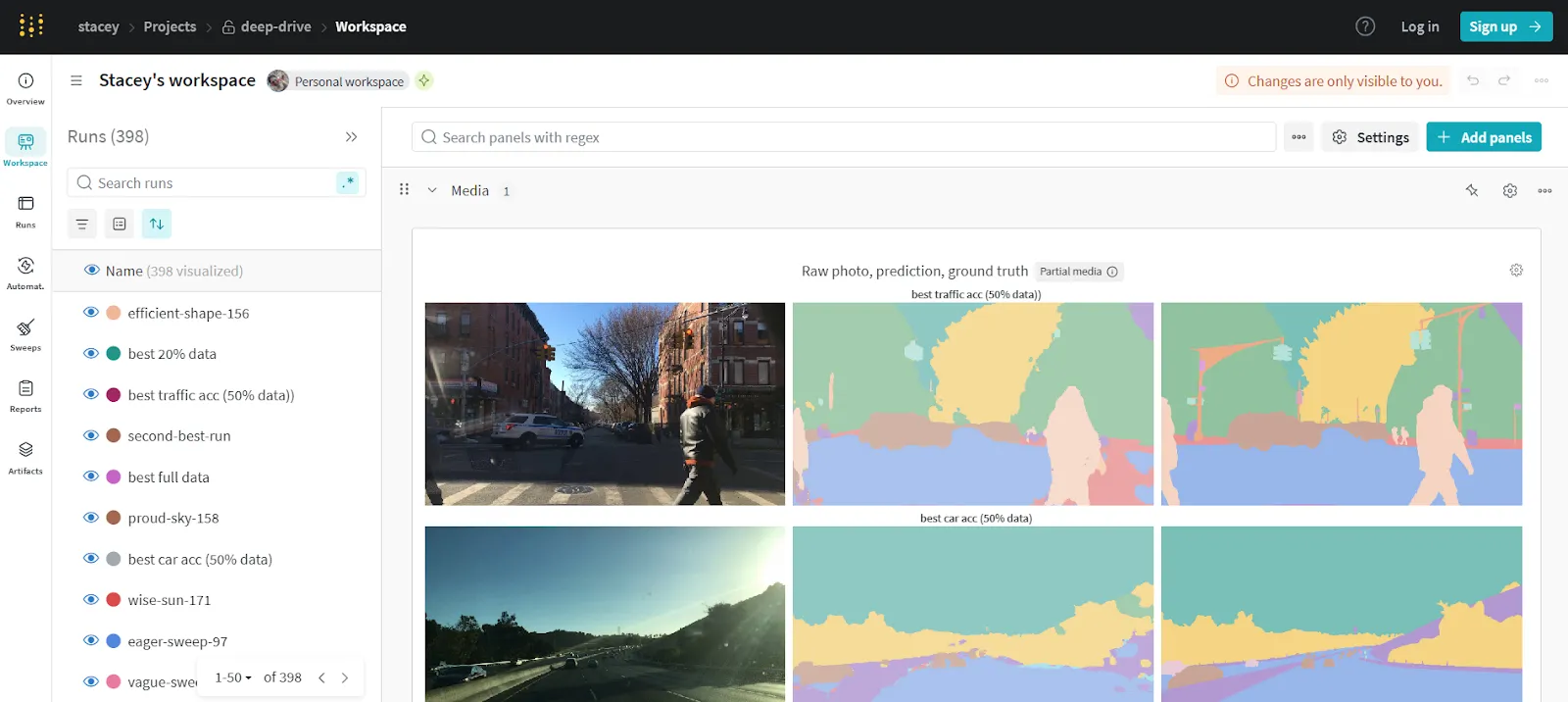
Weights & Biases (W&B) es una de las mejores herramientas de MLOps para el seguimiento de experimentos, la colaboración y la visualización de modelos. Se ha adoptado ampliamente tanto en entornos de investigación como de producción, y ofrece una integración sencilla con la mayoría de los marcos de aprendizaje automático. W&B se centra en la observabilidad, lo que permite obtener información en tiempo real sobre el rendimiento del entrenamiento, los hiperparámetros y las métricas del sistema.
Características principales:
Ideal para:
Los equipos de aprendizaje automático se centraron en la iteración, la visualización y la colaboración rápidas. Ideal para entornos y equipos impulsados por la investigación que desean conocer mejor el rendimiento de la formación.
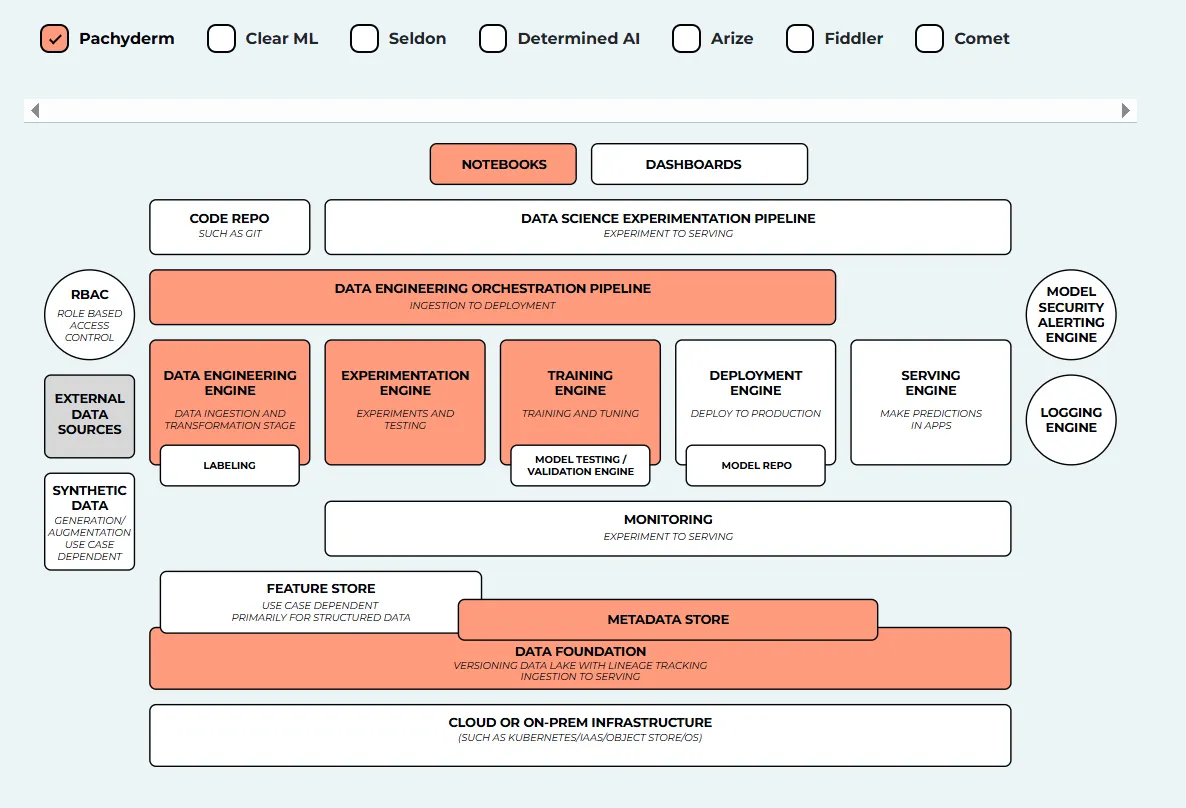
Pachyderm es una plataforma de ciencia de datos de código abierto creada para el linaje de datos, el control de versiones y las canalizaciones reproducibles. A diferencia de las herramientas MLOps tradicionales, Pachyderm utiliza un enfoque similar al de Git para los datos, lo que la hace muy adecuada para los equipos que gestionan dependencias de datos complejas o entornos regulados. Combina la contenedorización con la orquestación de las canalizaciones de datos para garantizar flujos de trabajo rastreables y versionados.
Características principales:
Ideal para:
Equipos de sectores regulados o flujos de trabajo con uso intensivo de datos que necesitan un control de versiones sólido y un seguimiento del linaje para garantizar el cumplimiento, la reproducibilidad y la escalabilidad.
Allegro AI es una plataforma mLOps diseñada específicamente para administrar los flujos de trabajo de aprendizaje profundo a escala, especialmente en entornos de visión artificial e IA perimetral. Se centra en mejorar la reproducibilidad, la colaboración y la trazabilidad a lo largo del ciclo de vida de la IA.
Con sólidas capacidades en la administración de conjuntos de datos, el control de versiones de modelos y el seguimiento de experimentos, esta herramienta MLOps ofrece una infraestructura segura e integral para los equipos que crean e implementan modelos de alto rendimiento en entornos regulados o de producción.
Características principales:
Ideal para:
Equipos que trabajan en casos prácticos de visión artificial, aprendizaje profundo o despliegue periférico, especialmente en sectores como la automoción, la fabricación, la sanidad o la defensa, donde la trazabilidad y el control de los datos y los modelos son fundamentales.
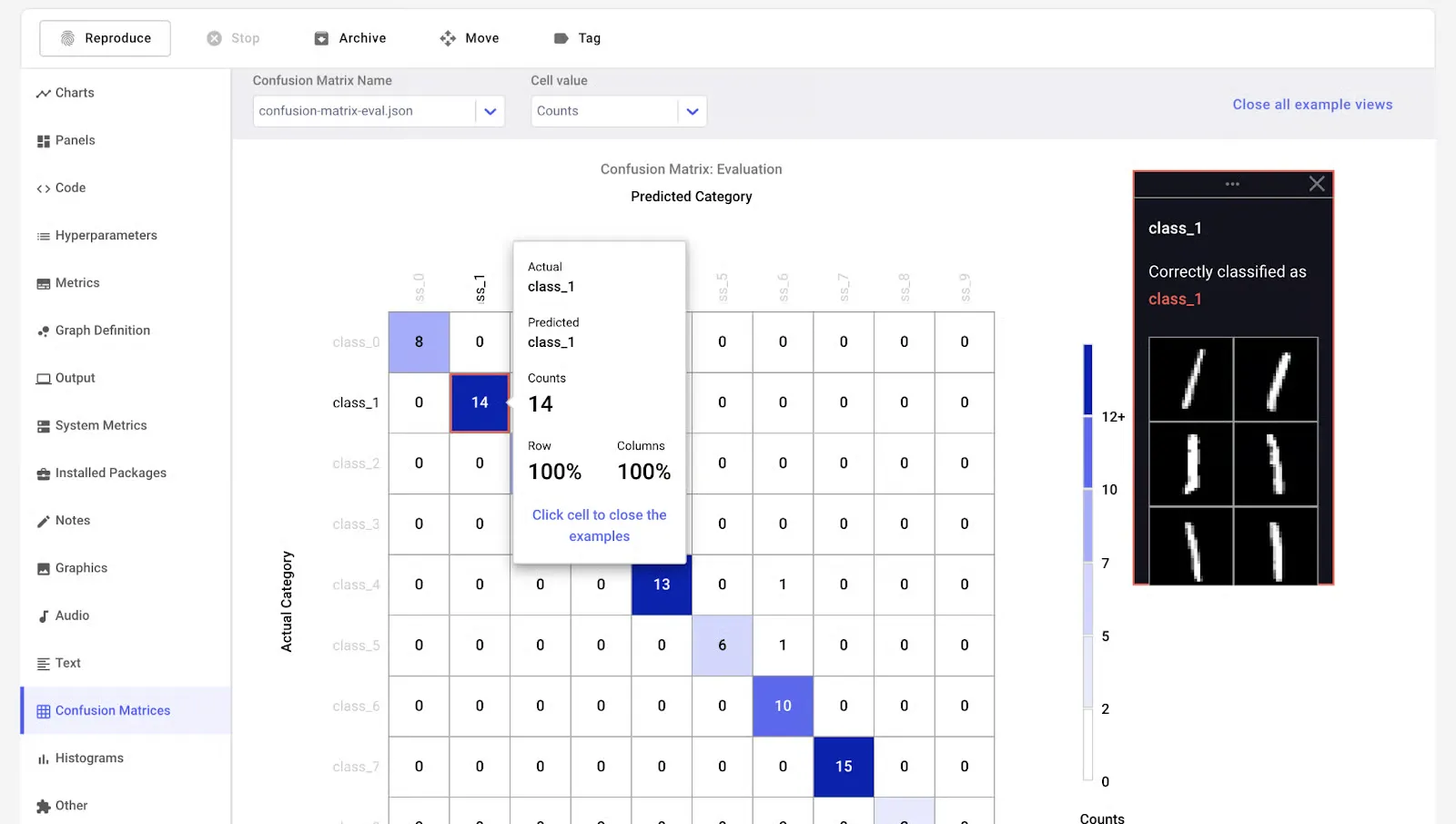
Comet ML es una plataforma de aprendizaje automático diseñada para ayudarlo a monitorear, analizar y refinar modelos y experimentos. Funciona a la perfección con bibliotecas populares como Scikit-learn, PyTorch, TensorFlow y Hugging Face.
La herramienta Comet MLOps facilita la exploración y comparación de los resultados de los experimentos, al tiempo que proporciona visualizaciones ricas para muestras de datos, incluidas imágenes, audio, texto y tablas estructuradas.
Características principales:
Ideal para:
Ideal para científicos de datos, ingenieros de aprendizaje automático y equipos que desean una forma sencilla de realizar un seguimiento de los experimentos, comparar los resultados y mejorar el rendimiento de los modelos.

Prefect es una herramienta moderna de orquestación del flujo de trabajo diseñada para monitorear, coordinar y administrar las canalizaciones de datos en todas las aplicaciones. Se trata de una solución ligera y de código abierto diseñada para respaldar el aprendizaje automático y los flujos de trabajo de datos de principio a fin.
Puede usar Prefect Orion UI o Prefect Cloud para administrar y visualizar los flujos de trabajo. Prefect Orion UI es un motor de orquestación y servidor de API de código abierto y alojado localmente que proporciona información sobre los flujos de trabajo locales y la actividad del sistema.
Prefect Cloud, por otro lado, es un servicio hospedado que le permite visualizar los flujos, las ejecuciones y las implementaciones, al mismo tiempo que administra las cuentas, los espacios de trabajo y la colaboración en equipo.
Características principales:
Ideal para:
Ingenieros de datos, ingenieros de aprendizaje automático y equipos que necesitan una orquestación confiable del flujo de trabajo, visibilidad de las canalizaciones y una colaboración escalable para datos y proyectos de aprendizaje automático.
Metaflow es una herramienta de gestión del flujo de trabajo para la ciencia de datos y el aprendizaje automático que simplifica la creación, la ejecución y la implementación de modelos. Esta herramienta mLOps ayuda a los equipos a gestionar las canalizaciones a escala y, al mismo tiempo, gestionar automáticamente el seguimiento de los experimentos, el control de versiones de los datos y el despliegue de la producción.
Características principales:
Ideal para:
Científicos de datos y equipos de aprendizaje automático que desean una herramienta de flujo de trabajo simple y escalable que gestione la orquestación, el seguimiento y la implementación y, al mismo tiempo, minimice la sobrecarga de los MLOps.
Dagster es una plataforma de orquestación nativa de la nube que ayuda a los equipos de datos a definir, ejecutar y monitorear flujos de datos complejos de manera eficiente. Se centra en la fiabilidad, la observabilidad y una experiencia de desarrollo moderna para gestionar los flujos de trabajo de datos.
Características principales:
Ideal para:
Ingenieros de datos y equipos de datos que necesitan una orquestación de canalización de datos confiable, comprobable y observable con una sólida integración soporte y un flujo de trabajo de desarrollo moderno.

Kedro es una herramienta de orquestación de flujos de trabajo basada en Python que ayuda a crear proyectos de ciencia de datos reproducibles, mantenibles y modulares. Incorpora las mejores prácticas de ingeniería de software, como la modularidad, la separación de preocupaciones y el control de versiones, a los flujos de trabajo de aprendizaje automático.
Características principales:
Ideal para:
Equipos y científicos de datos que desean flujos de trabajo de ciencia de datos estructurados, mantenibles y reproducibles utilizando las mejores prácticas de ingeniería de software.
TrueRA es una plataforma enfocada en mejorar la calidad del modelo de aprendizaje automático mediante pruebas, explicabilidad y análisis de causa raíz. Esta herramienta de MLOps ayuda a los equipos a depurar modelos, comprender los problemas de rendimiento y garantizar la equidad durante todo el ciclo de vida del aprendizaje automático.
Características principales:
Ideal para:
Ingenieros de aprendizaje automático, científicos de datos y organizaciones que necesitan información más profunda sobre los modelos, comprobaciones de imparcialidad y una supervisión fiable del rendimiento durante todo el ciclo de vida del modelo.
BentoML es una plataforma basada en Python que simplifica la implementación, el servicio y la supervisión de los modelos de aprendizaje automático en producción. Ayuda a los equipos a distribuir las aplicaciones de aprendizaje automático con mayor rapidez con un servicio de modelos escalable y de alto rendimiento.
Características principales:
Ideal para:
Ingenieros y equipos de aprendizaje automático que necesitan una forma rápida, escalable y confiable de implementar y administrar modelos de aprendizaje automático en entornos de producción.
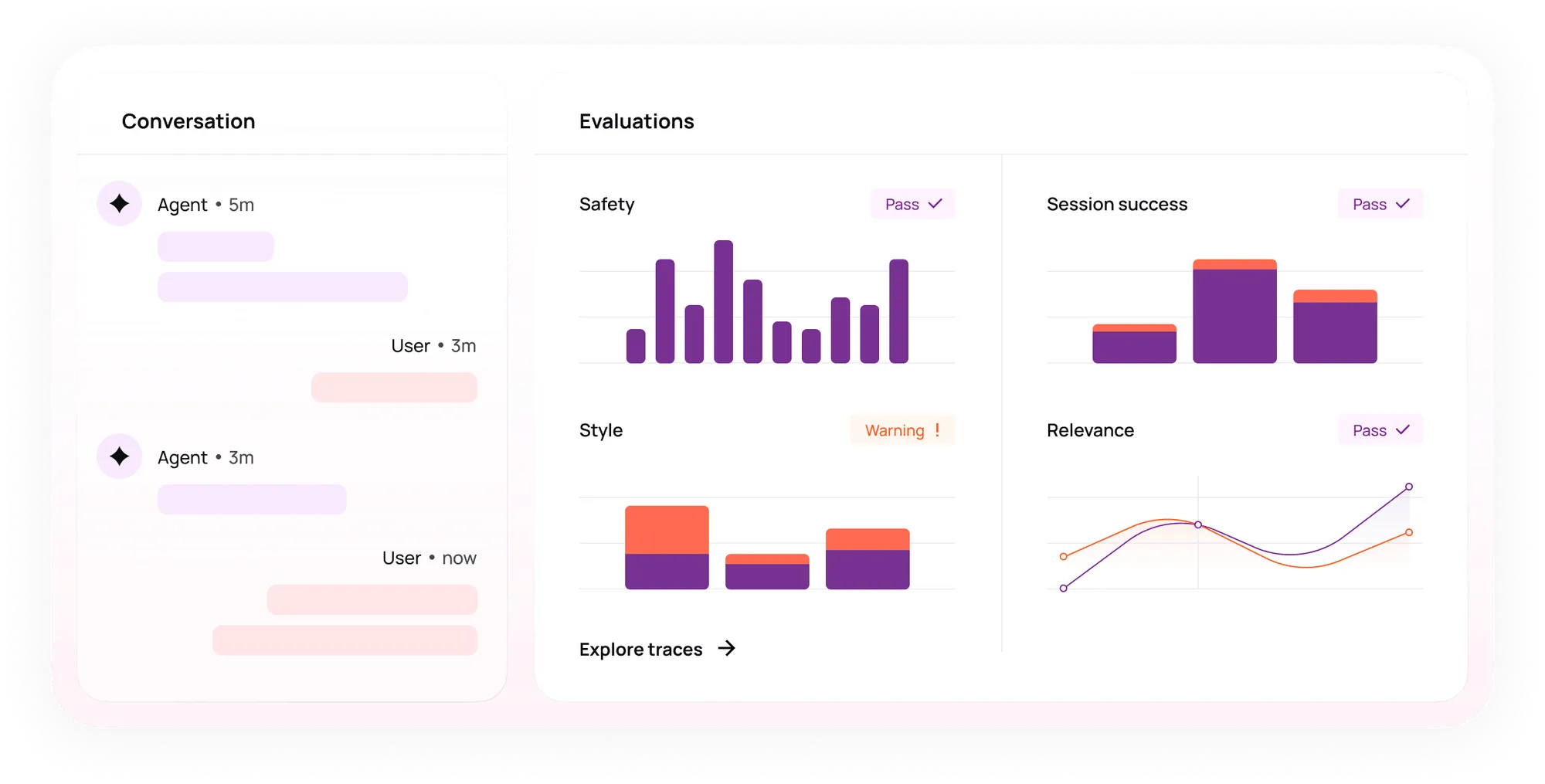
Evidentemente, la IA es una biblioteca de Python de código abierto para monitorear los modelos de aprendizaje automático en el desarrollo, la validación y la producción. Ayuda a garantizar la calidad de los datos y los modelos al detectar desviaciones, problemas de rendimiento y otros posibles problemas.
Características principales:
Ideal para:
Científicos de datos e ingenieros de aprendizaje automático que necesitan una supervisión fiable de los modelos, la detección de desviaciones y el seguimiento del rendimiento durante todo el ciclo de vida del aprendizaje automático.
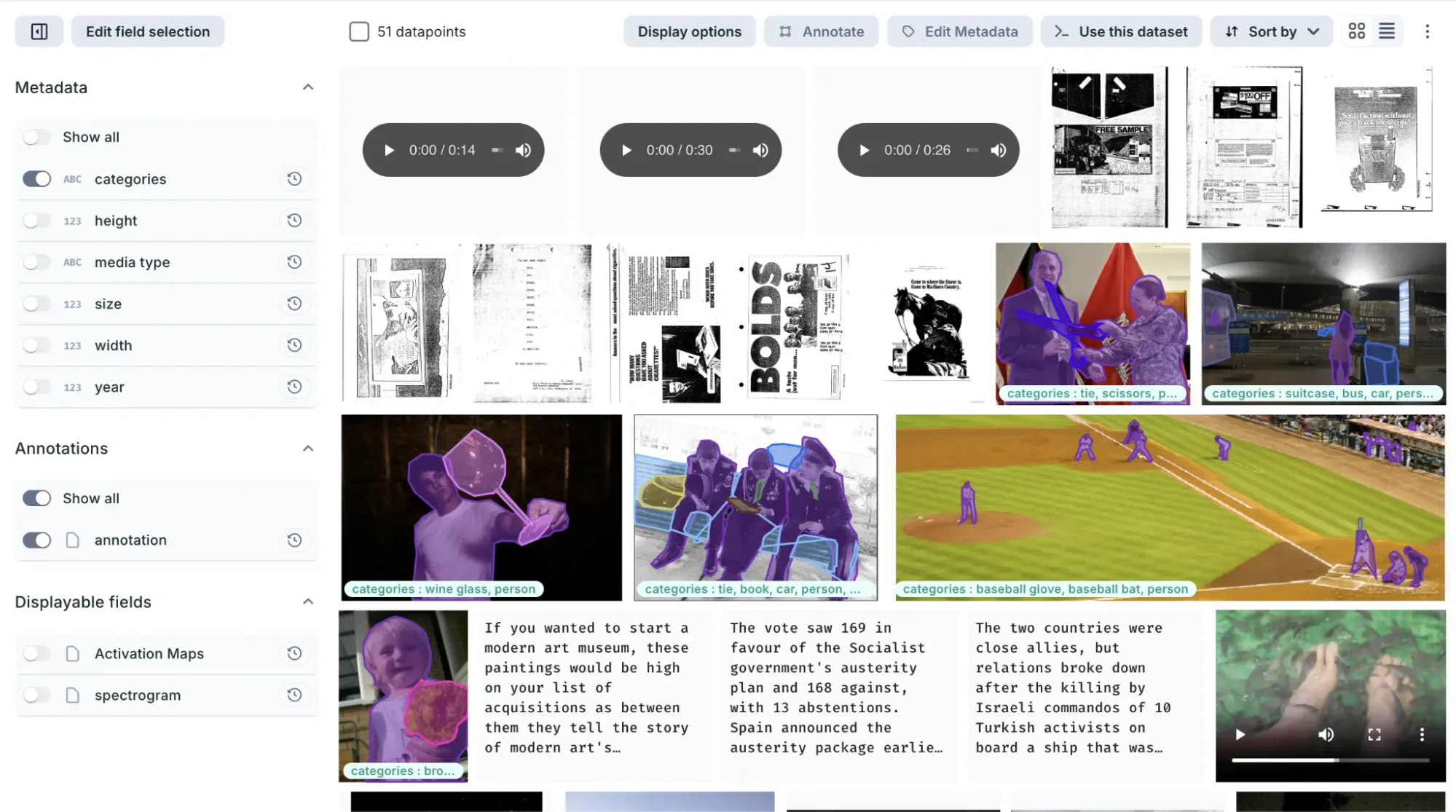
DagsHub es una plataforma de colaboración para proyectos de aprendizaje automático que ayuda a los equipos a rastrear, versionar y administrar datos, modelos, experimentos, canalizaciones y código en un solo lugar. A menudo descrita como «GitHub para el aprendizaje automático», proporciona herramientas para optimizar el flujo de trabajo de aprendizaje automático de principio a fin.
Características principales:
Ideal para:
Equipos y organizaciones de aprendizaje automático que necesitan un entorno colaborativo y controlado por versiones para gestionar todo el ciclo de vida del aprendizaje automático con un sólido soporte de integración y reproducibilidad.

La plataforma MLOps de Iguazio es una solución integral que automatiza todo el ciclo de vida del aprendizaje automático, desde la ingesta y preparación de datos hasta la capacitación, la implementación y el monitoreo de la producción. Esta herramienta mLOps ofrece tanto un marco de código abierto (MLRun) como una plataforma totalmente gestionada, con una implementación flexible en entornos de nube, híbridos o locales.
Características principales:
Ideal para:
Empresas e industrias reguladas (por ejemplo, atención médica, finanzas) que necesitan una plataforma MLOps flexible, escalable y gobernada con un sólido control de automatización e implementación.

Qdrant es una base de datos vectorial de código abierto y búsqueda de similitud motor que le permite almacenar, administrar y consultar incrustaciones de vectores a través de un servicio listo para la producción y una API sencilla. Está diseñado para aplicaciones de búsqueda semántica de alto rendimiento y basadas en inteligencia artificial.
Características principales:
Ideal para:
Creación de equipos de aprendizaje automático y desarrolladores búsqueda semántica, sistemas de recomendación y aplicaciones de IA que requieren una búsqueda y un filtrado vectoriales rápidos y escalables.

LakeFS es un sistema de control de versiones de datos de código abierto que incorpora operaciones similares a las de Git al almacenamiento de objetos, lo que permite a los equipos gestionar los lagos de datos con los mismos flujos de trabajo que se utilizan para el código. Permite un control de versiones de datos escalable y fiable para entornos de datos a gran escala.
Características principales:
Ideal para:
Ingenieros de datos y organizaciones que gestionan grandes lagos de datos y necesitan un control de versiones fiable, experimentación segura y flujos de trabajo de datos reproducibles a escala.

Fiddler AI es una plataforma de monitoreo y explicabilidad de modelos que ayuda a los equipos a comprender, depurar y rastrear los modelos de aprendizaje automático en producción. Proporciona información clara sobre el comportamiento, el rendimiento y la calidad de los datos de los modelos a través de una interfaz intuitiva.
Características principales:
Ideal para:
Ingenieros de aprendizaje automático, científicos de datos y organizaciones que necesitan una supervisión transparente de los modelos, capacidad de explicación y alertas proactivas para mantener sistemas de aprendizaje automático de producción confiables.
Ray es un marco de computación distribuida que ayuda a los desarrolladores a escalar las aplicaciones de IA y Python con facilidad. Proporciona un tiempo de ejecución flexible y un conjunto de bibliotecas de IA para crear, entrenar e implementar sistemas de aprendizaje automático a escala.
Características principales:
Ideal para:
Desarrolladores, ingenieros de aprendizaje automático y equipos de inteligencia artificial que necesitan un marco flexible y de alto rendimiento para escalar la capacitación, el procesamiento de datos y la prestación de modelos en entornos distribuidos.
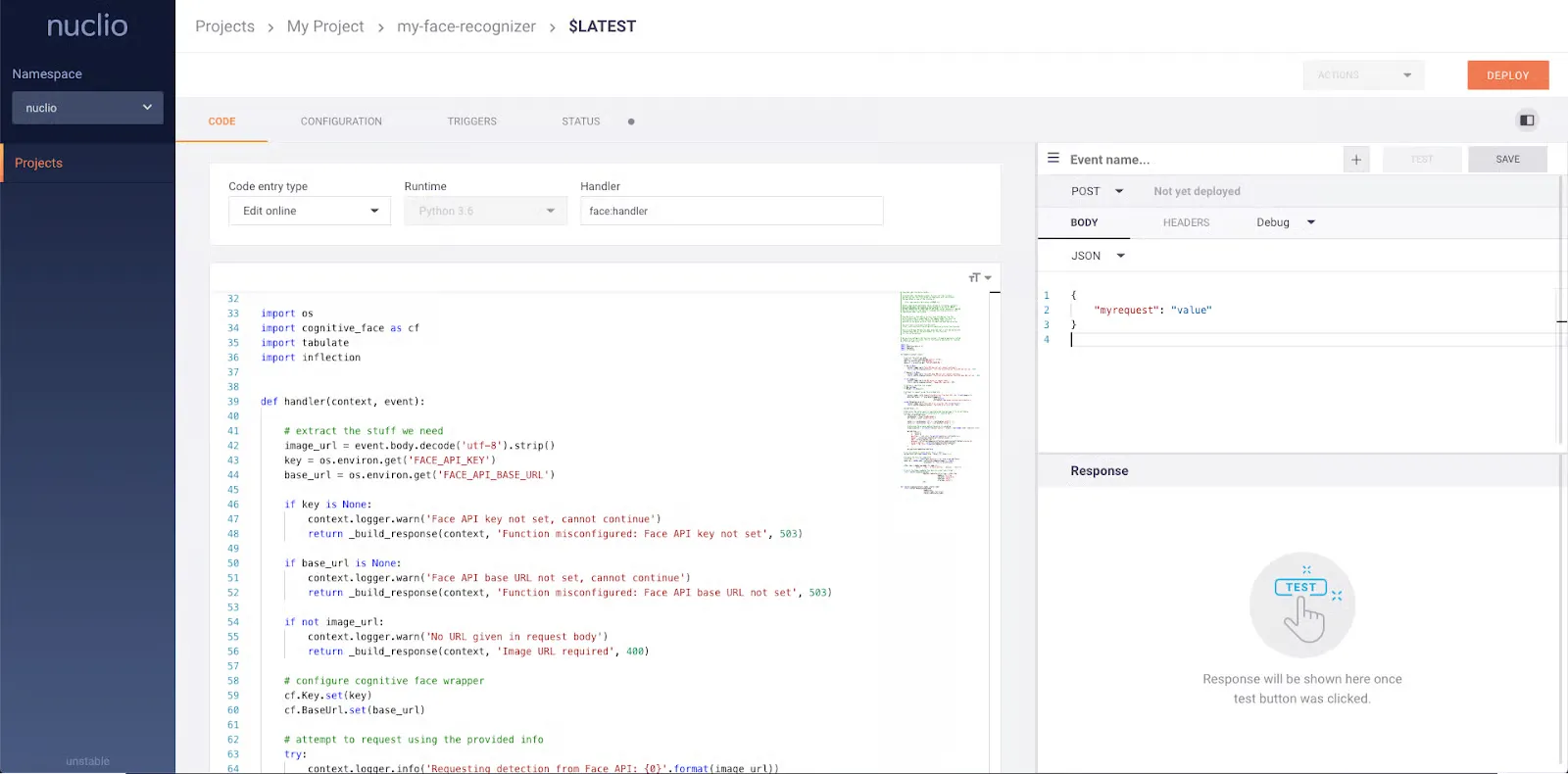
Nuclio es un marco sin servidor de alto rendimiento diseñado para cargas de trabajo con uso intensivo de datos, E/S y computación. Permite el procesamiento en tiempo real sin necesidad de administrar servidores y se integra bien con las herramientas de ciencia de datos y las plataformas de aprendizaje automático.
Características principales:
Ideal para:
Organizaciones y equipos de aprendizaje automático que necesitan una plataforma de alto rendimiento y sin servidores para el procesamiento de datos en tiempo real, la transmisión y las cargas de trabajo de IA escalables en entornos de nube y perimetrales.
Las mejores herramientas de MLOps ayudan a las organizaciones a administrar el ciclo de vida integral del aprendizaje automático de manera más eficiente. Aportan automatización, colaboración y confiabilidad a la creación, la implementación y el mantenimiento de los sistemas de aprendizaje automático.
Las herramientas de MLOps automatizan las tareas repetitivas, como la preparación de datos, el seguimiento de experimentos y la organización de canalizaciones. Esto permite a los equipos realizar iteraciones más rápido, reducir los errores manuales y pasar los modelos de la idea a la producción con mayor rapidez.
Estas herramientas proporcionan espacios de trabajo compartidos, activos versionados y documentación clara, lo que facilita que los científicos de datos, los ingenieros y las partes interesadas colaboren, revisen los cambios y compartan información entre los equipos.
Con la supervisión, las pruebas y la validación integradas, las herramientas de mLOps ayudan a detectar problemas como la desviación de los datos, el sesgo y la degradación del rendimiento. Esto garantiza que los modelos sigan siendo precisos, confiables y estén alineados con los objetivos empresariales.
Las plataformas MLOps rastrean las versiones de los datos, el código, los modelos y los experimentos, lo que permite a los equipos reproducir los resultados, auditar los cambios y mantener la coherencia en todos los entornos.
Simplifican la implementación de modelos en la producción mediante la automatización, los procesos de CI/CD y una infraestructura escalable, lo que permite a las organizaciones gestionar el aumento de las cargas de trabajo y adaptarse a las cambiantes demandas de manera eficiente.
MLOps ha pasado de ser una práctica especializada a convertirse en un componente fundamental de los flujos de trabajo modernos de aprendizaje automático. En 2026, las organizaciones ya no se preguntan si necesitan MLOps, sino qué plataforma se alinea mejor con sus objetivos, infraestructura y escala.
Como hemos visto, el panorama ofrece de todo, desde herramientas ligeras y modulares como MLFlow y DVC hasta soluciones empresariales totalmente administradas como Azure ML, Vertex AI y SageMaker.
Para los equipos que se centran en GenAI, el ajuste fino y la inferencia en tiempo real, las plataformas más nuevas, como TrueFoundry, ofrecen capacidades de vanguardia diseñadas para los desafíos modernos de la IA.
Operatice sus cargas de trabajo de ML y GenAI con mayor rapidez. Reserva una demostración con TrueFoundry para empezar.
mLOps no es mejor que DevOps; es una extensión de DevOps diseñada para el aprendizaje automático. Si bien DevOps se centra en la entrega de software y la automatización de la infraestructura, mLOps añade capacidades para la gestión de datos, el seguimiento de experimentos, la supervisión de modelos y la reproducibilidad, abordando los desafíos únicos de crear, implementar y mantener sistemas de aprendizaje automático en producción.
Las mejores herramientas de MLOps para empresas son aquellas que equilibran la velocidad de los desarrolladores con una gestión estricta de la infraestructura. Si bien los grandes proveedores de nube ofrecen amplios servicios, TrueFoundry suele ser la opción ideal para los equipos que requieren soberanía de datos y flexibilidad en la nube múltiple. Proporciona un plano de control unificado que se ejecuta de forma nativa dentro de su VPC privada, lo que le permite automatizar todo el ciclo de vida, desde la formación hasta la implementación, sin comprometer la seguridad ni el control de la infraestructura.
Docker es una tecnología fundamental para la contenedorización, lo que la convierte en una pieza fundamental del conjunto de herramientas de mLOps. Garantiza que los modelos se ejecuten de manera uniforme en todos los entornos de desarrollo y producción, aunque no gestiona tareas de nivel superior, como la supervisión de modelos o el control de versiones. TrueFoundry simplifica el proceso de contenedorización al crear automáticamente imágenes de Docker y organizarlas en Kubernetes, lo que permite a los científicos de datos implementar código sin necesidad de convertirse en expertos en DevOps.
TrueFoundry funciona como una capa de abstracción centrada en el desarrollador que se encuentra sobre su infraestructura de nube existente. Se conecta directamente a sus clústeres de Kubernetes y automatiza tareas complejas como el aprovisionamiento de recursos, la CI/CD y la entrega de modelos. Al proporcionar una interfaz única para gestionar los experimentos y las cargas de trabajo de producción, reduce los tiempos de implementación de semanas a minutos, al tiempo que reduce los costos mediante la optimización automatizada de la GPU y el soporte de instancias puntuales.
Ninguna nube es la mejor para los MLOps; la elección correcta depende de sus necesidades, herramientas y presupuesto. AWS, Azure y Google Cloud ofrecen servicios sólidos de MLOps, que incluyen canalizaciones automatizadas, capacitación escalable y monitoreo de modelos. Los equipos suelen elegir en función de la infraestructura existente, los requisitos de cumplimiento y la integración con su ecosistema de datos.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada








.png)

.webp)
.webp)
.webp)



.webp)
.webp)


