

October 5, 2023
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: April 27, 2026
%20(10).webp)
Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!

In diesem Beispiel trainieren wir ein Modell, das eine Blume der Gattung Iris anhand der Größenmaße ihrer Blütenblätter und Kelchblätter in eine von drei Arten einteilen kann.
Sie können diesem Beispiel auch auf einem folgen Google Collaboratory Notizbuch.
Das Iris-Datensatz enthält drei verschiedene Arten:
Wir müssen einen Klassifikator erstellen, der die Art der Blume anhand der folgenden Parameter identifizieren kann:
Wahre Gießerei bietet zwei Bibliotheken zur Vereinfachung Ihrer ML-Workflows:
MLFoundry Die Bibliothek wird verwendet, um ML-Trainingsexperimente zu verfolgen.
Warum brauchst du Experiment-Tracking? Wenn Sie mehrere ML-Modelle trainieren, um ein Problem zu lösen, werden Sie wahrscheinlich mehrere Modelle mit mehreren Frameworks, Hyperparametern und mehreren Datensätzen trainieren. Verfolgen Sie Ihr Experiment mit einer Bibliothek wie MLFoundry kann Ihnen bei der Organisation Ihrer ML-Experimente helfen.
Sie können MLFoundry verwenden, um Hyperparameter, Metriken, Datensätze und Modelle zu protokollieren. Anschließend können Sie verschiedene Experimente auf dem vergleichen TrueFoundry-Dashboard und wählen Sie ein Modell aus, das in der Produktion eingesetzt werden soll, oder entscheiden Sie, das Modell erneut zu trainieren.
In diesem Beispiel werden wir 5 verschiedene APIs von MLFoundry verwenden. Sie sind:
Mit dem Servicegießerei Bibliothek, Sie können ein Modell einfach paketieren, containerisieren und in einem Kubernetes-Cluster bereitstellen.
Öffnen Sie ein IPython-Notizbuch — Sie können entweder Jupyter verwenden, das lokal auf Ihrem Computer läuft, oder ein Google Colab-Notebook, das in der Cloud läuft.
Installieren Sie die erforderlichen Bibliotheken.
Melden Sie sich bei TrueFoundry an. Erstellen und kopieren Sie einen API-Schlüssel von der Einstellungsseite. Verwenden Sie diesen API-Schlüssel, um den MLFoundry-Client zu initialisieren und einen Lauf zu erstellen. Ein Lauf ist eine Entität, die ein einzelnes Experiment darstellt.
Rufen Sie den Iris-Datensatz mit dem sklearn.datasets Modul. Wir unterteilen es dann in Test- und Trainingsdatensätze.
Schauen wir uns die Zielnamen an. Wir werden dies verwenden, um die Integer-Ausgabe des Modells den tatsächlichen Namen der Arten zuzuordnen
Initialisieren Sie ein Modell. Verwenden Sie dann MLFoundry, um die Parameter des Modells zu protokollieren und einige Tags für diesen aktuellen Experimentlauf zu erstellen.
Als Nächstes trainieren wir das Modell anhand unseres Zugdatensatzes. Sobald das Training abgeschlossen ist, berechnen wir die verschiedenen Metriken und protokollieren sie in MLFoundry mit log_metrics.
Wenn wir mit den Genauigkeitswerten und anderen Metriken zufrieden sind, können wir uns dafür entscheiden, das aktuelle Modell einzusetzen. Dafür müssen wir das Modell speichern und kopiere die aktuelle Lauf-ID.
Du kannst alle deine Läufe sehen und Metriken vergleichen über TrueFoundry-Dashboard zur Versuchsverfolgung.

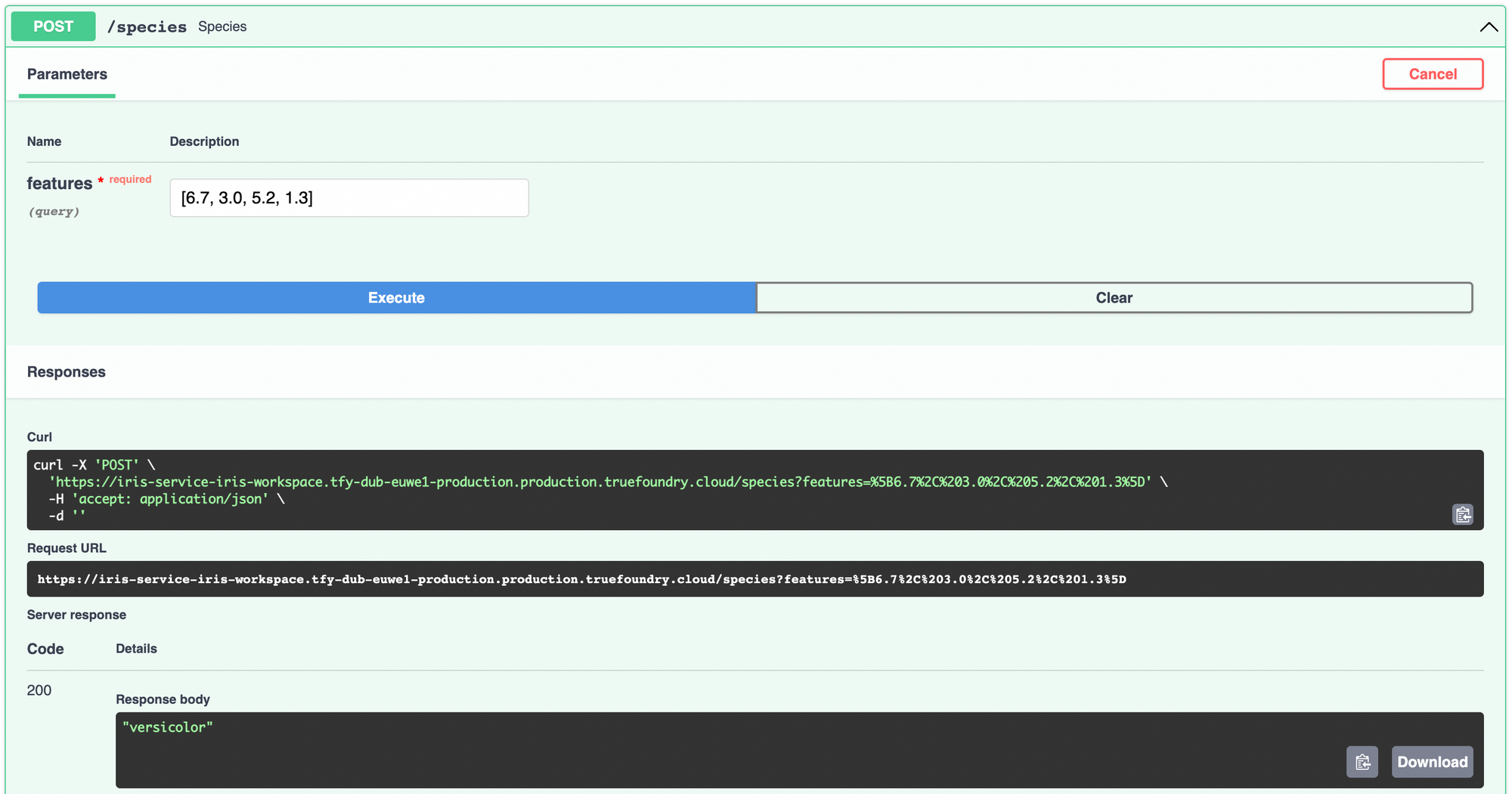
Um das Modell mit ServiceFoundry bereitzustellen, müssen wir eine Python-Datei erstellen, die die Funktion enthält, die wir als Endpunkt bereitstellen möchten.
In dieser Python-Datei rufen wir das Modell ab, das wir gerade trainiert und gespeichert haben, unter Verwendung der Run-ID MLFoundry. Beachten Sie, dass der API-Schlüssel erforderlich ist von MLFoundry wird als Umgebungsvariable verfügbar sein TFY_API_KEY.
Erstellen Sie in Ihrem IPython-Notizbuch einen Block mit dem folgenden Inhalt und führen Sie ihn aus, um eine Python-Datei mit dem Namen zu erstellen predict.py. Wir verwenden den Jupyter-Zauberbefehl % Datei schreiben um die Datei in der Notebook-Umgebung zu erstellen.
Innerhalb der Artenfunktion laden wir die Merkmale in eine Pandas DataFrame und treffen Sie die Vorhersage mithilfe des Modells. Wir übersetzen von der Integer-Klasse in Artennamen mit Hilfe der Zielnamen wir haben während des Trainings gedruckt.
Das ist so ziemlich die ganze Arbeit, die Sie erledigen müssen. Lassen Sie uns dieses Modell nun als API-Dienst bereitstellen. Installieren und importieren Sie zunächst Servicegießerei in deinem Notizbuch. Loggen Sie sich ein Servicegießerei.
Gehe zum TrueFoundry-Dashboard und erstellen Sie einen Arbeitsbereich, um den Dienst bereitzustellen. Workspaces sind eine Möglichkeit, verwandte Projekte in TrueFoundry zu gruppieren. Sobald der Workspace erstellt ist, kopiere den FQN, damit wir das erkennen können Servicegießerei wo das Modell eingesetzt werden soll.

Servicegießerei Mit der Bibliothek können Sie alle Abhängigkeiten der Datei sammeln, die Sie gerade mit Anforderungen sammeln Funktion.
Erstellen Sie jetzt eine SFY-Service Objekt, stellen Sie den Workspace-FQN bereit und stellen Sie ihn bereit, indem Sie .bereitstellen ()
Sie können den Fortschritt dieser Bereitstellung auf der Dashboard. Sobald die Bereitstellung abgeschlossen ist, können Sie von dort aus auf den bereitgestellten Dienst zugreifen und ihn ausprobieren.
Das TrueFoundry-Dashboard enthält auch Links zu Metriken und Protokollen, die in TrueFoundry-Bereitstellungen in Form von Grafana-Dashboards standardmäßig enthalten sind. Sie können mehr über sie lesen hier.

Sie können interaktive UI-Anwendungen und Gradio-Anwendungen auch einfach von einem IPython-Notebook aus bereitstellen, indem Sie Servicegießerei. Lesen Sie das Leitfaden um zu sehen wie.
Wir arbeiten daran, die Integration zwischen Versuchsverfolgung und Bereitstellung noch enger zu gestalten und das Erlebnis noch angenehmer zu gestalten. Weitere Dinge, die Sie mit TrueFoundry tun können, finden Sie unter unsere Dokumente.Wenn Sie Modelle für maschinelles Lernen trainieren, um ein Problem zu lösen, hilft Ihnen TrueFoundry dabei, verschiedene Experimente nachzuverfolgen und macht es einfach und intuitiv, Modelle mit Best Practices bereitzustellen und sie innerhalb weniger Minuten der Öffentlichkeit zugänglich zu machen.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.








.png)
.webp)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




