

May 8, 2024
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: April 22, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
In einer Zeit, in der LLMs kritische Anwendungen unterstützen, ist der Einblick in ihr Innenleben nicht verhandelbar. LLM-Observability ist die Praxis, Daten auf Inferenzebene zu erfassen und zu analysieren, einschließlich Token-Nutzung, Prompt-Performance, Fehlerraten, Latenz- und Kostenkennzahlen, und sie mit Benutzerinteraktionen zu korrelieren. Dies geht über die herkömmliche Modellüberwachung hinaus, bei der Infrastrukturkennzahlen wie CPU-Auslastung und Reaktionszeiten weitgehend nachverfolgt werden. Das AI Gateway von TrueFoundry enthält eine umfassende Beobachtbarkeitsebene mit zeitnaher Versionierung, strukturierter Protokollierung, Dashboards für Echtzeitanalysen und Anomaliewarnungen, um verwertbare Erkenntnisse zu gewinnen, die Leistung zu optimieren und die Kosten in jeder Phase Ihrer LLM-Pipeline zu kontrollieren.
LLM-Observability ist die umfassende Praxis der Instrumentierung, Erfassung und Analyse jedes Inferenzereignisses in einer Sprachmodell-Pipeline. Es kombiniert zwei Kernschichten:
Interaktive Analytik
Ein zentralisiertes Dashboard zeigt Echtzeit-Metriken zur Token-Nutzung, zum Anforderungsvolumen und zu den Kosten an. Sie können die kumulativen Eingabe- und Ausgabetokens, die Gesamtzahl der Anfragen und die Token-Kosten sowie die Latenzperzentile (P50, P90, P99) für jedes Modell anzeigen. Diagramme zeigen Anfragen pro Sekunde, Fehlerraten, Verbrauch auf Benutzerebene und modellspezifische Kostenaufschlüsselungen. Mithilfe von Filtern können Sie Anrufe isolieren, die von Ratenbegrenzungen, Fallbacks oder Load Balancing betroffen sind, und überprüfen, welche Regeln angewendet wurden.
Metadatengetriebener Kontext
Jede Anfrage kann benutzerdefinierte Tags wie Umgebung (dev, staging, prod), Feature-Name, Benutzer-ID, Team oder einen beliebigen Geschäftskontext über einen X-TFY-METADATA-Header enthalten. Metadaten ermöglichen:
Exportieren von Protokollen
Für eingehende Analysen oder Archivierung unterstützt TrueFoundry auf Anfrage strukturierte JSON-Exporte von Protokollen und Traces und ermöglicht so eine Offline-Untersuchung von Leistung, Kosten und Nutzungsmustern
Zusammen bieten diese Funktionen den Teams einen vollständigen Überblick über das Modellverhalten, die Kostentreiber und potenzielle Probleme und sorgen so für zuverlässige und optimierte LLM-Bereitstellungen.
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
Traditionelle Modellbeobachtbarkeit konzentriert sich in erster Linie auf den Zustand der Infrastruktur und grundlegende Anforderungsmetriken. Sie überwachen Indikatoren auf Systemebene wie CPU- und GPU-Auslastung, Speicherverbrauch, Festplatten-I/O, Netzwerkdurchsatz, allgemeine Anforderungslatenz und Fehlerraten. Diese Metriken geben an, ob Ihre Model-Serving-Plattform betriebsbereit ist und wo Rechen- oder Netzwerkengpässe auftreten können. Warnmeldungen werden bei Grenzwertüberschreitungen wie hoher CPU-Auslastung oder erhöhten 5xx-Fehlerraten ausgelöst, sodass Betriebsteams Ressourcen bereitstellen oder Serviceausfälle untersuchen können.
Im Gegensatz dazu befasst sich die LLM-Observability eingehender mit der Semantik und Ökonomie jeder Inferenz. Große Sprachmodelle verarbeiten Eingaben mit variabler Länge und generieren Inhalte Token für Token. Um ihr Verhalten zu verstehen, ist eine inhaltsorientierte Instrumentierung erforderlich:
Token-Metriken im Vergleich zum festen Durchsatz
Herkömmliche Modelle zählen Anfragen pro Sekunde; LLMs verfolgen Eingabe- und Ausgabetokens. Observability erfasst das kumulative Token-Volumen, die Token-Kosten und die Token-Nutzung pro Modell. Auf diese Weise können Sie Ausgaben bestimmten Benutzern oder Funktionen zuordnen und unkontrollierbare Aufforderungen erkennen, bevor die Kosten eskalieren.
Prompt-Response-Logging im Vergleich zu Black-Box-Vorhersagen
Standard-ML-Observability-Logs fordern nur Metadaten an, wie Endpunkt-Treffer und Statuscode. LLM-Observability zeichnet vollständige Prompt-Response-Paare zusammen mit kontextbezogenen Metadaten wie Umgebung, Funktion und Benutzer-ID auf. Dadurch ist es möglich, Halluzinationen oder Qualitätsregressionen auf bestimmte Prompt-Vorlagen oder Benutzerkohorten zurückzuverfolgen.
Latenzperzentile im Vergleich zu Durchschnittswerten
Herkömmliche Setups melden oft eine durchschnittliche Latenz. LLM-Dashboards zeigen P50-, P90- und P99-Latenzperzentile pro Modell an, da die Token-für-Token-Generierung zu Verzögerungen führen kann, die durchschnittliche Metriken verschleiern.
Konfigurationsgesteuerte Effekte
Bei LLMs wirken sich Steuerelemente wie Ratenbegrenzung, Lastausgleich und Fallback-Regeln auf das Verhalten aus. Observability kennzeichnet Anfragen, die von diesen Regeln betroffen sind — zum Beispiel Anrufe, die ratenbegrenzt waren, umgeleitet wurden oder an einen anderen Anbieter weitergeleitet wurden —, sodass Teams die Richtlinien optimieren können.
Echtzeitanalysen im Vergleich zu Post-Mortem-Logs
Während herkömmliche Observability auf regelmäßigen Protokollanalysen beruht, bieten LLM-Observability-Plattformen wie das AI Gateway von TrueFoundry interaktive Dashboards für die Filterung und Trenderkundung in Echtzeit, sodass Sie Metriken im Handumdrehen nach Metadaten-Tags aufteilen können.
Zusammenfassend lässt sich sagen, dass die traditionelle Observability die Frage beantwortet: „Ist die Serverinfrastruktur in Ordnung?“ LLM-Observability erklärt: „Wie, wann und warum wird jedes Token generiert, und was bedeutet das für Kosten, Leistung und Ausgabequalität?“
Die Implementierung einer robusten Beobachtbarkeit für LLMs ist unerlässlich, um die Leistung aufrechtzuerhalten, die Kosten zu kontrollieren und qualitativ hochwertige Ergebnisse sicherzustellen. Diese Kernpfeiler arbeiten zusammen, um den Teams einen vollständigen Überblick über jedes Inferenzereignis zu bieten. Wenn Sie sie verstehen und anwenden, können Sie Ihre LLM-Implementierungen effektiv überwachen, diagnostizieren und optimieren.
1. Interaktive Analytik
Ein einheitliches Dashboard bietet Einblicke in Echtzeit in jeden Aspekt Ihres LLM-Workloads. Sie können das kumulierte und modellspezifische Eingabe- und Ausgabe-Token-Volumen, die Gesamtzahl der Anfragen und die tokenbasierten Kosten verfolgen. Die detaillierten Latenzperzentile P50, P90 und P99 geben Aufschluss über die Leistungsmerkmale. Diagramme für Anfragen pro Sekunde und Fehlerraten helfen Ihnen dabei, Anomalien zu erkennen. Mithilfe von Filtern können Sie Anrufe, die von Ratenbegrenzungen, Lastausgleichsregeln oder Fallbacks betroffen sind, detailliert untersuchen, um eine gezielte Fehlerbehebung zu ermöglichen.
2. Metadatengetriebener Kontext
Indem Sie jeder Anfrage benutzerdefinierte Metadaten wie Umgebung (Dev, Staging, Prod), Feature-Name, Benutzer-ID oder Team anhängen, erhalten Sie die Möglichkeit, Ihre Metriken aufzuteilen. Metadaten ermöglichen eine detaillierte kohortenübergreifende Nutzungsüberwachung, ermöglichen bedingte Kontrollen zur Ratenbegrenzung und Modellauswahl und ermöglichen eine präzise Protokollfilterung für Audits und die Einhaltung gesetzlicher Vorschriften. Sie übergeben Metadaten über einen einzigen X-TFY-METADATA-Header in OpenAI- oder LangChain-SDKs, REST-Anfragen oder cURL-Aufrufen.
3. Umfassende Protokollierung
Jede Inferenz wird in einem strukturierten Format protokolliert, das vollständige Prompt-Response-Paare, Tokenzahlen, Latenzdetails, Fehlercodes und angehängte Metadaten enthält. Mit diesem Detaillierungsgrad können Sie Ursachenanalysen für Halluzinationen, Qualitätsregressionen oder Leistungsanomalien durchführen. Sie können die Versionen der Eingabeaufforderungen vergleichen, überwachen, wie sich Änderungen an Vorlagen auf die Ausgabequalität auswirken, und Probleme auf bestimmte Benutzerkohorten oder Funktionen zurückführen.
4. Export und Prüfung von Protokollen
Für tiefere Offline-Analysen oder Archivierung unterstützt TrueFoundry strukturierte JSON-Exporte von Logs und Traces. Administratoren fordern einfach Exporte mit einem bestimmten Zeitrahmen über den Support an. Exportierte Daten ermöglichen benutzerdefinierte Analysen, Compliance-Berichte oder die langfristige Speicherung.
Zusammen bieten diese Säulen vollständige Transparenz über Kostentreiber, Leistungsprofile und Ergebnisqualität und stellen so sicher, dass Ihre LLM-Implementierungen zuverlässig, effizient und kostengünstig bleiben.
Hier sind die 4 beste LLM-Observability-Tools, jeweils mit einem kurzen Überblick:
Das AI Gateway von TrueFoundry bietet eine einheitliche, unternehmenstaugliche Observability- und Governance-Lösung für LLMs mit den folgenden Funktionen:
Echtzeit-Metriken
.webp)
Interaktive Dashboards, die die kumulative Anzahl der Eingabe-/Ausgabe-Tokens pro Modell, das gesamte Anforderungsvolumen, Kostenaufschlüsselungen nach Modell und Benutzer sowie detaillierte Latenzperzentile (P50, P90, P99) anzeigen. Heatmaps für Anfragen pro Sekunde, Trends bei der Fehlerrate und konfigurierbare Anomaliewarnungen zur Erkennung von Ausfall- oder Latenzspitzen
Metadatengestützte Einblicke
{
„tfy_log_request“: „true“, //Ob ein Log/Trace für diese Anfrage oder jetzt hinzugefügt werden soll
„environment“: „staging“,//Die Umgebung - Entwicklung, Staging oder Produktion?
„feature“: „countdown-bot“ //Welches Feature hat die Anfrage ausgelöst?
}
Taggen Sie Anfragen mit dem Geschäftskontext (Umgebung, Funktion, Benutzer, Team) über einen einzigen X-TFY-METADATA-Header. Unterteilen Sie Dashboards und Protokolle nach Metadaten, um Umgebungen zu vergleichen, die Nutzung von Funktionen zu isolieren und Benutzer- oder Teamaktivitäten zu überprüfen.
Richtlinienkontrollen als Code
Definieren Sie YAML-gesteuerte Regeln zur Ratenbegrenzung (z. B. „1000 GPT-4-Aufrufe/Tag für Entwickler“), Lastausgleichsgewichtungen zwischen Anbietern und Fallback-Ketten, wenn Fehler auftreten
Versionskontrollierte Richtliniendefinitionen, die über GitOps-Workflows verwaltet werden und Pull-Request-Reviews, CI-Validierung und Rollbacks ermöglichen
Umfassendes Logging & Tracing

Speichern Sie strukturierte JSON-Protokolle mit vollständigen Prompt-Response-Paaren, Aufschlüsselungen auf Token-Ebene, Latenz, Fehlercodes und angewendeten Richtlinien-IDs. Korrelieren Sie verteilte Traces, um mehrstufige Workflows oder RAG-Pipelines zu debuggen
Export und Einhaltung der Vorschriften:
On-Demand-Export von Logs und Traces in JSON für Offline-Analysen, Langzeitarchivierung oder behördliche Prüfungen. Integrierte RBAC- und Audit-Trails stellen sicher, dass nur autorisierte Benutzer sensible Daten einsehen oder exportieren können
Diese Funktionen machen TrueFoundry zu einer herausragenden Wahl für Teams, die bei ihren LLM-Implementierungen eine durchgängige Transparenz, eine präzise Kostenkontrolle, Policy-as-Code-Governance und robuste Überprüfbarkeit benötigen.
LangSmith ist auf Deep Tracing und Debugging für LangChain-basierte Anwendungen spezialisiert. Es erfasst automatisch jeden Schritt Ihrer Ketten und protokolliert Eingaben, Zwischenausgaben und endgültige Antworten. Entwickler erhalten einen interaktiven Trace-Visualizer, mit dem sie Vorlagen für Eingabeaufforderungen im Zeitverlauf vergleichen, Leistungseinbußen erkennen und Funktionsaufrufen detailliert analysieren können. LangSmith zeichnet auch Laufzeitmetriken wie Token-Nutzung und Latenz pro Kettenschritt auf und ermöglicht es Ihnen, benutzerdefinierte Metadaten für das Feature-Tracking anzuhängen. Mit dem integrierten Versuchsmanagement können Sie Läufe taggen, die Ausgabequalität verschiedener Modellversionen vergleichen und zu bewährten Konfigurationen zurückkehren. Der Fokus liegt auf der Ergonomie der Entwickler und der Chain-Transparenz und ist daher ideal für schnelle Iterationen und Debugging.
Helicone bietet eine API-zentrierte Beobachtbarkeitsplattform, die auf generative KI zugeschnitten ist. Sie zeichnet jeden API-Aufruf an OpenAI-, Anthropic- oder andere Endpunkte auf und erfasst vollständige Eingabeaufforderungstexte, Antworten, Token-Nutzung und Zeitdetails. Das Dashboard von Helicone zeigt die Kosten pro Anruf, die am häufigsten verwendeten Vorlagen für Eingabeaufforderungen und die Fehlerverteilungen auf und hilft Ihnen dabei, teure oder fehleranfällige Muster zu erkennen. Integrierte Visualisierungen zur Traffic-Shaping verdeutlichen, wie sich Ratenbegrenzungen und Kontingente auf den Durchsatz auswirken. Außerdem können Sie Warnmeldungen für Kostenspitzen oder erhöhte Fehlerraten konfigurieren. Mit seinen schlanken SDK-Integrationen bietet Helicone schnelle Einblicke in Ausgaben und Leistung und ist somit eine hervorragende Wahl für Teams, die sich auf API-Kostenkontrolle und schnelle Optimierung konzentrieren.
Lunary konzentriert sich auf Einfachheit und Entwicklererfahrung für LLM-Observability. Es instrumentiert OpenAI- und Anthropic SDK-Aufrufe automatisch und protokolliert Prompt-Journeys, Token-Metriken und Antwortzeiten mit minimaler Konfiguration. Das Dashboard bietet versionierte Vorlagen für Eingabeaufforderungen und Regressionserkennung für die Ausgabequalität. Sie werden benachrichtigt, wenn Änderungen zu unerwarteten Ergebnissen führen. Lunary bietet auch eine Annotations-API, um Experimente oder A/B-Tests zu taggen, was klare Vergleiche zwischen Durchläufen ermöglicht. Es ist zwar leicht, unterstützt aber bedingte Steuerungen für Ratenbegrenzung und Fallback-Routing. Lunary legt großen Wert auf einfache Einrichtung und zentrale Observability-Funktionen und ist daher ideal für kleine Teams oder Prototypen, die schnelles Feedback zum Modellverhalten ohne komplexe Integrationen benötigen.
Verwendung variabler Tokens: LLMs generieren Ausgaben Token für Token, sodass jede Anfrage sehr unterschiedliche Tokenzahlen verbrauchen kann. Die Überwachung und Zuordnung der Kosten wird komplex, wenn das Token-Volumen je nach Eingabeaufforderungen und Benutzern stark schwankt. Ohne ein detailliertes Token-Tracking riskieren Teams unerwartete Abrechnungsspitzen oder unbemerkte ineffiziente Aufforderungen.
Hohes Datenvolumen: Durch die Erfassung vollständiger Prompt-Response-Paare, Token-Metriken, Latenzdetails und Metadaten für jede Inferenz können täglich Millionen von Protokolleinträgen generiert werden. Das Speichern, Indizieren und Abfragen dieser Menge strukturierter Daten erfordert skalierbare Speicherlösungen und optimierte Abfrage-Engines, um Leistungsengpässe in Ihrer Observability-Pipeline zu vermeiden.
Kontextuelle Komplexität: Das LLM-Verhalten hängt stark von der Formulierung der Eingabeaufforderung, den Temperatureinstellungen und der Modellversion ab. Das Korrelieren von Änderungen der Ausgabequalität oder Latenz mit bestimmten Eingabeaufforderungsänderungen oder Konfigurationsanpassungen erfordert eine robuste Trace-Verknüpfung und Versionierung. Teams müssen ein konsistentes Metadaten-Tagging implementieren und umgehend eine Versionskontrolle durchführen, um das Netz der Einflussfaktoren zu entwirren.
Korrelation mehrerer Anbieter: Viele Bereitstellungen verwenden mehrere LLM-Anbieter für den Lastenausgleich oder die Kostenoptimierung. Die Zusammenfassung der Metriken von OpenAI, Azure, Anthropic und anderen Endpunkten in einer einheitlichen Ansicht erfordert die Normalisierung unterschiedlicher APIs, Antwortformate und Kostenstrukturen. Das Versäumnis, diese Streams zu vereinheitlichen, führt zu fragmentierten Erkenntnissen und blinden Flecken bei anbieterübergreifenden Leistungsvergleichen.
Alarmierung in Echtzeit im Vergleich zu Lärm: Die Festlegung aussagekräftiger Warnschwellenwerte für Fehlerraten, Latenzspitzen oder Kostenanomalien ist in einer Umgebung, in der natürliche Schwankungen häufig vorkommen, eine Herausforderung. Zu sensible Alarme führen zu einer Übermüdung der Warnmeldungen, während zu hohe Schwellenwerte die Erkennung kritischer Probleme verzögern können. Teams benötigen adaptive Alarmstrategien, die normale Nutzungsmuster lernen und Schwellenwerte dynamisch anpassen.
Einhaltung von Vorschriften und Datenschutz: Das Speichern vollständiger Konversationsprotokolle kann mit Datenschutzbestimmungen oder internen Sicherheitsrichtlinien in Konflikt geraten. Um den Bedarf an Beobachtbarkeitsdaten mit den Anforderungen an Datenminimierung, Verschlüsselung und Zugriffskontrollen abzuwägen, ist eine sorgfältige Definition von Richtlinien und die Unterstützung von Tools für die selektive Redaktion oder Anonymisierung von Protokollen erforderlich.
Um diesen Herausforderungen zu begegnen, ist ein robustes Observability-Framework erforderlich, das mit der Nutzung skaliert, konsistente Metadatenpraktiken durchsetzt, Daten mehrerer Anbieter normalisiert und intelligente Warnmeldungen bietet, um nur die kritischsten Probleme aufzudecken.
In realen Systemen ist eine LLM-Anfrage selten ein einziger Aufruf an ein Modell. Es ist eine Kette von Schritten.
Benutzereingaben werden zu einer Aufforderung. Diese Eingabeaufforderung bezieht den Kontext ein. Das Modell reagiert. Die Antwort löst ein Tool aus. Das Werkzeugergebnis fließt zurück in das Modell. Erst dann sieht der Benutzer eine Antwort. Jede Phase beinhaltet Wiederholungen LLM-Inferenz, weshalb bei der Rückverfolgung jede Zwischenentscheidung erfasst werden muss und nicht nur das Endergebnis.
Eine gute Rückverfolgung macht dies sichtbar.
Die Teams müssen Folgendes sehen:
Ohne dies wird das Debuggen zum Rätselraten. Damit können Teams genau verfolgen, was passiert ist und wo die Dinge schief gelaufen sind.
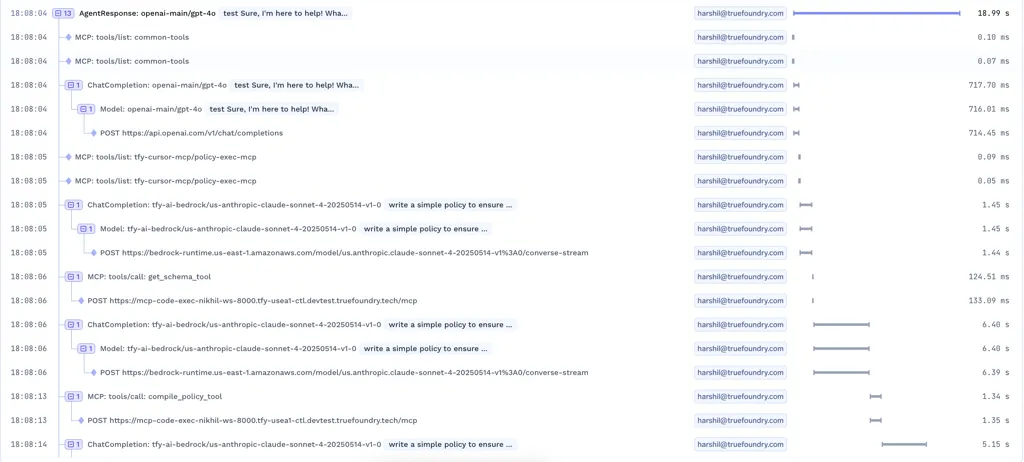
Für viele Teams sind die Kosten die erste echte Alarmglocke. Die LLM-Kosten steigen nicht wie die Infrastrukturkosten. Sie wachsen mit Tokens, Ausführlichkeit, Wiederholungsversuchen und versteckten Zwischenschritten. Eine kleine schnelle Änderung oder ein Mitarbeiter, der sich schlecht benimmt, kann stillschweigend das Doppelte ausgeben.
Aus diesem Grund ist die Sichtbarkeit auf Token-Ebene wichtig.
Die Teams müssen verstehen:
Wenn Token-Daten an Spuren gebunden sind, sind die Kosten keine Überraschung mehr und Sie können sie verwalten.
Sobald LLMs anfangen, Tools aufzurufen, werden die Dinge leistungsfähiger — und fragiler. Agenten können Datenbanken durchsuchen, APIs aufrufen oder Workflows auslösen. Mit MCP werden diese Tools dynamisch erkannt und aufgerufen, was die Systeme flexibler macht, aber es ist auch schwieriger, Überlegungen anzustellen.
In der Produktion benötigen Teams klare Antworten auf grundlegende Fragen:
Ohne Beobachtbarkeit an der LLM-Beobachtbarkeits-Toolebene, Teams verlieren schnell das Vertrauen. Damit können sie das Verhalten überprüfen, Fehler debuggen und agentengestützte Systeme sicher skalieren.
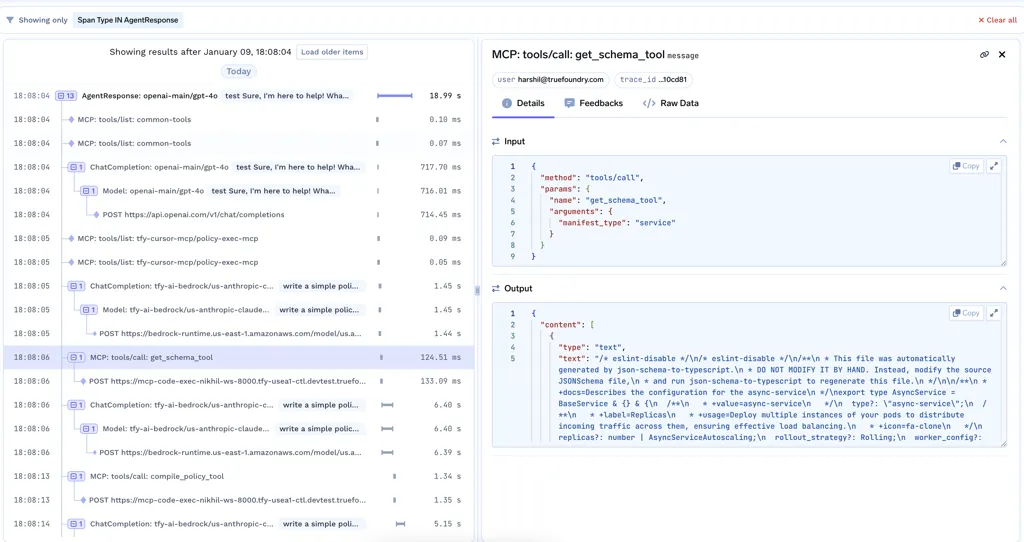
Das Ziel sind keine besseren Dashboards. Es ist Selbstvertrauen. In der Praxis ist das wo LLMOPs wird entscheidend, da Observability-Daten kontinuierlich in Bereitstellungsentscheidungen, Kostenkontrollen und Modell-Governance einfließen müssen. Wenn Teams die Spuren, die Token-Nutzung und das Verhalten der Tools klar erkennen können, können sie Probleme früher erkennen, die Kosten kontrollieren und die Qualität auf der Grundlage realer Produktionsdaten verbessern.
Dadurch entsteht eine Schleife: Beobachten Sie, was in der Produktion passiert, lernen Sie daraus, verbessern Sie das System und wiederholen Sie den Vorgang. Plattformen wie Das KI-Gateway von TrueFoundry helfen Sie Teams dabei, indem Sie Tracing, Metriken und Governance an einem Ort zusammenführen, sodass LLM-Systeme wie die kritische Infrastruktur behandelt werden können, die sie sind.
Durch die Implementierung von LLM-Observability werden undurchsichtige Inferenz-Pipelines in transparente, verwaltbare Systeme umgewandelt. Durch die Kombination von interaktiven Analysen, metadatengestütztem Kontext, dynamischen Richtlinienkontrollen, umfassender Protokollierung und nahtlosem Protokollexport erhalten Teams die Erkenntnisse, die sie benötigen, um die Leistung zu überwachen, die Kosten zu kontrollieren und die Qualität der Ergebnisse aufrechtzuerhalten. Herausforderungen wie die variable Token-Nutzung, das Datenvolumen und die Korrelation mehrerer Anbieter erfordern zwar skalierbare Architekturen und disziplinierte Metadatenpraktiken, aber eine einheitliche Observability-Lösung stellt sicher, dass Sie Anomalien frühzeitig erkennen, effektiv Fehler beheben und auf Eingabeaufforderungen zuverlässig reagieren können. In der heutigen KI-gestützten Umgebung ist eine robuste LLM-Observability nicht optional, sondern unerlässlich, um zuverlässige, kosteneffiziente Anwendungen in großem Maßstab bereitzustellen.
Buchen Sie eine Demo, um zu erfahren, wie TrueFoundry Ihnen helfen kann, die LLM-Beobachtbarkeit zu verbessern.
Beobachtbarkeit in der KI bezieht sich auf die Fähigkeit, den internen Zustand eines Systems zu verstehen, indem seine Telemetrie und Ausgänge untersucht werden. Durch die Analyse von Traces, Metriken und Logs können Teams Leistungsprobleme in Echtzeit diagnostizieren. Dadurch wird sichergestellt, dass komplexe Bereitstellungen transparent und zuverlässig bleiben und eng an den beabsichtigten Geschäftszielen ausgerichtet sind.
Zu den fünf Säulen der LLM-Observability gehören interaktive Analysen, metadatengesteuerter Kontext, umfassende Protokollierung, Auswertungen und Protokollexporte. Diese Elemente bieten Einblick in den Token-Verbrauch, die Kosten und die Antwortqualität. Zusammen ermöglichen sie es den Entwicklungsteams, ihre LLM-Anwendungen effektiv zu überwachen, Fehler zu beheben und zu optimieren.
Zu den beliebten Plattformen für tiefe Einblicke in Modelle gehören LangSmith, Helicone und Arize Phoenix. Für Unternehmen, die der Datensouveränität Priorität einräumen, bietet TrueFoundry eine leistungsstarke Möglichkeit, LLM-Observability in ihrer eigenen Infrastruktur zu implementieren. Diese Tools helfen Entwicklern dabei, Argumentationsketten zu debuggen, Kosten zu verfolgen und eine hohe Ausgabequalität der Antworten aufrechtzuerhalten.
Herkömmliches Monitoring verfolgt bekannte Kennzahlen wie Latenz oder Fehlerraten, um den Zustand der Infrastruktur aufrechtzuerhalten. LLM Observability verwendet semantisches Tracing, um zu erklären, warum bestimmte Probleme auftreten. Während die Überwachung lediglich darauf hinweist, dass ein System ausgefallen ist, liefert Observability die umfassenden Daten und den Kontext, die erforderlich sind, um die Ursache zu finden und zu beheben.
TrueFoundry ist einzigartig, weil es die Nachverfolgung auf Anwendungsebene mit der Infrastrukturüberwachung in Ihrer eigenen sicheren VPC vereint. Es behält eine Latenz von unter 10 ms bei und bewältigt gleichzeitig hohen Datenverkehr über mehrere Anbieter hinweg. Diese Integration stellt sicher, dass die LLM-Observability-Bemühungen kostengünstig und sicher bleiben und gleichzeitig detaillierte Einblicke in jede einzelne Modellinteraktion bieten.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.







.png)
.webp)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




