Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.
9,9
TrueFoundry Accelerator-Serie: Intelligenter Beschleuniger für die Dokumentenverarbeitung
Sind OCR und Dokumentenverarbeitung nicht ein gelöstes Problem?
Während viele glauben, dass OCR und Dokumentenverarbeitung gelöste Technologien sind, kostet die manuelle Dateneingabe US-Unternehmen etwa 15000 bis 30000 US-Dollar pro Mitarbeiter und Jahr. Quelle: Der Betriebs- und Zeitaufwand aufgrund der manuellen Dokumentenverarbeitung ist immer noch erheblich, weil:
Traditionelles OCR: Spröde und leistungsschwach
Herkömmliche OCR-Methoden (Computer Vision + Rules + NLP) weisen eine geringe Anpassungsfähigkeit an verschiedene Schreibformate und Layouts auf und berücksichtigen häufig die Kontext- und Datenformatanforderungen nicht.
Geringe Anpassungsfähigkeit: Selbst die besten traditionellen OCR-Systeme ihrer Klasse erreichen bei komplexen Dokumenten eine Genauigkeit von 85 bis 90%, wobei die Genauigkeit handgeschriebener Inhalte auf nur 64% sinkt. SQuelle
Schlechte Bildqualität oder Beleuchtung: 300 DPI ist das Standardminimum für optimale OCR-Ergebnisse
Lärm
Schräglage und Orientierung
Vorlagen- und Layoutabhängigkeit: Optimiert für die Arbeit mit einer bestimmten Vorlage, erfordert benutzerdefinierte Downstream-Verarbeitungspipelines oder eine Änderung der Vorlage für jedes neue Dokumenttyp-/Vorlagenupdate. Z. B. Neues Rechnungsformat von einem Lieferanten, eine leicht verschobene Spalte in einem Bericht
Kontextblindheit: OCR auf Zeichenebene kann nicht zwischen ähnlichen Zeichen unterscheiden, wodurch das dokumentweite Kontextverständnis verloren geht. Beispielsweise könnte „50 mg Metformin“ als „5Omg Metformin“ gelesen werden, was für alle nachfolgenden medizinischen Aufgaben falsch ist.
OCR/LLM Accuracy by Document Type
Document Type
Traditional OCR
SmolDocling (2B)
Qwen-VL-Max (18B)
GPT-4o
Gemini 2.5 Pro
Claude 3.7 Sonnet
Human Baseline
Clean Printed Text
97–98%
92–95%
97–98%
99–99.5%
99–99.5%
99–99.5%
99.8%
Tables & Forms
80–85%
83–87%
91–94%
96–98%
95–97%
95–97%
98–99%
Handwriting (Print)
70–80%
65–75%
80–85%
86–90%
88–92%
89–93%
96–98%
Handwriting (Cursive)
50–70%
60–70%
75–80%
82–90%
80–89%
81–90%
95–97%
Low-Quality Scans
60–75%
80–85%
90–93%
93–96%
92–95%
93–95%
95–97%
Mathematical Notation
70–80%
75–80%
88–93%
92–96%
94–97%
94–96%
97–99%
LLM-basierte OCR: Unvorhersehbar und kostspielig
LLM-basierte OCRs lösen einige Herausforderungen traditioneller Methoden, bringen jedoch neue Komplexitäten mit sich:
Nicht gelöst für handgeschriebenen Text: Obwohl GPT-4V und Claude 3.5 Sonnet erreicht haben 82-90% Genauigkeit bei handgeschriebenem Text, was eine deutliche Verbesserung darstellt, liegt dieser Wert immer noch unter den geschäftskritischen Schwellenwerten. Im Gesundheitswesen beispielsweise kann eine Fehlerquote von 10-18% bei handschriftlichen Rezepten buchstäblich lebensbedrohlich sein.
Schwer zu skalieren:
Unbezahlbar teuer: Für Unternehmen, die jedes Jahr Millionen von Dokumenten verarbeiten.
Langsamere Antworten:
Es ist schwierig, SLAs in Self-Hosted einzuhalten
Ausfallzeiten und Latenzspitzen bei Drittanbietern
Inkonsistente Ausgaben:
Halluzinationen - z. B. ein vollständig erfundener Wert für eine Klausel in einem Rechtsdokument
Es ist schwierig, die strukturierte Ausgabe einzuhalten
Gleiche Aufforderung, unterschiedliche Antworten
In Branchen wie Finanzdienstleistungen und Gesundheitswesen, in denen jährlich Millionen kritischer Dokumente verarbeitet werden, ist ein System, das zuverlässig skaliert und qualitativ hochwertige Ergebnisse zu niedrigen Kosten generiert, unerlässlich.
Wie gut ist Ihre Dokumentenverarbeitungspipeline? (Praktische Metriken)
Operational Metrics & World-Class Benchmarks
Metric
Definition (Short)
World-Class Benchmark
Straight-Through Processing (STP)
% of documents processed end-to-end without human touch
85–95% for structured documents
Field Extraction Accuracy
Correctness of extracted key fields (names, amounts, dates)
99%+ for critical fields
Time to Value
Time from document receipt to structured data availability
<2 min (simple docs), <10 min (complex forms)
Human Edit Rate
% of data requiring manual correction
<5% while maintaining 99%+ accuracy
Processing Cost per Document
Total cost (compute, labor, infra) per processed page
$0.02–$0.15 per page (depending on complexity)
Wir stellen vor: TrueFoundrys Intelligent Document Processing Accelerator
TrueFoundrys Intelligent Document Processing (IDP) ist ein generativer KI-basierter Beschleuniger, der produktionsreife Verfahren mit einer hochgradig anpassbaren und genauen OCR-Pipeline kombiniert, um durchgängige Workflows für die Dokumentenverarbeitung zu erstellen und bereitzustellen.
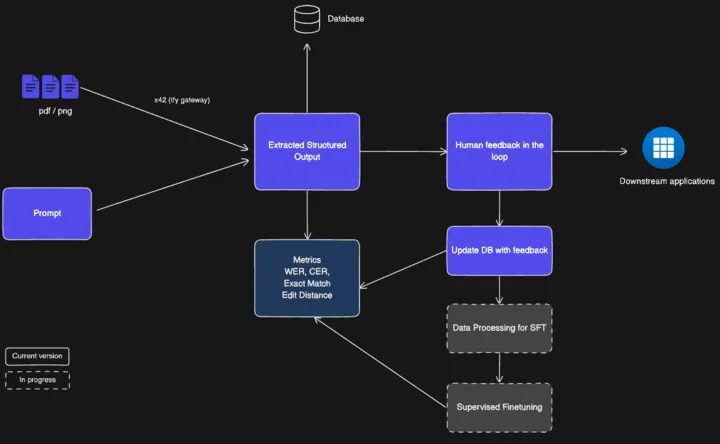
So funktioniert's: Versorgen Sie Ihre Anwendungen in wenigen Minuten mit strukturierten Daten!
Der Beschleuniger nimmt Ihre PDFs, Bilder oder Faxe auf und bereinigt sie: Rauschunterdrückung, Verzerrungsreduzierung und Hochskalierung. Modelle gehen also von einem scharfen Bild aus. Anschließend klassifiziert es jedes Dokument (Rechnung, Rezept, handschriftliche Notiz) und fügt das richtige Schema, die richtigen Aufforderungen und Domänenregeln hinzu. Das Extraktionsmodell ruft strukturierte Felder und Vertrauenswerte ab. Eine Regel-Engine validiert sie und reichert sie mit Prüfungen und Suchvorgängen an. Die Elemente werden über eine einfache Benutzeroberfläche an einen Prüfer weitergeleitet, und jede Korrektur wird rückgemeldet, um das System kontinuierlich zu verbessern.
Individuell anpassbare und modulare Komponenten
Der Accelerator besteht aus steckbaren modularen Komponenten, die zusammen sowohl einen Prototyp am ersten Tag als auch eine serienreife Anwendung in Originalgröße erstellen können.
Grundlegende Komponenten
Unterstützung mehrerer Modelle (OSS und Closedsource)
Mensch-in-the-Loop (HITL) und Feedback
Integrierte Feinabstimmungsinfrastruktur
Überwachung und Beobachtbarkeit
Integration der Wissensdatenbank (RAG + Knowledge Graph)
Fortgeschrittene Komponenten
Automatisierte Klassifizierung und Weiterleitung
Regionsorientierte OCR- und Bounding-Boxes
Automatische Schemaerkennung (Zero-Shot)
Validierung und Nachbearbeitung
Einhaltung und Überprüfbarkeit
Unser Design wurde in mehreren Unternehmensimplementierungen validiert
Gebaut für Wahlfreiheit und Kontrolle
Der Beschleuniger ist modellunabhängig, OSS oder Closedsource und kann je nach Anbieter weitergeleitet werden, um Preis/Leistung und Failover zu gewährleisten. Experten bleiben mit einer domänenspezifischen Überprüfungsoberfläche auf dem Laufenden, deren Änderungen in Trainingsdaten umgewandelt werden.
Ab dem ersten Tag einsatzbereit.
Sie erhalten Beobachtbarkeit in Echtzeit (Latenz, Durchsatz, Kosten pro Dokument) sowie Geschäfts-KPIs — STP, Feldgenauigkeit und Bearbeitungsrate. Durch Validierung und Anreicherung werden bereichsübergreifende Regeln durchgesetzt und Formate normalisiert, bevor die Daten nachgelagerte Anwendungen erreichen.
Anpassungsfähig, insbesondere für komplexe Unternehmens-Anwendungsfälle
Schemaerkennung, regionsbezogenes OCR und Wissensdatenbank-Grounding bewältigen komplexe Layouts. Auditprotokolle speichern alle Aktionen, Ergebnisse und Überschreibungen für regulierte Umgebungen.
Wie stellen wir sicher, dass dieses System skaliert?
Unsere Architektur ist ein cloudunabhängiger, auf Microservices basierender Blueprint, der für Zuverlässigkeit, Skalierbarkeit und Kosteneffizienz auf Unternehmensebene konzipiert wurde. Durch die Entkopplung der Kernkomponenten durch asynchrone Nachrichtenwarteschlangen bewältigt das System schwankende Arbeitslasten und Komponentenausfälle ohne Datenverlust und vermeidet so eine Anbieterbindung.
Aufnahmeschicht
Stateless LLM Gateway: Ein einziger Einstiegspunkt (Auth/Rate-Limit), der jedes Dokument in die Warteschlange eines Nachrichtenthemas einreiht.
Dauerhafte Pufferung: Raw-Uploads werden zur Wiedergabe, Prüfung und Wiederherstellung in den Objektspeicher geschrieben.
Verarbeitungspipeline
Dienstisolierung: Separate Worker für Klassifizierung, Extraktion und Validierung; jeder kann einzeln aktualisiert und skaliert werden.
Unabhängige Autoskalierung: CPU-/GPU-lastige Extraktoren skalieren bei Spitzenwerten, ohne dass leichtere Stufen beeinträchtigt werden.
Idempotente Jobs: Wiederspielbare Aufgaben mit Dedup sorgen für sichere Wiederholungen und exakt einmalige Ausgaben.
Daten- und Zustandsmanagement
Tragbarer Speicher: S3-kompatible Buckets enthalten Dokumente und Artefakte mit Versionierung.
Relationales Backbone: Eine PostgreSQL-kompatible Datenbank verfolgt Metadaten, Workflow-Status und HITL-Warteschlangen.
Schemaverträge: Klare Schnittstellen zwischen Diensten ermöglichen sichere, abwärtskompatible Änderungen.
Feedback- und MLOps-Ebene
Human Loop: Verifizierte Korrekturen werden anhand der Herkunft der Trainingsdaten erfasst.
Geschlossener Kreislauf: Automatisierte Pipelines für die Umschulung, Evaluierung und Bereitstellung von Pipelines bringen bessere Modelle zurück in die Produktion.
Gesteuerte Versionen: Modellregistrierung, A/B-Prüfungen und Rollbacks sorgen dafür, dass Verbesserungen sicher und überprüfbar sind.
Fazit
Moderne OCR ist nicht „gelöst“, insbesondere wenn Genauigkeit, Umfang und Kosten eine Rolle spielen. Der IDP Accelerator von TrueFoundry bietet einen pragmatischen, produktionsbereiten Ansatz mit Extraktion mehrerer Modelle, automatisierter Validierung und einer Benutzerschnittstelle, die das System kontinuierlich verbessert. Das Ergebnis ist eine schnellere direkte Verarbeitung, eine höhere Genauigkeit der Dokumente auf Feldebene, die Ihr Unternehmen tatsächlich ausmachen, und eine Plattform, die Ihre Teams bedienen können — und nicht nur eine Vorführung, die es zu bestaunen gilt.
Dieser Beschleuniger hilft Ihnen dabei, mehr Dokumente effizient und kostengünstig zu verarbeiten und gleichzeitig die Datenintegrität für Auditoren, Experten und Bediener aufrechtzuerhalten, sodass eine sofortige Implementierung ohne umfangreiche kundenspezifische Planung möglich ist.
Pilot in der Produktion: Setzen Sie sich über diesen Link mit uns in Verbindung. Wir können einen funktionierenden Prototyp für Ihren eigenen Anwendungsfall erstellen und Ihnen helfen, eine produktionsreife Anwendung in einem Zehntel der normalen Entwicklungszeit bereitzustellen!
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.
Auf Geschwindigkeit ausgelegt: ~ 10 ms Latenz, auch unter Last
































.png)
.webp)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




