

May 23, 2024
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: June 4, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Transformatoren haben sich zu einer bahnbrechenden Technologie entwickelt, die Kunst und Art, wie Computer die Sprache der Menschen, grundlegend verändert. Im Gegensatz zu konventionellen Modellen, die Wörter nacheinander verarbeiten, können Transformers einen ganzen Satz auf einmal betrachten, wodurch sie die Nuancen der Sprache unglaublich effizient erfassen können. The Transformer war der Erste in der Arbeit mit dem Titel Aufmerksamkeit ist alles was du brauchst. Sie wurden hauptsächlich entwickelt, um jede Art von Aufgabe zu lösen, die eine Eingabesequenz in eine Ausgabesequenz umwandelt, wie z. B. Sprachübersetzung, Text-zu-Sprache-Transformation usw.
Sprachmodelle haben einen langen Weg zurückgelegt und sie wurden von einfachen, regelbasierten Algorithmen zu ausgeklügelten neuronalen Netzwerken entwickelt. Anfänglich konnten diese Modelle nur vordefinierten Regeln folgen oder die Häufigkeit von Wörtern zählen. Dann kamen statistische Modelle, die Wörter wurden auf der Grundlage ihrer früheren Vorhersagen, aber mit anderen Sätzen umstritten. Die Einführung neuronaler Netzwerke, insbesondere RNNs und LSTMs, zeigte eine deutliche Verbesserung, da sie auch mehr Kontext schaffen könnten. Sie verarbeiteten Text jedoch immer noch sequentiell, was ihr Verständnis komplexer Sprachstrukturen einschränkte.
Transformers revolutionierten die Sprachverarbeitung mit ihrer Fähigkeit, alle Teile eines Satzes gleichzeitig zu verarbeiten. Das beschleunigt nicht nur die Verarbeitungszeit, sondern ermöglicht auch ein tieferes Verständnis des Kontextes, unabhängig davon, wie weit die Wörter in einem Satz voneinander entfernt sind. Die Grundidee hinter Transformers ist der „Selbstaufmerksamkeitsmechanismus“, dass es das Modell ist, das jedem Wort in einer Menge in der Beziehung zu allen anderen die Bedeutung ermöglicht. Dieser Technologiefrühling hat Fortschritte in der maschinellen Übersetzung, der Inhaltsgenerierung und sogar dem Verstehen und Generieren von menschenähnlichem Text ermöglicht und damit einen neuen Standard im NLP-Bereich gesetzt.
In diesem Blog werden wir versuchen, die Architektur des Vanilla Transformer im Detail zu untersuchen.

Transformers, eine neuartige KI-Architektur, hat neue Maßstäbe gesetzt, wie Maschinen Sprache verstehen und erzeugen. Im Kern sind sie aufgrund mehrerer zentraler Konzepte außergewöhnlich gut darin, riesige Mengen an Textdaten zu verarbeiten. Lassen Sie uns in diesem Zusammenhang die Kernkonzepte und die Architektur und die Hauptkomponenten dazu, die Transformatoren, kennen.
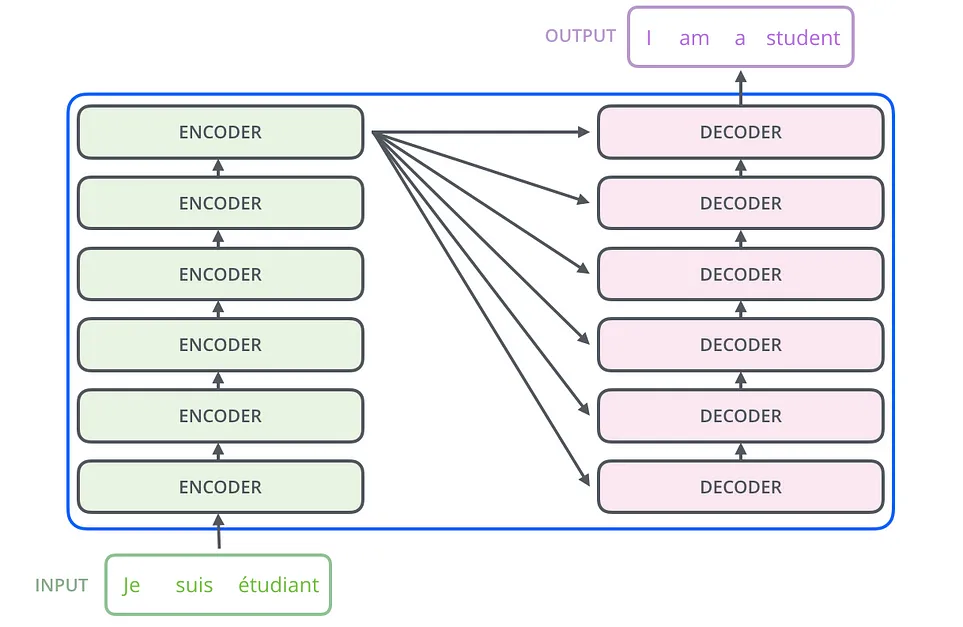
Die Architektur von Transformers basiert auf zwei Säulen: dem Encoder und dem Decoder. Der Encoder liest und verarbeitet den Eingangstext und wandelt ihn in ein Format um, das das Modell verstehen kann. Setze dich vor, es nimmt einen Satz auf und zerlegt ihn in seiner Essenz. Auf der anderen Seite nimmt der Decoder diese Informationen und verarbeitet Schritt für Schritt die Ausgabe, als ob das Set in eine andere Sprache übersetzt würde. This and Her macht Transformers so leistungsstark für Aufgaben wie Übersetzungen, bei denen es darauf ankommt, den Kontext zu verstehen und genaue Antworten zu generieren.
Das Herzstück der Encoder und Decoder des Transformer ist der Selbstaufmerksamkeitsmechanismus. Das Modell kann die Bedeutung jedes Wortes in einer Reihe in Bezug auf das Verhältnis zu den anderen Wörtern nur sehr dünn modellieren. Im Gegensatz zu älteren Modellen, die in einem langen Satz möglicherweise den Überblick über frühere Wörter verlieren, verfügen Transformers also über ein umfassendes Verständnis des gesamten Kontextes.

Da Transformers alle Wörter in einem Satz gleichzeitig verarbeiten, benötigen sie eine Möglichkeit, die Reihenfolge der Wörter zu verstehen — hier ist die Positionscodierung im Spiel. Jedes Wort ist ein eindeutiger Code, den seine Position im Satz darstellt. Dadurch wird sichergestellt, dass das Modell den Sprachfluss und die Struktur der Sprache erfassen kann, was für das Verständnis der Bedeutung der Sätze von ausschlaggebender Bedeutung ist.
Aufbauend auf der Idee der Selbstaufmerksamkeit ermöglicht die Mehrkopfaufmerksamkeit das Modell, das Set aus verschiedenen Perspektiven. Durch die Aufteilung des Aufmerksamkeitsmechanismus in mehrere „Köpfe“ können Transformers verschiedene Textaspekte, wie Grammatik und Semantik, gleichzeitig verarbeiten und so ein umfassendes Verständnis der Eingabe ermöglichen.


Wenn der Mensch sich für die Mechanik der Transformatoren interessiert, eine elegante Architektur entworfen hat, die darauf ausgelegt ist, komplexe Sprachen zu verstehen und zu erzeugen. Hier wird im Detail an Encodern und Decodieren gearbeitet und untersucht, wie sie bei der Verarbeitung und Produktion von Sprache funktionieren.
Die Hauptfunktion der Encoder besteht darin, die Eingangssequenz zu verarbeiten. Jedes Wort im Eingangssatz wird in Vektoren umgewandelt. Das funktionierte zu umfangreichen numerischen Grafiken, die den Kern der Wortbedeutung mit einbeziehen. Aber die Arbeit der Encoder hörts hier nicht weiter. Es muss auch den Kontext verstehen, der jedes Wort umgibt — wie es sich auf die Wörter davor bezieht und danach.
Um dies zu erreichen, verwendete der Encoder eine Reihe von Schichten, die jeweils aus Selbstaufmerksamkeitsmechanismen und neuronalen Feed-Forward-Netzwerken bestehen. Der Selbstaufmerksamkeitsmechanismus ermöglicht es dem Encoder, die Bedeutung anderer Wörter in der Menge zu berücksichtigen, sofern es sich um ein bestimmtes Wort handelt. Dieser Vorgang wird mathematisch durch Generierung der Vektoren Q (Abfrage), K (Schlüssel) und V (Wert) dargestellt, was ein dynamisches Verständnis der gesetzten Kontexte ermöglicht.

Der Decoder übernimmt den Stab vom Encoder, der mit der Generierung der Ausgangssequenz beauftragt ist. Es beginnt mit einem speziellen Token, das den Beginn der Ausgabe spezifiziert und den vom Encoder bereitgestellten Kontext verwendet, um ein Wort nach dem anderen zu generieren. Die Selbstaufmerksamkeitsschicht der Decoder sorgt dafür, dass jedes generierte Wort anhand der Wörter, die vor ihm stehen, angemessen ist, während die Aufmerksamkeitsschicht der Encoder es ermöglicht, sich auf die relevanten Teile der Eingabesequenz zu konzentrieren.
In dieser Phase finden die Transformer-Modelle die richtige Sprachgenerierung, sei es die Übersetzung eines Satzes in eine andere Sprache, die Zusammenfassung eines Textes oder sogar die Generierung kreativer Inhalte. Die Fähigkeit der Decoder, sowohl den unmittelbaren Inhalt (vorherige Wörter in der Ausgabe) als auch den breiten Inhalt (die Reihenfolge der Eingaben, wie sie vom Encoder verarbeitet werden), ist entscheidend für die erzeugte, kohärente und kontextbezogene Sprache.
Die wahre Stärke von Transformers liegt in der Synergie zwischen Encoder und Decoder. Wenn der Encoder ein tiefes Verständnis des Eingangssatzes bietet, verwendet der Decoder diese Informationen, um eine präzise und relevante Ausgabe zu erzeugen. Diese Interaktion wird durch den Aufmerksamkeitsmechanismus zwischen Encoder und Decoder gewährleistet, sodass der Decoder bei jedem Schritt des Generierungsprozesses die Ausgabe der Encoder anfordern kann.
Dieser kollaborative Mechanismus stellt sicher, dass die Ausgabe nicht nur sprachlich verstanden wird, sondern auch eine originale, echte Präsentation oder Transformation der Ausgabe darstellt. Es ist diese Synergie zwischen Encoder und Decoder, die es Transformatoren ermöglicht, hervorragende Dienste bei einer Reihe von Sprachverarbeitungsaufgaben zu bieten, von der maschinellen Übersetzung bis zur Inhaltsgenerierung.
Transformatoren haben nicht nur den Bereich der Verarbeitung natürlicher Sprache (NLP) revolutioniert, sondern auch ihre Vielseitigkeit unter Beweis gestellt, indem sie ihre Reichweite auf andere Bereiche ausgedehnt haben. So erzielen sie Wirkung:
Übersetzung: Transformatoren haben eine maschinelle Übersetzung erheblich verbessert und bieten ein schnelles menschliches Niveau an Sprachkompetenz und Verständnis. Google Translate ist ein Paradebeispiel dafür, dass zwei Transformer-Modelle wie BERT und GPT maßgeblich zur Verbesserung der Übersetzungsqualität in vielen Sprachen verwendet wurden.

Textzusammenfassung: Automatisierte Zusammenfassungstools, die auf Transformer-Modellen basieren, können jetzt präzise Zusammenfassungen langer Artikel, Berichte und Dokumente erstellen, wobei der Kontext und die Nuancen des Originaltextes beibehalten werden. Tools wie die GPT-Reihe von OpenAI sind für die Weiterentwicklung dieser Bereiche von Bedeutung und ermöglichen Nutzern schnelle Einblicke in umfangreiche Inhalte.
Transformers have through the text barriers and they through in the visual world. Vision Transformers (ViT) wendet die Prinzipien der Selbstaufmerksamkeit auf Bildpixel an und erzielt so modernste Ergebnisse bei Bilderkennungsaufgaben. Dieser Ansatz hat herkömmliche neuronale Faltungsnetzwerke (CNNs) mit Fragen und einer neuen Perspektive auf die Verarbeitung visueller Informationen in Verbindung gebracht.

Die Suchmaschine von Google war mit BERT (Bidirectional Encoder Representations from Transformers) ausgestattet, sodass sie den Kontext von Suchanfragen besser verstehen können. Dies hat die Relevanz der Suchergebnisse erheblich verbessert und den Zugriff auf Informationen für weltweite Nutzer verbessert.
KI-gesteuerte Chatbots, die Transformer-Technologie nutzen, bieten ansprechende und menschenähnliche Interaktionen. Unternehmen haben diese fortschrittlichen Chatbots in ihren Kundenservice integriert, um sofortige, kontextbezogene Unterstützung zu bieten und so die Kundenzufriedenheit und die betriebliche Effizienz zu verbessern.
GPT-3.5 und GPT-4 von OpenAI sind ein Meilenstein in große Sprachmodelleund demonstriert eine unheimliche Fähigkeit, menschenähnlichen Text zu generieren, Fragen zu beantworten und sogar zu programmieren. Die Anwendungen reichen von der Produktion von Inhalten bis hin zur Unterstützung bei Programmieraufgaben und zeigen das enorme Potenzial von Transformatoren in unterschiedlichen Branchen.
Wenn wir uns durch die entwickelte Landschaft der künstlichen Intelligenz bewegen, stehen Transformers auf dieser Reise an vorderster Front und blicken auf eine Zukunft voller Versprechen und Potenzial zurück. Ihre rasante Entwicklung und Integration in verschiedenen Bereichen deutet auf einen Weg hin zu bahnbrechenderen Innovationen. Hier sprechen wir über die Fortschritte und zukünftigen Entwicklungen sowie über die Herausforderungen und Chancen, die wir erwartet haben.
Die Enthüllung von GPT-4 durch OpenAI stellt einen monumentalen Fortschritt auf dem Gebiet dar, dass große Sprachmodelle die Grenze sind, die ich beim Verstehen und Generieren von Sprachen erreichen kann. GPT-4 übertrifft seine Vorgänger nicht nur an Größe, sondern auch an Raffinesse und bietet noch eine nuancierte Textgenerierung, Problemlösungsfunktionen und ein verbessertes Verständnis der menschlichen Sprachnuancen. Der Horizont von GPT-4 liegt in Bereichen der Verbesserung des Zusammenspiels zwischen Mensch und KI, der Automatisierung komplexer Aufgaben und der Bereitstellung innovativer Lösungen für zahlreiche Anwendungen. Wenn wir über GPT-4 hinausgehen, konzentrieren wir uns zunehmend darauf, diese Modelle effizient, interpretierbar und in der Lage zu machen, ein noch breiteres Aufgabenspektrum zu bewältigen. Das ist ein bedeutender Schritt in Richtung wirklich intelligenter Systeme.
Wenn wir mit Modellen wie GPT-4 in die Zukunft schauen, stehen wir vor fundamentalen Herausforderungen und Chancen in Bezug auf Skalierbarkeit, Interpretierbarkeit und Ethik. Um diese leistungsfähigen Modelle größer und komplexer zu machen, ist viel Leistung und Energie erforderlich, welche Fragen zu Kosten und Umweltauswirkungen stellen. Gleichzeitig ist es wichtig, dass wir verstehen, wie diese Modelle Entscheidungen treffen, insbesondere wenn sie in wichtigen Bereichen wie dem Gesundheitswesen oder dem Finanzwesen eingesetzt werden. Darüber hinaus müssen wir die ethische Seite der Dinge berücksichtigen, z. B. wie die Verbreitung falscher Informationen verhindert werden kann und welche Auswirkungen es hat, wenn Arbeitsplätze durch KI ersetzt werden. Um diese Probleme anzugehen, müssen alle, die mit KI zu tun haben, von den Developers bis hin zu den Regierungsvertretern versuchen, dass das Wachstum der Transformer-Modelle für die Gesellschaft gewährleistet und vorteilhaft ist.
Zusammenfassend lässt sich sagen, dass Transformers die Landschaft der künstlichen Intelligenz und der Verarbeitung natürlicher Sprache erheblich verändert haben. Ihre einzigartige Architektur, die in der Lage ist, den Kontext und die Nuancen der Sprache zu verstehen, hat zu bemerkenswerten Fortschritten bei Aufgaben wie Übersetzung, Textzusammenfassung und sogar über den Bereich des Textes hinaus zur Bilderkennung und vielem mehr geführt.
Zu den wichtigsten Erkenntnissen gehören die Bedeutung des Selbstachtsamkeitsmechanismus, der es ermöglicht, dass Transformatoren alle Datensequenzen gleichzeitig verarbeiten, und der innovative Einsatz von Positionscodierung, um die Sequenzreihenfolge durch die Datenverarbeitung aufrechtzuerhalten. Darüber hinaus skizziert die Skalierbarkeit dieser Modelle zusammen mit der Notwendigkeit der Interpretierbarkeit und ethischen Überlegungen den Fahrplan für zukünftige Entwicklungen in diesem Bereich.
Transformatoren sind nicht nur ein technologischer Fortschritt, sie stehen auch für eine Veränderung in der Kunst und Weise, wie wir die Fähigkeiten der KI präsentiert haben. Sie bieten einen Einblick in eine Zukunft, in der KI die menschliche Sprache mit beispielloser Tiefe und Flexibilität verstehen und mit ihr interagieren kann, was branchenübergreifend neue Wege für Automatisierung, Kreativität und Effizienz eröffnet. Wenn wir die Grenzen der Transformer-Technologie weiter ausloten und erweitern, ist ihre Rolle bei der Gestaltung der Zukunft der KI nach wie vor von großer Bedeutung. Sie verspricht ein Umfeld, in dem in der Partnerschaft zwischen Menschen und Maschinen neue Höhen der Zusammenarbeit und Innovation erreicht werden.
Die LLM-Transformator-Architektur ist ein revolutionäres neuronales Netzwerkdesign, bei dem die gesamten Eingabesequenzen gleichzeitig verarbeitet werden. Im Gegensatz zu älteren Modellen wird im Wortkontext ein Mechanismus der Selbstaufmerksamkeit verwendet, um den Text zu verstehen. Dies ermöglicht es den großen Sprachmodellen, die Menschen gerne Text effizient zu verstehen und zu generieren, da die maschinelle Übersetzung und Inhaltsproduktion in den Vereinigten Staaten einen Schritt voraus sind.
Ja, Large Language Models (LLMs) verlassen sich heute in der LLM-Entwicklung stark auf die Transformer-Architektur. Transformers revolutionierte die Sprachverarbeitung, indem sie alle Sätze gleichzeitig verarbeiteten und so das Kontextverständnis und die Verarbeitungsgeschwindigkeit verbesserten. Diese Kerninnovation ist nach der für moderne LLMs wichtigen Bedeutung, menschenähnlichen Text zu generieren und komplexe Sprachaufgaben für Nutzer in den USA effizient zu erledigen.
Ein Transformator in LLM ist eine KI-Architektur, die alle Sätze gleichzeitig verarbeitet. Es nutzte einen Mechanismus der Selbstaufmerksamkeit, um die Wortbeziehungen und den Sinn im Kontext zu verstehen. Diese bahnbrechende technologische Revolution war die Kunst und die Art und Weise, wie große Sprachmodelle menschenähnlichem Text lernen und generieren, war für fortgeschrittene Anwendungen und effizientes Sprachverständnis von entscheidender Bedeutung.
Die Architektur hinter Large Language Models (LLMs) ist als LLM-Transformer-Architecture bekannt. Dieses clevere Design hilft ihnen, menschenähnlichen Text zu verstehen und zu generieren, indem Informationen auf einzigartige Weise verarbeitet werden. Es ermöglicht ihnen, komplexe Muster aus riesigen Datenmengen zu lernen.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.







.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




