July 25, 2026
|
5 min read

Published: June 12, 2026

Blazingly fast way to build, track and deploy your models!
Transformers have emerged as a groundbreaking technology, reshaping how computers understand human language. Unlike traditional models that process words one after another, Transformers can look at an entire sentence all at once, making them incredibly efficient at picking up the nuances of language. The Transformer was first introduced in the work titled Attention Is All You Need. They were mainly developed to solve any kind of task that transforms an input sequence to an output sequence, such as speech translation, text-to-speech transformation etc.
Language models have come a long way, evolving from simple, rule-based algorithms to sophisticated neural networks. Initially, these models could only follow predefined rules or count the frequency of words. Then came statistical models, which predicted words based on their previous ones but struggled with longer sentences. The introduction of neural networks, especially RNNs and LSTMs, marked a significant improvement, allowing models to remember more context. However, they still processed text sequentially, which limited their understanding of complex language structures.

Transformers revolutionized language processing with their ability to handle all parts of a sentence simultaneously. This not only speeds up the processing time but also enables a deeper understanding of context, regardless of how far apart words are in a sentence. The main idea behind Transformers is the “self-attention mechanism,” which allows the model to weigh the importance of each word in a sentence relative to all others. This leap in technology has powered advancements in machine translation, content generation, and even understanding and generating human-like text, setting a new standard in the field of NLP.
In this blog, we will try to explore the architecture of the vanilla Transformer in detail.

Transformers, a novel AI architecture, have set new benchmarks in how machines understand and generate language. At their core, several pivotal concepts make them exceptionally good at processing vast amounts of text data. Let’s dive into these core concepts, breaking down the architecture and key components that define Transformers.
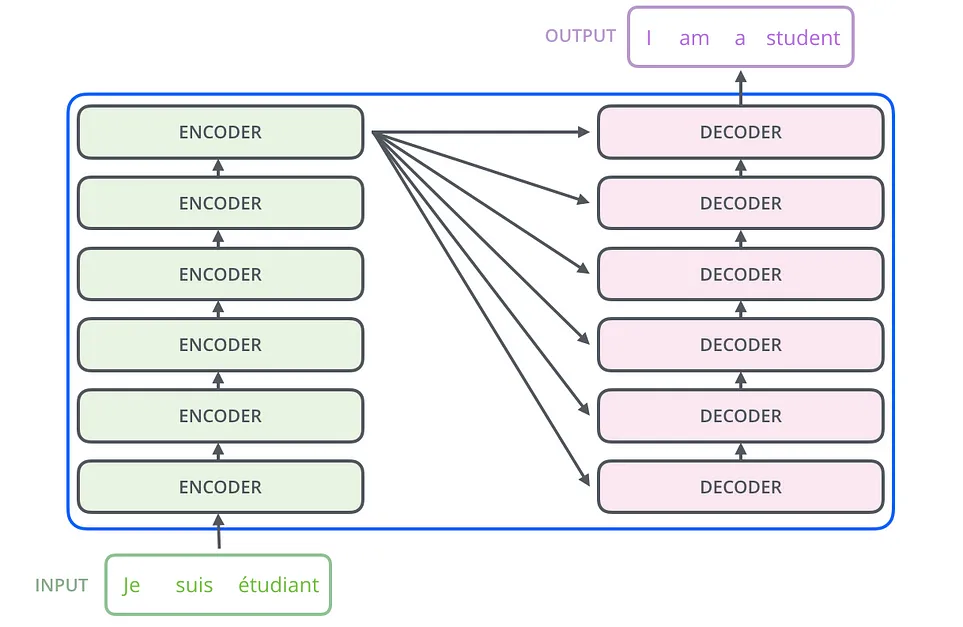
The architecture of Transformers stands on two pillars: the encoder and the decoder. The encoder reads and processes the input text, transforming it into a format that the model can understand. Imagine it as absorbing a sentence and breaking it down into its essence. On the other side, the decoder takes this processed information and steps through it to produce the output, like translating the sentence into another language. This back-and-forth is what makes Transformers so powerful for tasks like translation, where understanding context and generating accurate responses are key.
At the heart of the Transformer’s encoder and decoder is the self-attention mechanism. This allows the model to weigh the importance of each word in a sentence in relation to every other word. Hence, unlike older models that might lose track of earlier words in a long sentence, Transformers maintain a comprehensive understanding of the entire context.

Since Transformers process all words in a sentence simultaneously, they need a way to understand the order of words—this is where positional encoding comes in. Each word is given a unique code that represents its position in the sentence, ensuring that the model can grasp the flow and structure of the language, crucial for understanding the meaning behind sentences.
Building on the idea of self-attention, multihead attention allows the model to look at the sentence from different perspectives. By splitting the attention mechanism into multiple “heads,” Transformers can simultaneously process diverse aspects of the text, like grammar and semantics, giving a richer understanding of the input.

Delving deeper into the mechanics of Transformers reveals an elegant architecture designed for complex language understanding and generation. Here, we’ll explore the intricacies of the encoder and decoder, as well as how they work in concert to process and produce language.
The encoder’s primary function is to process the input sequence. Each word in the input sentence is converted into vectors, which are rich numerical representations containing the essence of the word’s meaning. But the encoder’s job doesn’t stop there. It also needs to understand the context surrounding each word—how it relates to the words before and after it.
To achieve this, the encoder utilizes a series of layers, each composed of self-attention mechanisms and feed-forward neural networks. The self-attention mechanism allows the encoder to weigh the importance of other words in the sentence when considering a specific word. This process is mathematically represented through the generation of Q (Query), K (Key), and V (Value) vectors, facilitating a dynamic understanding of the sentence’s context.

The decoder takes the baton from the encoder, tasked with generating the output sequence. It starts with a special token indicating the beginning of the output and uses the context provided by the encoder to generate one word at a time. The decoder’s self-attention layer ensures that each generated word is appropriate based on the words that have come before it, while the encoder-decoder attention layer allows the decoder to focus on relevant parts of the input sequence.
This stage of the Transformer model is where the actual language generation happens, whether it be translating a sentence into another language, summarizing a text, or even generating creative content. The decoder’s ability to consider both the immediate context (previous words in the output) and the broader context (the input sequence as processed by the encoder) is crucial for producing coherent and contextually relevant language.
The true power of Transformers lies in the synergy between the encoder and decoder. While the encoder provides a deep understanding of the input sentence, the decoder leverages this information to produce an accurate and relevant output. This interaction is mediated through the encoder-decoder attention mechanism, allowing the decoder to query the encoder’s output at each step of the generation process.
This collaborative mechanism ensures that the output not only makes sense linguistically but is also a faithful representation or transformation of the input. It’s this encoder-decoder synergy that enables Transformers to excel in a wide range of language processing tasks, from machine translation to content generation.
Transformers have not only revolutionized the field of Natural Language Processing (NLP) but also shown their versatility by extending their reach into other domains. Here’s how they’re making an impact:
Translation: Transformers have significantly improved machine translation, offering near-human levels of fluency and understanding. Google Translate is a prime example, where Transformer models like BERT and GPT have been pivotal in enhancing translation quality across numerous languages.

Text Summarization: Automated summarization tools, powered by Transformer models, can now produce concise summaries of long articles, reports, and documents, maintaining the original text’s context and nuance. Tools like OpenAI’s GPT series have been instrumental in advancing this field, providing users with quick insights from lengthy content.
Breaking the barriers of text, Transformers have ventured into the visual world. Vision Transformers (ViT) apply the principles of self-attention to image pixels, achieving state-of-the-art results in image recognition tasks. This approach has challenged conventional convolutional neural networks (CNNs), offering a new perspective on processing visual information.

Google’s search engine has been supercharged with BERT (Bidirectional Encoder Representations from Transformers), enabling it to understand the context of search queries better. This has significantly improved the relevance of search results, making information retrieval more precise for users worldwide.
AI-driven chatbots, leveraging Transformer technology, offer more engaging and human-like interactions. Businesses have integrated these advanced chatbots into their customer service to provide immediate, context-aware support, enhancing customer satisfaction and operational efficiency.
GPT-3.5 and GPT-4 by OpenAI are a landmark in large language models, demonstrating an uncanny ability to generate human-like text, answer questions, and even code. Its applications range from content creation to aiding in programming tasks, showcasing the vast potential of Transformers in various industries.
As we navigate through the evolving landscape of artificial intelligence, Transformers are at the forefront of this journey, holding a future filled with promise and potential. Their rapid development and integration into various fields suggest a path toward even more groundbreaking innovations. Here, we delve into the advancements and prospective directions, alongside the challenges and opportunities that await.
The unveiling of GPT-4 by OpenAI represents a monumental leap forward in the realm of large language models, pushing the boundaries of what AI can achieve in language understanding and generation. GPT-4 not only surpasses its predecessors in size but also in sophistication, offering even more nuanced text generation, problem-solving capabilities, and an enhanced understanding of human language nuances. The horizon for GPT-4 extends into improving human-AI interaction, automating complex tasks, and providing innovative solutions across countless applications. As we look beyond GPT-4, the focus intensifies on making these models more efficient, interpretable, and capable of handling an even wider array of tasks, marking a significant stride toward truly intelligent systems.
As we look into the future with models like GPT-4, we face essential challenges and opportunities around scalability, interpretability, and ethics. Making these powerful models bigger and more complex requires a lot of computing power and energy, which raises questions about cost and environmental impact. At the same time, it’s important that we can understand how these models make decisions, especially when they’re used in important areas like healthcare or finance. Further, we need to consider the ethical side of things, such as how to prevent the spread of false information and understand the effects of replacing jobs with AI. Tackling these issues will take effort from everyone involved in AI, from developers to government leaders, to ensure that the growth of Transformer models is responsible and beneficial for society.
In summary, Transformers have significantly reshaped the landscape of artificial intelligence and natural language processing. Their unique architecture, capable of understanding the context and nuances of language, has led to remarkable advancements in tasks such as translation, text summarization, and even beyond the realm of text into image recognition and more.
Key takeaways include the importance of the self-attention mechanism that allows Transformers to process entire sequences of data simultaneously, and the innovative use of positional encodings to maintain the sequence order in data processing. Furthermore, the scalability of these models, alongside the need for interpretability and ethical considerations, outlines the roadmap for future developments in the field.
Transformers are not just a technological advancement; they represent a shift in how we envision the capabilities of AI. They offer a glimpse into a future where AI can understand and interact with human language with unprecedented depth and flexibility, opening new avenues for automation, creativity, and efficiency across industries. As we continue to explore and expand the boundaries of Transformer technology, their role in shaping the future of AI remains pivotal, promising a landscape where the partnership between humans and machines reaches new heights of collaboration and innovation.
The llm transformer architecture is a revolutionary neural network design that processes entire input sequences simultaneously. It leverages a self-attention mechanism to understand word context deeply, unlike older models. This enables large language models to efficiently comprehend and generate human-like text, powering advancements in machine translation and content creation across the US.
Yes, Large Language Models (LLMs) heavily rely on the transformer architecture in LLM development today. Transformers revolutionized language processing by handling entire sentences simultaneously, improving context understanding and processing speed. This core innovation remains crucial for modern LLMs to generate human-like text and perform complex language tasks efficiently for users in the us.
A transformer in LLM is an AI architecture that processes entire sentences simultaneously. It uses a self-attention mechanism to understand word relationships and context deeply. This groundbreaking technology revolutionized how large language models learn and generate human-like text, crucial for advanced applications and efficient language understanding.
The architecture behind Large Language Models (LLMs) is known as the llm transformer architecture. This clever design helps them understand and generate human-like text by processing information in a unique way. It lets them learn complex patterns from huge amounts of data.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








The latest news, articles, and resources sent to your inbox

.webp)