

July 21, 2026
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: June 4, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Generative KI hat sich schnell vom Experimentieren zur Ausführung entwickelt und ist jetzt in allen Produkten, Abläufen und Kundenerlebnissen verankert. Mit zunehmender Akzeptanz durch Unternehmen zeichnet sich jedoch ein strukturelles Problem ab: Die Nutzung von KI wächst schneller als die Mechanismen, die zur Kostenkontrolle erforderlich sind. Was als ein in sich geschlossenes Pilotprojekt beginnt, erweitert sich schnell auf mehrere Teams, die unabhängig voneinander arbeiten, Anwendungen, die mehrere Modelle aufrufen, und agentische Workflows, die mehrstufige Argumentation ausführen. Das Ergebnis sind nicht nur höhere Ausgaben, sondern auch zunehmend unvorhersehbare und sich verschärfende Kosten im gesamten Unternehmen.
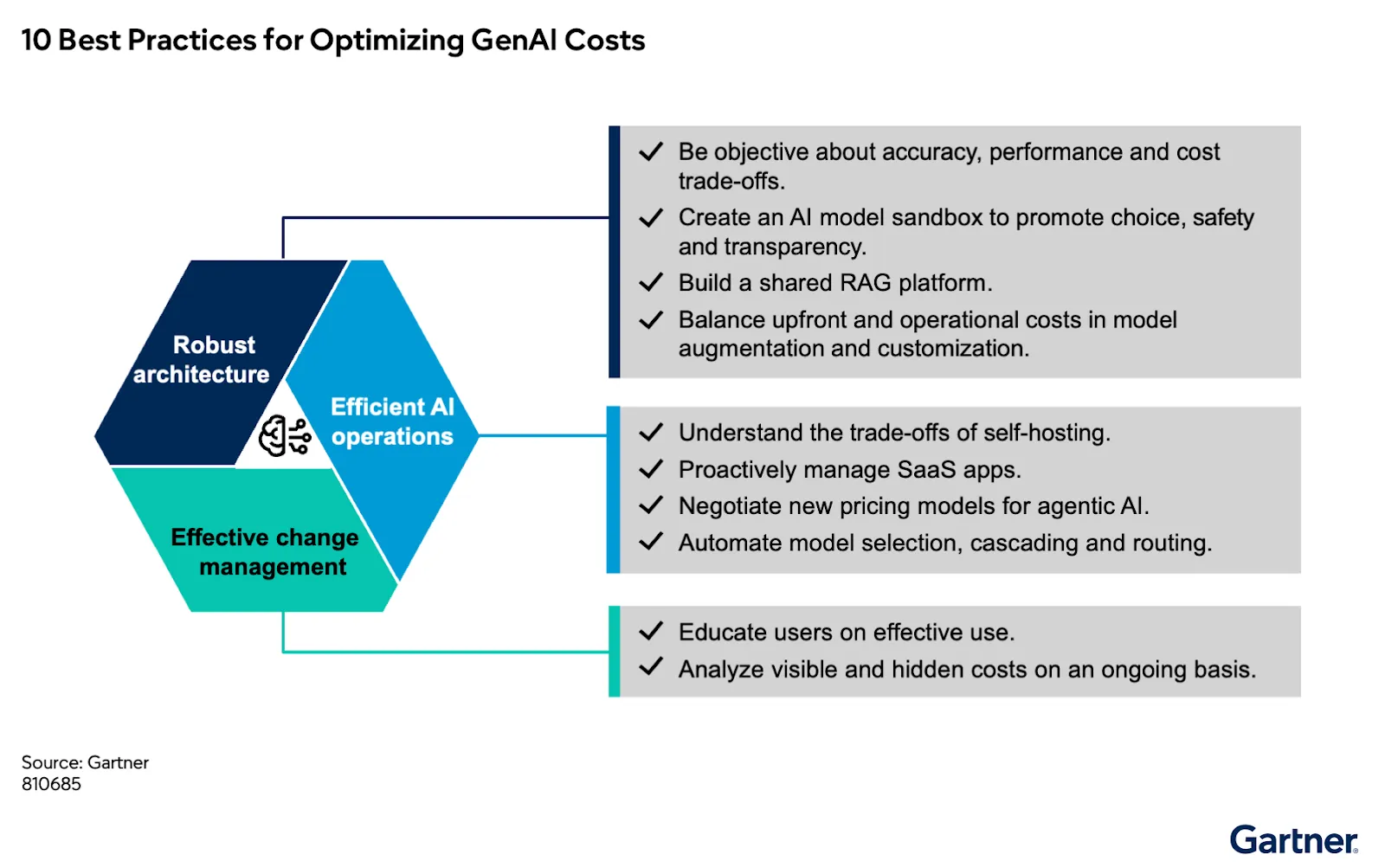
Diese Herausforderung wird in Gartner hervorgehoben “10 Best Practices zur Optimierung der Kosten für generative und agentische KI“ , in dem untersucht wird, wie architektonische Entscheidungen und mangelnde Betriebsdisziplin zu Kostenüberschreitungen in großem Maßstab führen. Wie der Bericht feststellt,“Bis 2028 werden mindestens 50% der GENai-Projekte ihre budgetierten Kosten aufgrund schlechter architektonischer Entscheidungen und mangelnder betrieblicher Kenntnisse überschreiten.“ Es handelt sich nicht um ein Werkzeugproblem, sondern um einen grundlegenden Fehler in der Architektur und im Betriebsmodell.
Dieser Wandel wird in Gartner untersucht „10 Best Practices zur Optimierung generativer und agentischer KI-Kosten“ , das sich darauf konzentriert, wie Unternehmen Kosten, Unternehmensführung und Betriebskontrolle überdenken müssen, wenn KI-Systeme in die Produktion übergehen.
TrueFoundry wird in diesem Bericht erwähnt im Kontext von KI-Gateways — einer neuen Steuerungsebene zur Verwaltung von Kosten, Zuverlässigkeit und Governance für alle KI-Workloads.
Lesen Sie den vollständigen Bericht hier
Gartner hebt das Ausmaß der Herausforderung deutlich hervor:“Unternehmen, die von GenAI-Pilotprojekten zur Produktion übergehen, erleben ein böses Erwachen, wenn es um die Kosten geht. Die Entwicklung eines produktionsbereiten GENai-Systems kann um ein Vielfaches teurer sein als die Durchführung eines Pilotprojekts.“ Dies ist der Wendepunkt: Die KI-Kosten werden zu einem Laufzeitproblem und nicht zu einem Problem der Bauzeit, das davon abhängt, wie Systeme orchestriert, gesteuert und in großem Maßstab betrieben werden.
Um das Problem zu verstehen, ist es wichtig, das Verhalten von KI-Systemen im großen Maßstab aufzuschlüsseln.
1 Inferenz wird zur dominanten Kostenschicht
Im Gegensatz zu herkömmlichen Systemen verursacht KI bei jeder Verwendung Kosten.
Gartner hebt diesen Wandel hervor:
„Bis 2028 werden die aggregierten Kosten der Modellinferenz mindestens 70% der gesamten Lebenszeitkosten eines Modells ausmachen...“
Dies ändert grundlegend die Art und Weise, wie die Kosten verwaltet werden müssen.
2 Agentische Workflows vervielfachen die Kosten pro Anfrage
Moderne KI-Systeme sind nicht einstufig.
Eine einzelne Anfrage kann Folgendes auslösen:
Das schafft nichtlineare Kostenexpansion.
3 Fragmentierte Akzeptanz führt zu Ineffizienz
In den meisten Unternehmen:
Dies führt zu:
4 Fehlende Runtime-Governance führt zu Kostenüberhang
Ohne zentrale Steuerung:
Hier fallen die Kosten an im großen Maßstab nicht überschaubar.

Die Empfehlungen im Gartner deuten auf eine deutliche Veränderung hin.
Es geht nicht um bessere Modelle.
Es geht um steuert, wie Modelle in der Produktion verwendet werden.
Zu den wichtigsten Praktiken gehören:
1 Zentraler Zugriff auf KI-Systeme
Eine einzige Steuerungsebene zur Verwaltung aller Modell- und Werkzeuginteraktionen.
2 Intelligentes Modellrouting
Dynamische Auswahl von Modellen auf der Grundlage von Kosten, Latenz und Leistung.
3 Regierungsführung und Durchsetzung von Richtlinien
Anwendung von Kontingenten, Grenzwerten und Leitplanken für die gesamte Nutzung.
4 Durchgängige Beobachtbarkeit
Verfolgen Sie Nutzung, Leistung und Kosten auf granularer Ebene.
5 Mechanismen zur Kostenoptimierung
Reduzierung redundanter Inferenzen durch Caching und Wiederverwendung.
Gartner formalisiert diesen Wandel:
„Eine neue Kategorie von Tools, sogenannte KI-Gateways, kann helfen, die Kosten zu kontrollieren, indem sie Richtlinien durchsetzt... und Funktionen wie Caching und Model-Routing zur Kostensenkung bereitstellt.“
Dies definiert eine neue Ebene:
die KI-Steuerungsebene
Wir glauben, dass die von Gartner skizzierte Richtung auf eine klare Anforderung hinweist:
eine zentrale Steuerungsebene, die regelt, wie KI im gesamten Unternehmen eingesetzt wird.
TrueFoundry wurde in diesem Bericht erwähnt als Teil dieses aufstrebenden KI-Gateway-Ökosystems.
TrueFoundry arbeitet auf der Ebene, auf der Die Nutzung von KI findet statt — und zwar dort, wo Kosten entstehen.
1 Von reaktivem Tracking zur proaktiven Kontrolle
Anstatt:
TrueFoundry ermöglicht:
2 Dynamische Optimierung zur Laufzeit
3 Vollständige Sichtbarkeit aller KI-Systeme
4 Unternehmensführung
5 Einsatzbereite Bereitstellung für Unternehmen
Dadurch ändert sich das Betriebsmodell von:
„Wie hoch sind unsere KI-Ausgaben?“
zu
„Setzen wir KI effizient ein — und sollte diese Anfrage überhaupt ausgeführt werden?“
Generative KI tritt in ihre zweite Phase ein.
In der ersten Phase ging es um den Zugang.
In der nächsten Phase geht es um Kontrolle und Wirtschaft.
Gleichzeitig entwickeln sich die Preismodelle weiter:
„Bis 2030 werden mindestens 40% der SaaS-Ausgaben von Unternehmen in nutzungs-, vermittlungs- oder ergebnisorientierte Preisgestaltung verlagert werden.“ Das verursacht Kosten:
Organisationen, die Kontrolle auf der Laufzeitebene einführen, werden:
Endgültige Perspektive
Gartner definiert generative KI-Kosten als Herausforderung auf Systemebene, die auf dem Laufzeitverhalten beruht — nicht auf der Modellauswahl. Weil im großen Maßstab:
Erfolgreiche Unternehmen werden nicht diejenigen sein, die KI schneller einführen.
Sie werden diejenigen sein, die Folgendes vorstellen:
Kontrolle, Steuerung und wirtschaftliche Disziplin bei der Funktionsweise von KI-Systemen.
Der Vorteil wird nicht aus dem Zugang zu Modellen resultieren —
aber aus der Kontrolle darüber, wie diese Modelle verwendet werden.
Erkunden Sie weiter
“ Lesen Sie den vollständigen Gartner-Bericht
Erfahre mehr über TrueFoundry: https://www.truefoundry.com
Gartner unterstützt keine Anbieter, Produkte oder Dienstleistungen, die in seinen Forschungspublikationen dargestellt werden, und rät Technologieanwendern nicht, nur die Anbieter mit den höchsten Bewertungen oder anderen Auszeichnungen auszuwählen. Die Forschungspublikationen von Gartner geben die Meinungen der Forschungsorganisation von Gartner wieder und sollten nicht als Tatsachenfeststellungen ausgelegt werden.
Gartner, 10 Best Practices zur Optimierung generativer und agentischer KI-Kosten, von Arun Chandrasekaran et al., 20. März 2026
GARTNER ist eine Marke von Gartner, Inc. und/oder seinen verbundenen Unternehmen.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.





Sie können generative KI-Kosten optimieren, indem Sie das richtige Modell für jede Aufgabe verwenden und unnötige Nutzung vermeiden. Einfache Aufgaben erfordern keine großen und teuren Modelle. Fokussierte Prompts vermeiden zusätzlichen Token-Verbrauch ohne Mehrwert. Die Begrenzung der Antwortlänge verhindert Bezahlung für unnötige Ausgabe.
Sie können LLM-Kosten reduzieren, indem Sie lange Prompts und wiederholte Abfragen einschränken. Da längere Eingaben den Token-Verbrauch erhöhen, helfen prägnante Prompts bei der Kostenkontrolle. Wiederholte Abfragen ohne Caching führen zu vermeidbaren Ausgaben. Die Verwendung kleinerer Modelle für einfache Aufgaben ist ein weiterer effektiver Weg, Kosten zu senken.
Ein KI-Gateway hilft bei der Kostenoptimierung, indem es steuert, wie verschiedene KI-Modelle eingesetzt werden. Es leitet Anfragen basierend auf der Aufgabe an das kosteneffizienteste Modell weiter, sodass einfache Abfragen keine teuren Modelle verwenden. Dies verhindert unnötige Ausgaben und verbessert die Effizienz. Mit TrueFoundry geht das KI-Gateway noch weiter, indem es Teams eine einheitliche Schicht zur Verbindung, Beobachtung und Steuerung der KI-Nutzung über Anwendungen hinweg bietet.
Ja, Sie können generative KI über begrenzte Pläne von Anbietern kostenlos nutzen. Diese Pläne sind für Tests und kleine Nutzungen geeignet. Sie haben jedoch Einschränkungen bei Nutzung und Funktionen. Sobald die Nutzung steigt, müssen Sie auf bezahlte Pläne wechseln.
Generative KI ist teuer, da sie für jede Anfrage hohe Rechenleistung benötigt. Große Modelle laufen auf kostspielier Infrastruktur, was die Gesamtkosten erhöht. Kosten entstehen auch durch Embeddings, Integrationen und wiederholte Workflows. Dies macht die Gesamtkosten höher als nur die Token-Nutzung.
Zu den Best Practices für die KI-Kostenoptimierung gehören die Verwendung des kleinsten effektiven Modells und die Reduzierung unnötiger Nutzung. Klare und begrenzte Prompts und Ausgaben helfen, den Token-Verbrauch zu kontrollieren. Regelmäßiges Monitoring der Nutzung hilft, kostenintensive Bereiche zu identifizieren. Die Reduzierung wiederholter Aufgaben und die Optimierung von Workflows verbessern ebenfalls die Effizienz.
Die LLM-Inferenzkosten werden von Modellgröße, Token-Nutzung und Anfragehäufigkeit beeinflusst. Größere Modelle kosten mehr, da sie mehr Rechenleistung benötigen. Längere Prompts und Ausgaben erhöhen den Token-Verbrauch und die Kosten. Häufige oder mehrstufige Anfragen können die Gesamtkosten schnell erhöhen.
Die Token-Nutzung beeinflusst KI-Kosten, indem sie bestimmt, wie viel pro Anfrage berechnet wird. Jede Eingabe und Ausgabe wird in Tokens gemessen. Längere Prompts und Antworten führen zu höheren Kosten. Ein sorgfältiges Management der Token-Nutzung hilft, die Gesamtausgaben unter Kontrolle zu halten.
Die Kosten für den Betrieb von LLMs in der Produktion umfassen Token-Nutzung, Infrastruktur und systembezogene Ausgaben. Auch Speicher, Monitoring und Integrationen müssen berücksichtigt werden. Token-Kosten sind oft nur ein Teil der Gesamtausgaben. Mit wachsender Nutzung steigen diese zusätzlichen Kosten erheblich.
Agentische KI ist ein System, bei dem KI Aufgaben in mehreren Schritten und Entscheidungen ausführt. Dies beeinflusst die Kosten, indem die Anzahl der erforderlichen Modellaufrufe zur Aufgabenerledigung steigt. Jeder Schritt erhöht den Token-Verbrauch und die Rechenkosten. Dies macht sie teurer als einstufige KI-Interaktionen.






Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


